 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Bit-Rate Speech Coding with VQ-VAE and a WaveNet Decoder
Oct 14, 2019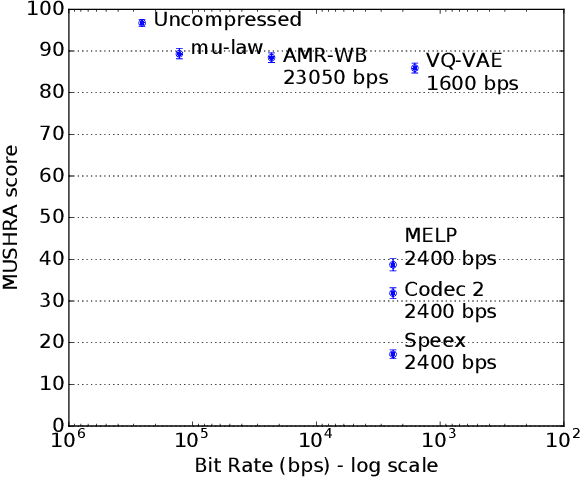
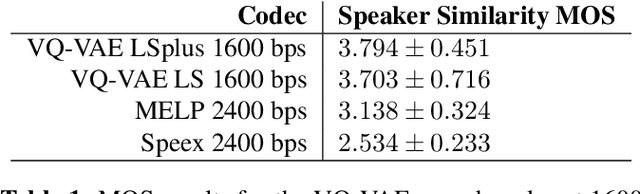
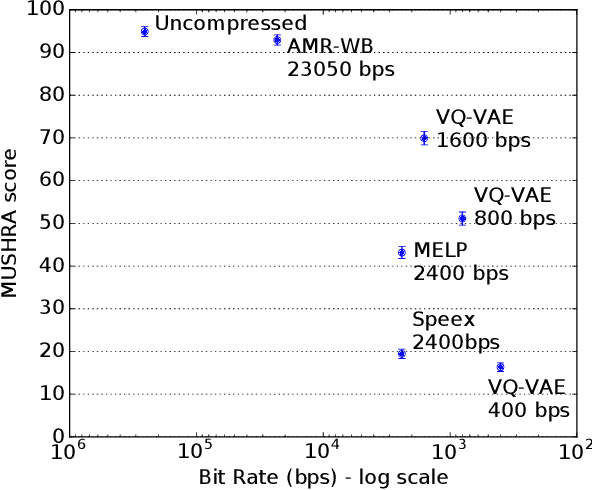
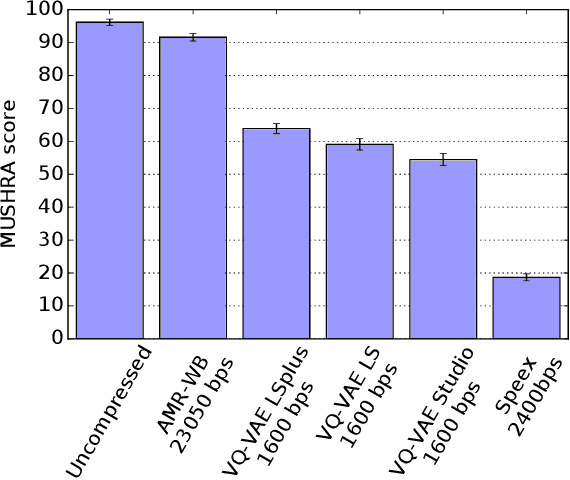
In order to efficiently transmit and store speech signals, speech codecs create a minimally redundant representation of the input signal which is then decoded at the receiver with the best possible perceptual quality. In this work we demonstrate that a neural network architecture based on VQ-VAE with a WaveNet decoder can be used to perform very low bit-rate speech coding with high reconstruction quality. A prosody-transparent and speaker-independent model trained on the LibriSpeech corpus coding audio at 1.6 kbps exhibits perceptual quality which is around halfway between the MELP codec at 2.4 kbps and AMR-WB codec at 23.05 kbps. In addition, when training on high-quality recorded speech with the test speaker included in the training set, a model coding speech at 1.6 kbps produces output of similar perceptual quality to that generated by AMR-WB at 23.05 kbps.
* ICASSP 2019
Unsupervised Doodling and Painting with Improved SPIRAL
Oct 02, 2019
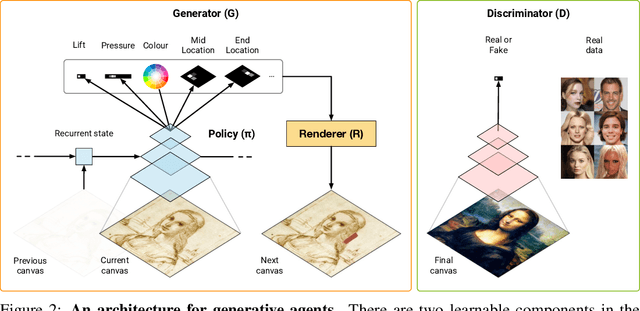


We investigate using reinforcement learning agents as generative models of images (extending arXiv:1804.01118). A generative agent controls a simulated painting environment, and is trained with rewards provided by a discriminator network simultaneously trained to assess the realism of the agent's samples, either unconditional or reconstructions. Compared to prior work, we make a number of improvements to the architectures of the agents and discriminators that lead to intriguing and at times surprising results. We find that when sufficiently constrained, generative agents can learn to produce images with a degree of visual abstraction, despite having only ever seen real photographs (no human brush strokes). And given enough time with the painting environment, they can produce images with considerable realism. These results show that, under the right circumstances, some aspects of human drawing can emerge from simulated embodiment, without the need for external supervision, imitation or social cues. Finally, we note the framework's potential for use in creative applications.
Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
Sep 19, 2019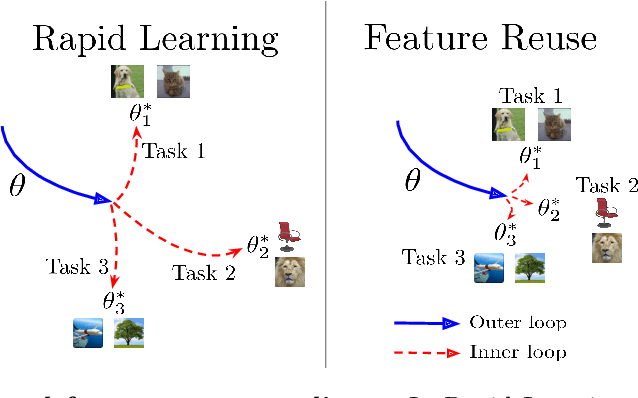

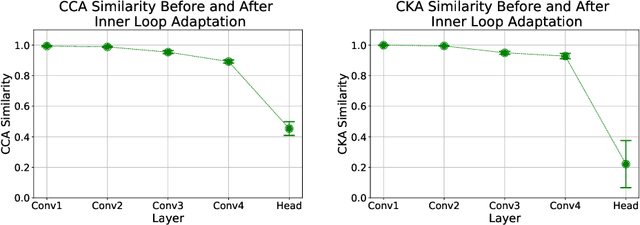

An important research direction in machine learning has centered around developing meta-learning algorithms to tackle few-shot learning. An especially successful algorithm has been Model Agnostic Meta-Learning (MAML), a method that consists of two optimization loops, with the outer loop finding a meta-initialization, from which the inner loop can efficiently learn new tasks. Despite MAML's popularity, a fundamental open question remains -- is the effectiveness of MAML due to the meta-initialization being primed for rapid learning (large, efficient changes in the representations) or due to feature reuse, with the meta initialization already containing high quality features? We investigate this question, via ablation studies and analysis of the latent representations, finding that feature reuse is the dominant factor. This leads to the ANIL (Almost No Inner Loop) algorithm, a simplification of MAML where we remove the inner loop for all but the (task-specific) head of a MAML-trained network. ANIL matches MAML's performance on benchmark few-shot image classification and RL and offers computational improvements over MAML. We further study the precise contributions of the head and body of the network, showing that performance on the test tasks is entirely determined by the quality of the learned features, and we can remove even the head of the network (the NIL algorithm). We conclude with a discussion of the rapid learning vs feature reuse question for meta-learning algorithms more broadly.
Generating Diverse High-Fidelity Images with VQ-VAE-2
Jun 02, 2019
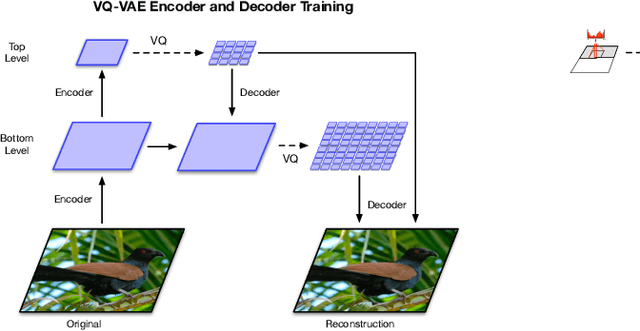

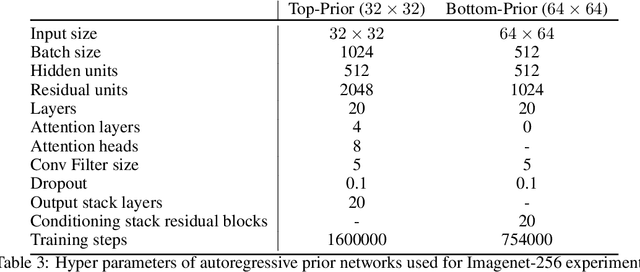
We explore the use of Vector Quantized Variational AutoEncoder (VQ-VAE) models for large scale image generation. To this end, we scale and enhance the autoregressive priors used in VQ-VAE to generate synthetic samples of much higher coherence and fidelity than possible before. We use simple feed-forward encoder and decoder networks, making our model an attractive candidate for applications where the encoding and/or decoding speed is critical. Additionally, VQ-VAE requires sampling an autoregressive model only in the compressed latent space, which is an order of magnitude faster than sampling in the pixel space, especially for large images. We demonstrate that a multi-scale hierarchical organization of VQ-VAE, augmented with powerful priors over the latent codes, is able to generate samples with quality that rivals that of state of the art Generative Adversarial Networks on multifaceted datasets such as ImageNet, while not suffering from GAN's known shortcomings such as mode collapse and lack of diversity.
REGAL: Transfer Learning For Fast Optimization of Computation Graphs
May 30, 2019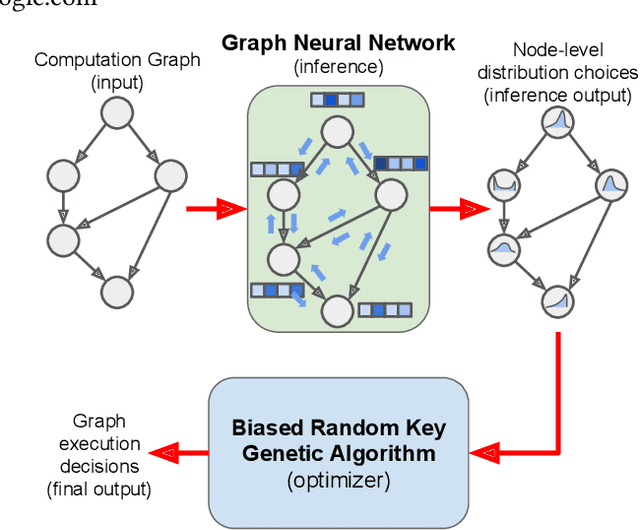
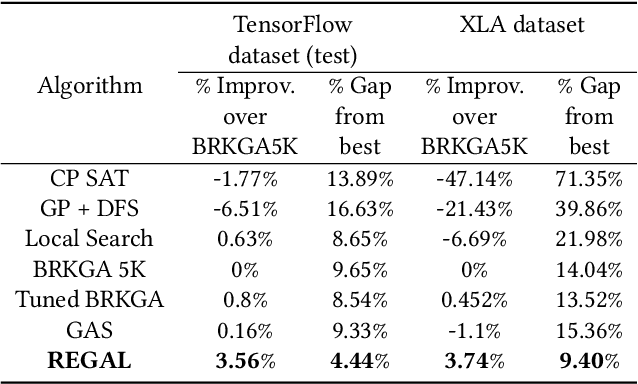
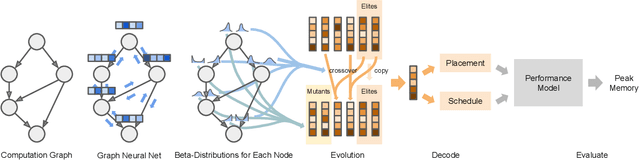
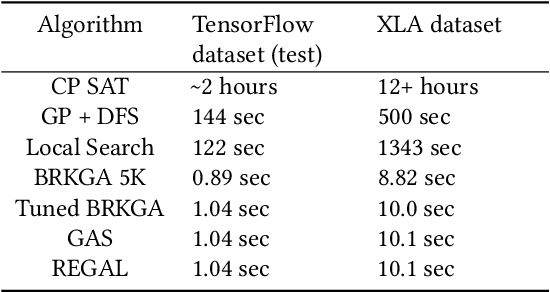
We present a deep reinforcement learning approach to optimizing the execution cost of computation graphs in a static compiler. The key idea is to combine a neural network policy with a genetic algorithm, the Biased Random-Key Genetic Algorithm (BRKGA). The policy is trained to predict, given an input graph to be optimized, the node-level probability distributions for sampling mutations and crossovers in BRKGA. Our approach, "REINFORCE-based Genetic Algorithm Learning" (REGAL), uses the policy's ability to transfer to new graphs to significantly improve the solution quality of the genetic algorithm for the same objective evaluation budget. As a concrete application, we show results for minimizing peak memory in TensorFlow graphs by jointly optimizing device placement and scheduling. REGAL achieves on average 3.56% lower peak memory than BRKGA on previously unseen graphs, outperforming all the algorithms we compare to, and giving 4.4x bigger improvement than the next best algorithm. We also evaluate REGAL on a production compiler team's performance benchmark of XLA graphs and achieve on average 3.74% lower peak memory than BRKGA, again outperforming all others. Our approach and analysis is made possible by collecting a dataset of 372 unique real-world TensorFlow graphs, more than an order of magnitude more data than previous work.
Classification Accuracy Score for Conditional Generative Models
May 26, 2019
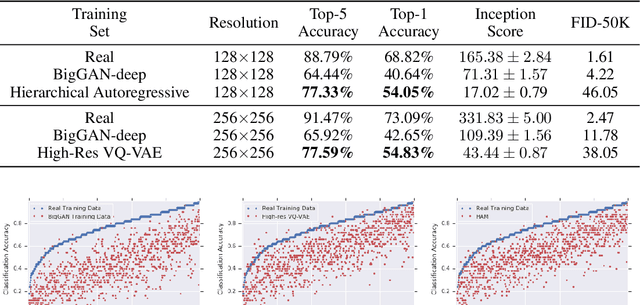
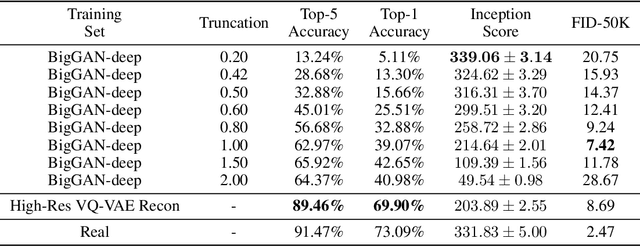

Deep generative models (DGMs) of images are now sufficiently mature that they produce nearly photorealistic samples and obtain scores similar to the data distribution on heuristics such as Frechet Inception Distance. These results, especially on large-scale datasets such as ImageNet, suggest that DGMs are learning the data distribution in a perceptually meaningful space, and can be used in downstream tasks. To test this latter hypothesis, we use class-conditional generative models from a number of model classes---variational autoencoder, autoregressive models, and generative adversarial networks---to infer the class labels of real data. We perform this inference by training the image classifier using only synthetic data, and using the classifier to predict labels on real data. The performance on this task, which we call Classification Accuracy Score (CAS), highlights some surprising results not captured by traditional metrics and comprise our contributions. First, when using a state-of-the-art GAN (BigGAN), Top-5 accuracy decreases by 41.6% compared to the original data and conditional generative models from other model classes, such as high-resolution VQ-VAE and Hierarchical Autoregressive Models, substantially outperform GANs on this benchmark. Second, CAS automatically surfaces particular classes for which generative models failed to capture the data distribution, and were previously unknown in the literature. Third, we find traditional GAN metrics such as Frechet Inception Distance neither predictive of CAS nor useful when evaluating non-GAN models. Finally, we introduce Naive Augmentation Score, a variant of CAS where the image classifier is trained on both real and synthetic data, to demonstrate that naive augmentation improves classification performance in limited circumstances. In order to facilitate better diagnoses of generative models, we open-source the proposed metric.
Graph Matching Networks for Learning the Similarity of Graph Structured Objects
May 12, 2019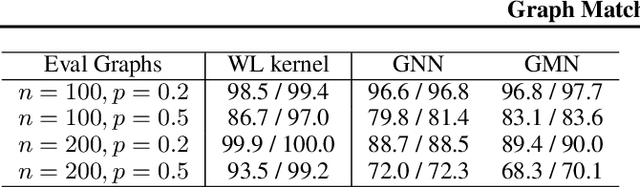
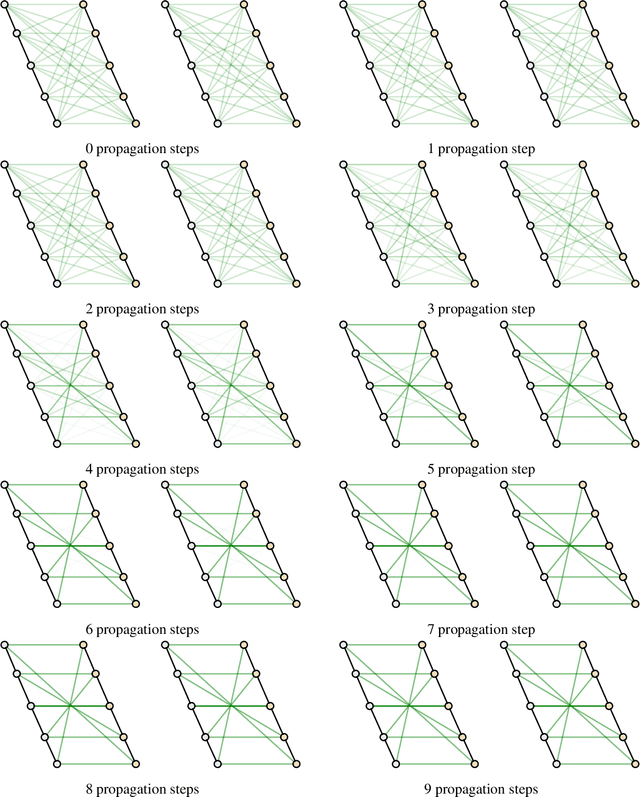
This paper addresses the challenging problem of retrieval and matching of graph structured objects, and makes two key contributions. First, we demonstrate how Graph Neural Networks (GNN), which have emerged as an effective model for various supervised prediction problems defined on structured data, can be trained to produce embedding of graphs in vector spaces that enables efficient similarity reasoning. Second, we propose a novel Graph Matching Network model that, given a pair of graphs as input, computes a similarity score between them by jointly reasoning on the pair through a new cross-graph attention-based matching mechanism. We demonstrate the effectiveness of our models on different domains including the challenging problem of control-flow-graph based function similarity search that plays an important role in the detection of vulnerabilities in software systems. The experimental analysis demonstrates that our models are not only able to exploit structure in the context of similarity learning but they can also outperform domain-specific baseline systems that have been carefully hand-engineered for these problems.
Attentive Neural Processes
Jan 17, 2019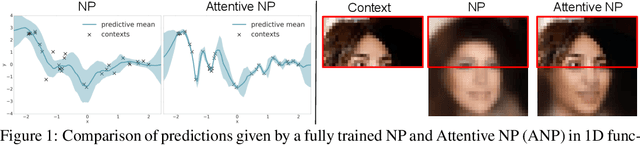
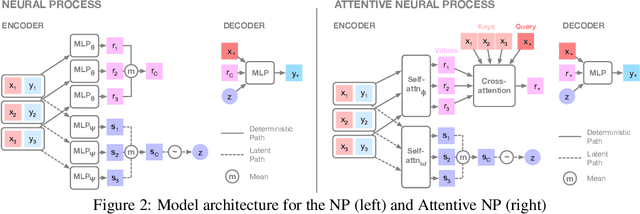
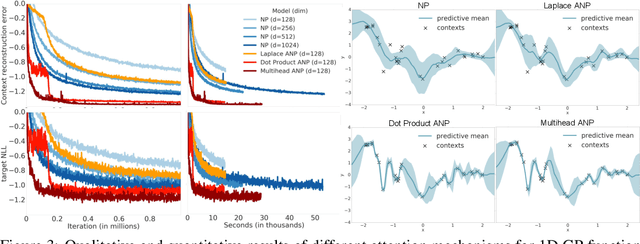
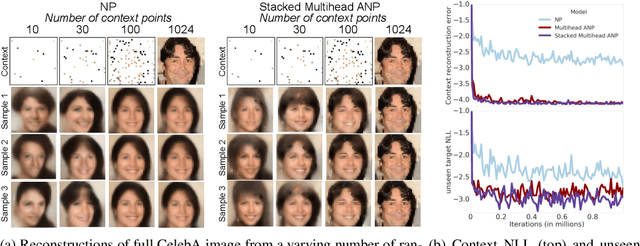
Neural Processes (NPs) (Garnelo et al 2018a;b) approach regression by learning to map a context set of observed input-output pairs to a distribution over regression functions. Each function models the distribution of the output given an input, conditioned on the context. NPs have the benefit of fitting observed data efficiently with linear complexity in the number of context input-output pairs, and can learn a wide family of conditional distributions; they learn predictive distributions conditioned on context sets of arbitrary size. Nonetheless, we show that NPs suffer a fundamental drawback of underfitting, giving inaccurate predictions at the inputs of the observed data they condition on. We address this issue by incorporating attention into NPs, allowing each input location to attend to the relevant context points for the prediction. We show that this greatly improves the accuracy of predictions, results in noticeably faster training, and expands the range of functions that can be modelled.
Preventing Posterior Collapse with delta-VAEs
Jan 10, 2019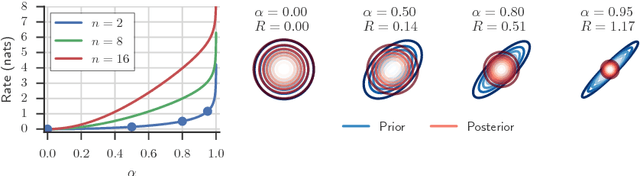
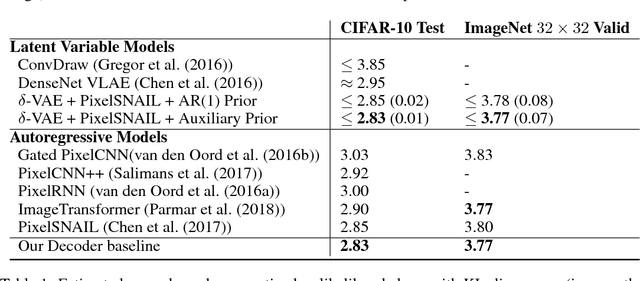
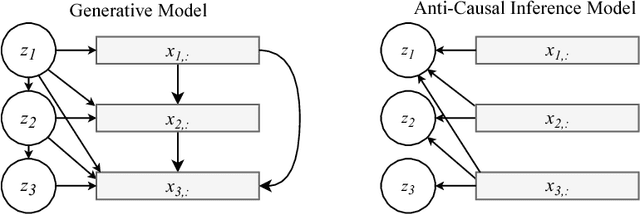

Due to the phenomenon of "posterior collapse," current latent variable generative models pose a challenging design choice that either weakens the capacity of the decoder or requires augmenting the objective so it does not only maximize the likelihood of the data. In this paper, we propose an alternative that utilizes the most powerful generative models as decoders, whilst optimising the variational lower bound all while ensuring that the latent variables preserve and encode useful information. Our proposed $\delta$-VAEs achieve this by constraining the variational family for the posterior to have a minimum distance to the prior. For sequential latent variable models, our approach resembles the classic representation learning approach of slow feature analysis. We demonstrate the efficacy of our approach at modeling text on LM1B and modeling images: learning representations, improving sample quality, and achieving state of the art log-likelihood on CIFAR-10 and ImageNet $32\times 32$.
Generating Diverse Programs with Instruction Conditioned Reinforced Adversarial Learning
Dec 03, 2018

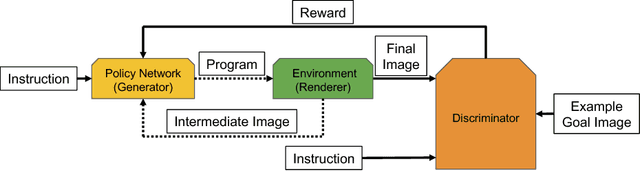
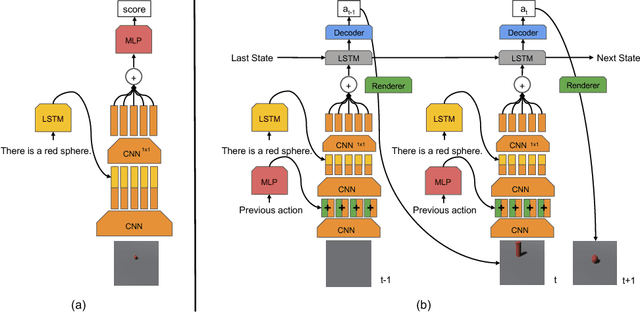
Advances in Deep Reinforcement Learning have led to agents that perform well across a variety of sensory-motor domains. In this work, we study the setting in which an agent must learn to generate programs for diverse scenes conditioned on a given symbolic instruction. Final goals are specified to our agent via images of the scenes. A symbolic instruction consistent with the goal images is used as the conditioning input for our policies. Since a single instruction corresponds to a diverse set of different but still consistent end-goal images, the agent needs to learn to generate a distribution over programs given an instruction. We demonstrate that with simple changes to the reinforced adversarial learning objective, we can learn instruction conditioned policies to achieve the corresponding diverse set of goals. Most importantly, our agent's stochastic policy is shown to more accurately capture the diversity in the goal distribution than a fixed pixel-based reward function baseline. We demonstrate the efficacy of our approach on two domains: (1) drawing MNIST digits with a paint software conditioned on instructions and (2) constructing scenes in a 3D editor that satisfies a certain instruction.