 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Me Teach You: Pedagogical Foundations of Feedback for Language Models
Jul 01, 2023



Natural Language Feedback (NLF) is an increasingly popular avenue to align Large Language Models (LLMs) to human preferences. Despite the richness and diversity of the information it can convey, NLF is often hand-designed and arbitrary. In a different world, research in pedagogy has long established several effective feedback models. In this opinion piece, we compile ideas from pedagogy to introduce FELT, a feedback framework for LLMs that outlines the various characteristics of the feedback space, and a feedback content taxonomy based on these variables. Our taxonomy offers both a general mapping of the feedback space, as well as pedagogy-established discrete categories, allowing us to empirically demonstrate the impact of different feedback types on revised generations. In addition to streamlining existing NLF designs, FELT also brings out new, unexplored directions for research in NLF. We make our taxonomy available to the community, providing guides and examples for mapping our categorizations to future resources.
Editing Commonsense Knowledge in GPT
May 24, 2023



Memory editing methods for updating encyclopedic knowledge in transformers have received increasing attention for their efficacy, specificity, and generalization advantages. However, it remains unclear if such methods can be adapted for the more nuanced domain of commonsense knowledge. We propose $MEMIT_{CSK}$, an adaptation of MEMIT to edit commonsense mistakes in GPT-2 Large and XL. We extend editing to various token locations and employ a robust layer selection strategy. Models edited by $MEMIT_{CSK}$ outperforms the fine-tuning baselines by 10.97% and 10.73% F1 scores on subsets of PEP3k and 20Q. We further propose a novel evaluation dataset, MEMIT-CSK-PROBE, that contains unaffected neighborhood, affected neighborhood, affected paraphrase, and affected reasoning challenges. $MEMIT_{CSK}$ demonstrates favorable semantic generalization, outperforming fine-tuning baselines by 13.72% and 5.57% overall scores on MEMIT-CSK-PROBE. These results suggest a compelling future direction of incorporating context-specific user feedback concerning commonsense in GPT by direct model editing, rectifying and customizing model behaviors via human-in-the-loop systems.
Aligning Language Models to User Opinions
May 24, 2023An important aspect of developing LLMs that interact with humans is to align models' behavior to their users. It is possible to prompt an LLM into behaving as a certain persona, especially a user group or ideological persona the model captured during its pertaining stage. But, how to best align an LLM with a specific user and not a demographic or ideological group remains an open question. Mining public opinion surveys (by Pew Research), we find that the opinions of a user and their demographics and ideologies are not mutual predictors. We use this insight to align LLMs by modeling both user opinions as well as user demographics and ideology, achieving up to 7 points accuracy gains in predicting public opinions from survey questions across a broad set of topics. In addition to the typical approach of prompting LLMs with demographics and ideology, we discover that utilizing the most relevant past opinions from individual users enables the model to predict user opinions more accurately.
OpenPI2.0: An Improved Dataset for Entity Tracking in Texts
May 24, 2023Representing texts as information about entities has long been deemed effective in event reasoning. We propose OpenPI2.0, an improved dataset for tracking entity states in procedural texts. OpenPI2.0 features not only canonicalized entities that facilitate evaluation, but also salience annotations including both manual labels and automatic predictions. Regarding entity salience, we provide a survey on annotation subjectivity, modeling feasibility, and downstream applications in tasks such as question answering and classical planning.
RL4F: Generating Natural Language Feedback with Reinforcement Learning for Repairing Model Outputs
May 15, 2023



Despite their unprecedented success, even the largest language models make mistakes. Similar to how humans learn and improve using feedback, previous work proposed providing language models with natural language feedback to guide them in repairing their outputs. Because human-generated critiques are expensive to obtain, researchers have devised learned critique generators in lieu of human critics while assuming one can train downstream models to utilize generated feedback. However, this approach does not apply to black-box or limited access models such as ChatGPT, as they cannot be fine-tuned. Moreover, in the era of large general-purpose language agents, fine-tuning is neither computationally nor spatially efficient as it results in multiple copies of the network. In this work, we introduce RL4F (Reinforcement Learning for Feedback), a multi-agent collaborative framework where the critique generator is trained to maximize end-task performance of GPT-3, a fixed model more than 200 times its size. RL4F produces critiques that help GPT-3 revise its outputs. We study three datasets for action planning, summarization and alphabetization and show improvements (~5% on average) in multiple text similarity metrics over strong baselines across all three tasks.
Self-Refine: Iterative Refinement with Self-Feedback
Mar 30, 2023



Like people, LLMs do not always generate the best text for a given generation problem on their first try (e.g., summaries, answers, explanations). Just as people then refine their text, we introduce SELF-REFINE, a framework for similarly improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an output using an LLM, then allow the same model to provide multi-aspect feedback for its own output; finally, the same model refines its previously generated output given its own feedback. Unlike earlier work, our iterative refinement framework does not require supervised training data or reinforcement learning, and works with a single LLM. We experiment with 7 diverse tasks, ranging from review rewriting to math reasoning, demonstrating that our approach outperforms direct generation. In all tasks, outputs generated with SELF-REFINE are preferred by humans and by automated metrics over those generated directly with GPT-3.5 and GPT-4, improving on average by absolute 20% across tasks.
Conditional set generation using Seq2seq models
May 25, 2022
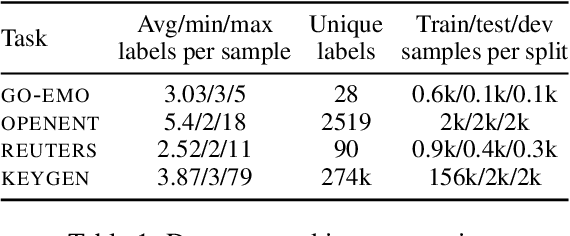
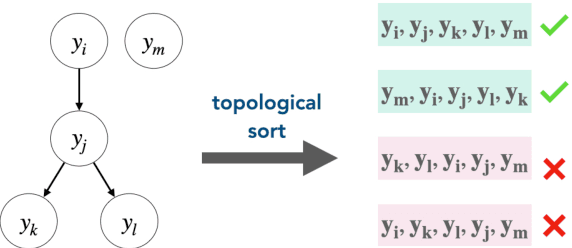
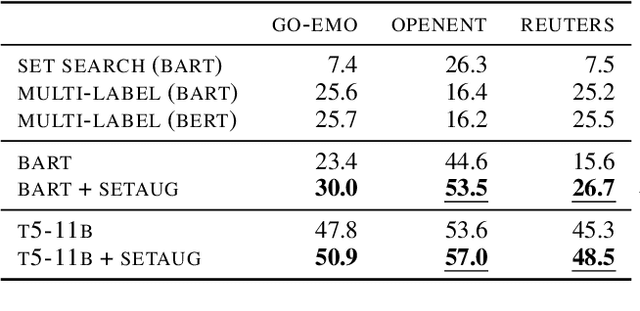
Conditional set generation learns a mapping from an input sequence of tokens to a set. Several NLP tasks, such as entity typing and dialogue emotion tagging, are instances of set generation. Sequence-to-sequence~(Seq2seq) models are a popular choice to model set generation, but they treat a set as a sequence and do not fully leverage its key properties, namely order-invariance and cardinality. We propose a novel algorithm for effectively sampling informative orders over the combinatorial space of label orders. Further, we jointly model the set cardinality and output by adding the set size as the first element and taking advantage of the autoregressive factorization used by Seq2seq models. Our method is a model-independent data augmentation approach that endows any Seq2seq model with the signals of order-invariance and cardinality. Training a Seq2seq model on this new augmented data~(without any additional annotations) gets an average relative improvement of 20% for four benchmarks datasets across models spanning from BART-base, T5-xxl, and GPT-3.
Memory-assisted prompt editing to improve GPT-3 after deployment
Jan 16, 2022
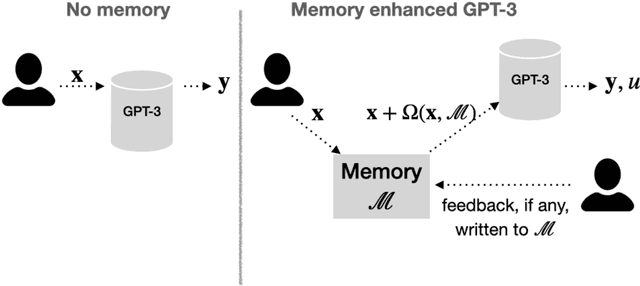

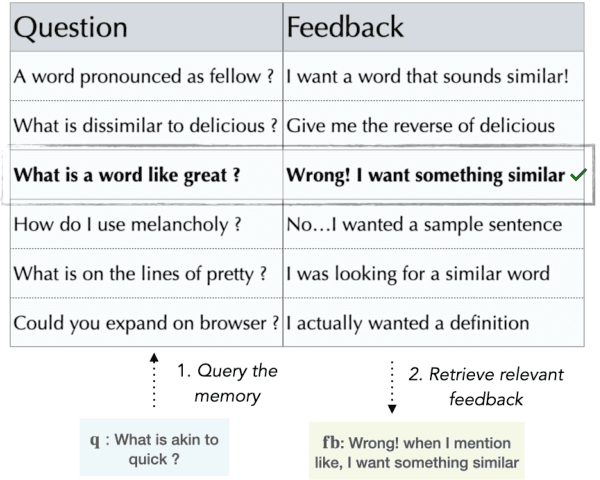
Large LMs such as GPT-3, while powerful, are not immune to mistakes, but are prohibitively costly to retrain. One failure mode is misinterpreting a user's instruction (e.g., GPT-3 interpreting "What word is similar to good?" to mean a homonym, while the user intended a synonym). Our goal is to allow users to correct such errors directly through interaction -- without retraining. Our approach pairs GPT-3 with a growing memory of cases where the model misunderstood the user's intent and was provided with feedback, clarifying the instruction. Given a new query, our memory-enhanced GPT-3 uses feedback from similar, prior queries to enrich the prompt. Through simple proof-of-concept experiments, we show how a (simulated) user can interactively teach a deployed GPT-3, doubling its accuracy on basic lexical tasks (e.g., generate a synonym) where users query in different, novel (often misunderstood) ways. In such scenarios, memory helps avoid repeating similar past mistakes. Our simple idea is a first step towards strengthening deployed models, potentially broadening their utility. All the code and data is available at https://github.com/madaan/memprompt.
Improving scripts with a memory of natural feedback
Dec 16, 2021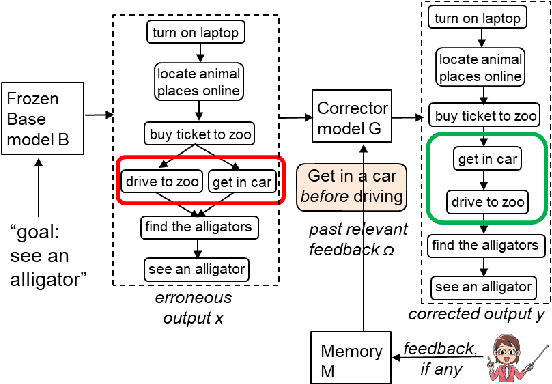
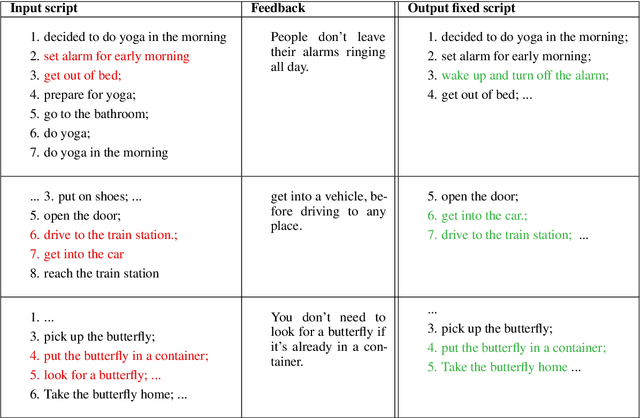
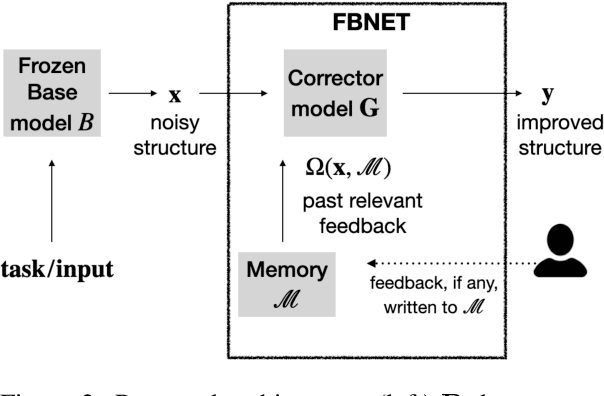
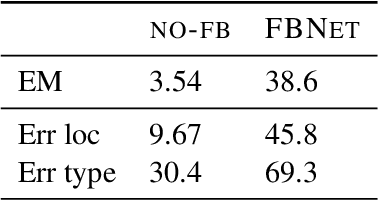
How can an end-user provide feedback if a deployed structured prediction model generates incorrect output? Our goal is to allow users to correct errors directly through interaction, without retraining, by giving feedback on the model's output. We create a dynamic memory architecture with a growing memory of feedbacks about errors in the output. Given a new, unseen input, our model can use feedback from a similar, past erroneous state. On a script generation task, we show empirically that the model learns to apply feedback effectively (up to 30 points improvement), while avoiding similar past mistakes after deployment (up to 10 points improvement on an unseen set). This is a first step towards strengthening deployed models, potentially broadening their utility.
Interscript: A dataset for interactive learning of scripts through error feedback
Dec 16, 2021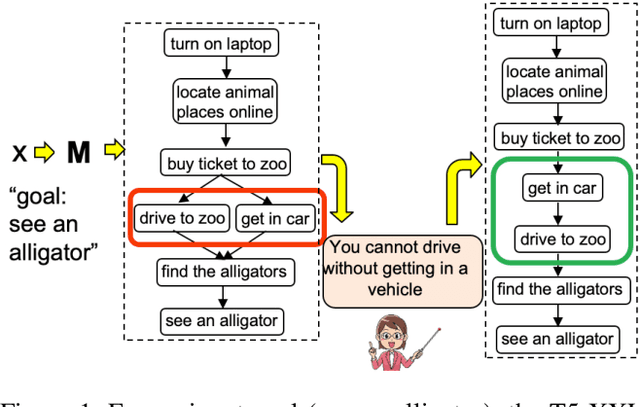
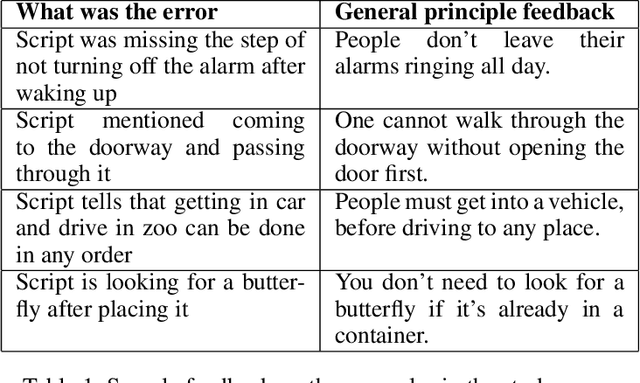
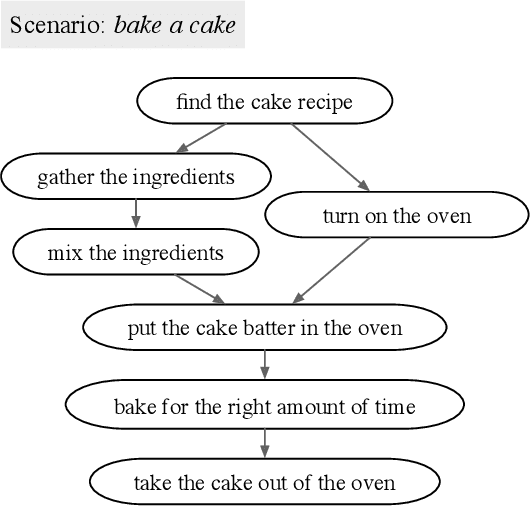

How can an end-user provide feedback if a deployed structured prediction model generates inconsistent output, ignoring the structural complexity of human language? This is an emerging topic with recent progress in synthetic or constrained settings, and the next big leap would require testing and tuning models in real-world settings. We present a new dataset, Interscript, containing user feedback on a deployed model that generates complex everyday tasks. Interscript contains 8,466 data points -- the input is a possibly erroneous script and a user feedback, and the output is a modified script. We posit two use-cases of \ours that might significantly advance the state-of-the-art in interactive learning. The dataset is available at: https://github.com/allenai/interscript.