 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaired Examples as Indirect Supervision in Latent Decision Models
Apr 05, 2021
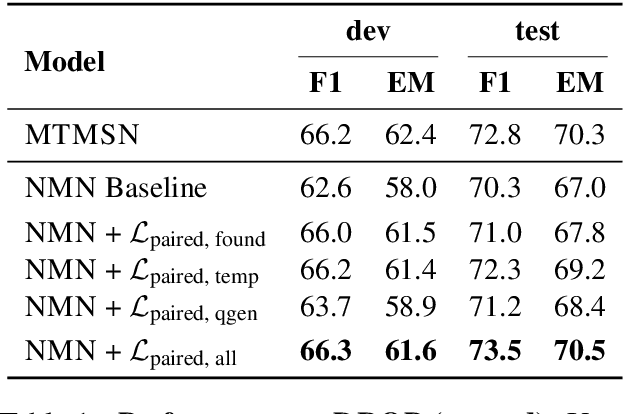


Compositional, structured models are appealing because they explicitly decompose problems and provide interpretable intermediate outputs that give confidence that the model is not simply latching onto data artifacts. Learning these models is challenging, however, because end-task supervision only provides a weak indirect signal on what values the latent decisions should take. This often results in the model failing to learn to perform the intermediate tasks correctly. In this work, we introduce a way to leverage paired examples that provide stronger cues for learning latent decisions. When two related training examples share internal substructure, we add an additional training objective to encourage consistency between their latent decisions. Such an objective does not require external supervision for the values of the latent output, or even the end task, yet provides an additional training signal to that provided by individual training examples themselves. We apply our method to improve compositional question answering using neural module networks on the DROP dataset. We explore three ways to acquire paired questions in DROP: (a) discovering naturally occurring paired examples within the dataset, (b) constructing paired examples using templates, and (c) generating paired examples using a question generation model. We empirically demonstrate that our proposed approach improves both in- and out-of-distribution generalization and leads to correct latent decision predictions.
What do we expect from Multiple-choice QA Systems?
Nov 20, 2020
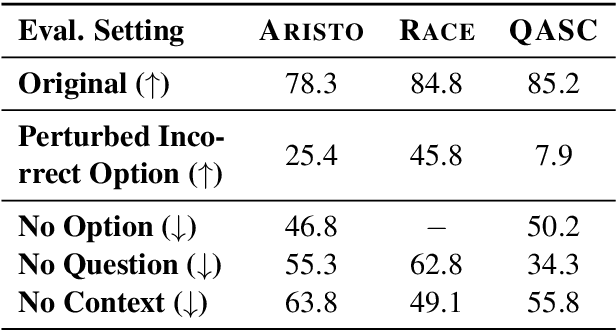
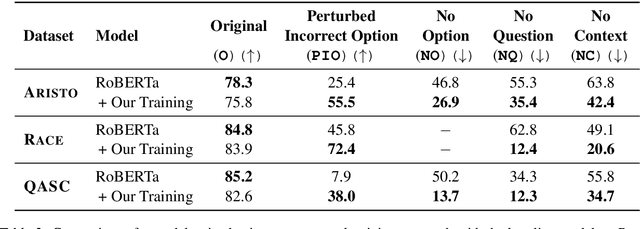
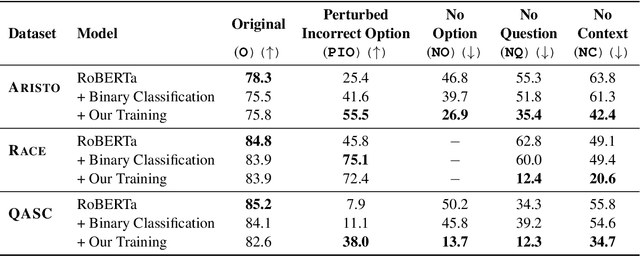
The recent success of machine learning systems on various QA datasets could be interpreted as a significant improvement in models' language understanding abilities. However, using various perturbations, multiple recent works have shown that good performance on a dataset might not indicate performance that correlates well with human's expectations from models that "understand" language. In this work we consider a top performing model on several Multiple Choice Question Answering (MCQA) datasets, and evaluate it against a set of expectations one might have from such a model, using a series of zero-information perturbations of the model's inputs. Our results show that the model clearly falls short of our expectations, and motivates a modified training approach that forces the model to better attend to the inputs. We show that the new training paradigm leads to a model that performs on par with the original model while better satisfying our expectations.
* Findings of EMNLP 2020
Improving Compositional Generalization in Semantic Parsing
Oct 12, 2020
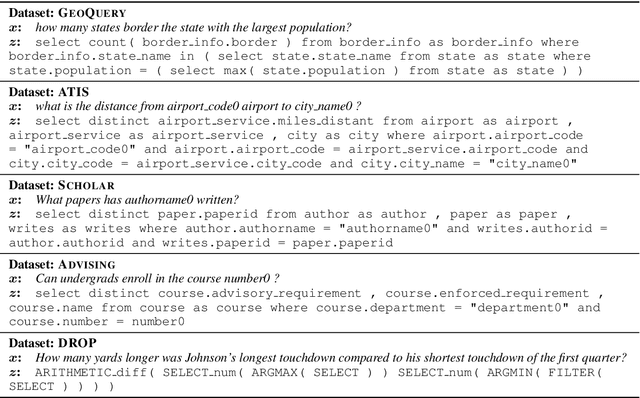

Generalization of models to out-of-distribution (OOD) data has captured tremendous attention recently. Specifically, compositional generalization, i.e., whether a model generalizes to new structures built of components observed during training, has sparked substantial interest. In this work, we investigate compositional generalization in semantic parsing, a natural test-bed for compositional generalization, as output programs are constructed from sub-components. We analyze a wide variety of models and propose multiple extensions to the attention module of the semantic parser, aiming to improve compositional generalization. We find that the following factors improve compositional generalization: (a) using contextual representations, such as ELMo and BERT, (b) informing the decoder what input tokens have previously been attended to, (c) training the decoder attention to agree with pre-computed token alignments, and (d) downsampling examples corresponding to frequent program templates. While we substantially reduce the gap between in-distribution and OOD generalization, performance on OOD compositions is still substantially lower.
Obtaining Faithful Interpretations from Compositional Neural Networks
May 02, 2020
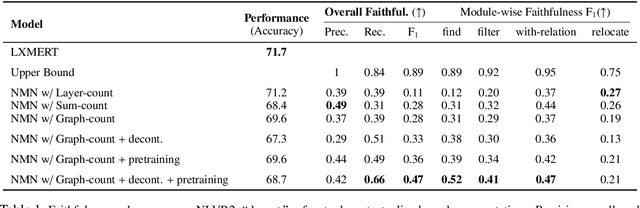
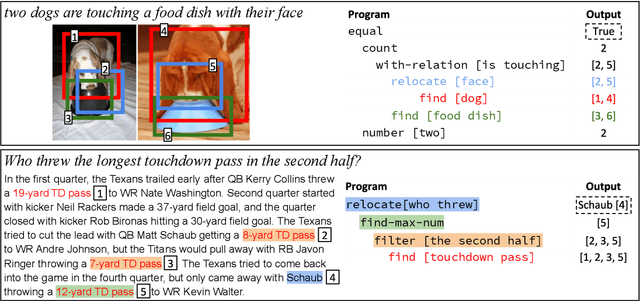
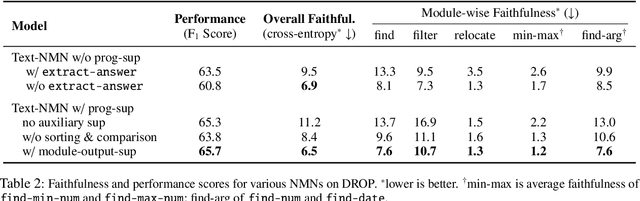
Neural module networks (NMNs) are a popular approach for modeling compositionality: they achieve high accuracy when applied to problems in language and vision, while reflecting the compositional structure of the problem in the network architecture. However, prior work implicitly assumed that the structure of the network modules, describing the abstract reasoning process, provides a faithful explanation of the model's reasoning; that is, that all modules perform their intended behaviour. In this work, we propose and conduct a systematic evaluation of the intermediate outputs of NMNs on NLVR2 and DROP, two datasets which require composing multiple reasoning steps. We find that the intermediate outputs differ from the expected output, illustrating that the network structure does not provide a faithful explanation of model behaviour. To remedy that, we train the model with auxiliary supervision and propose particular choices for module architecture that yield much better faithfulness, at a minimal cost to accuracy.
Overestimation of Syntactic Representationin Neural Language Models
Apr 10, 2020
With the advent of powerful neural language models over the last few years, research attention has increasingly focused on what aspects of language they represent that make them so successful. Several testing methodologies have been developed to probe models' syntactic representations. One popular method for determining a model's ability to induce syntactic structure trains a model on strings generated according to a template then tests the model's ability to distinguish such strings from superficially similar ones with different syntax. We illustrate a fundamental problem with this approach by reproducing positive results from a recent paper with two non-syntactic baseline language models: an n-gram model and an LSTM model trained on scrambled inputs.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
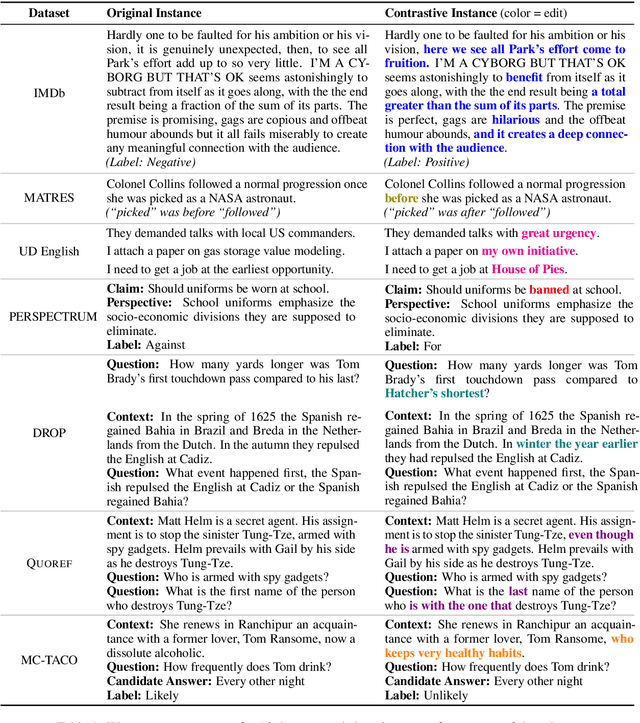
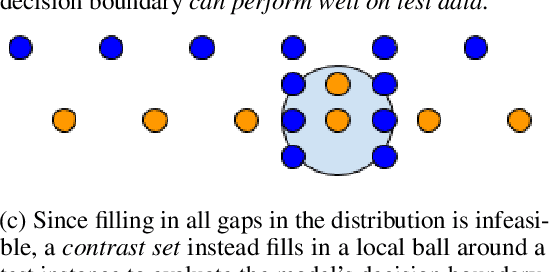
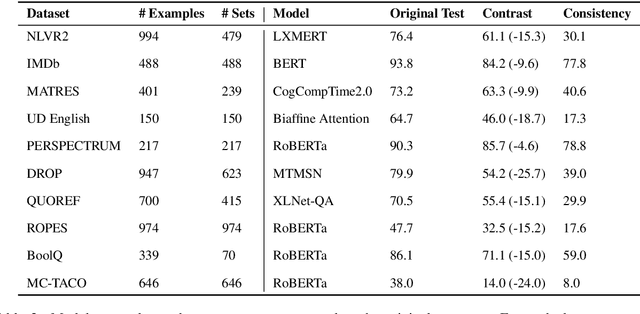
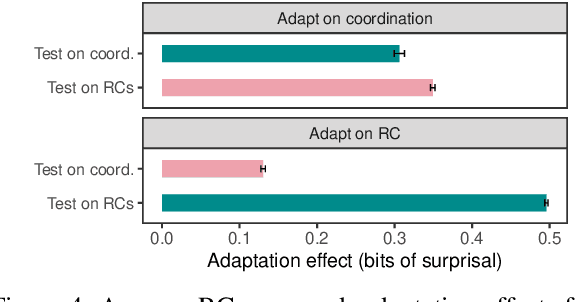
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Robust Named Entity Recognition with Truecasing Pretraining
Dec 15, 2019
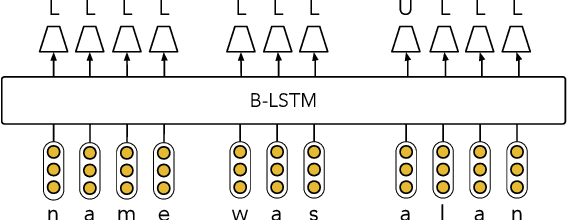

Although modern named entity recognition (NER) systems show impressive performance on standard datasets, they perform poorly when presented with noisy data. In particular, capitalization is a strong signal for entities in many languages, and even state of the art models overfit to this feature, with drastically lower performance on uncapitalized text. In this work, we address the problem of robustness of NER systems in data with noisy or uncertain casing, using a pretraining objective that predicts casing in text, or a truecaser, leveraging unlabeled data. The pretrained truecaser is combined with a standard BiLSTM-CRF model for NER by appending output distributions to character embeddings. In experiments over several datasets of varying domain and casing quality, we show that our new model improves performance in uncased text, even adding value to uncased BERT embeddings. Our method achieves a new state of the art on the WNUT17 shared task dataset.
Neural Module Networks for Reasoning over Text
Dec 10, 2019

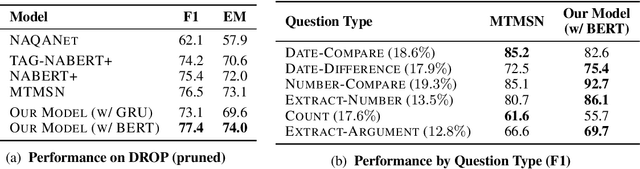

Answering compositional questions that require multiple steps of reasoning against text is challenging, especially when they involve discrete, symbolic operations. Neural module networks (NMNs) learn to parse such questions as executable programs composed of learnable modules, performing well on synthetic visual QA domains. However, we find that it is challenging to learn these models for non-synthetic questions on open-domain text, where a model needs to deal with the diversity of natural language and perform a broader range of reasoning. We extend NMNs by: (a) introducing modules that reason over a paragraph of text, performing symbolic reasoning (such as arithmetic, sorting, counting) over numbers and dates in a probabilistic and differentiable manner; and (b) proposing an unsupervised auxiliary loss to help extract arguments associated with the events in text. Additionally, we show that a limited amount of heuristically-obtained question program and intermediate module output supervision provides sufficient inductive bias for accurate learning. Our proposed model significantly outperforms state-of-the-art models on a subset of the DROP dataset that poses a variety of reasoning challenges that are covered by our modules.
Joint Multilingual Supervision for Cross-lingual Entity Linking
Sep 20, 2018
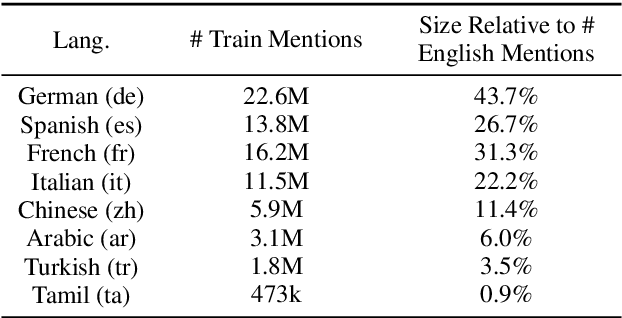
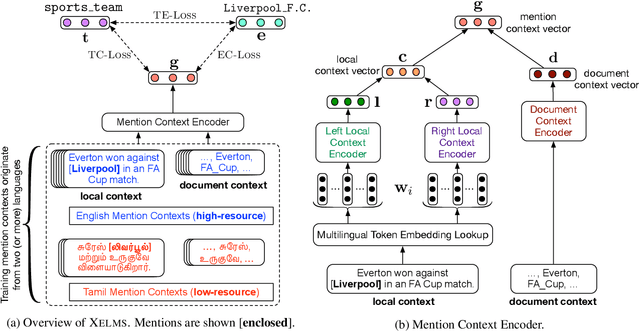
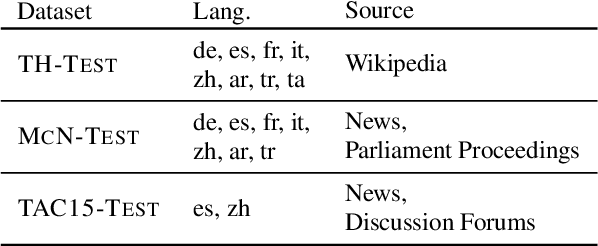
Cross-lingual Entity Linking (XEL) aims to ground entity mentions written in any language to an English Knowledge Base (KB), such as Wikipedia. XEL for most languages is challenging, owing to limited availability of resources as supervision. We address this challenge by developing the first XEL approach that combines supervision from multiple languages jointly. This enables our approach to: (a) augment the limited supervision in the target language with additional supervision from a high-resource language (like English), and (b) train a single entity linking model for multiple languages, improving upon individually trained models for each language. Extensive evaluation on three benchmark datasets across 8 languages shows that our approach significantly improves over the current state-of-the-art. We also provide analyses in two limited resource settings: (a) zero-shot setting, when no supervision in the target language is available, and in (b) low-resource setting, when some supervision in the target language is available. Our analysis provides insights into the limitations of zero-shot XEL approaches in realistic scenarios, and shows the value of joint supervision in low-resource settings.
Neural Compositional Denotational Semantics for Question Answering
Aug 29, 2018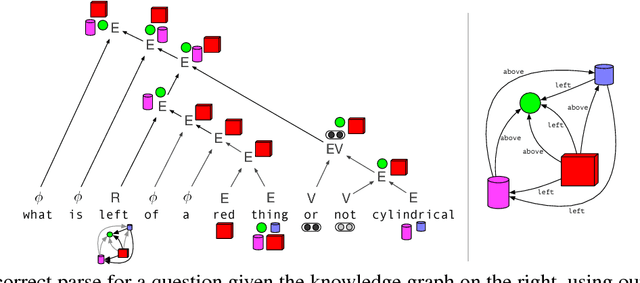
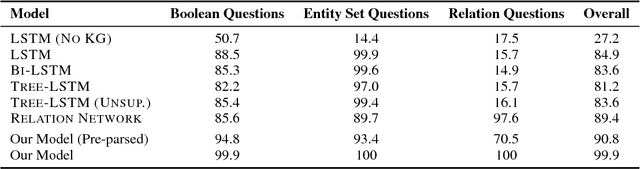
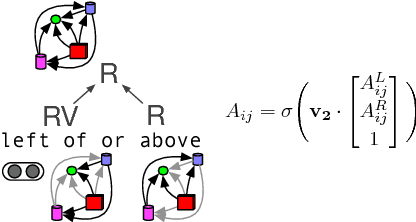
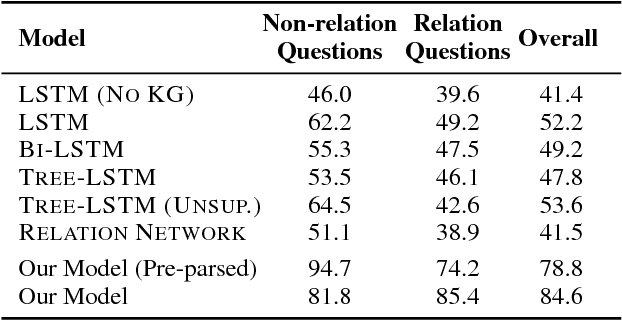
Answering compositional questions requiring multi-step reasoning is challenging. We introduce an end-to-end differentiable model for interpreting questions about a knowledge graph (KG), which is inspired by formal approaches to semantics. Each span of text is represented by a denotation in a KG and a vector that captures ungrounded aspects of meaning. Learned composition modules recursively combine constituent spans, culminating in a grounding for the complete sentence which answers the question. For example, to interpret "not green", the model represents "green" as a set of KG entities and "not" as a trainable ungrounded vector---and then uses this vector to parameterize a composition function that performs a complement operation. For each sentence, we build a parse chart subsuming all possible parses, allowing the model to jointly learn both the composition operators and output structure by gradient descent from end-task supervision. The model learns a variety of challenging semantic operators, such as quantifiers, disjunctions and composed relations, and infers latent syntactic structure. It also generalizes well to longer questions than seen in its training data, in contrast to RNN, its tree-based variants, and semantic parsing baselines.