 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Next 1000 Languages in Multilingual Machine Translation: Exploring the Synergy Between Supervised and Self-Supervised Learning
Jan 13, 2022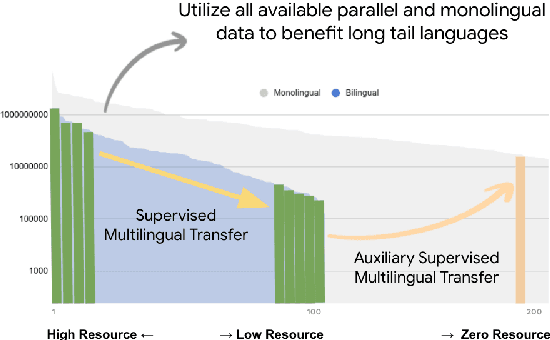
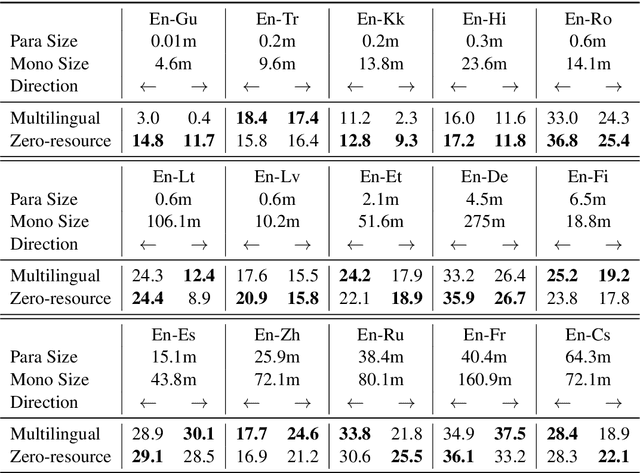
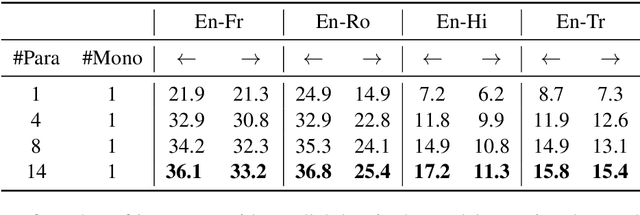
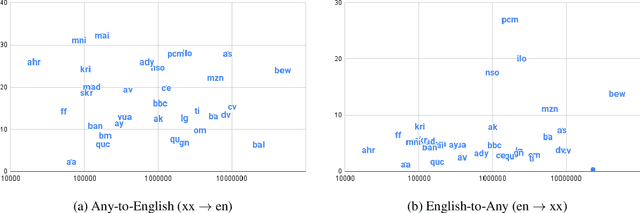
Achieving universal translation between all human language pairs is the holy-grail of machine translation (MT) research. While recent progress in massively multilingual MT is one step closer to reaching this goal, it is becoming evident that extending a multilingual MT system simply by training on more parallel data is unscalable, since the availability of labeled data for low-resource and non-English-centric language pairs is forbiddingly limited. To this end, we present a pragmatic approach towards building a multilingual MT model that covers hundreds of languages, using a mixture of supervised and self-supervised objectives, depending on the data availability for different language pairs. We demonstrate that the synergy between these two training paradigms enables the model to produce high-quality translations in the zero-resource setting, even surpassing supervised translation quality for low- and mid-resource languages. We conduct a wide array of experiments to understand the effect of the degree of multilingual supervision, domain mismatches and amounts of parallel and monolingual data on the quality of our self-supervised multilingual models. To demonstrate the scalability of the approach, we train models with over 200 languages and demonstrate high performance on zero-resource translation on several previously under-studied languages. We hope our findings will serve as a stepping stone towards enabling translation for the next thousand languages.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021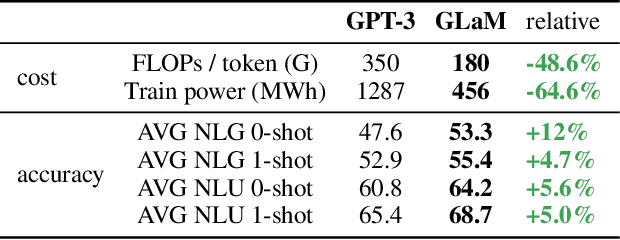
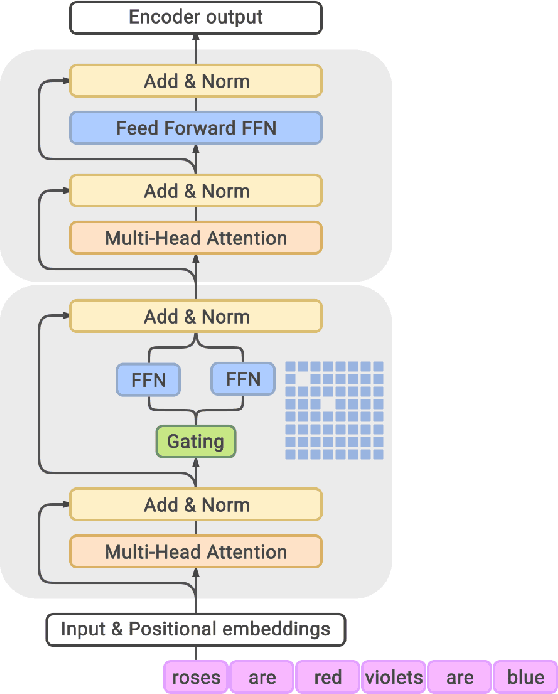
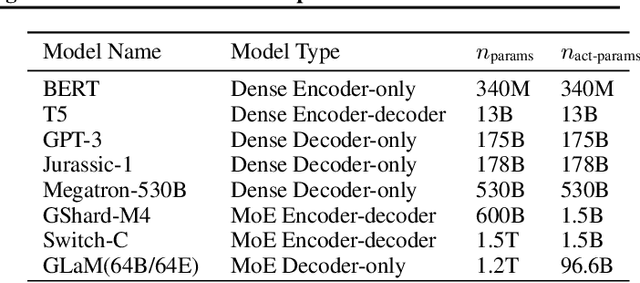
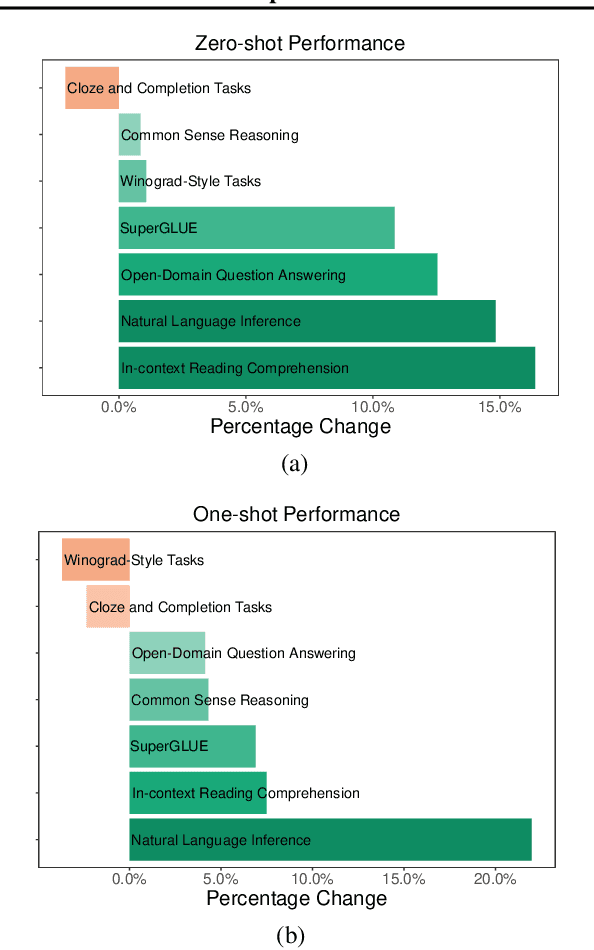
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
A Loss Curvature Perspective on Training Instability in Deep Learning
Oct 08, 2021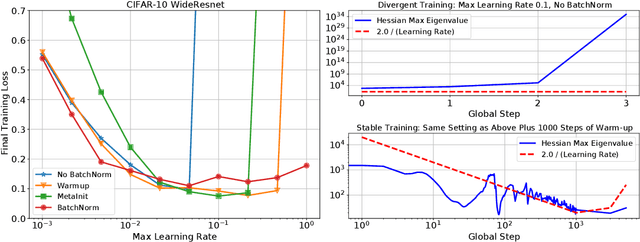

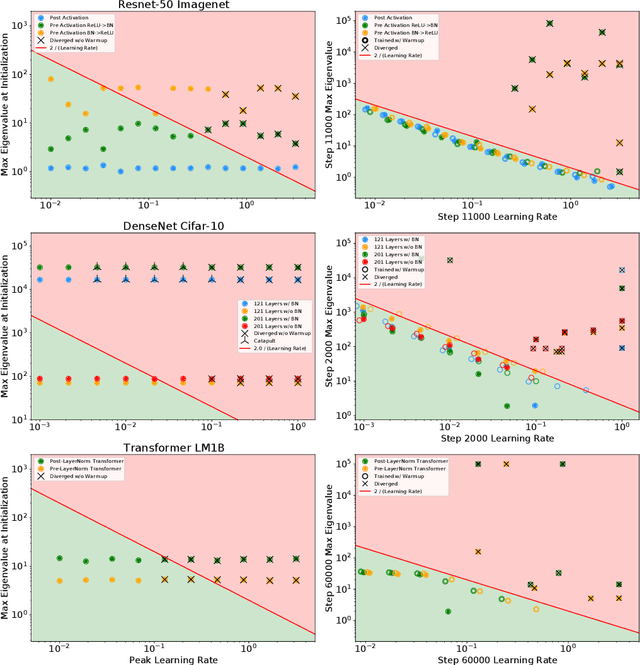

In this work, we study the evolution of the loss Hessian across many classification tasks in order to understand the effect the curvature of the loss has on the training dynamics. Whereas prior work has focused on how different learning rates affect the loss Hessian observed during training, we also analyze the effects of model initialization, architectural choices, and common training heuristics such as gradient clipping and learning rate warmup. Our results demonstrate that successful model and hyperparameter choices allow the early optimization trajectory to either avoid -- or navigate out of -- regions of high curvature and into flatter regions that tolerate a higher learning rate. Our results suggest a unifying perspective on how disparate mitigation strategies for training instability ultimately address the same underlying failure mode of neural network optimization, namely poor conditioning. Inspired by the conditioning perspective, we show that learning rate warmup can improve training stability just as much as batch normalization, layer normalization, MetaInit, GradInit, and Fixup initialization.
Beyond Distillation: Task-level Mixture-of-Experts for Efficient Inference
Sep 24, 2021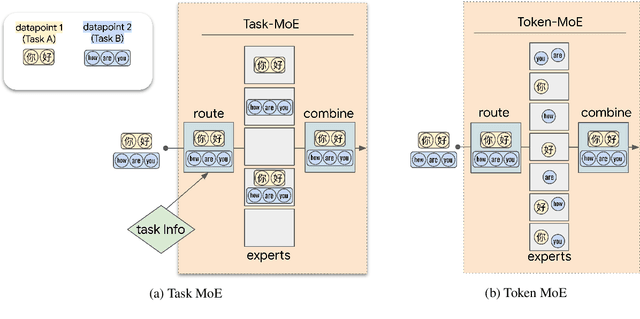
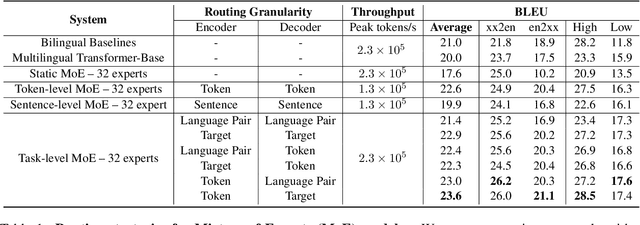
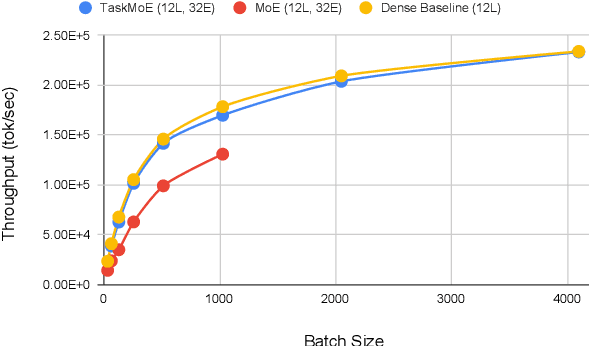

Sparse Mixture-of-Experts (MoE) has been a successful approach for scaling multilingual translation models to billions of parameters without a proportional increase in training computation. However, MoE models are prohibitively large and practitioners often resort to methods such as distillation for serving. In this work, we investigate routing strategies at different granularity (token, sentence, task) in MoE models to bypass distillation. Experiments on WMT and a web-scale dataset suggest that task-level routing (task-MoE) enables us to extract smaller, ready-to-deploy sub-networks from large sparse models. On WMT, our task-MoE with 32 experts (533M parameters) outperforms the best performing token-level MoE model (token-MoE) by +1.0 BLEU on average across 30 language pairs. The peak inference throughput is also improved by a factor of 1.9x when we route by tasks instead of tokens. While distilling a token-MoE to a smaller dense model preserves only 32% of the BLEU gains, our sub-network task-MoE, by design, preserves all the gains with the same inference cost as the distilled student model. Finally, when scaling up to 200 language pairs, our 128-expert task-MoE (13B parameters) performs competitively with a token-level counterpart, while improving the peak inference throughput by a factor of 2.6x.
Multilingual Document-Level Translation Enables Zero-Shot Transfer From Sentences to Documents
Sep 21, 2021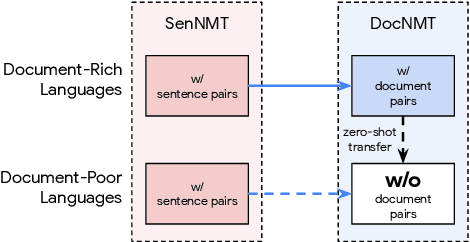

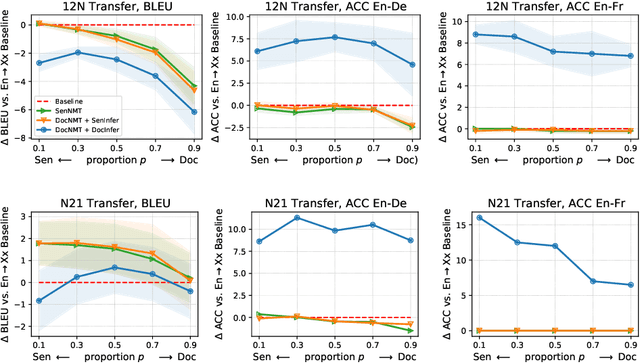
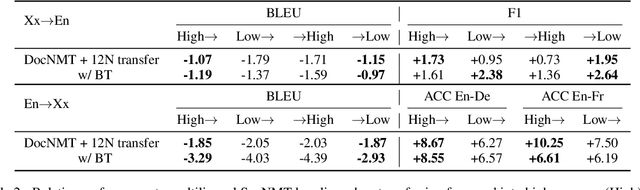
Document-level neural machine translation (DocNMT) delivers coherent translations by incorporating cross-sentence context. However, for most language pairs there's a shortage of parallel documents, although parallel sentences are readily available. In this paper, we study whether and how contextual modeling in DocNMT is transferable from sentences to documents in a zero-shot fashion (i.e. no parallel documents for student languages) through multilingual modeling. Using simple concatenation-based DocNMT, we explore the effect of 3 factors on multilingual transfer: the number of document-supervised teacher languages, the data schedule for parallel documents at training, and the data condition of parallel documents (genuine vs. backtranslated). Our experiments on Europarl-7 and IWSLT-10 datasets show the feasibility of multilingual transfer for DocNMT, particularly on document-specific metrics. We observe that more teacher languages and adequate data schedule both contribute to better transfer quality. Surprisingly, the transfer is less sensitive to the data condition and multilingual DocNMT achieves comparable performance with both back-translated and genuine document pairs.
Towards Zero-Label Language Learning
Sep 19, 2021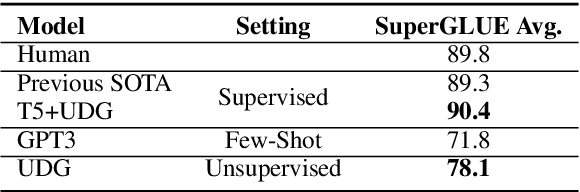
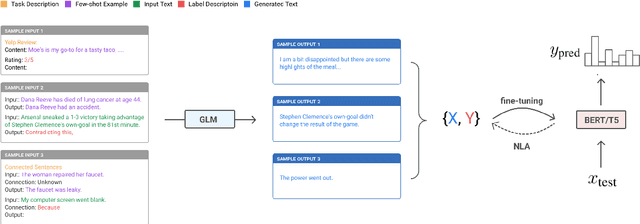
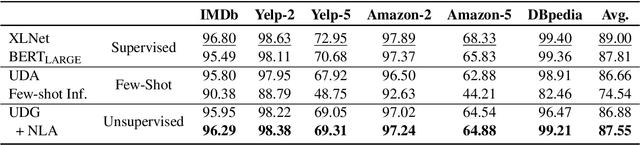
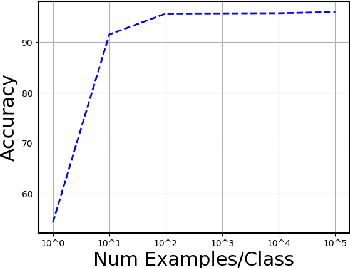
This paper explores zero-label learning in Natural Language Processing (NLP), whereby no human-annotated data is used anywhere during training and models are trained purely on synthetic data. At the core of our framework is a novel approach for better leveraging the powerful pretrained language models. Specifically, inspired by the recent success of few-shot inference on GPT-3, we present a training data creation procedure named Unsupervised Data Generation (UDG), which leverages few-shot prompts to synthesize high-quality training data without real human annotations. Our method enables zero-label learning as we train task-specific models solely on the synthetic data, yet we achieve better or comparable results from strong baseline models trained on human-labeled data. Furthermore, when mixed with labeled data, our approach serves as a highly effective data augmentation procedure, achieving new state-of-the-art results on the SuperGLUE benchmark.
Scaling Laws for Neural Machine Translation
Sep 16, 2021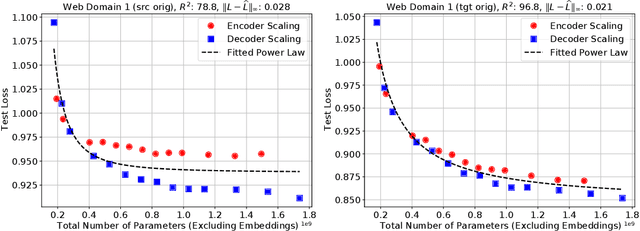
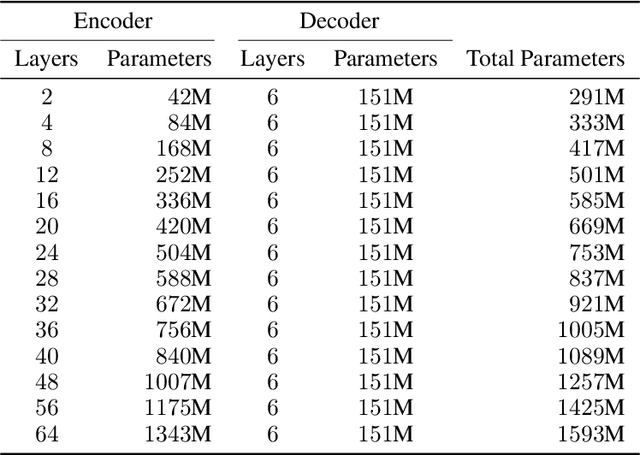
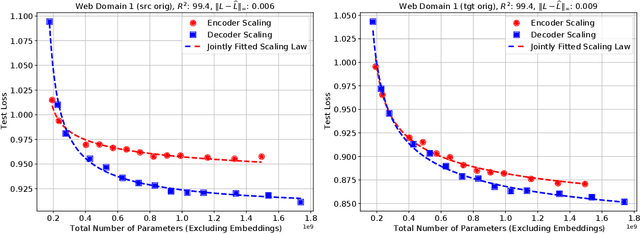
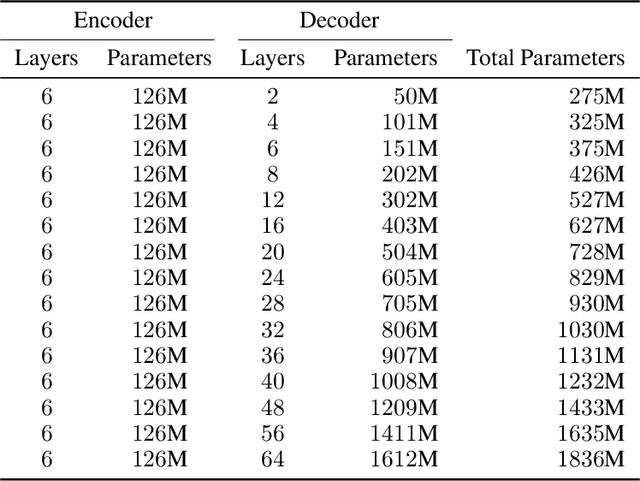
We present an empirical study of scaling properties of encoder-decoder Transformer models used in neural machine translation (NMT). We show that cross-entropy loss as a function of model size follows a certain scaling law. Specifically (i) We propose a formula which describes the scaling behavior of cross-entropy loss as a bivariate function of encoder and decoder size, and show that it gives accurate predictions under a variety of scaling approaches and languages; we show that the total number of parameters alone is not sufficient for such purposes. (ii) We observe different power law exponents when scaling the decoder vs scaling the encoder, and provide recommendations for optimal allocation of encoder/decoder capacity based on this observation. (iii) We also report that the scaling behavior of the model is acutely influenced by composition bias of the train/test sets, which we define as any deviation from naturally generated text (either via machine generated or human translated text). We observe that natural text on the target side enjoys scaling, which manifests as successful reduction of the cross-entropy loss. (iv) Finally, we investigate the relationship between the cross-entropy loss and the quality of the generated translations. We find two different behaviors, depending on the nature of the test data. For test sets which were originally translated from target language to source language, both loss and BLEU score improve as model size increases. In contrast, for test sets originally translated from source language to target language, the loss improves, but the BLEU score stops improving after a certain threshold. We release generated text from all models used in this study.
Evaluating Multiway Multilingual NMT in the Turkic Languages
Sep 13, 2021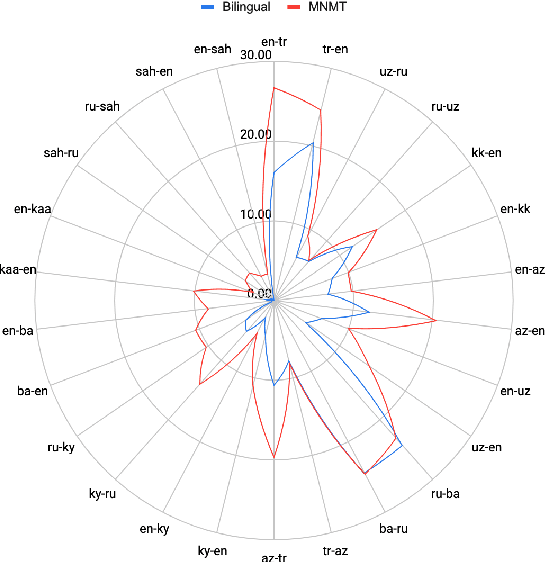

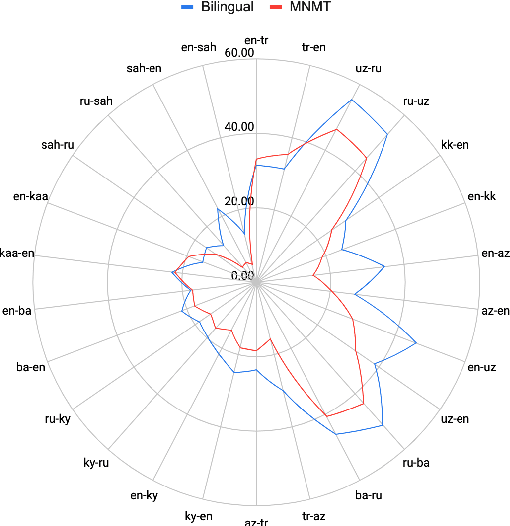
Despite the increasing number of large and comprehensive machine translation (MT) systems, evaluation of these methods in various languages has been restrained by the lack of high-quality parallel corpora as well as engagement with the people that speak these languages. In this study, we present an evaluation of state-of-the-art approaches to training and evaluating MT systems in 22 languages from the Turkic language family, most of which being extremely under-explored. First, we adopt the TIL Corpus with a few key improvements to the training and the evaluation sets. Then, we train 26 bilingual baselines as well as a multi-way neural MT (MNMT) model using the corpus and perform an extensive analysis using automatic metrics as well as human evaluations. We find that the MNMT model outperforms almost all bilingual baselines in the out-of-domain test sets and finetuning the model on a downstream task of a single pair also results in a huge performance boost in both low- and high-resource scenarios. Our attentive analysis of evaluation criteria for MT models in Turkic languages also points to the necessity for further research in this direction. We release the corpus splits, test sets as well as models to the public.
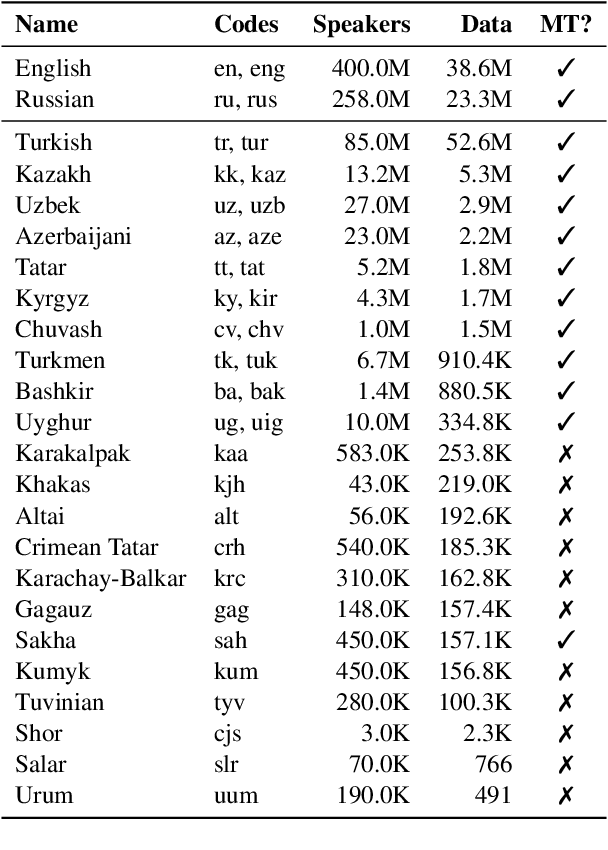
A Large-Scale Study of Machine Translation in the Turkic Languages
Sep 09, 2021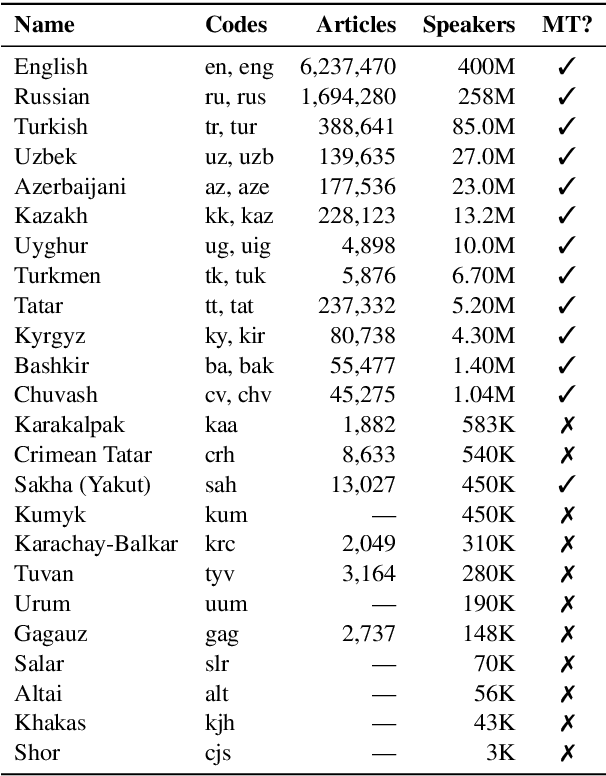
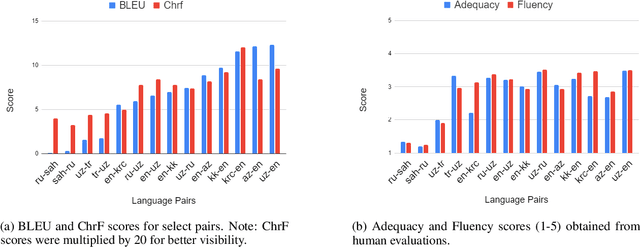
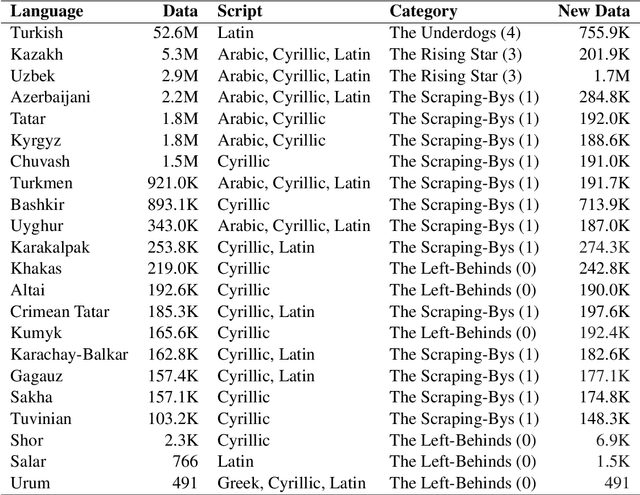

Recent advances in neural machine translation (NMT) have pushed the quality of machine translation systems to the point where they are becoming widely adopted to build competitive systems. However, there is still a large number of languages that are yet to reap the benefits of NMT. In this paper, we provide the first large-scale case study of the practical application of MT in the Turkic language family in order to realize the gains of NMT for Turkic languages under high-resource to extremely low-resource scenarios. In addition to presenting an extensive analysis that identifies the bottlenecks towards building competitive systems to ameliorate data scarcity, our study has several key contributions, including, i) a large parallel corpus covering 22 Turkic languages consisting of common public datasets in combination with new datasets of approximately 2 million parallel sentences, ii) bilingual baselines for 26 language pairs, iii) novel high-quality test sets in three different translation domains and iv) human evaluation scores. All models, scripts, and data will be released to the public.
Towards Universality in Multilingual Text Rewriting
Jul 30, 2021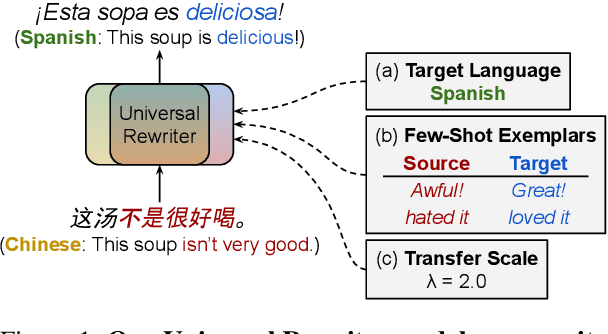
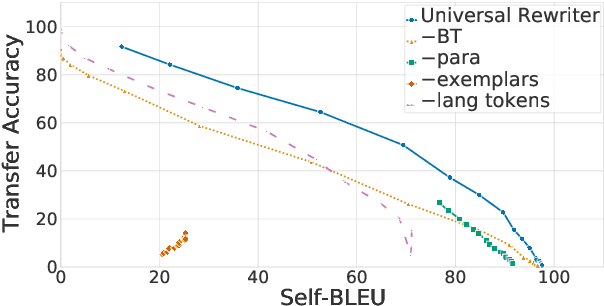

In this work, we take the first steps towards building a universal rewriter: a model capable of rewriting text in any language to exhibit a wide variety of attributes, including styles and languages, while preserving as much of the original semantics as possible. In addition to obtaining state-of-the-art results on unsupervised translation, we also demonstrate the ability to do zero-shot sentiment transfer in non-English languages using only English exemplars for sentiment. We then show that our model is able to modify multiple attributes at once, for example adjusting both language and sentiment jointly. Finally, we show that our model is capable of performing zero-shot formality-sensitive translation.