 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL Unplugged: Benchmarks for Offline Reinforcement Learning
Jul 02, 2020
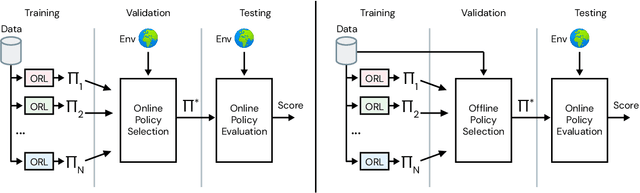
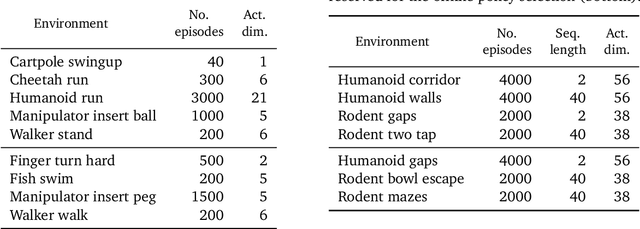
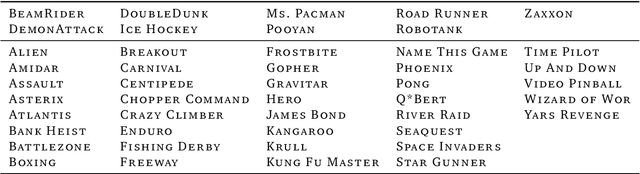
Offline methods for reinforcement learning have a potential to help bridge the gap between reinforcement learning research and real-world applications. They make it possible to learn policies from offline datasets, thus overcoming concerns associated with online data collection in the real-world, including cost, safety, or ethical concerns. In this paper, we propose a benchmark called RL Unplugged to evaluate and compare offline RL methods. RL Unplugged includes data from a diverse range of domains including games ({\em e.g.,} Atari benchmark) and simulated motor control problems ({\em e.g.,} DM Control Suite). The datasets include domains that are partially or fully observable, use continuous or discrete actions, and have stochastic vs. deterministic dynamics. We propose detailed evaluation protocols for each domain in RL Unplugged and provide an extensive analysis of supervised learning and offline RL methods using these protocols. We will release data for all our tasks and open-source all algorithms presented in this paper. We hope that our suite of benchmarks will increase the reproducibility of experiments and make it possible to study challenging tasks with a limited computational budget, thus making RL research both more systematic and more accessible across the community. Moving forward, we view RL Unplugged as a living benchmark suite that will evolve and grow with datasets contributed by the research community and ourselves. Our project page is available on github (https://git.io/JJUhd).
Deployment-Efficient Reinforcement Learning via Model-Based Offline Optimization
Jun 23, 2020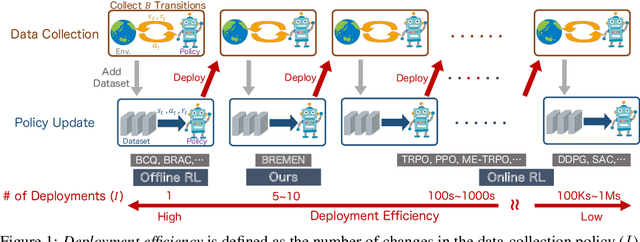
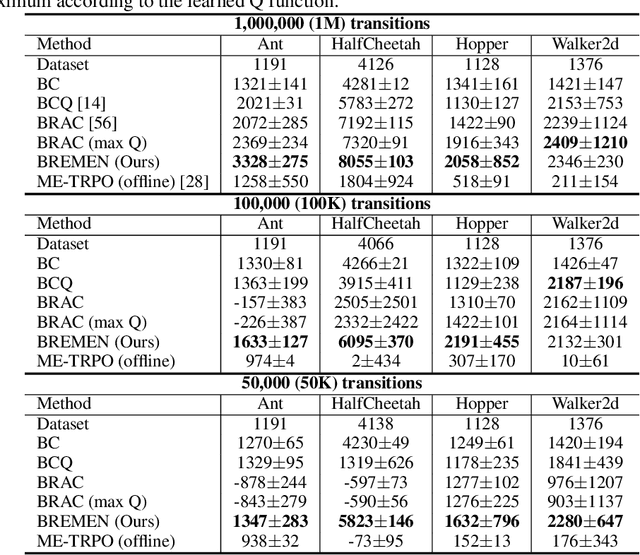
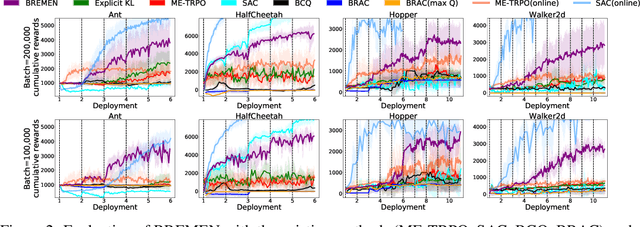

Most reinforcement learning (RL) algorithms assume online access to the environment, in which one may readily interleave updates to the policy with experience collection using that policy. However, in many real-world applications such as health, education, dialogue agents, and robotics, the cost or potential risk of deploying a new data-collection policy is high, to the point that it can become prohibitive to update the data-collection policy more than a few times during learning. With this view, we propose a novel concept of deployment efficiency, measuring the number of distinct data-collection policies that are used during policy learning. We observe that na\"{i}vely applying existing model-free offline RL algorithms recursively does not lead to a practical deployment-efficient and sample-efficient algorithm. We propose a novel model-based algorithm, Behavior-Regularized Model-ENsemble (BREMEN) that can effectively optimize a policy offline using 10-20 times fewer data than prior works. Furthermore, the recursive application of BREMEN is able to achieve impressive deployment efficiency while maintaining the same or better sample efficiency, learning successful policies from scratch on simulated robotic environments with only 5-10 deployments, compared to typical values of hundreds to millions in standard RL baselines. Codes and pre-trained models are available at https://github.com/matsuolab/BREMEN .
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Apr 20, 2020
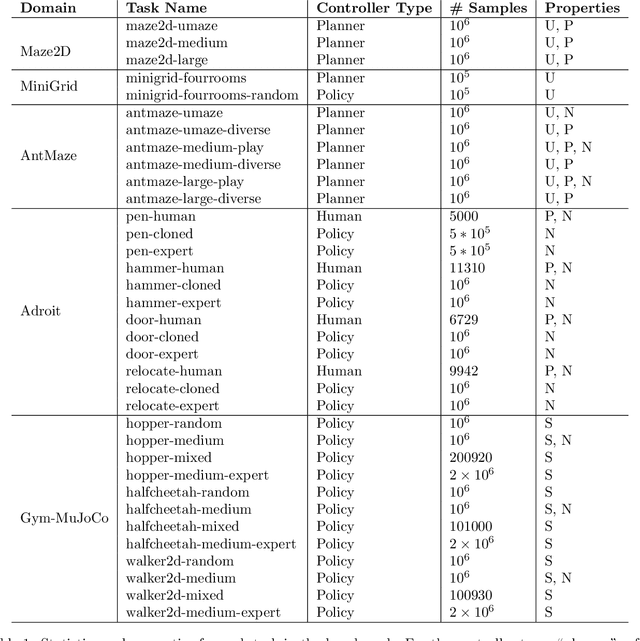
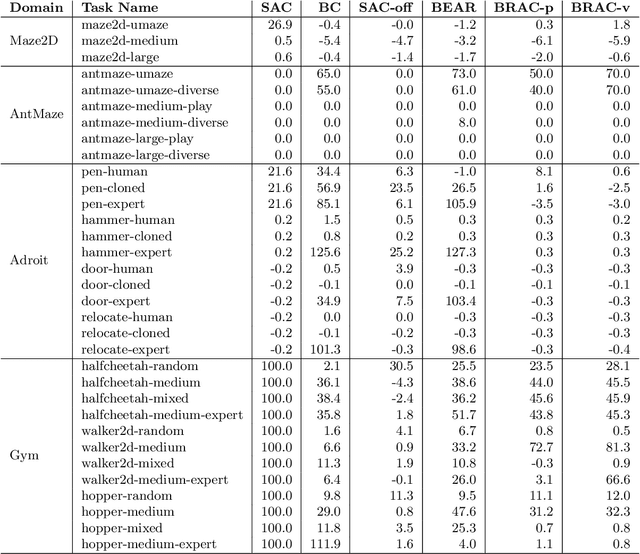
The offline reinforcement learning (RL) problem, also referred to as batch RL, refers to the setting where a policy must be learned from a dataset of previously collected data, without additional online data collection. In supervised learning, large datasets and complex deep neural networks have fueled impressive progress, but in contrast, conventional RL algorithms must collect large amounts of on-policy data and have had little success leveraging previously collected datasets. As a result, existing RL benchmarks are not well-suited for the offline setting, making progress in this area difficult to measure. To design a benchmark tailored to offline RL, we start by outlining key properties of datasets relevant to applications of offline RL. Based on these properties, we design a set of benchmark tasks and datasets that evaluate offline RL algorithms under these conditions. Examples of such properties include: datasets generated via hand-designed controllers and human demonstrators, multi-objective datasets, where an agent can perform different tasks in the same environment, and datasets consisting of a heterogeneous mix of high-quality and low-quality trajectories. By designing the benchmark tasks and datasets to reflect properties of real-world offline RL problems, our benchmark will focus research effort on methods that drive substantial improvements not just on simulated benchmarks, but ultimately on the kinds of real-world problems where offline RL will have the largest impact.
BRPO: Batch Residual Policy Optimization
Feb 08, 2020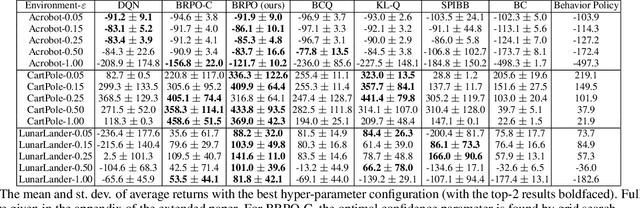

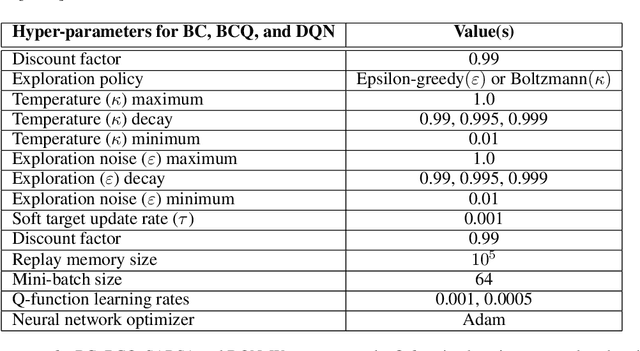
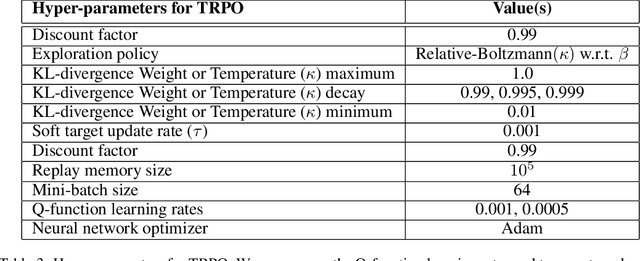
In batch reinforcement learning (RL), one often constrains a learned policy to be close to the behavior (data-generating) policy, e.g., by constraining the learned action distribution to differ from the behavior policy by some maximum degree that is the same at each state. This can cause batch RL to be overly conservative, unable to exploit large policy changes at frequently-visited, high-confidence states without risking poor performance at sparsely-visited states. To remedy this, we propose residual policies, where the allowable deviation of the learned policy is state-action-dependent. We derive a new for RL method, BRPO, which learns both the policy and allowable deviation that jointly maximize a lower bound on policy performance. We show that BRPO achieves the state-of-the-art performance in a number of tasks.
Reinforcement Learning via Fenchel-Rockafellar Duality
Jan 09, 2020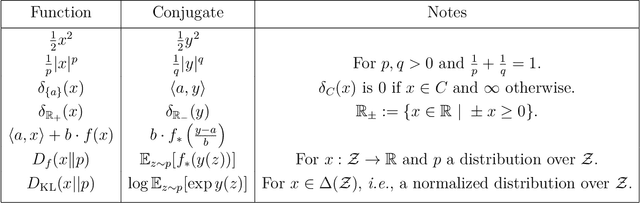
We review basic concepts of convex duality, focusing on the very general and supremely useful Fenchel-Rockafellar duality. We summarize how this duality may be applied to a variety of reinforcement learning (RL) settings, including policy evaluation or optimization, online or offline learning, and discounted or undiscounted rewards. The derivations yield a number of intriguing results, including the ability to perform policy evaluation and on-policy policy gradient with behavior-agnostic offline data and methods to learn a policy via max-likelihood optimization. Although many of these results have appeared previously in various forms, we provide a unified treatment and perspective on these results, which we hope will enable researchers to better use and apply the tools of convex duality to make further progress in RL.
Imitation Learning via Off-Policy Distribution Matching
Dec 10, 2019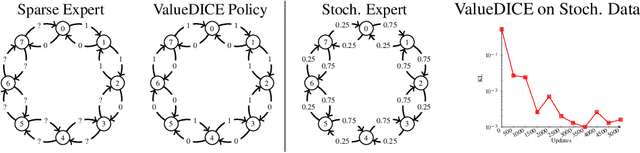
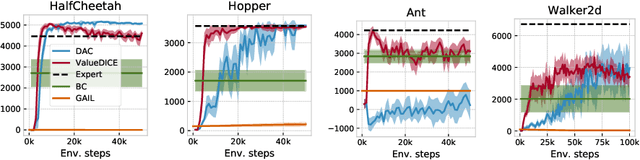
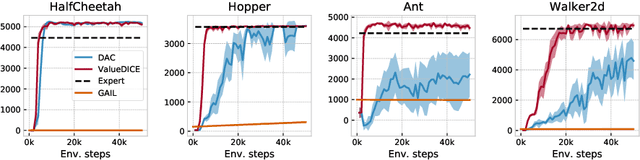
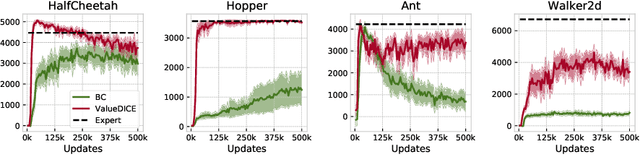
When performing imitation learning from expert demonstrations, distribution matching is a popular approach, in which one alternates between estimating distribution ratios and then using these ratios as rewards in a standard reinforcement learning (RL) algorithm. Traditionally, estimation of the distribution ratio requires on-policy data, which has caused previous work to either be exorbitantly data-inefficient or alter the original objective in a manner that can drastically change its optimum. In this work, we show how the original distribution ratio estimation objective may be transformed in a principled manner to yield a completely off-policy objective. In addition to the data-efficiency that this provides, we are able to show that this objective also renders the use of a separate RL optimization unnecessary.Rather, an imitation policy may be learned directly from this objective without the use of explicit rewards. We call the resulting algorithm ValueDICE and evaluate it on a suite of popular imitation learning benchmarks, finding that it can achieve state-of-the-art sample efficiency and performance.
AlgaeDICE: Policy Gradient from Arbitrary Experience
Dec 04, 2019
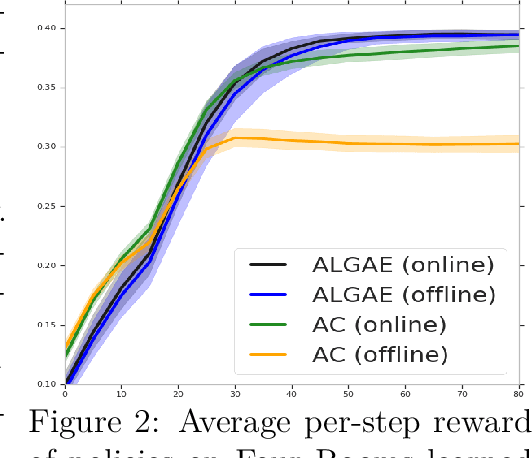
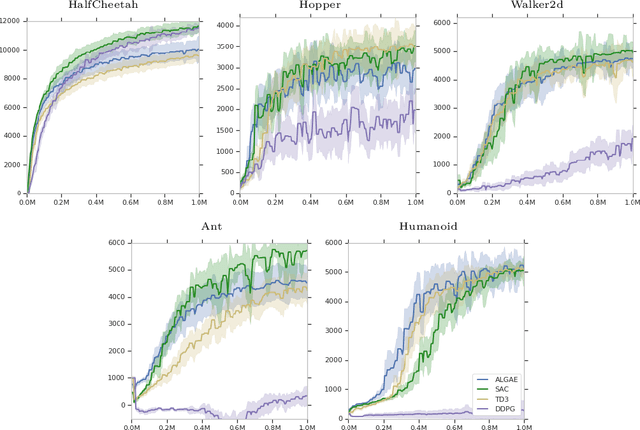
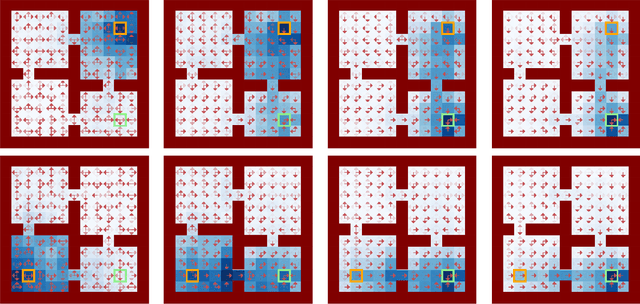
In many real-world applications of reinforcement learning (RL), interactions with the environment are limited due to cost or feasibility. This presents a challenge to traditional RL algorithms since the max-return objective involves an expectation over on-policy samples. We introduce a new formulation of max-return optimization that allows the problem to be re-expressed by an expectation over an arbitrary behavior-agnostic and off-policy data distribution. We first derive this result by considering a regularized version of the dual max-return objective before extending our findings to unregularized objectives through the use of a Lagrangian formulation of the linear programming characterization of Q-values. We show that, if auxiliary dual variables of the objective are optimized, then the gradient of the off-policy objective is exactly the on-policy policy gradient, without any use of importance weighting. In addition to revealing the appealing theoretical properties of this approach, we also show that it delivers good practical performance.
Behavior Regularized Offline Reinforcement Learning
Nov 26, 2019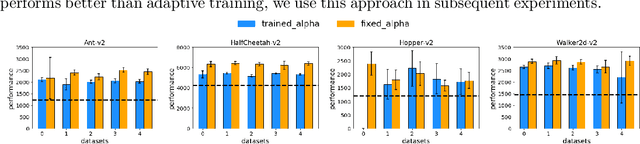
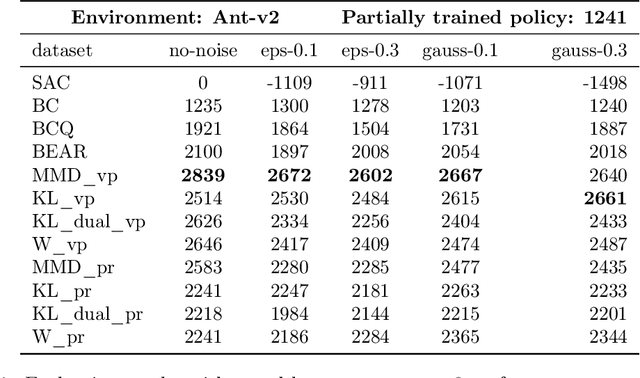
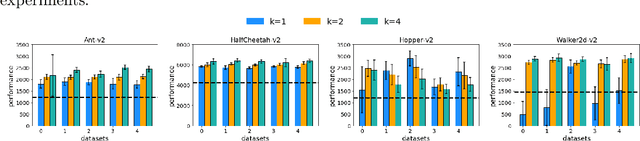
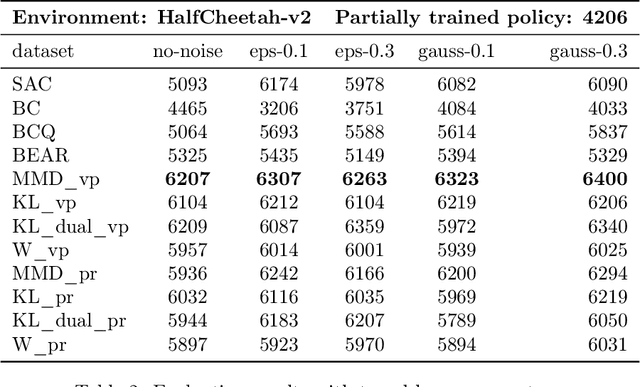
In reinforcement learning (RL) research, it is common to assume access to direct online interactions with the environment. However in many real-world applications, access to the environment is limited to a fixed offline dataset of logged experience. In such settings, standard RL algorithms have been shown to diverge or otherwise yield poor performance. Accordingly, recent work has suggested a number of remedies to these issues. In this work, we introduce a general framework, behavior regularized actor critic (BRAC), to empirically evaluate recently proposed methods as well as a number of simple baselines across a variety of offline continuous control tasks. Surprisingly, we find that many of the technical complexities introduced in recent methods are unnecessary to achieve strong performance. Additional ablations provide insights into which design choices matter most in the offline RL setting.
Group-based Fair Learning Leads to Counter-intuitive Predictions
Oct 04, 2019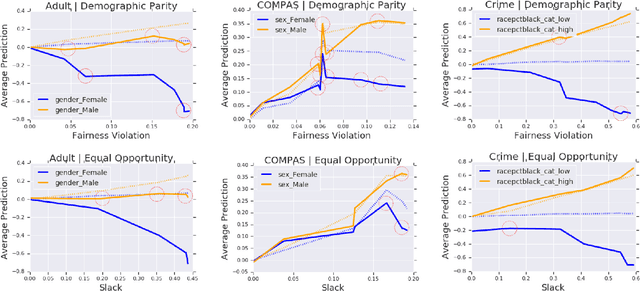

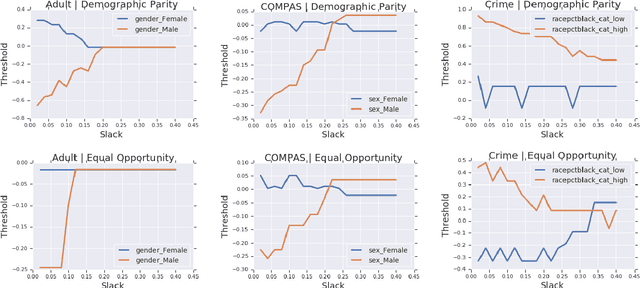
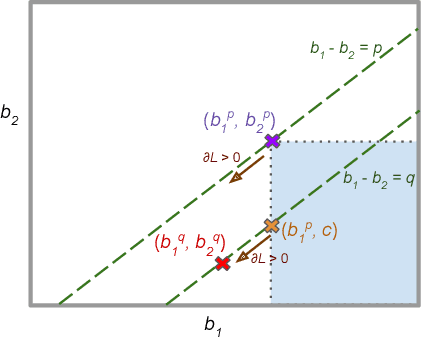
A number of machine learning (ML) methods have been proposed recently to maximize model predictive accuracy while enforcing notions of group parity or fairness across sub-populations. We propose a desirable property for these procedures, slack-consistency: For any individual, the predictions of the model should be monotonic with respect to allowed slack (i.e., maximum allowed group-parity violation). Such monotonicity can be useful for individuals to understand the impact of enforcing fairness on their predictions. Surprisingly, we find that standard ML methods for enforcing fairness violate this basic property. Moreover, this undesirable behavior arises in situations agnostic to the complexity of the underlying model or approximate optimizations, suggesting that the simple act of incorporating a constraint can lead to drastically unintended behavior in ML. We present a simple theoretical method for enforcing slack-consistency, while encouraging further discussions on the unintended behaviors potentially induced when enforcing group-based parity.
Why Does Hierarchy Work So Well in Reinforcement Learning?
Sep 23, 2019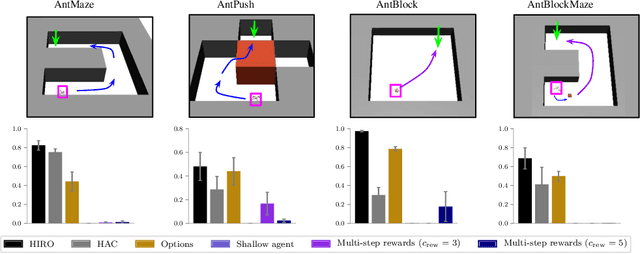
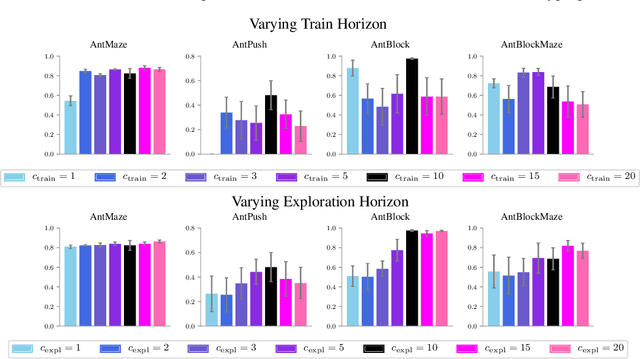
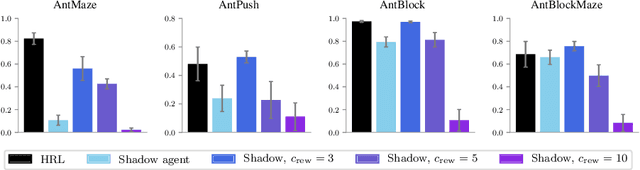
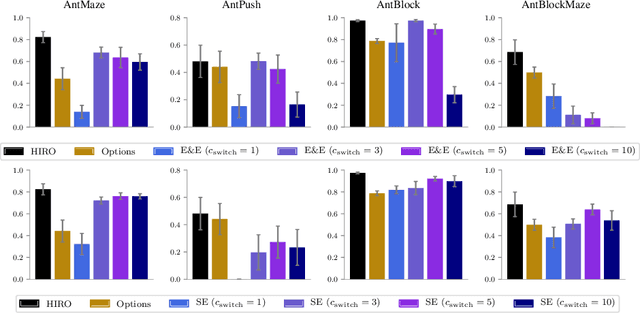
Hierarchical reinforcement learning has demonstrated significant success at solving difficult reinforcement learning (RL) tasks. Previous works have motivated the use of hierarchy by appealing to a number of intuitive benefits, including learning over temporally extended transitions, exploring over temporally extended periods, and training and exploring in a more semantically meaningful action space, among others. However, in fully observed, Markovian settings, it is not immediately clear why hierarchical RL should provide benefits over standard "shallow" RL architectures. In this work, we isolate and evaluate the claimed benefits of hierarchical RL on a suite of tasks encompassing locomotion, navigation, and manipulation. Surprisingly, we find that most of the observed benefits of hierarchy can be attributed to improved exploration, as opposed to easier policy learning or imposed hierarchical structures. Given this insight, we present exploration techniques inspired by hierarchy that achieve performance competitive with hierarchical RL while at the same time being much simpler to use and implement.