 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauss-Newton Unlearning for the LLM Era
Feb 11, 2026Standard large language model training can create models that produce outputs their trainer deems unacceptable in deployment. The probability of these outputs can be reduced using methods such as LLM unlearning. However, unlearning a set of data (called the forget set) can degrade model performance on other distributions where the trainer wants to retain the model's behavior. To improve this trade-off, we demonstrate that using the forget set to compute only a few uphill Gauss-Newton steps provides a conceptually simple, state-of-the-art unlearning approach for LLMs. While Gauss-Newton steps adapt Newton's method to non-linear models, it is non-trivial to efficiently and accurately compute such steps for LLMs. Hence, our approach crucially relies on parametric Hessian approximations such as Kronecker-Factored Approximate Curvature (K-FAC). We call this combined approach K-FADE (K-FAC for Distribution Erasure). Our evaluation on the WMDP and ToFU benchmarks demonstrates that K-FADE suppresses outputs from the forget set and approximates, in output space, the results of retraining without the forget set. Critically, our method does this while altering the outputs on the retain set less than previous methods. This is because K-FADE transforms a constraint on the model's outputs across the entire retain set into a constraint on the model's weights, allowing the algorithm to minimally change the model's behavior on the retain set at each step. Moreover, the unlearning updates computed by K-FADE can be reapplied later if the model undergoes further training, allowing unlearning to be cheaply maintained.
Leveraging Per-Instance Privacy for Machine Unlearning
May 24, 2025We present a principled, per-instance approach to quantifying the difficulty of unlearning via fine-tuning. We begin by sharpening an analysis of noisy gradient descent for unlearning (Chien et al., 2024), obtaining a better utility-unlearning tradeoff by replacing worst-case privacy loss bounds with per-instance privacy losses (Thudi et al., 2024), each of which bounds the (Renyi) divergence to retraining without an individual data point. To demonstrate the practical applicability of our theory, we present empirical results showing that our theoretical predictions are born out both for Stochastic Gradient Langevin Dynamics (SGLD) as well as for standard fine-tuning without explicit noise. We further demonstrate that per-instance privacy losses correlate well with several existing data difficulty metrics, while also identifying harder groups of data points, and introduce novel evaluation methods based on loss barriers. All together, our findings provide a foundation for more efficient and adaptive unlearning strategies tailored to the unique properties of individual data points.
Finding Optimally Robust Data Mixtures via Concave Maximization
Jun 03, 2024



Training on mixtures of data distributions is now common in many modern machine learning pipelines, useful for performing well on several downstream tasks. Group distributionally robust optimization (group DRO) is one popular way to learn mixture weights for training a specific model class, but group DRO methods suffer for non-linear models due to non-convex loss functions and when the models are non-parametric. We address these challenges by proposing to solve a more general DRO problem, giving a method we call MixMax. MixMax selects mixture weights by maximizing a particular concave objective with entropic mirror ascent, and, crucially, we prove that optimally fitting this mixture distribution over the set of bounded predictors returns a group DRO optimal model. Experimentally, we tested MixMax on a sequence modeling task with transformers and on a variety of non-parametric learning problems. In all instances MixMax matched or outperformed the standard data mixing and group DRO baselines, and in particular, MixMax improved the performance of XGBoost over the only baseline, data balancing, for variations of the ACSIncome and CelebA annotations datasets.
Unlearnable Algorithms for In-context Learning
Feb 01, 2024Machine unlearning is a desirable operation as models get increasingly deployed on data with unknown provenance. However, achieving exact unlearning -- obtaining a model that matches the model distribution when the data to be forgotten was never used -- is challenging or inefficient, often requiring significant retraining. In this paper, we focus on efficient unlearning methods for the task adaptation phase of a pretrained large language model (LLM). We observe that an LLM's ability to do in-context learning for task adaptation allows for efficient exact unlearning of task adaptation training data. We provide an algorithm for selecting few-shot training examples to prepend to the prompt given to an LLM (for task adaptation), ERASE, whose unlearning operation cost is independent of model and dataset size, meaning it scales to large models and datasets. We additionally compare our approach to fine-tuning approaches and discuss the trade-offs between the two approaches. This leads us to propose a new holistic measure of unlearning cost which accounts for varying inference costs, and conclude that in-context learning can often be more favourable than fine-tuning for deployments involving unlearning requests.
Gradients Look Alike: Sensitivity is Often Overestimated in DP-SGD
Jul 01, 2023



Differentially private stochastic gradient descent (DP-SGD) is the canonical algorithm for private deep learning. While it is known that its privacy analysis is tight in the worst-case, several empirical results suggest that when training on common benchmark datasets, the models obtained leak significantly less privacy for many datapoints. In this paper, we develop a new analysis for DP-SGD that captures the intuition that points with similar neighbors in the dataset enjoy better privacy than outliers. Formally, this is done by modifying the per-step privacy analysis of DP-SGD to introduce a dependence on the distribution of model updates computed from a training dataset. We further develop a new composition theorem to effectively use this new per-step analysis to reason about an entire training run. Put all together, our evaluation shows that this novel DP-SGD analysis allows us to now formally show that DP-SGD leaks significantly less privacy for many datapoints. In particular, we observe that correctly classified points obtain better privacy guarantees than misclassified points.
Training Private Models That Know What They Don't Know
May 28, 2023Training reliable deep learning models which avoid making overconfident but incorrect predictions is a longstanding challenge. This challenge is further exacerbated when learning has to be differentially private: protection provided to sensitive data comes at the price of injecting additional randomness into the learning process. In this work, we conduct a thorough empirical investigation of selective classifiers -- that can abstain when they are unsure -- under a differential privacy constraint. We find that several popular selective prediction approaches are ineffective in a differentially private setting as they increase the risk of privacy leakage. At the same time, we identify that a recent approach that only uses checkpoints produced by an off-the-shelf private learning algorithm stands out as particularly suitable under DP. Further, we show that differential privacy does not just harm utility but also degrades selective classification performance. To analyze this effect across privacy levels, we propose a novel evaluation mechanism which isolate selective prediction performance across model utility levels. Our experimental results show that recovering the performance level attainable by non-private models is possible but comes at a considerable coverage cost as the privacy budget decreases.
On the Fundamental Limits of Formally Proving Robustness in Proof-of-Learning
Aug 06, 2022



Proof-of-learning (PoL) proposes a model owner use machine learning training checkpoints to establish a proof of having expended the necessary compute for training. The authors of PoL forego cryptographic approaches and trade rigorous security guarantees for scalability to deep learning by being applicable to stochastic gradient descent and adaptive variants. This lack of formal analysis leaves the possibility that an attacker may be able to spoof a proof for a model they did not train. We contribute a formal analysis of why the PoL protocol cannot be formally (dis)proven to be robust against spoofing adversaries. To do so, we disentangle the two roles of proof verification in PoL: (a) efficiently determining if a proof is a valid gradient descent trajectory, and (b) establishing precedence by making it more expensive to craft a proof after training completes (i.e., spoofing). We show that efficient verification results in a tradeoff between accepting legitimate proofs and rejecting invalid proofs because deep learning necessarily involves noise. Without a precise analytical model for how this noise affects training, we cannot formally guarantee if a PoL verification algorithm is robust. Then, we demonstrate that establishing precedence robustly also reduces to an open problem in learning theory: spoofing a PoL post hoc training is akin to finding different trajectories with the same endpoint in non-convex learning. Yet, we do not rigorously know if priori knowledge of the final model weights helps discover such trajectories. We conclude that, until the aforementioned open problems are addressed, relying more heavily on cryptography is likely needed to formulate a new class of PoL protocols with formal robustness guarantees. In particular, this will help with establishing precedence. As a by-product of insights from our analysis, we also demonstrate two novel attacks against PoL.
Selective Classification Via Neural Network Training Dynamics
May 26, 2022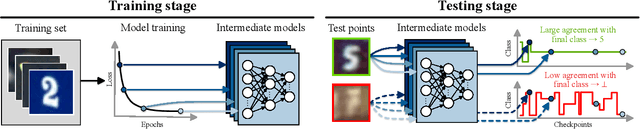
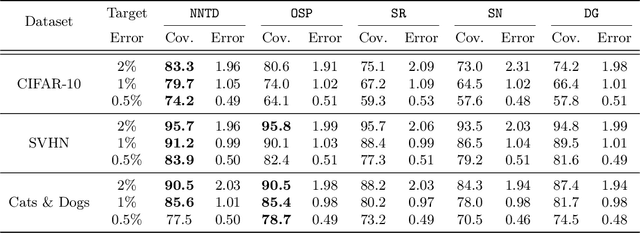
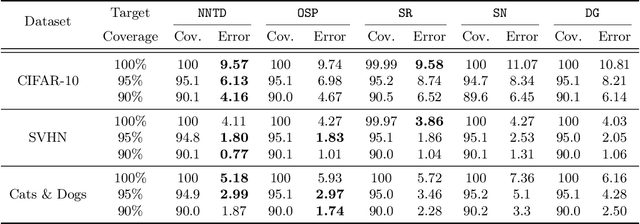
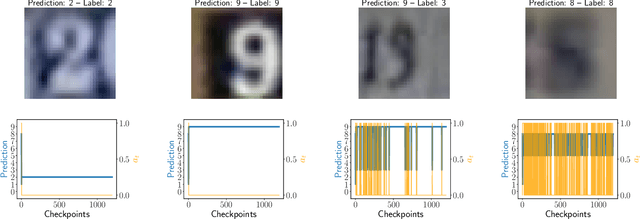
Selective classification is the task of rejecting inputs a model would predict incorrectly on through a trade-off between input space coverage and model accuracy. Current methods for selective classification impose constraints on either the model architecture or the loss function; this inhibits their usage in practice. In contrast to prior work, we show that state-of-the-art selective classification performance can be attained solely from studying the (discretized) training dynamics of a model. We propose a general framework that, for a given test input, monitors metrics capturing the disagreement with the final predicted label over intermediate models obtained during training; we then reject data points exhibiting too much disagreement at late stages in training. In particular, we instantiate a method that tracks when the label predicted during training stops disagreeing with the final predicted label. Our experimental evaluation shows that our method achieves state-of-the-art accuracy/coverage trade-offs on typical selective classification benchmarks. For example, we improve coverage on CIFAR-10/SVHN by 10.1%/1.5% respectively at a fixed target error of 0.5%.
Bounding Membership Inference
Feb 24, 2022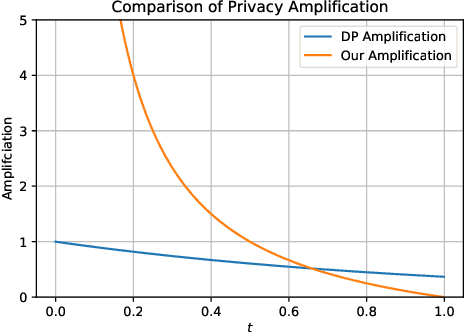

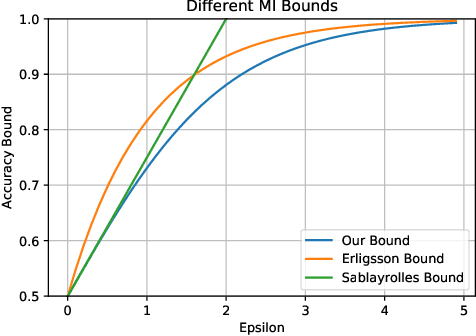
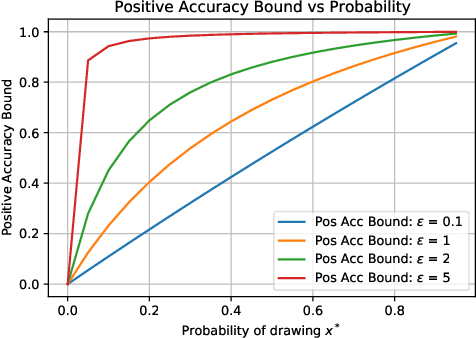
Differential Privacy (DP) is the de facto standard for reasoning about the privacy guarantees of a training algorithm. Despite the empirical observation that DP reduces the vulnerability of models to existing membership inference (MI) attacks, a theoretical underpinning as to why this is the case is largely missing in the literature. In practice, this means that models need to be trained with DP guarantees that greatly decrease their accuracy. In this paper, we provide a tighter bound on the accuracy of any MI adversary when a training algorithm provides $\epsilon$-DP. Our bound informs the design of a novel privacy amplification scheme, where an effective training set is sub-sampled from a larger set prior to the beginning of training, to greatly reduce the bound on MI accuracy. As a result, our scheme enables $\epsilon$-DP users to employ looser DP guarantees when training their model to limit the success of any MI adversary; this ensures that the model's accuracy is less impacted by the privacy guarantee. Finally, we discuss implications of our MI bound on the field of machine unlearning.
On the Necessity of Auditable Algorithmic Definitions for Machine Unlearning
Oct 22, 2021

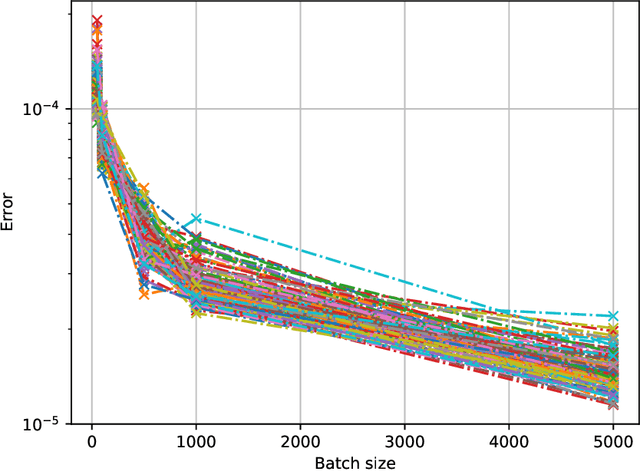
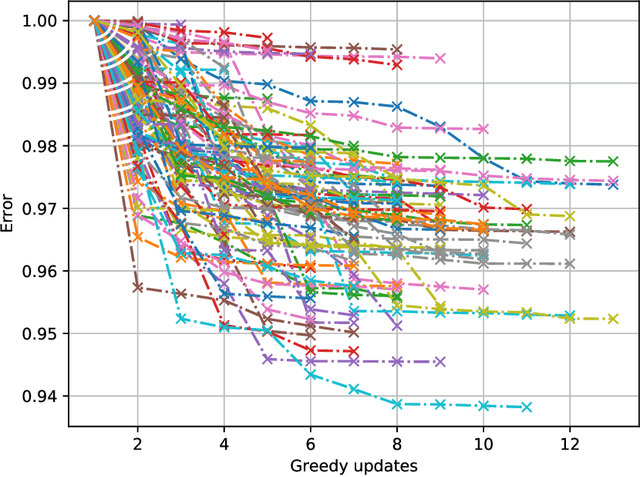
Machine unlearning, i.e. having a model forget about some of its training data, has become increasingly more important as privacy legislation promotes variants of the right-to-be-forgotten. In the context of deep learning, approaches for machine unlearning are broadly categorized into two classes: exact unlearning methods, where an entity has formally removed the data point's impact on the model by retraining the model from scratch, and approximate unlearning, where an entity approximates the model parameters one would obtain by exact unlearning to save on compute costs. In this paper we first show that the definition that underlies approximate unlearning, which seeks to prove the approximately unlearned model is close to an exactly retrained model, is incorrect because one can obtain the same model using different datasets. Thus one could unlearn without modifying the model at all. We then turn to exact unlearning approaches and ask how to verify their claims of unlearning. Our results show that even for a given training trajectory one cannot formally prove the absence of certain data points used during training. We thus conclude that unlearning is only well-defined at the algorithmic level, where an entity's only possible auditable claim to unlearning is that they used a particular algorithm designed to allow for external scrutiny during an audit.