 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction
Oct 02, 2022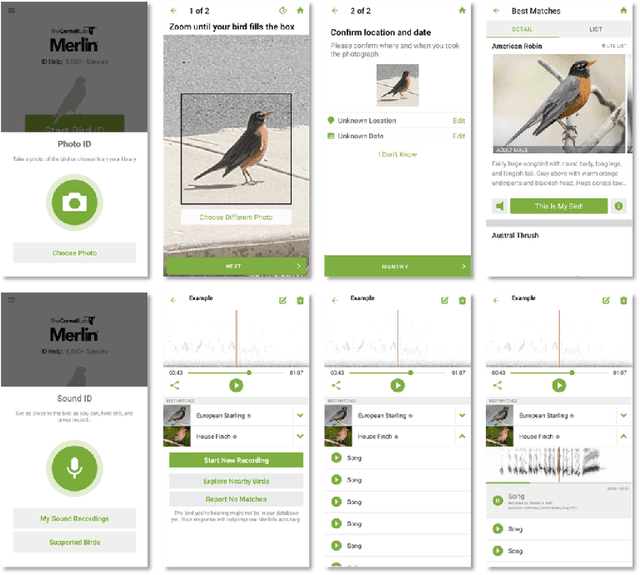

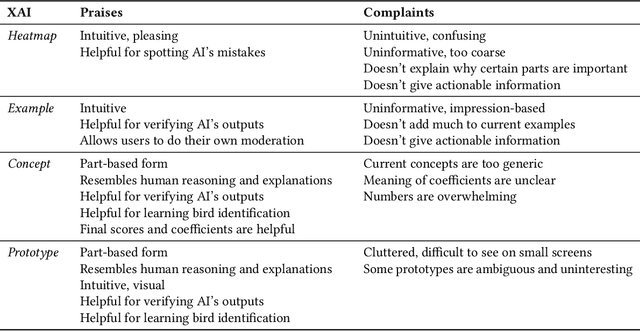
Despite the proliferation of explainable AI (XAI) methods, little is understood about end-users' explainability needs. This gap is critical, because end-users may have needs that XAI methods should but don't yet support. To address this gap and contribute to understanding how explainability can support human-AI interaction, we conducted a study of a real-world AI application via interviews with 20 end-users of Merlin, a bird-identification app. We found that people express a need for practically useful information that can improve their collaboration with the AI system, and intend to use XAI explanations for calibrating trust, improving their task skills, changing their behavior to supply better inputs to the AI system, and giving constructive feedback to developers. We also assessed end-users' perceptions of existing XAI approaches, finding that they prefer part-based explanations. Finally, we discuss implications of our findings and provide recommendations for future designs of XAI, specifically XAI for human-AI collaboration.
SiRi: A Simple Selective Retraining Mechanism for Transformer-based Visual Grounding
Jul 27, 2022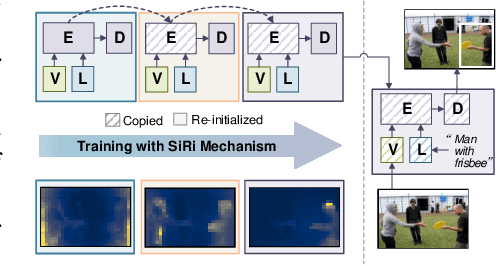
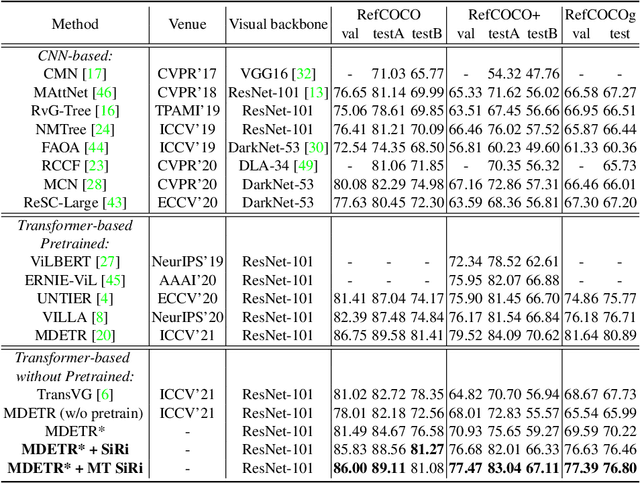
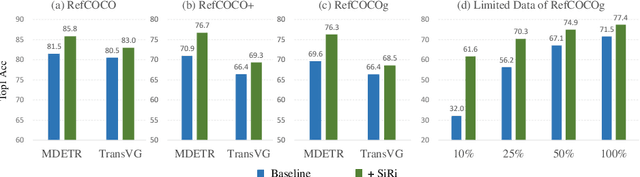
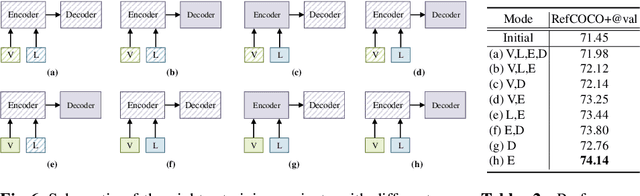
In this paper, we investigate how to achieve better visual grounding with modern vision-language transformers, and propose a simple yet powerful Selective Retraining (SiRi) mechanism for this challenging task. Particularly, SiRi conveys a significant principle to the research of visual grounding, i.e., a better initialized vision-language encoder would help the model converge to a better local minimum, advancing the performance accordingly. In specific, we continually update the parameters of the encoder as the training goes on, while periodically re-initialize rest of the parameters to compel the model to be better optimized based on an enhanced encoder. SiRi can significantly outperform previous approaches on three popular benchmarks. Specifically, our method achieves 83.04% Top1 accuracy on RefCOCO+ testA, outperforming the state-of-the-art approaches (training from scratch) by more than 10.21%. Additionally, we reveal that SiRi performs surprisingly superior even with limited training data. We also extend it to transformer-based visual grounding models and other vision-language tasks to verify the validity.
Overlooked factors in concept-based explanations: Dataset choice, concept salience, and human capability
Jul 20, 2022

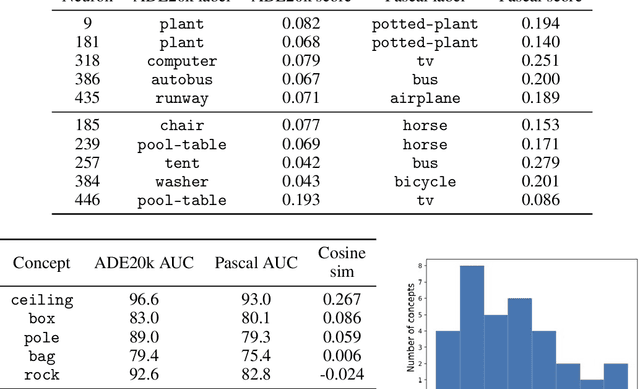
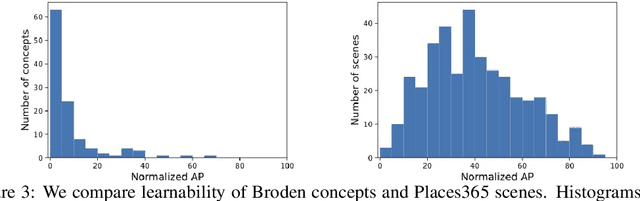
Concept-based interpretability methods aim to explain deep neural network model predictions using a predefined set of semantic concepts. These methods evaluate a trained model on a new, "probe" dataset and correlate model predictions with the visual concepts labeled in that dataset. Despite their popularity, they suffer from limitations that are not well-understood and articulated by the literature. In this work, we analyze three commonly overlooked factors in concept-based explanations. First, the choice of the probe dataset has a profound impact on the generated explanations. Our analysis reveals that different probe datasets may lead to very different explanations, and suggests that the explanations are not generalizable outside the probe dataset. Second, we find that concepts in the probe dataset are often less salient and harder to learn than the classes they claim to explain, calling into question the correctness of the explanations. We argue that only visually salient concepts should be used in concept-based explanations. Finally, while existing methods use hundreds or even thousands of concepts, our human studies reveal a much stricter upper bound of 32 concepts or less, beyond which the explanations are much less practically useful. We make suggestions for future development and analysis of concept-based interpretability methods. Code for our analysis and user interface can be found at \url{https://github.com/princetonvisualai/OverlookedFactors}
Gender Artifacts in Visual Datasets
Jun 18, 2022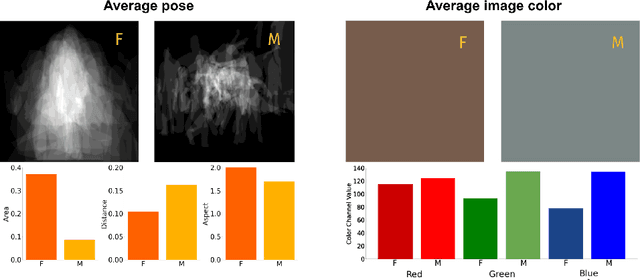

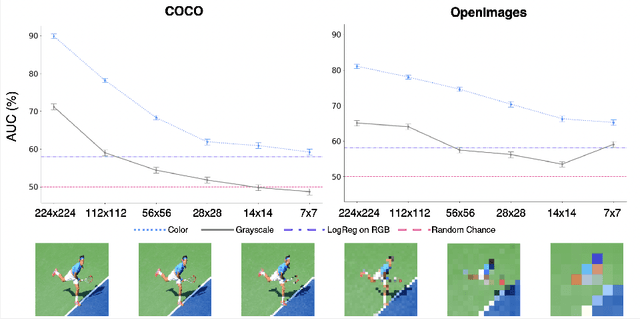
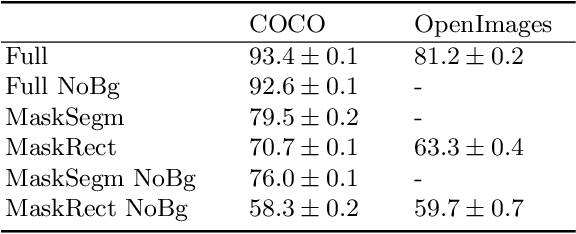
Gender biases are known to exist within large-scale visual datasets and can be reflected or even amplified in downstream models. Many prior works have proposed methods for mitigating gender biases, often by attempting to remove gender expression information from images. To understand the feasibility and practicality of these approaches, we investigate what $\textit{gender artifacts}$ exist within large-scale visual datasets. We define a $\textit{gender artifact}$ as a visual cue that is correlated with gender, focusing specifically on those cues that are learnable by a modern image classifier and have an interpretable human corollary. Through our analyses, we find that gender artifacts are ubiquitous in the COCO and OpenImages datasets, occurring everywhere from low-level information (e.g., the mean value of the color channels) to the higher-level composition of the image (e.g., pose and location of people). Given the prevalence of gender artifacts, we claim that attempts to remove gender artifacts from such datasets are largely infeasible. Instead, the responsibility lies with researchers and practitioners to be aware that the distribution of images within datasets is highly gendered and hence develop methods which are robust to these distributional shifts across groups.
ELUDE: Generating interpretable explanations via a decomposition into labelled and unlabelled features
Jun 16, 2022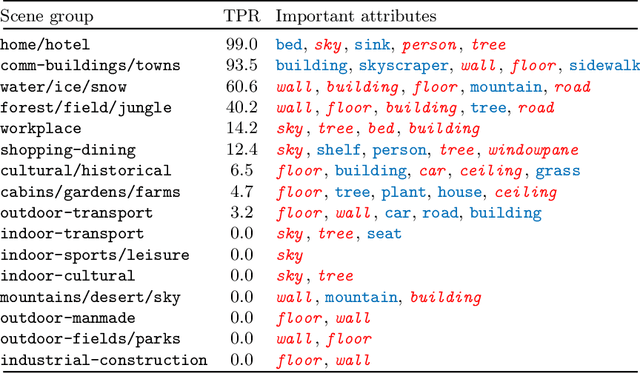
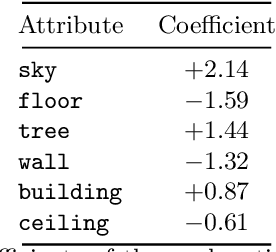
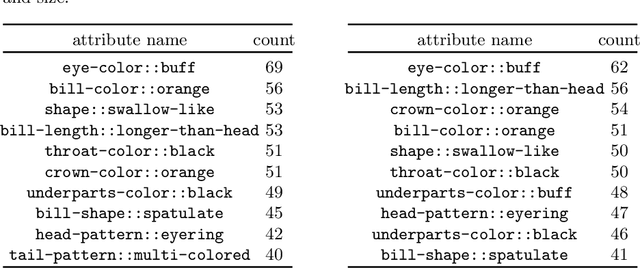

Deep learning models have achieved remarkable success in different areas of machine learning over the past decade; however, the size and complexity of these models make them difficult to understand. In an effort to make them more interpretable, several recent works focus on explaining parts of a deep neural network through human-interpretable, semantic attributes. However, it may be impossible to completely explain complex models using only semantic attributes. In this work, we propose to augment these attributes with a small set of uninterpretable features. Specifically, we develop a novel explanation framework ELUDE (Explanation via Labelled and Unlabelled DEcomposition) that decomposes a model's prediction into two parts: one that is explainable through a linear combination of the semantic attributes, and another that is dependent on the set of uninterpretable features. By identifying the latter, we are able to analyze the "unexplained" portion of the model, obtaining insights into the information used by the model. We show that the set of unlabelled features can generalize to multiple models trained with the same feature space and compare our work to two popular attribute-oriented methods, Interpretable Basis Decomposition and Concept Bottleneck, and discuss the additional insights ELUDE provides.
Remember the Past: Distilling Datasets into Addressable Memories for Neural Networks
Jun 06, 2022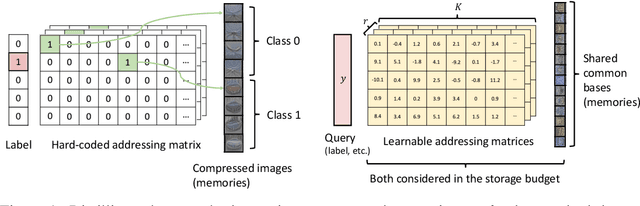

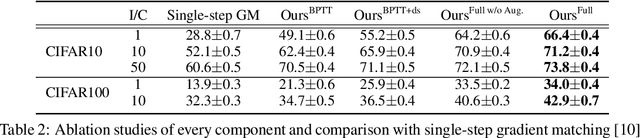
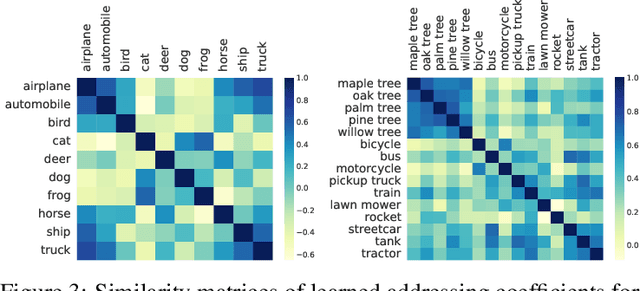
We propose an algorithm that compresses the critical information of a large dataset into compact addressable memories. These memories can then be recalled to quickly re-train a neural network and recover the performance (instead of storing and re-training on the full original dataset). Building upon the dataset distillation framework, we make a key observation that a shared common representation allows for more efficient and effective distillation. Concretely, we learn a set of bases (aka "memories") which are shared between classes and combined through learned flexible addressing functions to generate a diverse set of training examples. This leads to several benefits: 1) the size of compressed data does not necessarily grow linearly with the number of classes; 2) an overall higher compression rate with more effective distillation is achieved; and 3) more generalized queries are allowed beyond recalling the original classes. We demonstrate state-of-the-art results on the dataset distillation task across five benchmarks, including up to 16.5% and 9.7% in retained accuracy improvement when distilling CIFAR10 and CIFAR100 respectively. We then leverage our framework to perform continual learning, achieving state-of-the-art results on four benchmarks, with 23.2% accuracy improvement on MANY.
Towards Intersectionality in Machine Learning: Including More Identities, Handling Underrepresentation, and Performing Evaluation
May 10, 2022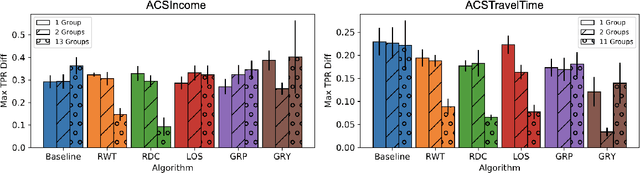
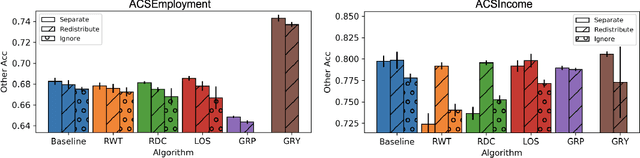
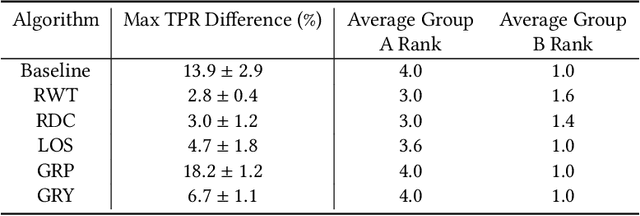
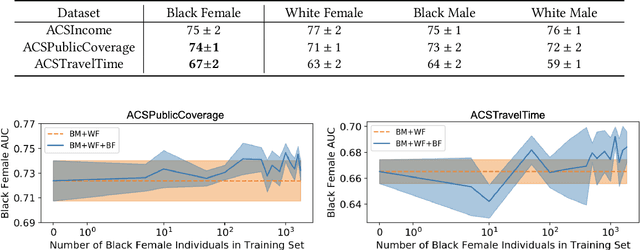
Research in machine learning fairness has historically considered a single binary demographic attribute; however, the reality is of course far more complicated. In this work, we grapple with questions that arise along three stages of the machine learning pipeline when incorporating intersectionality as multiple demographic attributes: (1) which demographic attributes to include as dataset labels, (2) how to handle the progressively smaller size of subgroups during model training, and (3) how to move beyond existing evaluation metrics when benchmarking model fairness for more subgroups. For each question, we provide thorough empirical evaluation on tabular datasets derived from the US Census, and present constructive recommendations for the machine learning community. First, we advocate for supplementing domain knowledge with empirical validation when choosing which demographic attribute labels to train on, while always evaluating on the full set of demographic attributes. Second, we warn against using data imbalance techniques without considering their normative implications and suggest an alternative using the structure in the data. Third, we introduce new evaluation metrics which are more appropriate for the intersectional setting. Overall, we provide substantive suggestions on three necessary (albeit not sufficient!) considerations when incorporating intersectionality into machine learning.
CARETS: A Consistency And Robustness Evaluative Test Suite for VQA
Mar 15, 2022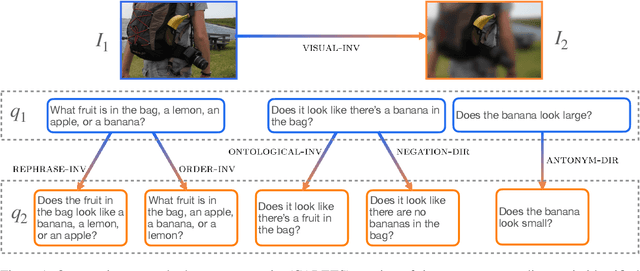
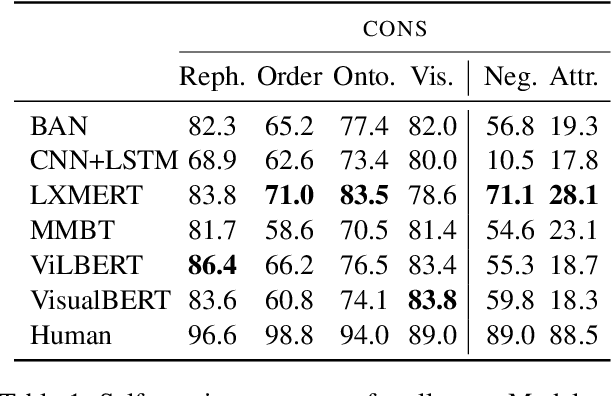
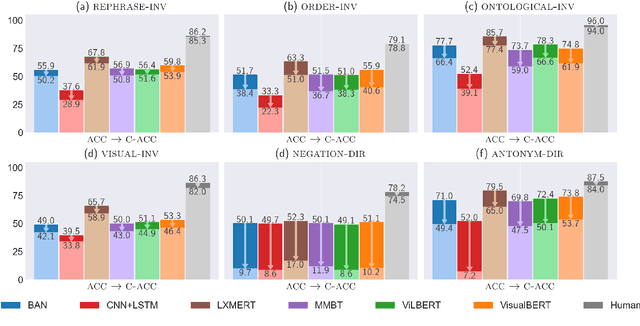
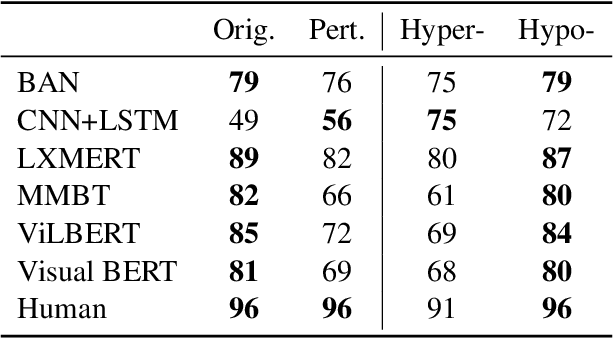
We introduce CARETS, a systematic test suite to measure consistency and robustness of modern VQA models through a series of six fine-grained capability tests. In contrast to existing VQA test sets, CARETS features balanced question generation to create pairs of instances to test models, with each pair focusing on a specific capability such as rephrasing, logical symmetry or image obfuscation. We evaluate six modern VQA systems on CARETS and identify several actionable weaknesses in model comprehension, especially with concepts such as negation, disjunction, or hypernym invariance. Interestingly, even the most sophisticated models are sensitive to aspects such as swapping the order of terms in a conjunction or varying the number of answer choices mentioned in the question. We release CARETS to be used as an extensible tool for evaluating multi-modal model robustness.
HIVE: Evaluating the Human Interpretability of Visual Explanations
Jan 10, 2022
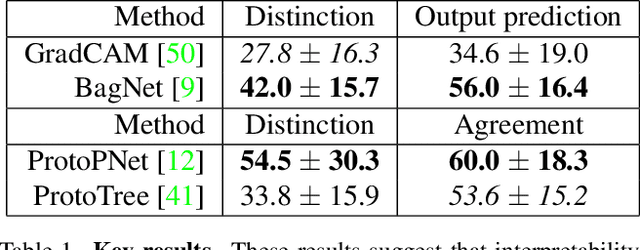

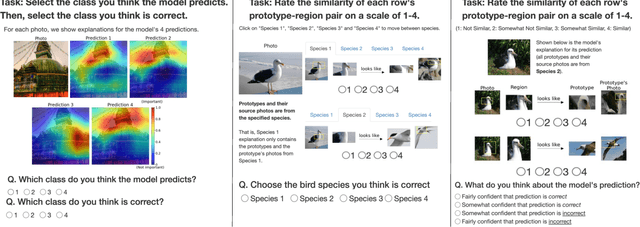
As machine learning is increasingly applied to high-impact, high-risk domains, there have been a number of new methods aimed at making AI models more human interpretable. Despite the recent growth of interpretability work, there is a lack of systematic evaluation of proposed techniques. In this work, we propose a novel human evaluation framework HIVE (Human Interpretability of Visual Explanations) for diverse interpretability methods in computer vision; to the best of our knowledge, this is the first work of its kind. We argue that human studies should be the gold standard in properly evaluating how interpretable a method is to human users. While human studies are often avoided due to challenges associated with cost, study design, and cross-method comparison, we describe how our framework mitigates these issues and conduct IRB-approved studies of four methods that represent the diversity of interpretability works: GradCAM, BagNet, ProtoPNet, and ProtoTree. Our results suggest that explanations (regardless of if they are actually correct) engender human trust, yet are not distinct enough for users to distinguish between correct and incorrect predictions. Lastly, we also open-source our framework to enable future studies and to encourage more human-centered approaches to interpretability.
Multi-query Video Retrieval
Jan 10, 2022
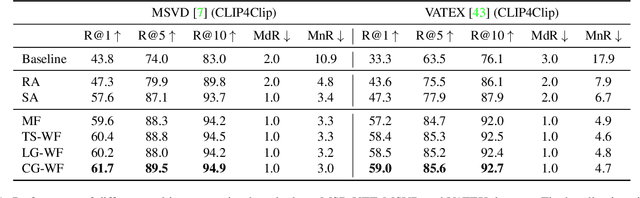
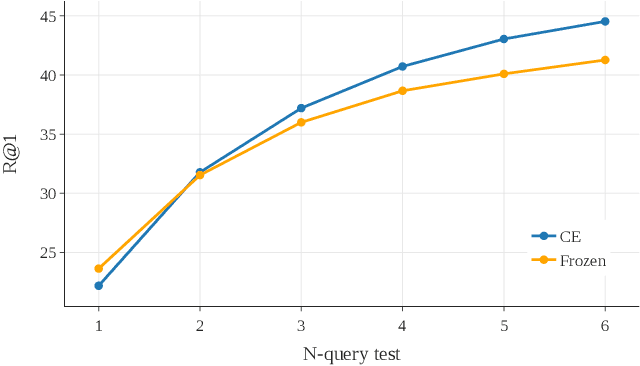
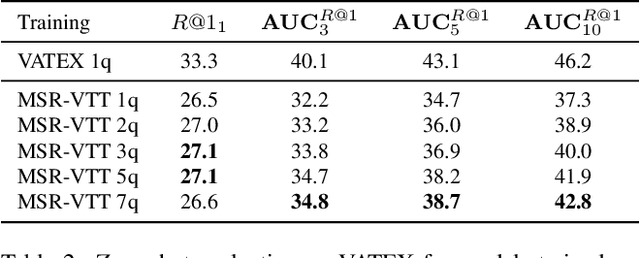
Retrieving target videos based on text descriptions is a task of great practical value and has received increasing attention over the past few years. In this paper, we focus on the less-studied setting of multi-query video retrieval, where multiple queries are provided to the model for searching over the video archive. We first show that the multi-query retrieval task is more pragmatic and representative of real-world use cases and better evaluates retrieval capabilities of current models, thereby deserving of further investigation alongside the more prevalent single-query retrieval setup. We then propose several new methods for leveraging multiple queries at training time to improve over simply combining similarity outputs of multiple queries from regular single-query trained models. Our models consistently outperform several competitive baselines over three different datasets. For instance, Recall@1 can be improved by 4.7 points on MSR-VTT, 4.1 points on MSVD and 11.7 points on VATEX over a strong baseline built on the state-of-the-art CLIP4Clip model. We believe further modeling efforts will bring new insights to this direction and spark new systems that perform better in real-world video retrieval applications. Code is available at https://github.com/princetonvisualai/MQVR.