 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Agreement in Multi-party Conversational AI
Nov 06, 2023Today, conversational systems are expected to handle conversations in multi-party settings, especially within Socially Assistive Robots (SARs). However, practical usability remains difficult as there are additional challenges to overcome, such as speaker recognition, addressee recognition, and complex turn-taking. In this paper, we present our work on a multi-party conversational system, which invites two users to play a trivia quiz game. The system detects users' agreement or disagreement on a final answer and responds accordingly. Our evaluation includes both performance and user assessment results, with a focus on detecting user agreement. Our annotated transcripts and the code for the proposed system have been released open-source on GitHub.
FurChat: An Embodied Conversational Agent using LLMs, Combining Open and Closed-Domain Dialogue with Facial Expressions
Aug 30, 2023We demonstrate an embodied conversational agent that can function as a receptionist and generate a mixture of open and closed-domain dialogue along with facial expressions, by using a large language model (LLM) to develop an engaging conversation. We deployed the system onto a Furhat robot, which is highly expressive and capable of using both verbal and nonverbal cues during interaction. The system was designed specifically for the National Robotarium to interact with visitors through natural conversations, providing them with information about the facilities, research, news, upcoming events, etc. The system utilises the state-of-the-art GPT-3.5 model to generate such information along with domain-general conversations and facial expressions based on prompt engineering.
Multi-party Goal Tracking with LLMs: Comparing Pre-training, Fine-tuning, and Prompt Engineering
Aug 29, 2023


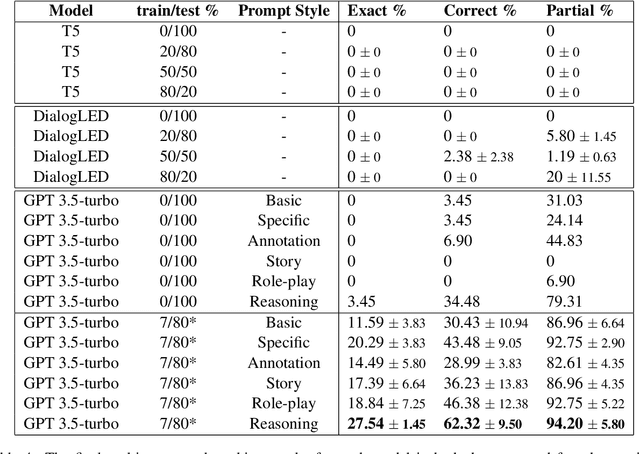
This paper evaluates the extent to which current Large Language Models (LLMs) can capture task-oriented multi-party conversations (MPCs). We have recorded and transcribed 29 MPCs between patients, their companions, and a social robot in a hospital. We then annotated this corpus for multi-party goal-tracking and intent-slot recognition. People share goals, answer each other's goals, and provide other people's goals in MPCs - none of which occur in dyadic interactions. To understand user goals in MPCs, we compared three methods in zero-shot and few-shot settings: we fine-tuned T5, created pre-training tasks to train DialogLM using LED, and employed prompt engineering techniques with GPT-3.5-turbo, to determine which approach can complete this novel task with limited data. GPT-3.5-turbo significantly outperformed the others in a few-shot setting. The `reasoning' style prompt, when given 7% of the corpus as example annotated conversations, was the best performing method. It correctly annotated 62.32% of the goal tracking MPCs, and 69.57% of the intent-slot recognition MPCs. A `story' style prompt increased model hallucination, which could be detrimental if deployed in safety-critical settings. We conclude that multi-party conversations still challenge state-of-the-art LLMs.
SimpleMTOD: A Simple Language Model for Multimodal Task-Oriented Dialogue with Symbolic Scene Representation
Jul 10, 2023



SimpleMTOD is a simple language model which recasts several sub-tasks in multimodal task-oriented dialogues as sequence prediction tasks. SimpleMTOD is built on a large-scale transformer-based auto-regressive architecture, which has already proven to be successful in uni-modal task-oriented dialogues, and effectively leverages transfer learning from pre-trained GPT-2. In-order to capture the semantics of visual scenes, we introduce both local and de-localized tokens for objects within a scene. De-localized tokens represent the type of an object rather than the specific object itself and so possess a consistent meaning across the dataset. SimpleMTOD achieves a state-of-the-art BLEU score (0.327) in the Response Generation sub-task of the SIMMC 2.0 test-std dataset while performing on par in other multimodal sub-tasks: Disambiguation, Coreference Resolution, and Dialog State Tracking. This is despite taking a minimalist approach for extracting visual (and non-visual) information. In addition the model does not rely on task-specific architectural changes such as classification heads.
An Empirical Study on the Generalization Power of Neural Representations Learned via Visual Guessing Games
Jan 31, 2021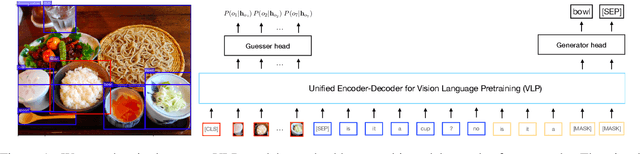


Guessing games are a prototypical instance of the "learning by interacting" paradigm. This work investigates how well an artificial agent can benefit from playing guessing games when later asked to perform on novel NLP downstream tasks such as Visual Question Answering (VQA). We propose two ways to exploit playing guessing games: 1) a supervised learning scenario in which the agent learns to mimic successful guessing games and 2) a novel way for an agent to play by itself, called Self-play via Iterated Experience Learning (SPIEL). We evaluate the ability of both procedures to generalize: an in-domain evaluation shows an increased accuracy (+7.79) compared with competitors on the evaluation suite CompGuessWhat?!; a transfer evaluation shows improved performance for VQA on the TDIUC dataset in terms of harmonic average accuracy (+5.31) thanks to more fine-grained object representations learned via SPIEL.
Encoding Syntactic Constituency Paths for Frame-Semantic Parsing with Graph Convolutional Networks
Nov 26, 2020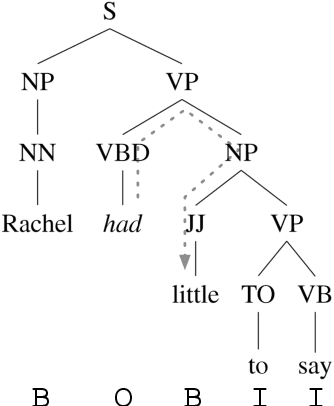
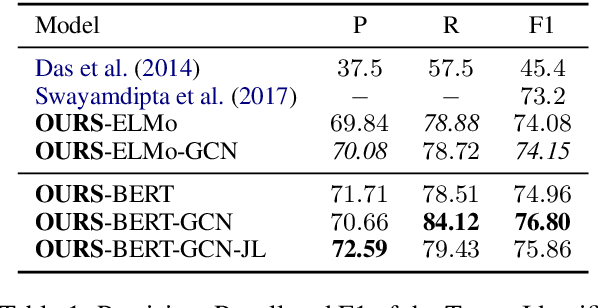
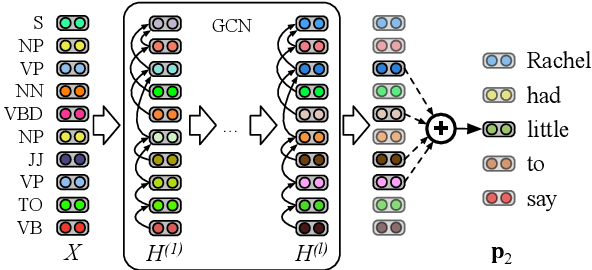
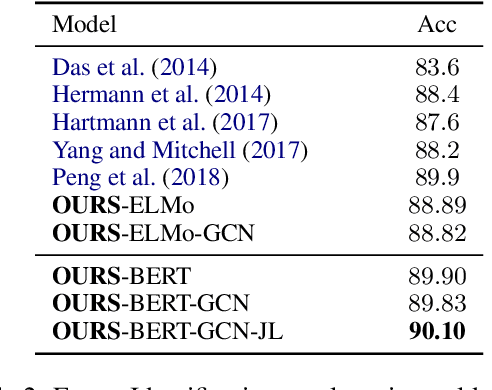
We study the problem of integrating syntactic information from constituency trees into a neural model in Frame-semantic parsing sub-tasks, namely Target Identification (TI), FrameIdentification (FI), and Semantic Role Labeling (SRL). We use a Graph Convolutional Network to learn specific representations of constituents, such that each constituent is profiled as the production grammar rule it corresponds to. We leverage these representations to build syntactic features for each word in a sentence, computed as the sum of all the constituents on the path between a word and a task-specific node in the tree, e.g. the target predicate for SRL. Our approach improves state-of-the-art results on the TI and SRL of ~1%and~3.5% points, respectively (+2.5% additional points are gained with BERT as input), when tested on FrameNet 1.5, while yielding comparable results on the CoNLL05 dataset to other syntax-aware systems.
Imagining Grounded Conceptual Representations from Perceptual Information in Situated Guessing Games
Nov 05, 2020
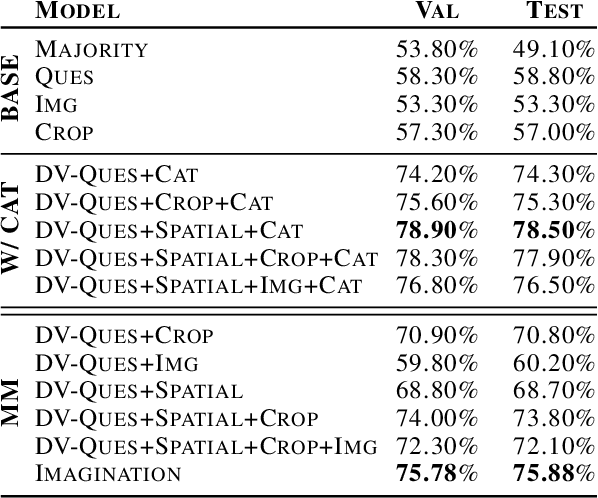

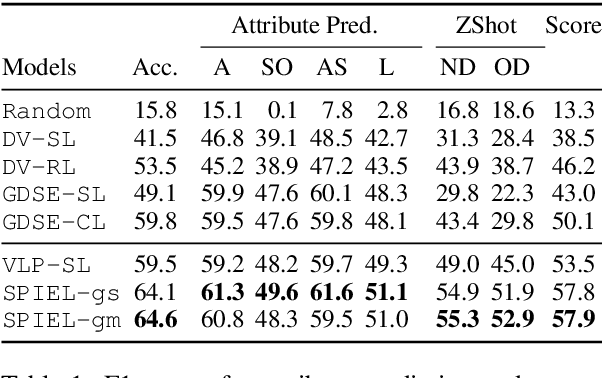
In visual guessing games, a Guesser has to identify a target object in a scene by asking questions to an Oracle. An effective strategy for the players is to learn conceptual representations of objects that are both discriminative and expressive enough to ask questions and guess correctly. However, as shown by Suglia et al. (2020), existing models fail to learn truly multi-modal representations, relying instead on gold category labels for objects in the scene both at training and inference time. This provides an unnatural performance advantage when categories at inference time match those at training time, and it causes models to fail in more realistic "zero-shot" scenarios where out-of-domain object categories are involved. To overcome this issue, we introduce a novel "imagination" module based on Regularized Auto-Encoders, that learns context-aware and category-aware latent embeddings without relying on category labels at inference time. Our imagination module outperforms state-of-the-art competitors by 8.26% gameplay accuracy in the CompGuessWhat?! zero-shot scenario (Suglia et al., 2020), and it improves the Oracle and Guesser accuracy by 2.08% and 12.86% in the GuessWhat?! benchmark, when no gold categories are available at inference time. The imagination module also boosts reasoning about object properties and attributes.
Explainable Representations of the Social State: A Model for Social Human-Robot Interactions
Oct 09, 2020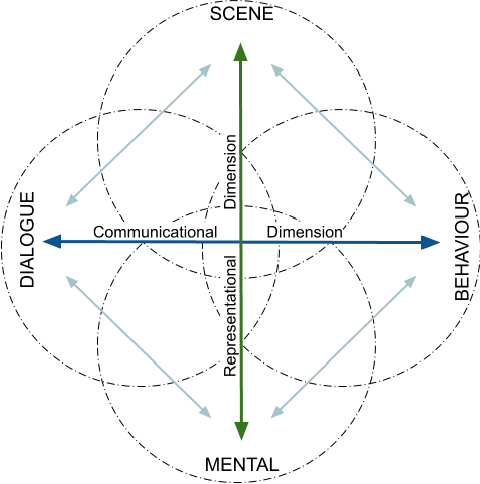
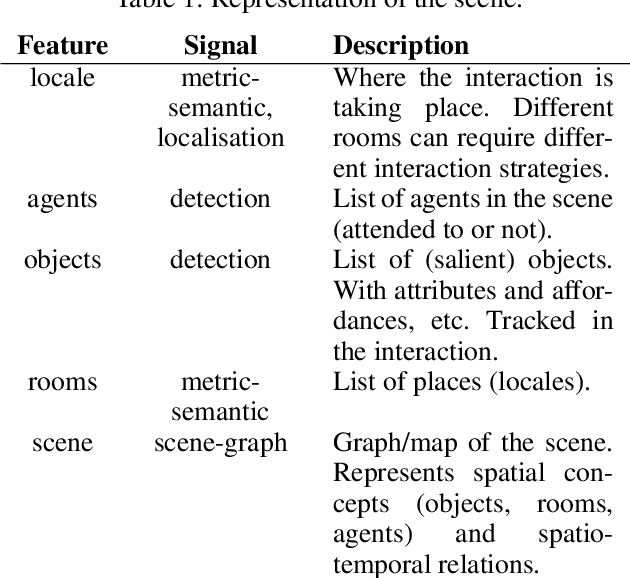


In this paper, we propose a minimum set of concepts and signals needed to track the social state during Human-Robot Interaction. We look into the problem of complex continuous interactions in a social context with multiple humans and robots, and discuss the creation of an explainable and tractable representation/model of their social interaction. We discuss these representations according to their representational and communicational properties, and organize them into four cognitive domains (scene-understanding, behaviour-profiling, mental-state, and dialogue-grounding).
CompGuessWhat?!: A Multi-task Evaluation Framework for Grounded Language Learning
Jun 03, 2020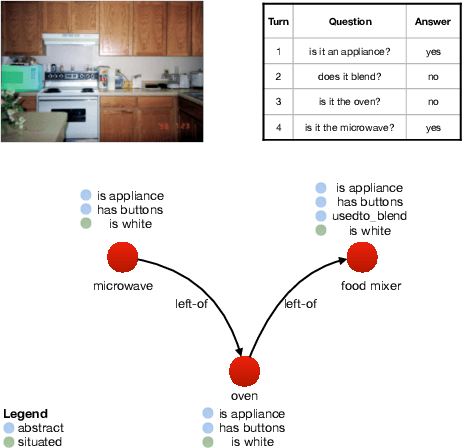
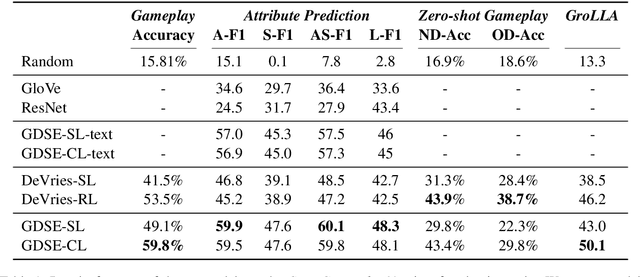


Approaches to Grounded Language Learning typically focus on a single task-based final performance measure that may not depend on desirable properties of the learned hidden representations, such as their ability to predict salient attributes or to generalise to unseen situations. To remedy this, we present GROLLA, an evaluation framework for Grounded Language Learning with Attributes with three sub-tasks: 1) Goal-oriented evaluation; 2) Object attribute prediction evaluation; and 3) Zero-shot evaluation. We also propose a new dataset CompGuessWhat?! as an instance of this framework for evaluating the quality of learned neural representations, in particular concerning attribute grounding. To this end, we extend the original GuessWhat?! dataset by including a semantic layer on top of the perceptual one. Specifically, we enrich the VisualGenome scene graphs associated with the GuessWhat?! images with abstract and situated attributes. By using diagnostic classifiers, we show that current models learn representations that are not expressive enough to encode object attributes (average F1 of 44.27). In addition, they do not learn strategies nor representations that are robust enough to perform well when novel scenes or objects are involved in gameplay (zero-shot best accuracy 50.06%).
Data-Efficient Goal-Oriented Conversation with Dialogue Knowledge Transfer Networks
Oct 03, 2019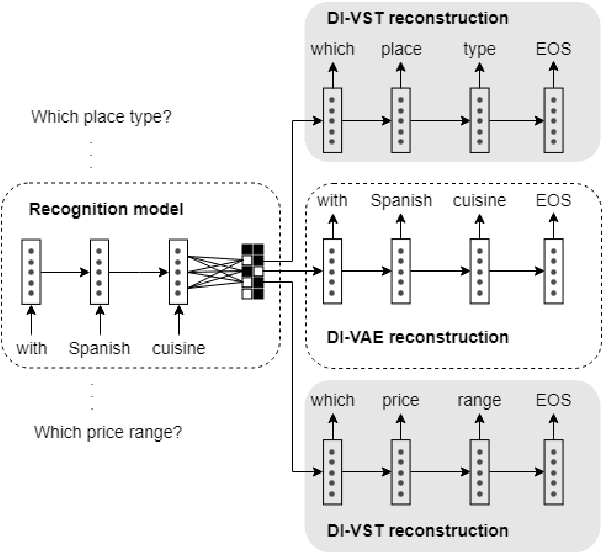
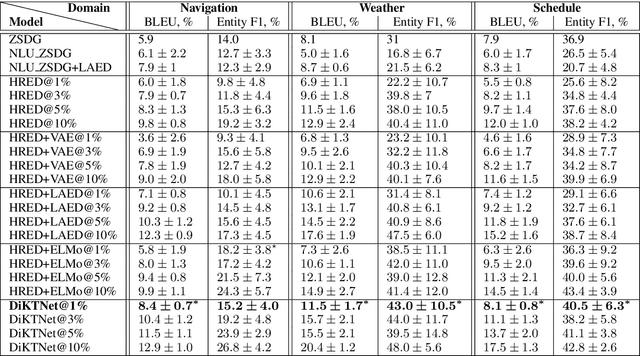
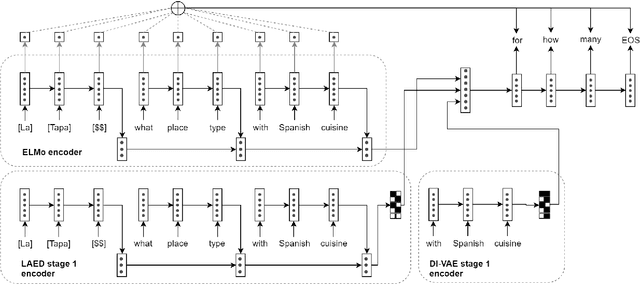

Goal-oriented dialogue systems are now being widely adopted in industry where it is of key importance to maintain a rapid prototyping cycle for new products and domains. Data-driven dialogue system development has to be adapted to meet this requirement --- therefore, reducing the amount of data and annotations necessary for training such systems is a central research problem. In this paper, we present the Dialogue Knowledge Transfer Network (DiKTNet), a state-of-the-art approach to goal-oriented dialogue generation which only uses a few example dialogues (i.e. few-shot learning), none of which has to be annotated. We achieve this by performing a 2-stage training. Firstly, we perform unsupervised dialogue representation pre-training on a large source of goal-oriented dialogues in multiple domains, the MetaLWOz corpus. Secondly, at the transfer stage, we train DiKTNet using this representation together with 2 other textual knowledge sources with different levels of generality: ELMo encoder and the main dataset's source domains. Our main dataset is the Stanford Multi-Domain dialogue corpus. We evaluate our model on it in terms of BLEU and Entity F1 scores, and show that our approach significantly and consistently improves upon a series of baseline models as well as over the previous state-of-the-art dialogue generation model, ZSDG. The improvement upon the latter --- up to 10% in Entity F1 and the average of 3% in BLEU score --- is achieved using only the equivalent of 10% of ZSDG's in-domain training data.