 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Erasure Illusion: Stress-Testing the Generalization of LLM Forgetting Evaluation
Dec 23, 2025Machine unlearning aims to remove specific data influences from trained models, a capability essential for adhering to copyright laws and ensuring AI safety. Current unlearning metrics typically measure success by monitoring the model's performance degradation on the specific unlearning dataset ($D_u$). We argue that for Large Language Models (LLMs), this evaluation paradigm is insufficient and potentially misleading. Many real-world uses of unlearning--motivated by copyright or safety--implicitly target not only verbatim content in $D_u$, but also behaviors influenced by the broader generalizations the model derived from it. We demonstrate that LLMs can pass standard unlearning evaluation and appear to have "forgotten" the target knowledge, while simultaneously retaining strong capabilities on content that is semantically adjacent to $D_u$. This phenomenon indicates that erasing exact sentences does not necessarily equate to removing the underlying knowledge. To address this gap, we propose Proximal Surrogate Generation (PSG), an automated stress-testing framework that generates a surrogate dataset, $\tilde{D}_u$. This surrogate set is constructed to be semantically derived from $D_u$ yet sufficiently distinct in embedding space. By comparing unlearning metric scores between $D_u$ and $\tilde{D}_u$, we can stress-test the reliability of the metric itself. Our extensive evaluation across three LLM families (Llama-3-8B, Qwen2.5-7B, and Zephyr-7B-$β$), three distinct datasets, and seven standard metrics reveals widespread inconsistencies. We find that current metrics frequently overestimate unlearning success, failing to detect retained knowledge exposed by our stress-test datasets.
Backdoor Detection through Replicated Execution of Outsourced Training
Mar 31, 2025



It is common practice to outsource the training of machine learning models to cloud providers. Clients who do so gain from the cloud's economies of scale, but implicitly assume trust: the server should not deviate from the client's training procedure. A malicious server may, for instance, seek to insert backdoors in the model. Detecting a backdoored model without prior knowledge of both the backdoor attack and its accompanying trigger remains a challenging problem. In this paper, we show that a client with access to multiple cloud providers can replicate a subset of training steps across multiple servers to detect deviation from the training procedure in a similar manner to differential testing. Assuming some cloud-provided servers are benign, we identify malicious servers by the substantial difference between model updates required for backdooring and those resulting from clean training. Perhaps the strongest advantage of our approach is its suitability to clients that have limited-to-no local compute capability to perform training; we leverage the existence of multiple cloud providers to identify malicious updates without expensive human labeling or heavy computation. We demonstrate the capabilities of our approach on an outsourced supervised learning task where $50\%$ of the cloud providers insert their own backdoor; our approach is able to correctly identify $99.6\%$ of them. In essence, our approach is successful because it replaces the signature-based paradigm taken by existing approaches with an anomaly-based detection paradigm. Furthermore, our approach is robust to several attacks from adaptive adversaries utilizing knowledge of our detection scheme.
LLM Dataset Inference: Did you train on my dataset?
Jun 10, 2024



The proliferation of large language models (LLMs) in the real world has come with a rise in copyright cases against companies for training their models on unlicensed data from the internet. Recent works have presented methods to identify if individual text sequences were members of the model's training data, known as membership inference attacks (MIAs). We demonstrate that the apparent success of these MIAs is confounded by selecting non-members (text sequences not used for training) belonging to a different distribution from the members (e.g., temporally shifted recent Wikipedia articles compared with ones used to train the model). This distribution shift makes membership inference appear successful. However, most MIA methods perform no better than random guessing when discriminating between members and non-members from the same distribution (e.g., in this case, the same period of time). Even when MIAs work, we find that different MIAs succeed at inferring membership of samples from different distributions. Instead, we propose a new dataset inference method to accurately identify the datasets used to train large language models. This paradigm sits realistically in the modern-day copyright landscape, where authors claim that an LLM is trained over multiple documents (such as a book) written by them, rather than one particular paragraph. While dataset inference shares many of the challenges of membership inference, we solve it by selectively combining the MIAs that provide positive signal for a given distribution, and aggregating them to perform a statistical test on a given dataset. Our approach successfully distinguishes the train and test sets of different subsets of the Pile with statistically significant p-values < 0.1, without any false positives.
Gradients Look Alike: Sensitivity is Often Overestimated in DP-SGD
Jul 01, 2023



Differentially private stochastic gradient descent (DP-SGD) is the canonical algorithm for private deep learning. While it is known that its privacy analysis is tight in the worst-case, several empirical results suggest that when training on common benchmark datasets, the models obtained leak significantly less privacy for many datapoints. In this paper, we develop a new analysis for DP-SGD that captures the intuition that points with similar neighbors in the dataset enjoy better privacy than outliers. Formally, this is done by modifying the per-step privacy analysis of DP-SGD to introduce a dependence on the distribution of model updates computed from a training dataset. We further develop a new composition theorem to effectively use this new per-step analysis to reason about an entire training run. Put all together, our evaluation shows that this novel DP-SGD analysis allows us to now formally show that DP-SGD leaks significantly less privacy for many datapoints. In particular, we observe that correctly classified points obtain better privacy guarantees than misclassified points.
On the Fundamental Limits of Formally Proving Robustness in Proof-of-Learning
Aug 06, 2022



Proof-of-learning (PoL) proposes a model owner use machine learning training checkpoints to establish a proof of having expended the necessary compute for training. The authors of PoL forego cryptographic approaches and trade rigorous security guarantees for scalability to deep learning by being applicable to stochastic gradient descent and adaptive variants. This lack of formal analysis leaves the possibility that an attacker may be able to spoof a proof for a model they did not train. We contribute a formal analysis of why the PoL protocol cannot be formally (dis)proven to be robust against spoofing adversaries. To do so, we disentangle the two roles of proof verification in PoL: (a) efficiently determining if a proof is a valid gradient descent trajectory, and (b) establishing precedence by making it more expensive to craft a proof after training completes (i.e., spoofing). We show that efficient verification results in a tradeoff between accepting legitimate proofs and rejecting invalid proofs because deep learning necessarily involves noise. Without a precise analytical model for how this noise affects training, we cannot formally guarantee if a PoL verification algorithm is robust. Then, we demonstrate that establishing precedence robustly also reduces to an open problem in learning theory: spoofing a PoL post hoc training is akin to finding different trajectories with the same endpoint in non-convex learning. Yet, we do not rigorously know if priori knowledge of the final model weights helps discover such trajectories. We conclude that, until the aforementioned open problems are addressed, relying more heavily on cryptography is likely needed to formulate a new class of PoL protocols with formal robustness guarantees. In particular, this will help with establishing precedence. As a by-product of insights from our analysis, we also demonstrate two novel attacks against PoL.
On the Necessity of Auditable Algorithmic Definitions for Machine Unlearning
Oct 22, 2021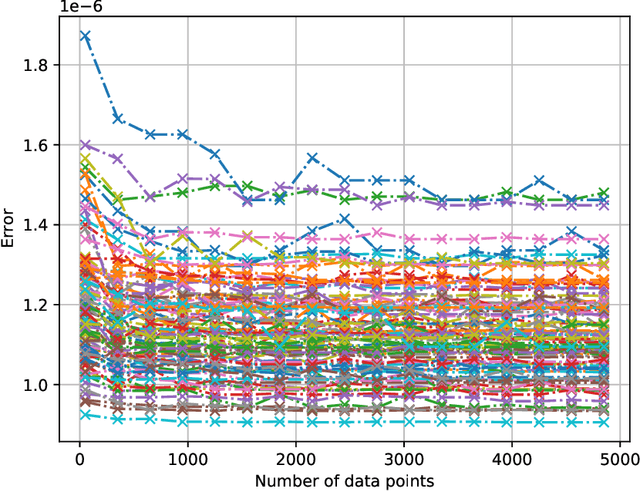

Machine unlearning, i.e. having a model forget about some of its training data, has become increasingly more important as privacy legislation promotes variants of the right-to-be-forgotten. In the context of deep learning, approaches for machine unlearning are broadly categorized into two classes: exact unlearning methods, where an entity has formally removed the data point's impact on the model by retraining the model from scratch, and approximate unlearning, where an entity approximates the model parameters one would obtain by exact unlearning to save on compute costs. In this paper we first show that the definition that underlies approximate unlearning, which seeks to prove the approximately unlearned model is close to an exactly retrained model, is incorrect because one can obtain the same model using different datasets. Thus one could unlearn without modifying the model at all. We then turn to exact unlearning approaches and ask how to verify their claims of unlearning. Our results show that even for a given training trajectory one cannot formally prove the absence of certain data points used during training. We thus conclude that unlearning is only well-defined at the algorithmic level, where an entity's only possible auditable claim to unlearning is that they used a particular algorithm designed to allow for external scrutiny during an audit.
SoK: Machine Learning Governance
Sep 20, 2021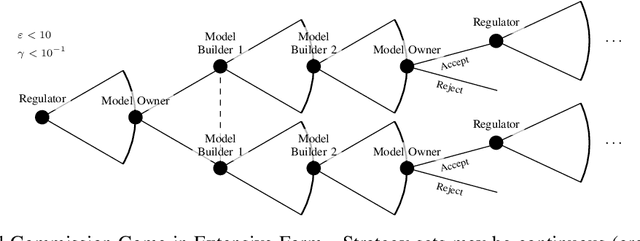
The application of machine learning (ML) in computer systems introduces not only many benefits but also risks to society. In this paper, we develop the concept of ML governance to balance such benefits and risks, with the aim of achieving responsible applications of ML. Our approach first systematizes research towards ascertaining ownership of data and models, thus fostering a notion of identity specific to ML systems. Building on this foundation, we use identities to hold principals accountable for failures of ML systems through both attribution and auditing. To increase trust in ML systems, we then survey techniques for developing assurance, i.e., confidence that the system meets its security requirements and does not exhibit certain known failures. This leads us to highlight the need for techniques that allow a model owner to manage the life cycle of their system, e.g., to patch or retire their ML system. Put altogether, our systematization of knowledge standardizes the interactions between principals involved in the deployment of ML throughout its life cycle. We highlight opportunities for future work, e.g., to formalize the resulting game between ML principals.
Proof-of-Learning: Definitions and Practice
Mar 09, 2021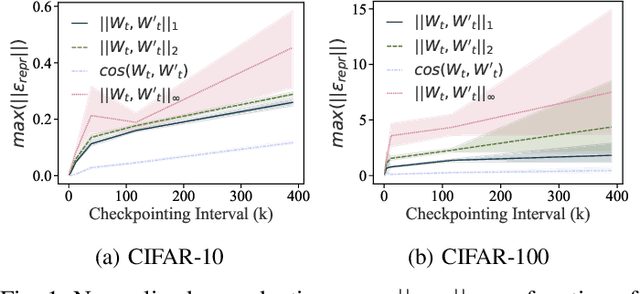
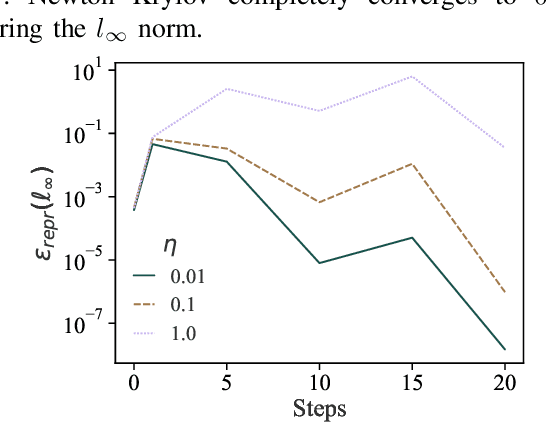
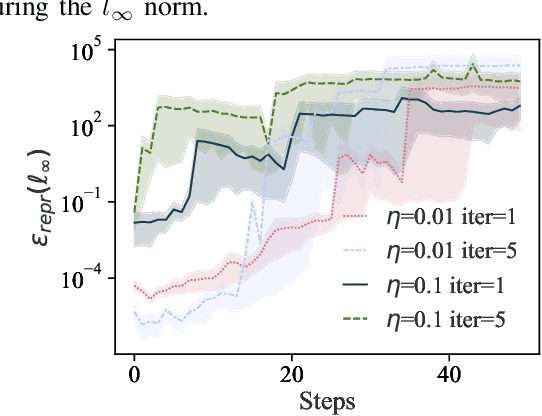
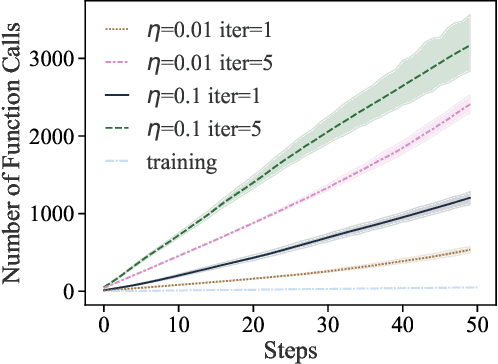
Training machine learning (ML) models typically involves expensive iterative optimization. Once the model's final parameters are released, there is currently no mechanism for the entity which trained the model to prove that these parameters were indeed the result of this optimization procedure. Such a mechanism would support security of ML applications in several ways. For instance, it would simplify ownership resolution when multiple parties contest ownership of a specific model. It would also facilitate the distributed training across untrusted workers where Byzantine workers might otherwise mount a denial-of-service by returning incorrect model updates. In this paper, we remediate this problem by introducing the concept of proof-of-learning in ML. Inspired by research on both proof-of-work and verified computations, we observe how a seminal training algorithm, stochastic gradient descent, accumulates secret information due to its stochasticity. This produces a natural construction for a proof-of-learning which demonstrates that a party has expended the compute require to obtain a set of model parameters correctly. In particular, our analyses and experiments show that an adversary seeking to illegitimately manufacture a proof-of-learning needs to perform *at least* as much work than is needed for gradient descent itself. We also instantiate a concrete proof-of-learning mechanism in both of the scenarios described above. In model ownership resolution, it protects the intellectual property of models released publicly. In distributed training, it preserves availability of the training procedure. Our empirical evaluation validates that our proof-of-learning mechanism is robust to variance induced by the hardware (ML accelerators) and software stacks.
Entangled Watermarks as a Defense against Model Extraction
Feb 27, 2020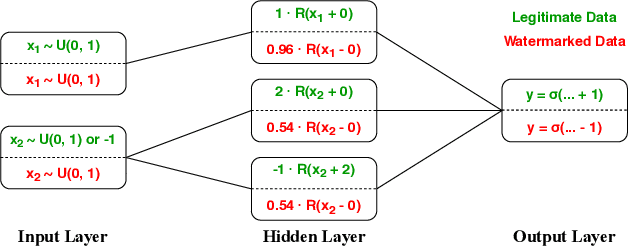


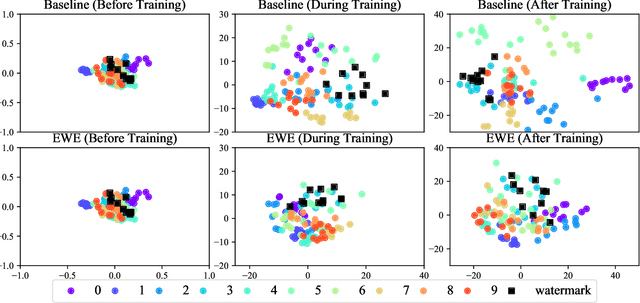
Machine learning involves expensive data collection and training procedures. Model owners may be concerned that valuable intellectual property can be leaked if adversaries mount model extraction attacks. Because it is difficult to defend against model extraction without sacrificing significant prediction accuracy, watermarking leverages unused model capacity to have the model overfit to outlier input-output pairs, which are not sampled from the task distribution and are only known to the defender. The defender then demonstrates knowledge of the input-output pairs to claim ownership of the model at inference. The effectiveness of watermarks remains limited because they are distinct from the task distribution and can thus be easily removed through compression or other forms of knowledge transfer. We introduce Entangled Watermarking Embeddings (EWE). Our approach encourages the model to learn common features for classifying data that is sampled from the task distribution, but also data that encodes watermarks. An adversary attempting to remove watermarks that are entangled with legitimate data is also forced to sacrifice performance on legitimate data. Experiments on MNIST, Fashion-MNIST, and Google Speech Commands validate that the defender can claim model ownership with 95% confidence after less than 10 queries to the stolen copy, at a modest cost of 1% accuracy in the defended model's performance.
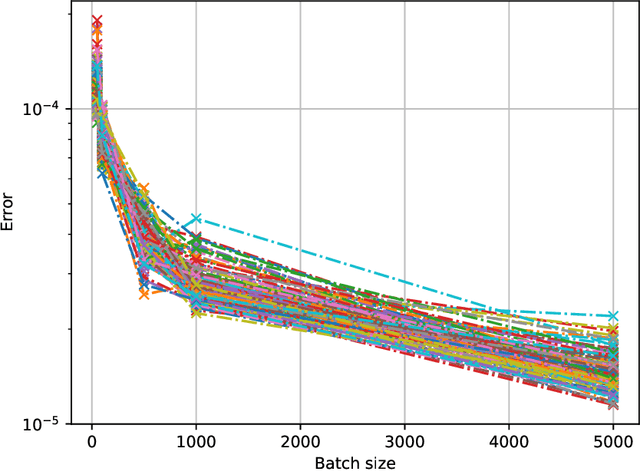
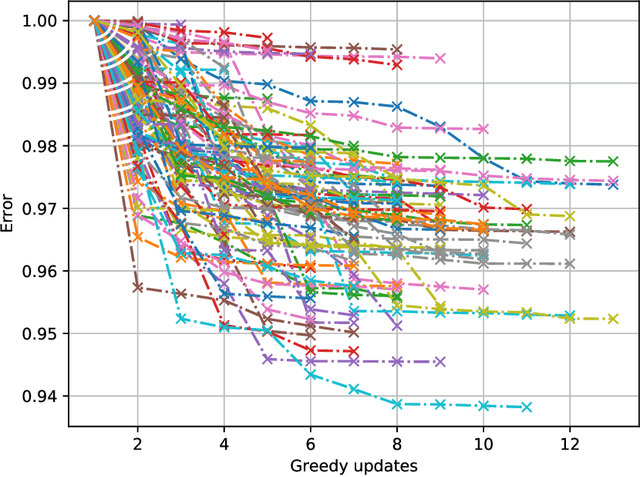
Machine Unlearning
Dec 09, 2019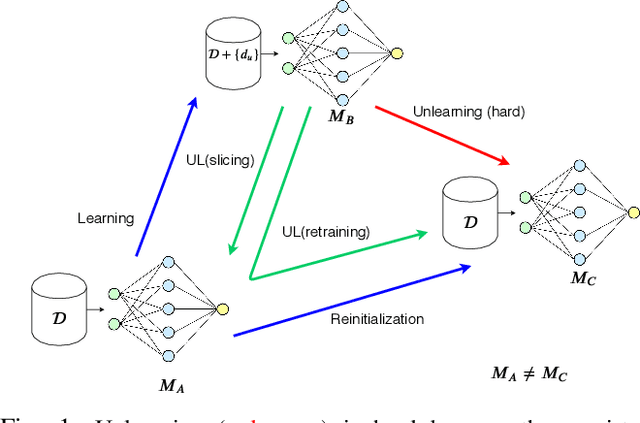
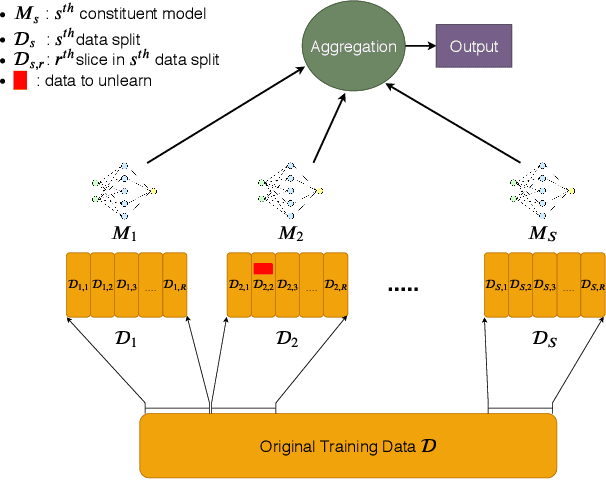
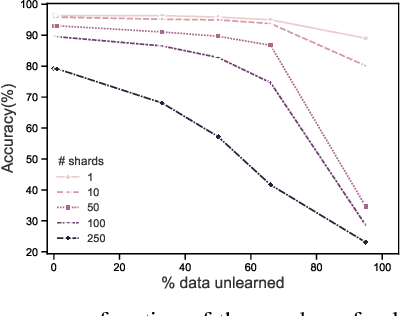
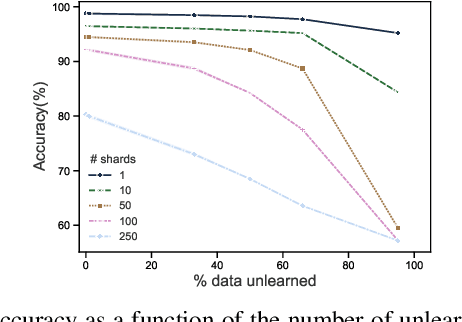
Once users have shared their data online, it is generally difficult for them to revoke access and ask for the data to be deleted. Machine learning (ML) exacerbates this problem because any model trained with said data may have memorized it, putting users at risk of a successful privacy attack exposing their information. Yet, having models unlearn is notoriously difficult. After a data point is removed from a training set, one often resorts to entirely retraining downstream models from scratch. We introduce SISA training, a framework that decreases the number of model parameters affected by an unlearning request and caches intermediate outputs of the training algorithm to limit the number of model updates that need to be computed to have these parameters unlearn. This framework reduces the computational overhead associated with unlearning, even in the worst-case setting where unlearning requests are made uniformly across the training set. In some cases, we may have a prior on the distribution of unlearning requests that will be issued by users. We may take this prior into account to partition and order data accordingly and further decrease overhead from unlearning. Our evaluation spans two datasets from different application domains, with corresponding motivations for unlearning. Under no distributional assumptions, we observe that SISA training improves unlearning for the Purchase dataset by 3.13x, and 1.658x for the SVHN dataset, over retraining from scratch. We also validate how knowledge of the unlearning distribution provides further improvements in retraining time by simulating a scenario where we model unlearning requests that come from users of a commercial product that is available in countries with varying sensitivity to privacy. Our work contributes to practical data governance in machine learning.