 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification Accuracy Score for Conditional Generative Models
Paper and Code
May 26, 2019
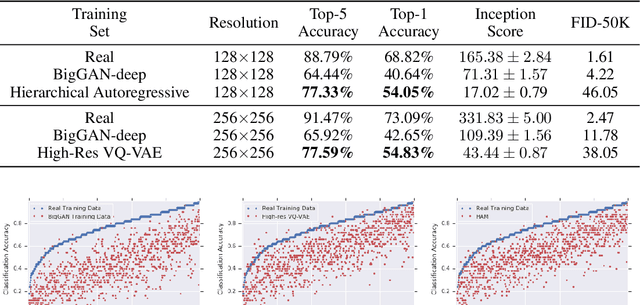
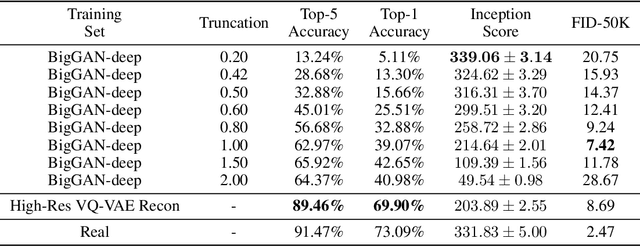

Deep generative models (DGMs) of images are now sufficiently mature that they produce nearly photorealistic samples and obtain scores similar to the data distribution on heuristics such as Frechet Inception Distance. These results, especially on large-scale datasets such as ImageNet, suggest that DGMs are learning the data distribution in a perceptually meaningful space, and can be used in downstream tasks. To test this latter hypothesis, we use class-conditional generative models from a number of model classes---variational autoencoder, autoregressive models, and generative adversarial networks---to infer the class labels of real data. We perform this inference by training the image classifier using only synthetic data, and using the classifier to predict labels on real data. The performance on this task, which we call Classification Accuracy Score (CAS), highlights some surprising results not captured by traditional metrics and comprise our contributions. First, when using a state-of-the-art GAN (BigGAN), Top-5 accuracy decreases by 41.6% compared to the original data and conditional generative models from other model classes, such as high-resolution VQ-VAE and Hierarchical Autoregressive Models, substantially outperform GANs on this benchmark. Second, CAS automatically surfaces particular classes for which generative models failed to capture the data distribution, and were previously unknown in the literature. Third, we find traditional GAN metrics such as Frechet Inception Distance neither predictive of CAS nor useful when evaluating non-GAN models. Finally, we introduce Naive Augmentation Score, a variant of CAS where the image classifier is trained on both real and synthetic data, to demonstrate that naive augmentation improves classification performance in limited circumstances. In order to facilitate better diagnoses of generative models, we open-source the proposed metric.