 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Perceiver
Feb 22, 2022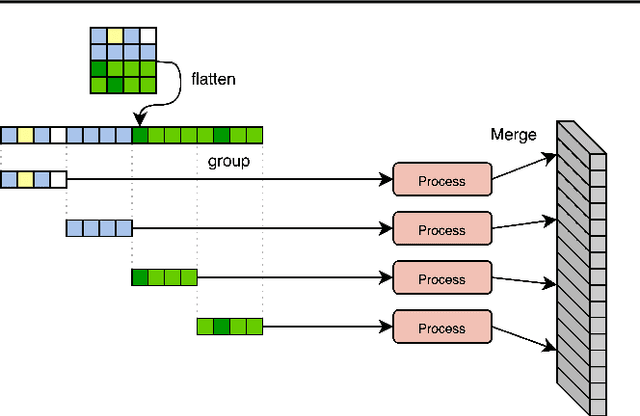

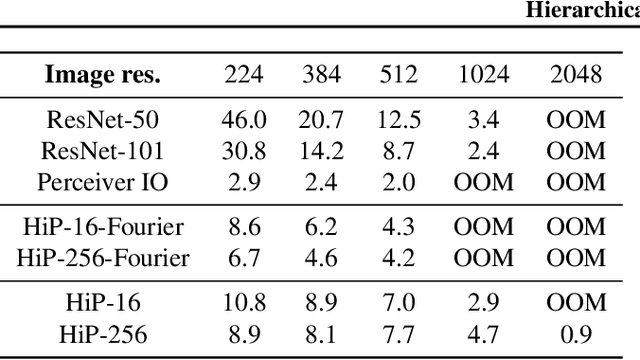

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
General-purpose, long-context autoregressive modeling with Perceiver AR
Feb 15, 2022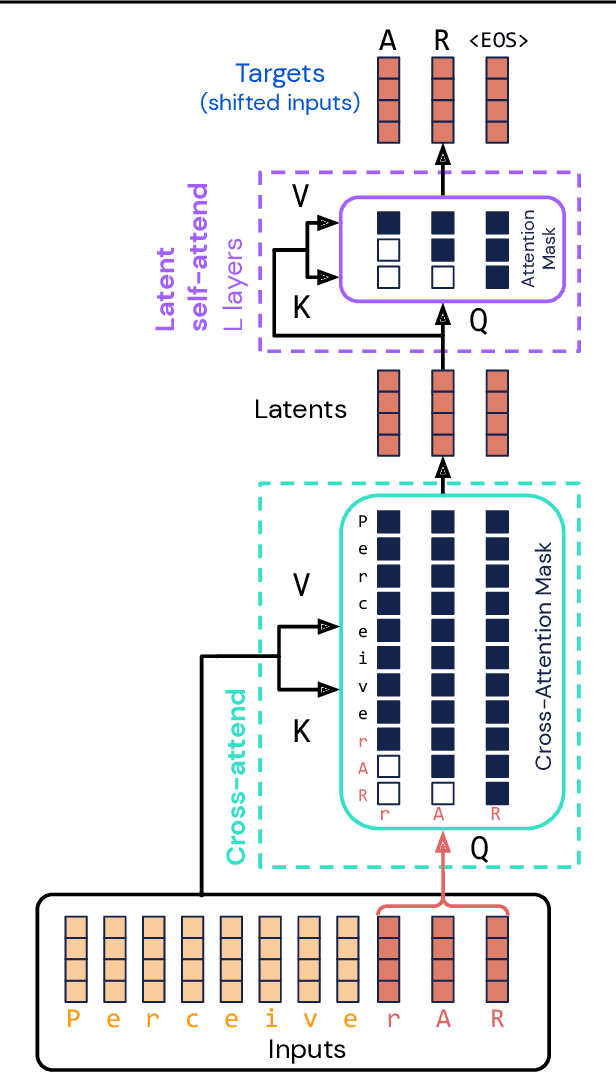
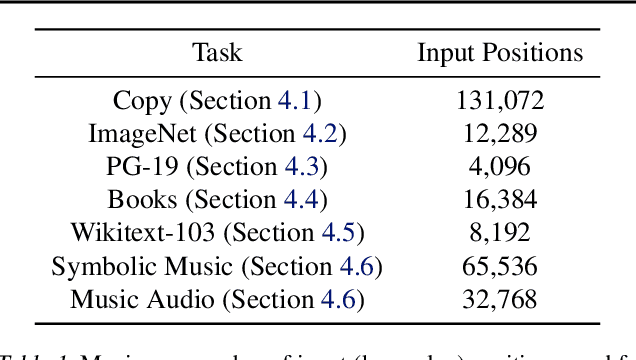
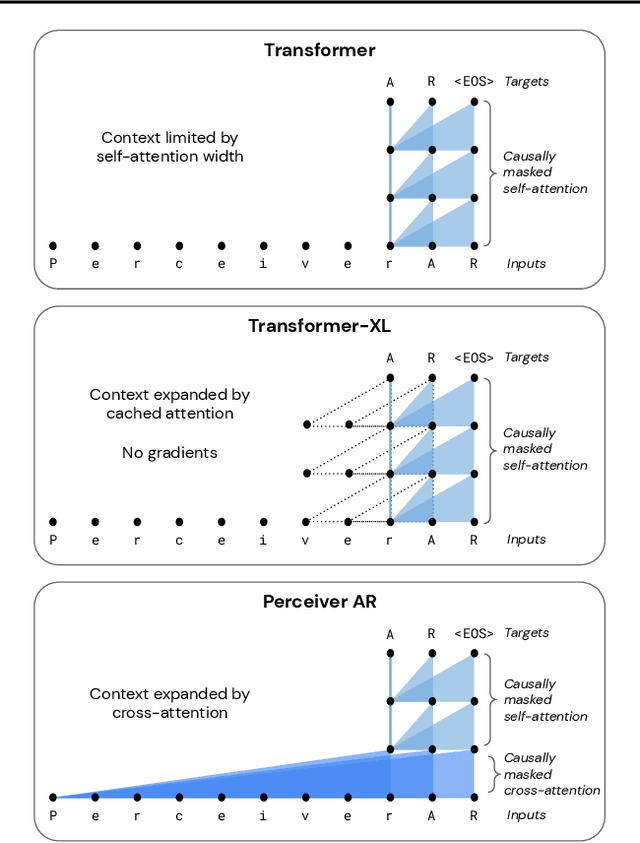
Real-world data is high-dimensional: a book, image, or musical performance can easily contain hundreds of thousands of elements even after compression. However, the most commonly used autoregressive models, Transformers, are prohibitively expensive to scale to the number of inputs and layers needed to capture this long-range structure. We develop Perceiver AR, an autoregressive, modality-agnostic architecture which uses cross-attention to map long-range inputs to a small number of latents while also maintaining end-to-end causal masking. Perceiver AR can directly attend to over a hundred thousand tokens, enabling practical long-context density estimation without the need for hand-crafted sparsity patterns or memory mechanisms. When trained on images or music, Perceiver AR generates outputs with clear long-term coherence and structure. Our architecture also obtains state-of-the-art likelihood on long-sequence benchmarks, including 64 x 64 ImageNet images and PG-19 books.
MuZero with Self-competition for Rate Control in VP9 Video Compression
Feb 14, 2022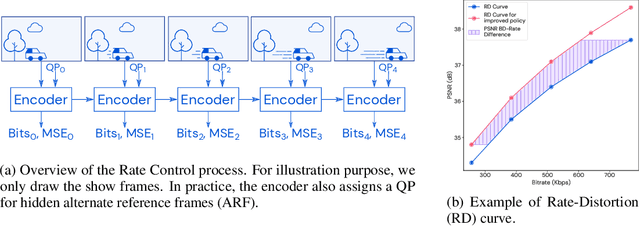

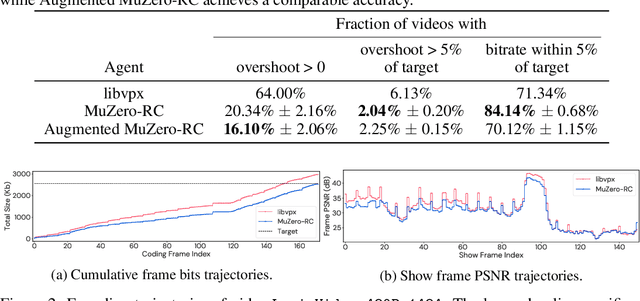
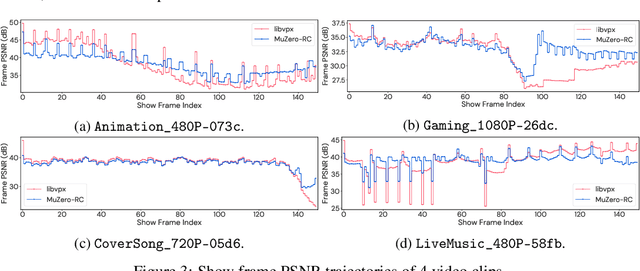
Video streaming usage has seen a significant rise as entertainment, education, and business increasingly rely on online video. Optimizing video compression has the potential to increase access and quality of content to users, and reduce energy use and costs overall. In this paper, we present an application of the MuZero algorithm to the challenge of video compression. Specifically, we target the problem of learning a rate control policy to select the quantization parameters (QP) in the encoding process of libvpx, an open source VP9 video compression library widely used by popular video-on-demand (VOD) services. We treat this as a sequential decision making problem to maximize the video quality with an episodic constraint imposed by the target bitrate. Notably, we introduce a novel self-competition based reward mechanism to solve constrained RL with variable constraint satisfaction difficulty, which is challenging for existing constrained RL methods. We demonstrate that the MuZero-based rate control achieves an average 6.28% reduction in size of the compressed videos for the same delivered video quality level (measured as PSNR BD-rate) compared to libvpx's two-pass VBR rate control policy, while having better constraint satisfaction behavior.
Unified Scaling Laws for Routed Language Models
Feb 09, 2022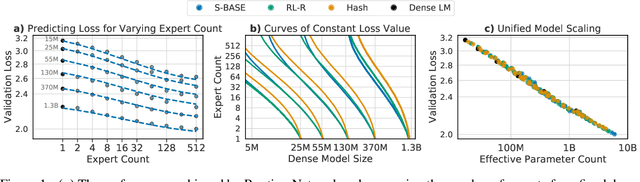

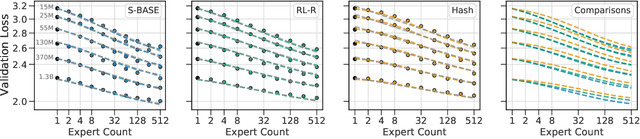
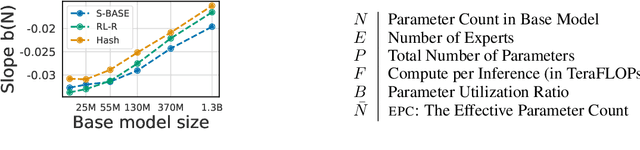
The performance of a language model has been shown to be effectively modeled as a power-law in its parameter count. Here we study the scaling behaviors of Routing Networks: architectures that conditionally use only a subset of their parameters while processing an input. For these models, parameter count and computational requirement form two independent axes along which an increase leads to better performance. In this work we derive and justify scaling laws defined on these two variables which generalize those known for standard language models and describe the performance of a wide range of routing architectures trained via three different techniques. Afterwards we provide two applications of these laws: first deriving an Effective Parameter Count along which all models scale at the same rate, and then using the scaling coefficients to give a quantitative comparison of the three routing techniques considered. Our analysis derives from an extensive evaluation of Routing Networks across five orders of magnitude of size, including models with hundreds of experts and hundreds of billions of parameters.
Improving language models by retrieving from trillions of tokens
Jan 11, 2022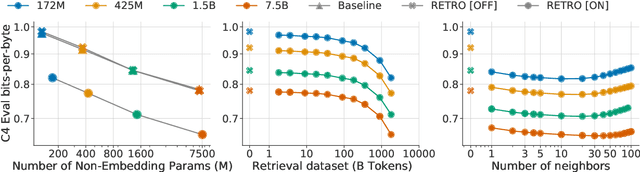

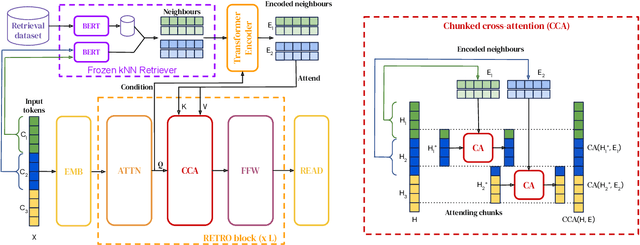

We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (RETRO) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25$\times$ fewer parameters. After fine-tuning, RETRO performance translates to downstream knowledge-intensive tasks such as question answering. RETRO combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train RETRO from scratch, yet can also rapidly RETROfit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Aug 02, 2021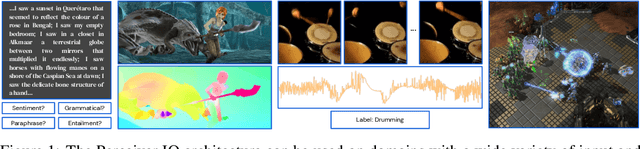
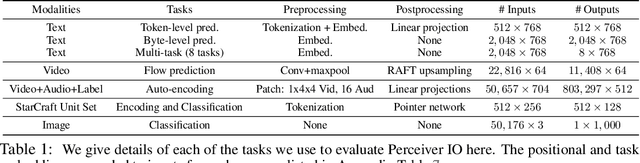
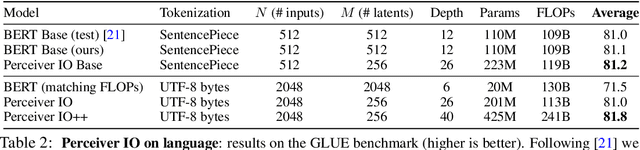
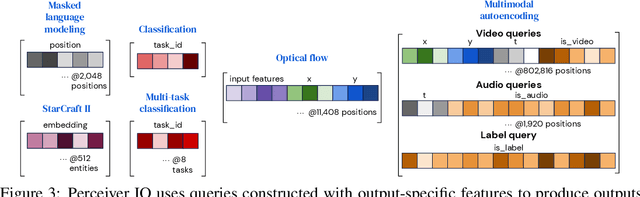
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.
WikiGraphs: A Wikipedia Text - Knowledge Graph Paired Dataset
Jul 20, 2021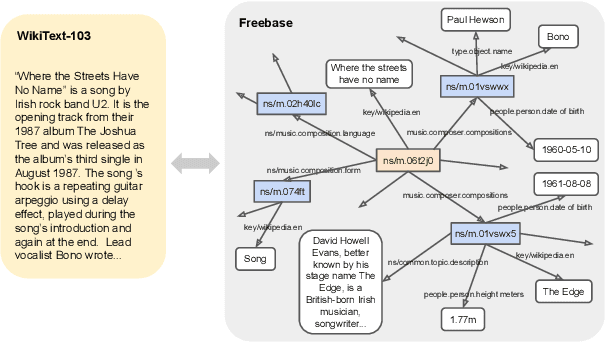
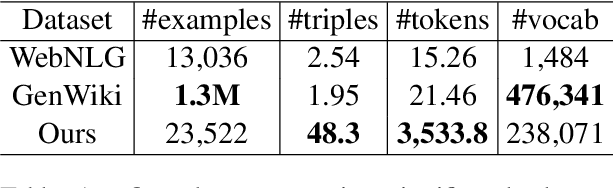
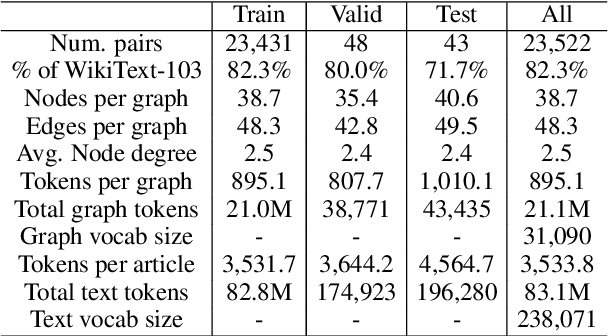
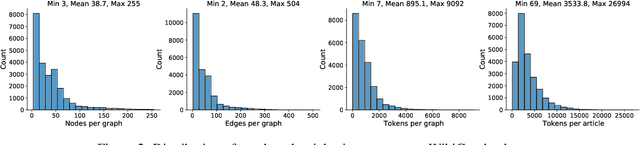
We present a new dataset of Wikipedia articles each paired with a knowledge graph, to facilitate the research in conditional text generation, graph generation and graph representation learning. Existing graph-text paired datasets typically contain small graphs and short text (1 or few sentences), thus limiting the capabilities of the models that can be learned on the data. Our new dataset WikiGraphs is collected by pairing each Wikipedia article from the established WikiText-103 benchmark (Merity et al., 2016) with a subgraph from the Freebase knowledge graph (Bollacker et al., 2008). This makes it easy to benchmark against other state-of-the-art text generative models that are capable of generating long paragraphs of coherent text. Both the graphs and the text data are of significantly larger scale compared to prior graph-text paired datasets. We present baseline graph neural network and transformer model results on our dataset for 3 tasks: graph -> text generation, graph -> text retrieval and text -> graph retrieval. We show that better conditioning on the graph provides gains in generation and retrieval quality but there is still large room for improvement.
The Benchmark Lottery
Jul 14, 2021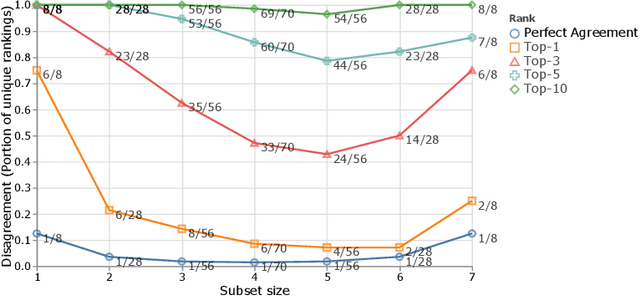

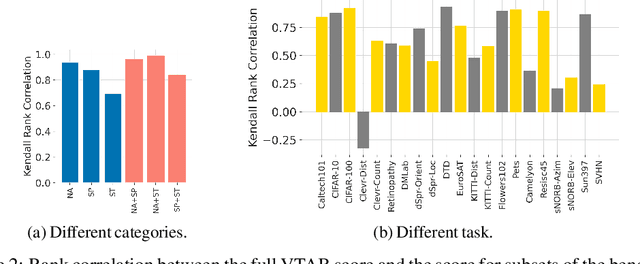
The world of empirical machine learning (ML) strongly relies on benchmarks in order to determine the relative effectiveness of different algorithms and methods. This paper proposes the notion of "a benchmark lottery" that describes the overall fragility of the ML benchmarking process. The benchmark lottery postulates that many factors, other than fundamental algorithmic superiority, may lead to a method being perceived as superior. On multiple benchmark setups that are prevalent in the ML community, we show that the relative performance of algorithms may be altered significantly simply by choosing different benchmark tasks, highlighting the fragility of the current paradigms and potential fallacious interpretation derived from benchmarking ML methods. Given that every benchmark makes a statement about what it perceives to be important, we argue that this might lead to biased progress in the community. We discuss the implications of the observed phenomena and provide recommendations on mitigating them using multiple machine learning domains and communities as use cases, including natural language processing, computer vision, information retrieval, recommender systems, and reinforcement learning.
Multimodal Few-Shot Learning with Frozen Language Models
Jul 03, 2021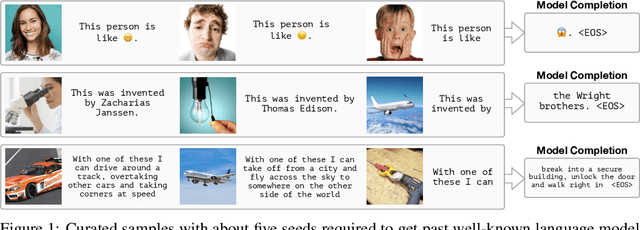
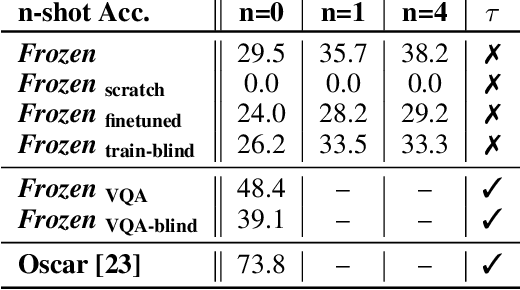
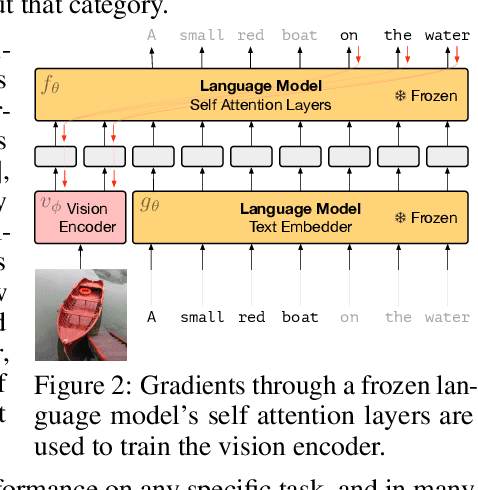
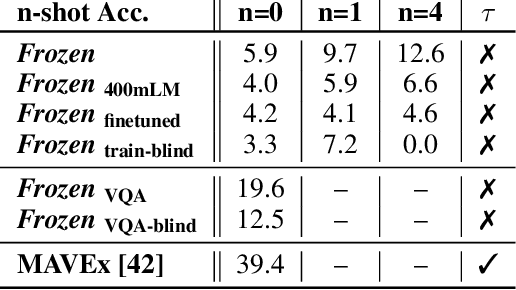
When trained at sufficient scale, auto-regressive language models exhibit the notable ability to learn a new language task after being prompted with just a few examples. Here, we present a simple, yet effective, approach for transferring this few-shot learning ability to a multimodal setting (vision and language). Using aligned image and caption data, we train a vision encoder to represent each image as a sequence of continuous embeddings, such that a pre-trained, frozen language model prompted with this prefix generates the appropriate caption. The resulting system is a multimodal few-shot learner, with the surprising ability to learn a variety of new tasks when conditioned on examples, represented as a sequence of multiple interleaved image and text embeddings. We demonstrate that it can rapidly learn words for new objects and novel visual categories, do visual question-answering with only a handful of examples, and make use of outside knowledge, by measuring a single model on a variety of established and new benchmarks.