 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Differential Privacy, There is Truth: On Vote Leakage in Ensemble Private Learning
Sep 22, 2022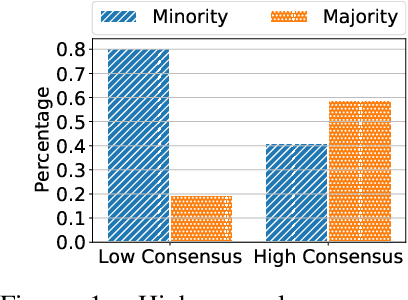

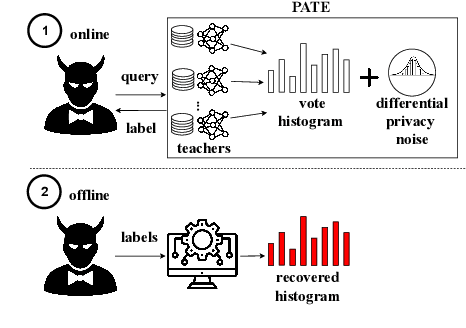
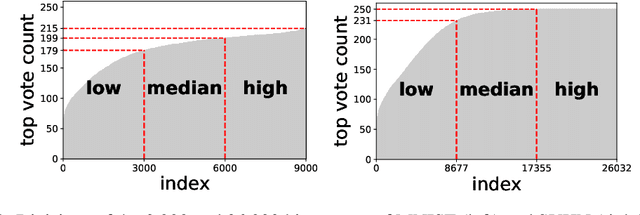
When learning from sensitive data, care must be taken to ensure that training algorithms address privacy concerns. The canonical Private Aggregation of Teacher Ensembles, or PATE, computes output labels by aggregating the predictions of a (possibly distributed) collection of teacher models via a voting mechanism. The mechanism adds noise to attain a differential privacy guarantee with respect to the teachers' training data. In this work, we observe that this use of noise, which makes PATE predictions stochastic, enables new forms of leakage of sensitive information. For a given input, our adversary exploits this stochasticity to extract high-fidelity histograms of the votes submitted by the underlying teachers. From these histograms, the adversary can learn sensitive attributes of the input such as race, gender, or age. Although this attack does not directly violate the differential privacy guarantee, it clearly violates privacy norms and expectations, and would not be possible at all without the noise inserted to obtain differential privacy. In fact, counter-intuitively, the attack becomes easier as we add more noise to provide stronger differential privacy. We hope this encourages future work to consider privacy holistically rather than treat differential privacy as a panacea.
Dataset Inference for Self-Supervised Models
Sep 16, 2022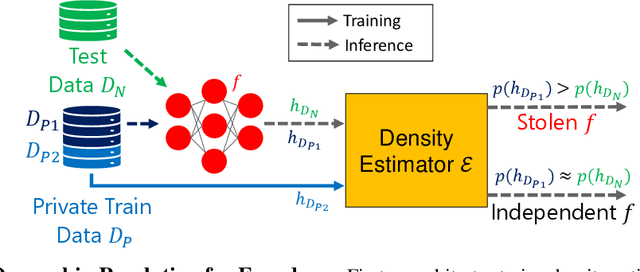
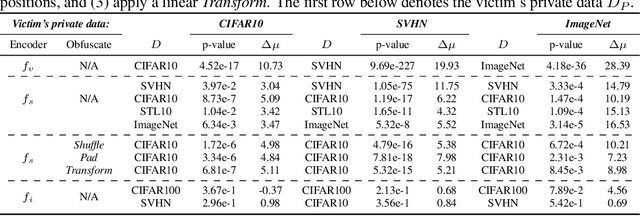
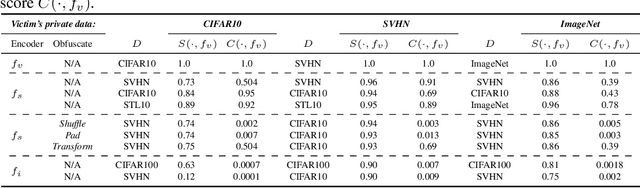
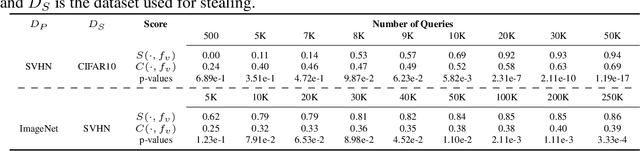
Self-supervised models are increasingly prevalent in machine learning (ML) since they reduce the need for expensively labeled data. Because of their versatility in downstream applications, they are increasingly used as a service exposed via public APIs. At the same time, these encoder models are particularly vulnerable to model stealing attacks due to the high dimensionality of vector representations they output. Yet, encoders remain undefended: existing mitigation strategies for stealing attacks focus on supervised learning. We introduce a new dataset inference defense, which uses the private training set of the victim encoder model to attribute its ownership in the event of stealing. The intuition is that the log-likelihood of an encoder's output representations is higher on the victim's training data than on test data if it is stolen from the victim, but not if it is independently trained. We compute this log-likelihood using density estimation models. As part of our evaluation, we also propose measuring the fidelity of stolen encoders and quantifying the effectiveness of the theft detection without involving downstream tasks; instead, we leverage mutual information and distance measurements. Our extensive empirical results in the vision domain demonstrate that dataset inference is a promising direction for defending self-supervised models against model stealing.
On the Fundamental Limits of Formally Proving Robustness in Proof-of-Learning
Aug 06, 2022



Proof-of-learning (PoL) proposes a model owner use machine learning training checkpoints to establish a proof of having expended the necessary compute for training. The authors of PoL forego cryptographic approaches and trade rigorous security guarantees for scalability to deep learning by being applicable to stochastic gradient descent and adaptive variants. This lack of formal analysis leaves the possibility that an attacker may be able to spoof a proof for a model they did not train. We contribute a formal analysis of why the PoL protocol cannot be formally (dis)proven to be robust against spoofing adversaries. To do so, we disentangle the two roles of proof verification in PoL: (a) efficiently determining if a proof is a valid gradient descent trajectory, and (b) establishing precedence by making it more expensive to craft a proof after training completes (i.e., spoofing). We show that efficient verification results in a tradeoff between accepting legitimate proofs and rejecting invalid proofs because deep learning necessarily involves noise. Without a precise analytical model for how this noise affects training, we cannot formally guarantee if a PoL verification algorithm is robust. Then, we demonstrate that establishing precedence robustly also reduces to an open problem in learning theory: spoofing a PoL post hoc training is akin to finding different trajectories with the same endpoint in non-convex learning. Yet, we do not rigorously know if priori knowledge of the final model weights helps discover such trajectories. We conclude that, until the aforementioned open problems are addressed, relying more heavily on cryptography is likely needed to formulate a new class of PoL protocols with formal robustness guarantees. In particular, this will help with establishing precedence. As a by-product of insights from our analysis, we also demonstrate two novel attacks against PoL.
Generative Extraction of Audio Classifiers for Speaker Identification
Jul 26, 2022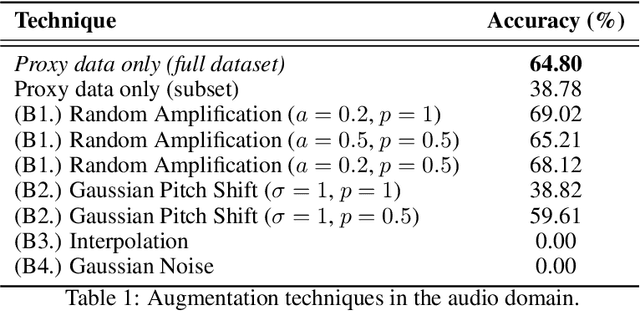
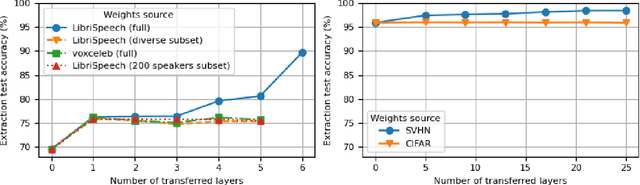

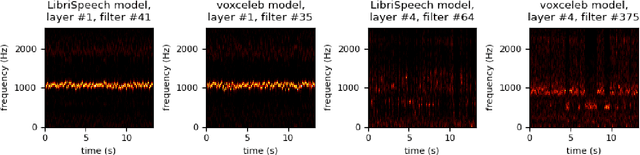
It is perhaps no longer surprising that machine learning models, especially deep neural networks, are particularly vulnerable to attacks. One such vulnerability that has been well studied is model extraction: a phenomenon in which the attacker attempts to steal a victim's model by training a surrogate model to mimic the decision boundaries of the victim model. Previous works have demonstrated the effectiveness of such an attack and its devastating consequences, but much of this work has been done primarily for image and text processing tasks. Our work is the first attempt to perform model extraction on {\em audio classification models}. We are motivated by an attacker whose goal is to mimic the behavior of the victim's model trained to identify a speaker. This is particularly problematic in security-sensitive domains such as biometric authentication. We find that prior model extraction techniques, where the attacker \textit{naively} uses a proxy dataset to attack a potential victim's model, fail. We therefore propose the use of a generative model to create a sufficiently large and diverse pool of synthetic attack queries. We find that our approach is able to extract a victim's model trained on \texttt{LibriSpeech} using queries synthesized with a proxy dataset based off of \texttt{VoxCeleb}; we achieve a test accuracy of 84.41\% with a budget of 3 million queries.
$p$-DkNN: Out-of-Distribution Detection Through Statistical Testing of Deep Representations
Jul 25, 2022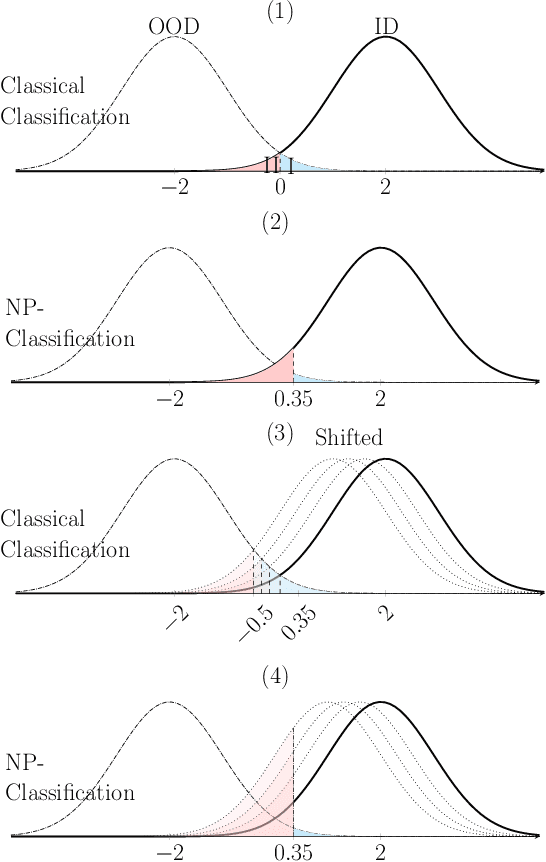
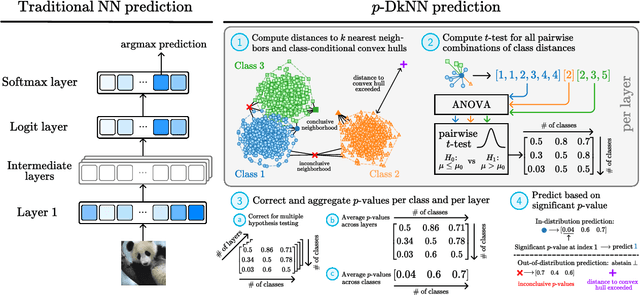
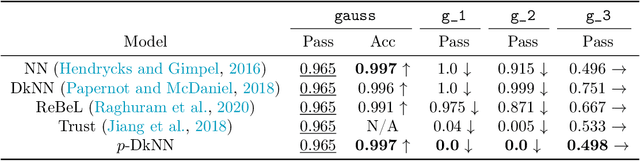
The lack of well-calibrated confidence estimates makes neural networks inadequate in safety-critical domains such as autonomous driving or healthcare. In these settings, having the ability to abstain from making a prediction on out-of-distribution (OOD) data can be as important as correctly classifying in-distribution data. We introduce $p$-DkNN, a novel inference procedure that takes a trained deep neural network and analyzes the similarity structures of its intermediate hidden representations to compute $p$-values associated with the end-to-end model prediction. The intuition is that statistical tests performed on latent representations can serve not only as a classifier, but also offer a statistically well-founded estimation of uncertainty. $p$-DkNN is scalable and leverages the composition of representations learned by hidden layers, which makes deep representation learning successful. Our theoretical analysis builds on Neyman-Pearson classification and connects it to recent advances in selective classification (reject option). We demonstrate advantageous trade-offs between abstaining from predicting on OOD inputs and maintaining high accuracy on in-distribution inputs. We find that $p$-DkNN forces adaptive attackers crafting adversarial examples, a form of worst-case OOD inputs, to introduce semantically meaningful changes to the inputs.
Efficient Adversarial Training With Data Pruning
Jul 01, 2022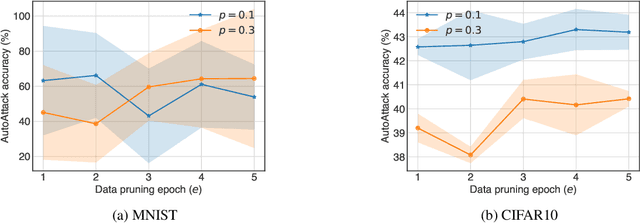
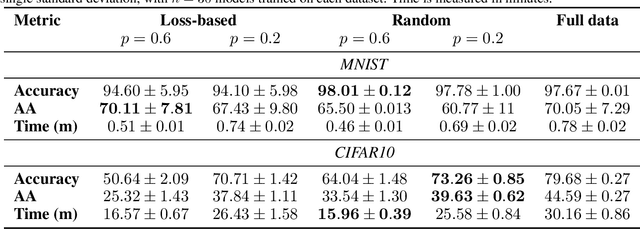
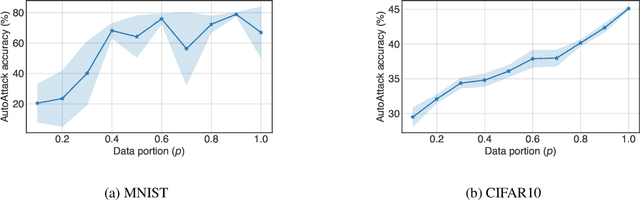

Neural networks are susceptible to adversarial examples-small input perturbations that cause models to fail. Adversarial training is one of the solutions that stops adversarial examples; models are exposed to attacks during training and learn to be resilient to them. Yet, such a procedure is currently expensive-it takes a long time to produce and train models with adversarial samples, and, what is worse, it occasionally fails. In this paper we demonstrate data pruning-a method for increasing adversarial training efficiency through data sub-sampling.We empirically show that data pruning leads to improvements in convergence and reliability of adversarial training, albeit with different levels of utility degradation. For example, we observe that using random sub-sampling of CIFAR10 to drop 40% of data, we lose 8% adversarial accuracy against the strongest attackers, while by using only 20% of data we lose 14% adversarial accuracy and reduce runtime by a factor of 3. Interestingly, we discover that in some settings data pruning brings benefits from both worlds-it both improves adversarial accuracy and training time.
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022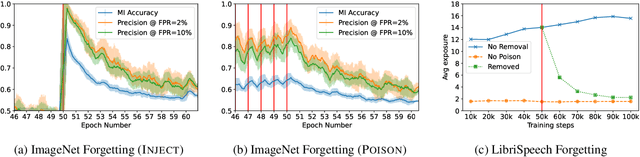
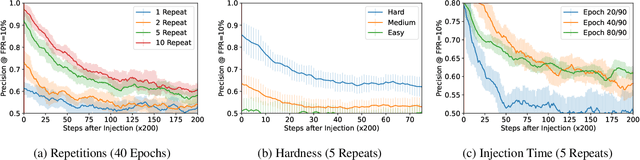
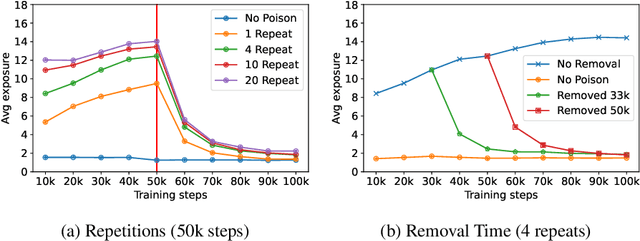
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
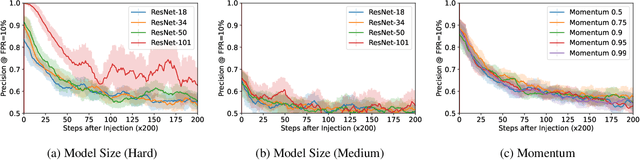
Intrinsic Anomaly Detection for Multi-Variate Time Series
Jun 29, 2022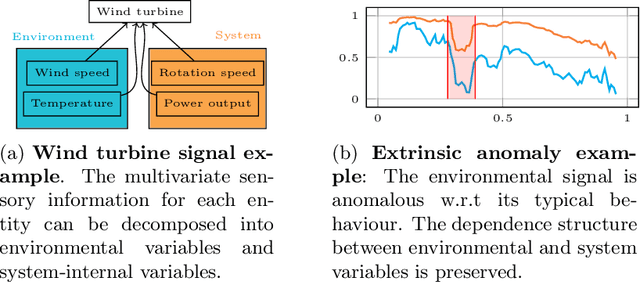

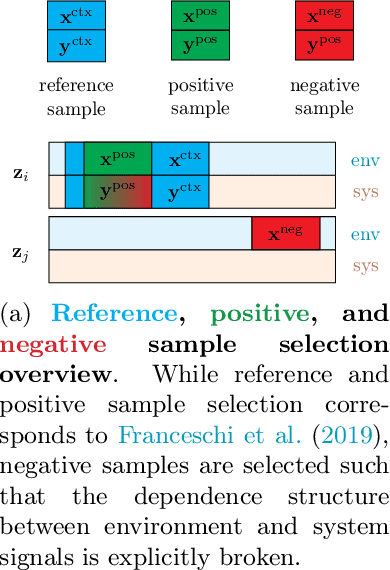
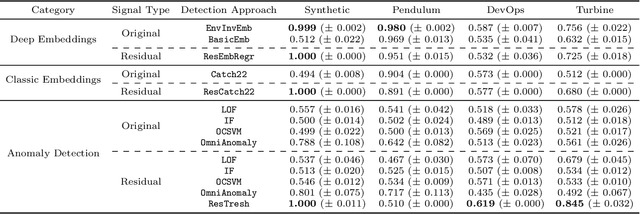
We introduce a novel, practically relevant variation of the anomaly detection problem in multi-variate time series: intrinsic anomaly detection. It appears in diverse practical scenarios ranging from DevOps to IoT, where we want to recognize failures of a system that operates under the influence of a surrounding environment. Intrinsic anomalies are changes in the functional dependency structure between time series that represent an environment and time series that represent the internal state of a system that is placed in said environment. We formalize this problem, provide under-studied public and new purpose-built data sets for it, and present methods that handle intrinsic anomaly detection. These address the short-coming of existing anomaly detection methods that cannot differentiate between expected changes in the system's state and unexpected ones, i.e., changes in the system that deviate from the environment's influence. Our most promising approach is fully unsupervised and combines adversarial learning and time series representation learning, thereby addressing problems such as label sparsity and subjectivity, while allowing to navigate and improve notoriously problematic anomaly detection data sets.
The Privacy Onion Effect: Memorization is Relative
Jun 22, 2022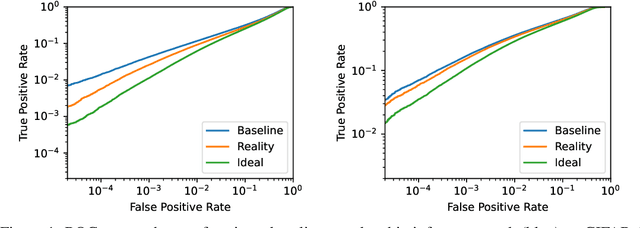
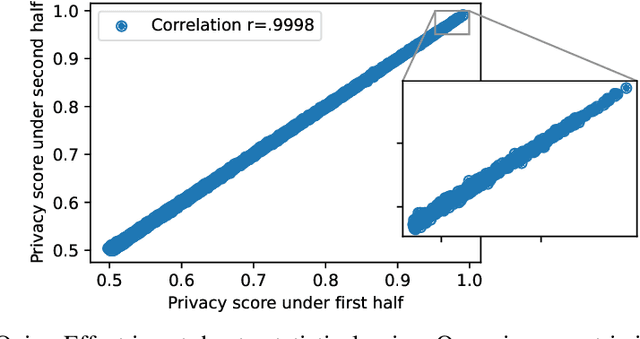
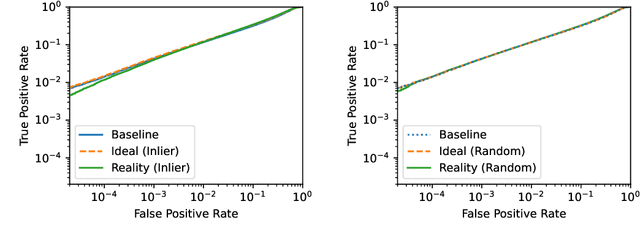
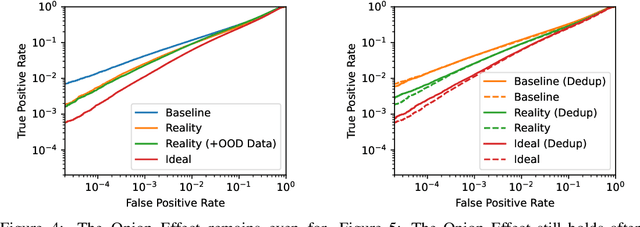
Machine learning models trained on private datasets have been shown to leak their private data. While recent work has found that the average data point is rarely leaked, the outlier samples are frequently subject to memorization and, consequently, privacy leakage. We demonstrate and analyse an Onion Effect of memorization: removing the "layer" of outlier points that are most vulnerable to a privacy attack exposes a new layer of previously-safe points to the same attack. We perform several experiments to study this effect, and understand why it occurs. The existence of this effect has various consequences. For example, it suggests that proposals to defend against memorization without training with rigorous privacy guarantees are unlikely to be effective. Further, it suggests that privacy-enhancing technologies such as machine unlearning could actually harm the privacy of other users.
On the Limitations of Stochastic Pre-processing Defenses
Jun 19, 2022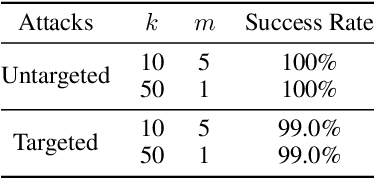
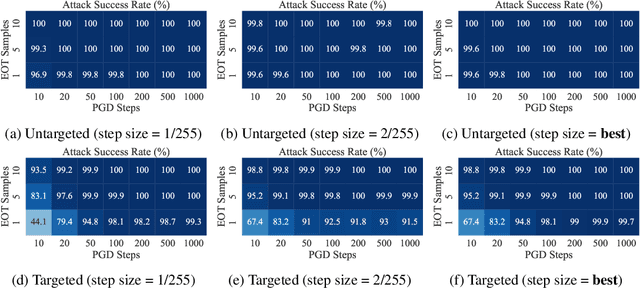
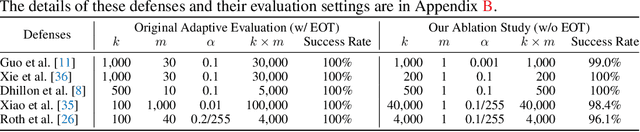
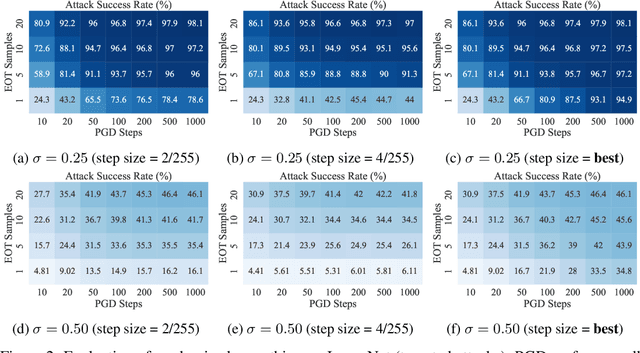
Defending against adversarial examples remains an open problem. A common belief is that randomness at inference increases the cost of finding adversarial inputs. An example of such a defense is to apply a random transformation to inputs prior to feeding them to the model. In this paper, we empirically and theoretically investigate such stochastic pre-processing defenses and demonstrate that they are flawed. First, we show that most stochastic defenses are weaker than previously thought; they lack sufficient randomness to withstand even standard attacks like projected gradient descent. This casts doubt on a long-held assumption that stochastic defenses invalidate attacks designed to evade deterministic defenses and force attackers to integrate the Expectation over Transformation (EOT) concept. Second, we show that stochastic defenses confront a trade-off between adversarial robustness and model invariance; they become less effective as the defended model acquires more invariance to their randomization. Future work will need to decouple these two effects. Our code is available in the supplementary material.