 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and Mitigating Constraint Violations of In-Context Learning for Utterance-to-API Semantic Parsing
May 24, 2023



In executable task-oriented semantic parsing, the system aims to translate users' utterances in natural language to machine-interpretable programs (API calls) that can be executed according to pre-defined API specifications. With the popularity of Large Language Models (LLMs), in-context learning offers a strong baseline for such scenarios, especially in data-limited regimes. However, LLMs are known to hallucinate and therefore pose a formidable challenge in constraining generated content. Thus, it remains uncertain if LLMs can effectively perform task-oriented utterance-to-API generation where respecting API's structural and task-specific constraints is crucial. In this work, we seek to measure, analyze and mitigate such constraints violations. First, we identify the categories of various constraints in obtaining API-semantics from task-oriented utterances, and define fine-grained metrics that complement traditional ones. Second, we leverage these metrics to conduct a detailed error analysis of constraints violations seen in state-of-the-art LLMs, which motivates us to investigate two mitigation strategies: Semantic-Retrieval of Demonstrations (SRD) and API-aware Constrained Decoding (API-CD). Our experiments show that these strategies are effective at reducing constraints violations and improving the quality of the generated API calls, but require careful consideration given their implementation complexity and latency.
Vcc: Scaling Transformers to 128K Tokens or More by Prioritizing Important Tokens
May 07, 2023



Transformer models are foundational to natural language processing (NLP) and computer vision. Despite various recent works devoted to reducing the quadratic cost of such models (as a function of the sequence length $n$), dealing with ultra long sequences efficiently (e.g., with more than 16K tokens) remains challenging. Applications such as answering questions based on an entire book or summarizing a scientific article are inefficient or infeasible. In this paper, we propose to significantly reduce the dependency of a Transformer model's complexity on $n$, by compressing the input into a representation whose size $r$ is independent of $n$ at each layer. Specifically, by exploiting the fact that in many tasks, only a small subset of special tokens (we call VIP-tokens) are most relevant to the final prediction, we propose a VIP-token centric compression (Vcc) scheme which selectively compresses the input sequence based on their impact on approximating the representation of these VIP-tokens. Compared with competitive baselines, the proposed algorithm not only is efficient (achieving more than $3\times$ efficiency improvement compared to baselines on 4K and 16K lengths), but also achieves competitive or better performance on a large number of tasks. Further, we show that our algorithm can be scaled to 128K tokens (or more) while consistently offering accuracy improvement.
Distortion Minimization with Age of Information and Cost Constraints
Mar 01, 2023We consider a source monitoring a stochastic process with a transmitter to transmit timely information through a wireless ON/OFF channel to a destination. We assume that once the source samples the data, the sampled data has to be processed to identify the state of the stochastic process. The processing can take place either at the source before transmission or after transmission at the destination. The objective is to minimize the distortion while keeping the age of information (AoI) that measures the timeliness of information under a certain threshold. We use a stationary randomized policy (SRP) framework to solve the formulated problem. We show that the two-dimensional discrete-time Markov chain considering the AoI and instantaneous distortion as the state is lumpable and we obtain the expression for the expected AoI under the SRP.
Conversation Style Transfer using Few-Shot Learning
Feb 16, 2023



Conventional text style transfer approaches for natural language focus on sentence-level style transfer without considering contextual information, and the style is described with attributes (e.g., formality). When applying style transfer on conversations such as task-oriented dialogues, existing approaches suffer from these limitations as context can play an important role and the style attributes are often difficult to define in conversations. In this paper, we introduce conversation style transfer as a few-shot learning problem, where the model learns to perform style transfer by observing only the target-style dialogue examples. We propose a novel in-context learning approach to solve the task with style-free dialogues as a pivot. Human evaluation shows that by incorporating multi-turn context, the model is able to match the target style while having better appropriateness and semantic correctness compared to utterance-level style transfer. Additionally, we show that conversation style transfer can also benefit downstream tasks. Results on multi-domain intent classification tasks show improvement in F1 scores after transferring the style of training data to match the style of test data.
Real-time Remote Reconstruction of a Markov Source and Actuation over Wireless
Feb 02, 2023In this work, we study the problem of real-time tracking and reconstruction of an information source with the purpose of actuation. A device monitors an $N$-state Markov process and transmits status updates to a receiver over a wireless erasure channel. We consider a set of joint sampling and transmission policies, including a semantics-aware one, and we study their performance with respect to relevant metrics. Specifically, we investigate the real-time reconstruction error and its variance, the consecutive error, the cost of memory error, and the cost of actuation error. Furthermore, we propose a randomized stationary sampling and transmission policy and derive closed-form expressions for all aforementioned metrics. We then formulate an optimization problem for minimizing the real-time reconstruction error subject to a sampling cost constraint. Our results show that in the scenario of constrained sampling generation, the optimal randomized stationary policy outperforms all other sampling policies when the source is rapidly evolving. Otherwise, the semantics-aware policy performs the best.
Backward Compatibility During Data Updates by Weight Interpolation
Jan 25, 2023



Backward compatibility of model predictions is a desired property when updating a machine learning driven application. It allows to seamlessly improve the underlying model without introducing regression bugs. In classification tasks these bugs occur in the form of negative flips. This means an instance that was correctly classified by the old model is now classified incorrectly by the updated model. This has direct negative impact on the user experience of such systems e.g. a frequently used voice assistant query is suddenly misclassified. A common reason to update the model is when new training data becomes available and needs to be incorporated. Simply retraining the model with the updated data introduces the unwanted negative flips. We study the problem of regression during data updates and propose Backward Compatible Weight Interpolation (BCWI). This method interpolates between the weights of the old and new model and we show in extensive experiments that it reduces negative flips without sacrificing the improved accuracy of the new model. BCWI is straight forward to implement and does not increase inference cost. We also explore the use of importance weighting during interpolation and averaging the weights of multiple new models in order to further reduce negative flips.
Dialog2API: Task-Oriented Dialogue with API Description and Example Programs
Dec 20, 2022



Functionality and dialogue experience are two important factors of task-oriented dialogue systems. Conventional approaches with closed schema (e.g., conversational semantic parsing) often fail as both the functionality and dialogue experience are strongly constrained by the underlying schema. We introduce a new paradigm for task-oriented dialogue - Dialog2API - to greatly expand the functionality and provide seamless dialogue experience. The conversational model interacts with the environment by generating and executing programs triggering a set of pre-defined APIs. The model also manages the dialogue policy and interact with the user through generating appropriate natural language responses. By allowing generating free-form programs, Dialog2API supports composite goals by combining different APIs, whereas unrestricted program revision provides natural and robust dialogue experience. To facilitate Dialog2API, the core model is provided with API documents, an execution environment and optionally some example dialogues annotated with programs. We propose an approach tailored for the Dialog2API, where the dialogue states are represented by a stack of programs, with most recently mentioned program on the top of the stack. Dialog2API can work with many application scenarios such as software automation and customer service. In this paper, we construct a dataset for AWS S3 APIs and present evaluation results of in-context learning baselines.
Task-Oriented and Semantics-Aware 6G Networks
Oct 17, 2022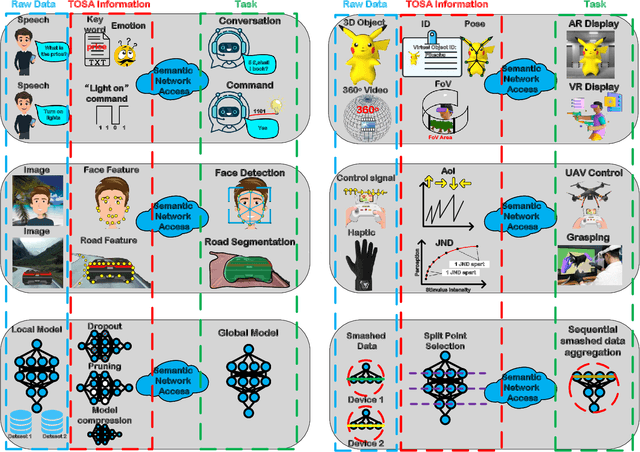
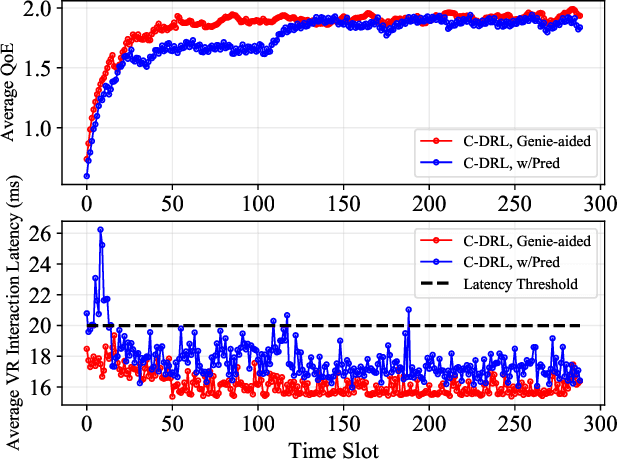
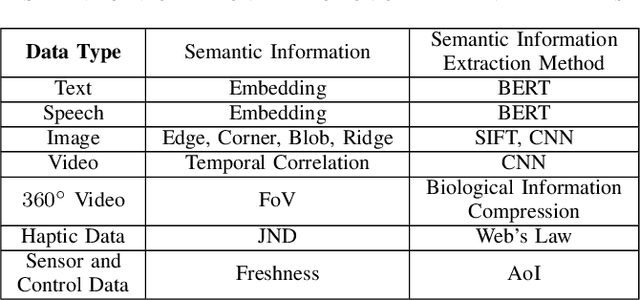
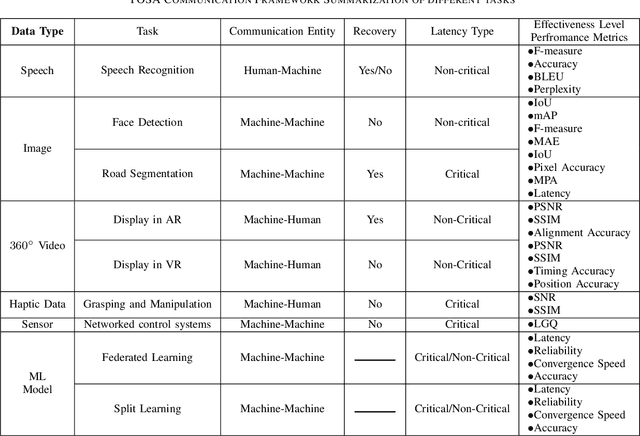
Upon the arrival of emerging devices, including Extended Reality (XR) and Unmanned Aerial Vehicles (UAVs), the traditional bit-oriented communication framework is approaching Shannon's physical capacity limit and fails to guarantee the massive amount of transmission within latency requirements. By jointly exploiting the context of data and its importance to the task, an emerging communication paradigm shift to semantic level and effectiveness level is envisioned to be a key revolution in Sixth Generation (6G) networks. However, an explicit and systematic communication framework incorporating both semantic level and effectiveness level has not been proposed yet. In this article, we propose a generic task-oriented and semantics-aware (TOSA) communication framework for various tasks with diverse data types, which incorporates both semantic level information and effectiveness level performance metrics. We first analyze the unique characteristics of all data types, and summarise the semantic information, along with corresponding extraction methods. We then propose a detailed TOSA communication framework for different time critical and non-critical tasks. In the TOSA framework, we present the TOSA information, extraction methods, recovery methods, and effectiveness level performance metrics. Last but not least, we present a TOSA framework tailored for Virtual Reality (VR) data with interactive VR tasks to validate the effectiveness of the proposed TOSA communication framework.
Modeling Context With Linear Attention for Scalable Document-Level Translation
Oct 16, 2022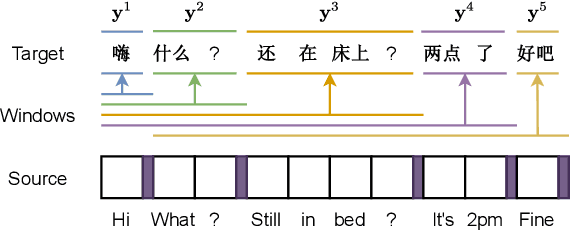
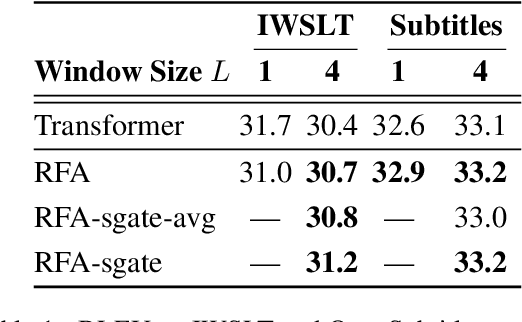
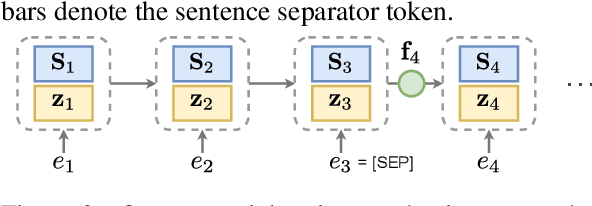
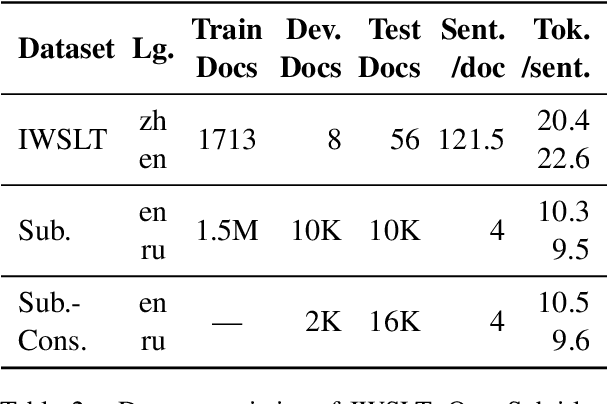
Document-level machine translation leverages inter-sentence dependencies to produce more coherent and consistent translations. However, these models, predominantly based on transformers, are difficult to scale to long documents as their attention layers have quadratic complexity in the sequence length. Recent efforts on efficient attention improve scalability, but their effect on document translation remains unexplored. In this work, we investigate the efficacy of a recent linear attention model by Peng et al. (2021) on document translation and augment it with a sentential gate to promote a recency inductive bias. We evaluate the model on IWSLT 2015 and OpenSubtitles 2018 against the transformer, demonstrating substantially increased decoding speed on long sequences with similar or better BLEU scores. We show that sentential gating further improves translation quality on IWSLT.
Robust Beamforming Design for IRS-Aided URLLC in D2D Networks
Jul 11, 2022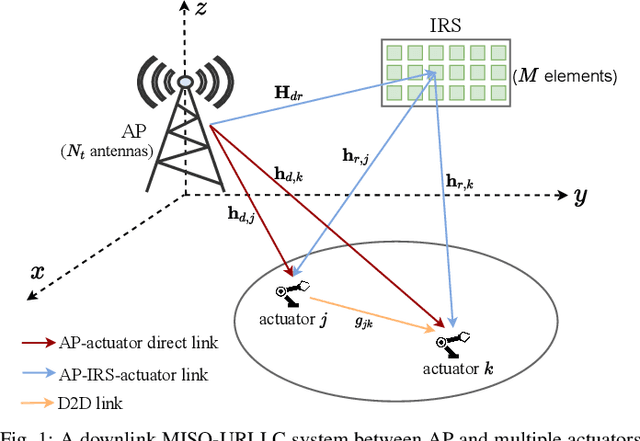
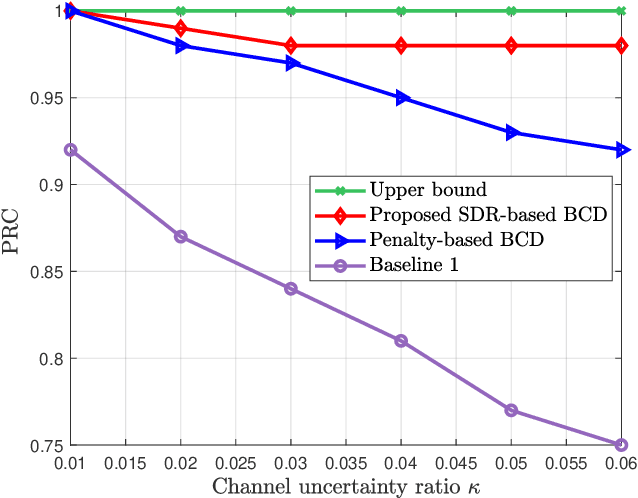
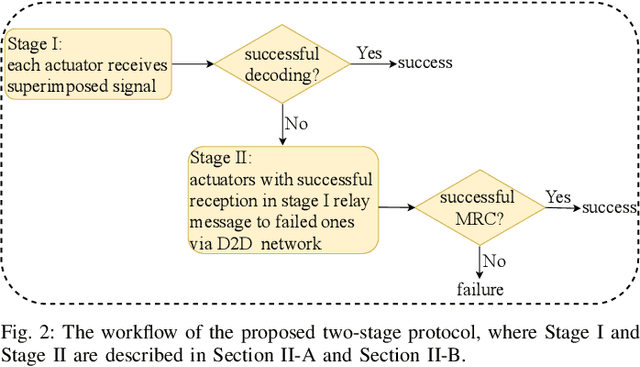
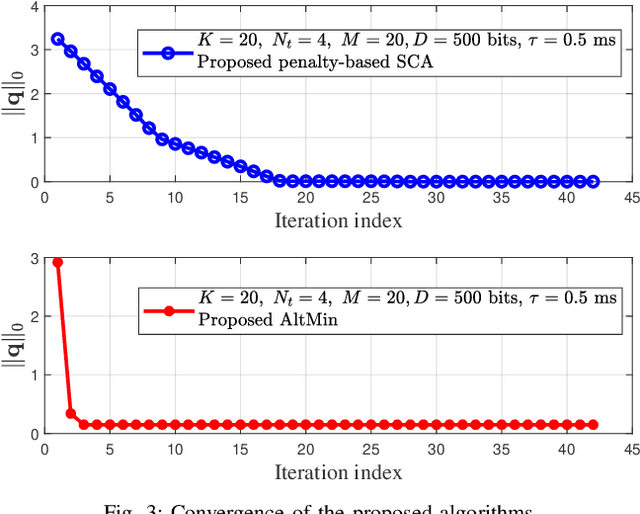
Intelligent reflecting surface (IRS) and device-to-device (D2D) communication are two promising technologies for improving transmission reliability between transceivers in communication systems. In this paper, we consider the design of reliable communication between the access point (AP) and actuators for a downlink multiuser multiple-input single-output (MISO) system in the industrial IoT (IIoT) scenario. We propose a two-stage protocol combining IRS with D2D communication so that all actuators can successfully receive the message from AP within a given delay. The superiority of the protocol is that the communication reliability between AP and actuators is doubly augmented by the IRS-aided first-stage transmission and the second-stage D2D transmission. A joint optimization problem of active and passive beamforming is formulated, which aims to maximize the number of actuators with successful decoding. We study the joint beamforming problem for cases where the channel state information (CSI) is perfect and imperfect. For each case, we develop efficient algorithms that include convergence and complexity analysis. Simulation results demonstrate the necessity and role of IRS with a well-optimized reflection matrix, and the D2D network in promoting reliable communication. Moreover, the proposed protocol can enable reliable communication even in the presence of stringent latency requirements and CSI estimation errors.