 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePex: Memory-efficient Microcontroller Deep Learning through Partial Execution
Nov 30, 2022



Embedded and IoT devices, largely powered by microcontroller units (MCUs), could be made more intelligent by leveraging on-device deep learning. One of the main challenges of neural network inference on an MCU is the extremely limited amount of read-write on-chip memory (SRAM, < 512 kB). SRAM is consumed by the neural network layer (operator) input and output buffers, which, traditionally, must be in memory (materialised) for an operator to execute. We discuss a novel execution paradigm for microcontroller deep learning, which modifies the execution of neural networks to avoid materialising full buffers in memory, drastically reducing SRAM usage with no computation overhead. This is achieved by exploiting the properties of operators, which can consume/produce a fraction of their input/output at a time. We describe a partial execution compiler, Pex, which produces memory-efficient execution schedules automatically by identifying subgraphs of operators whose execution can be split along the feature ("channel") dimension. Memory usage is reduced further by targeting memory bottlenecks with structured pruning, leading to the co-design of the network architecture and its execution schedule. Our evaluation of image and audio classification models: (a) establishes state-of-the-art performance in low SRAM usage regimes for considered tasks with up to +2.9% accuracy increase; (b) finds that a 4x memory reduction is possible by applying partial execution alone, or up to 10.5x when using the compiler-pruning co-design, while maintaining the classification accuracy compared to prior work; (c) uses the recovered SRAM to process higher resolution inputs instead, increasing accuracy by up to +3.9% on Visual Wake Words.
The Future of Consumer Edge-AI Computing
Oct 19, 2022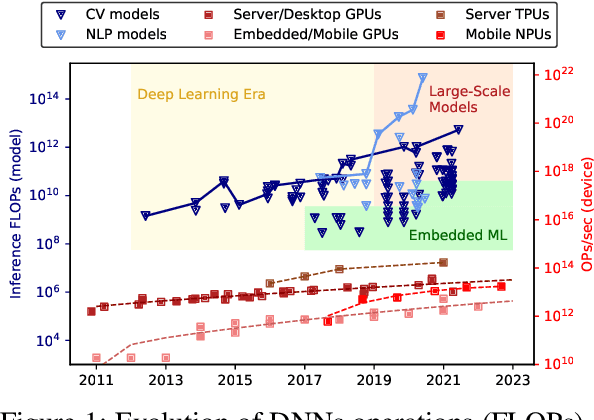
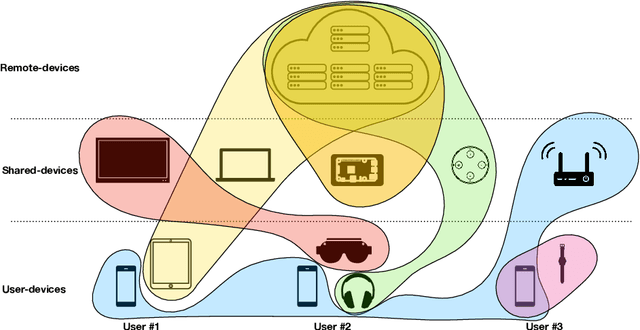
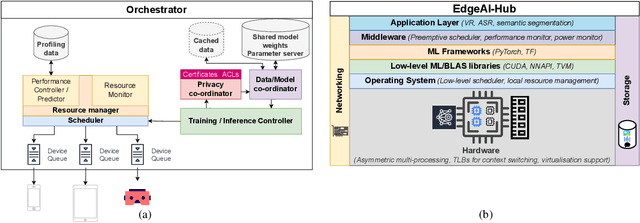
Deep Learning has proliferated dramatically across consumer devices in less than a decade, but has been largely powered through the hardware acceleration within isolated devices. Nonetheless, clear signals exist that the next decade of consumer intelligence will require levels of resources, a mixing of modalities and a collaboration of devices that will demand a significant pivot beyond hardware alone. To accomplish this, we believe a new Edge-AI paradigm will be necessary for this transition to be possible in a sustainable manner, without trespassing user-privacy or hurting quality of experience.
Match to Win: Analysing Sequences Lengths for Efficient Self-supervised Learning in Speech and Audio
Oct 03, 2022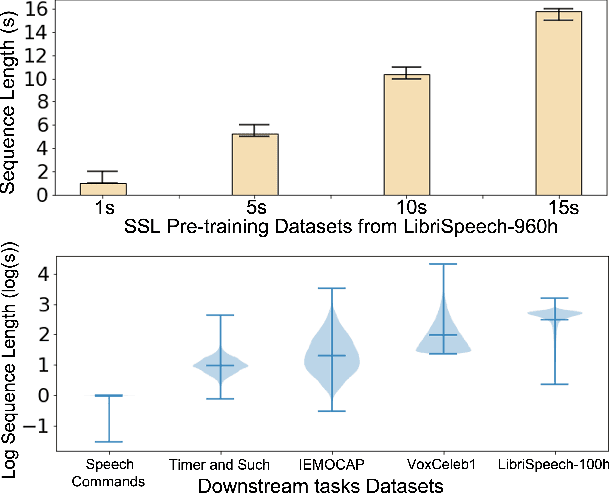

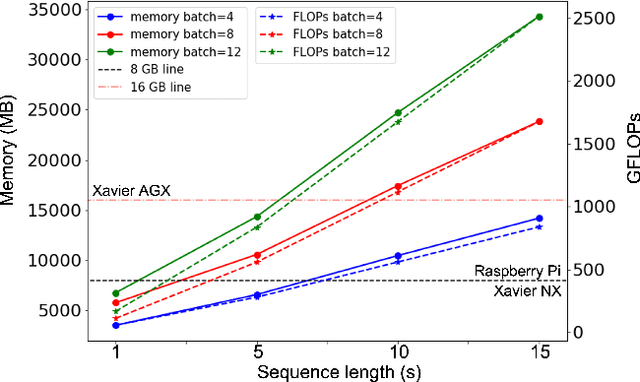
Self-supervised learning (SSL) has proven vital in speech and audio-related applications. The paradigm trains a general model on unlabeled data that can later be used to solve specific downstream tasks. This type of model is costly to train as it requires manipulating long input sequences that can only be handled by powerful centralised servers. Surprisingly, despite many attempts to increase training efficiency through model compression, the effects of truncating input sequence lengths to reduce computation have not been studied. In this paper, we provide the first empirical study of SSL pre-training for different specified sequence lengths and link this to various downstream tasks. We find that training on short sequences can dramatically reduce resource costs while retaining a satisfactory performance for all tasks. This simple one-line change would promote the migration of SSL training from data centres to user-end edge devices for more realistic and personalised applications.
Fluid Batching: Exit-Aware Preemptive Serving of Early-Exit Neural Networks on Edge NPUs
Sep 27, 2022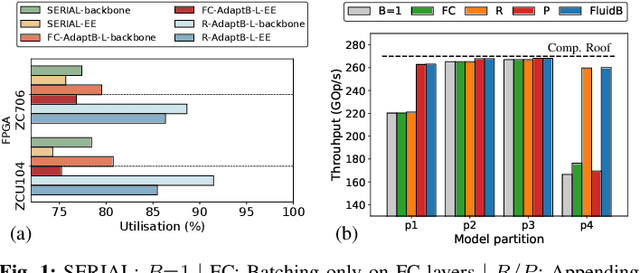
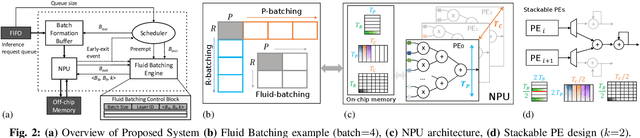
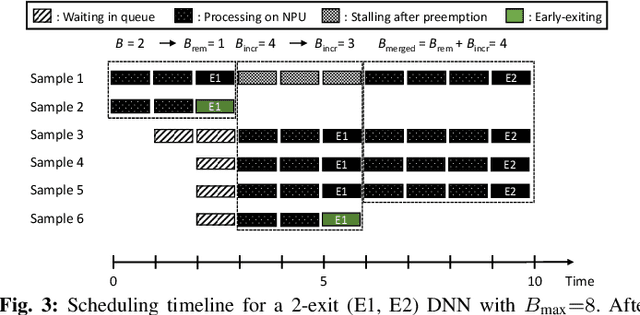
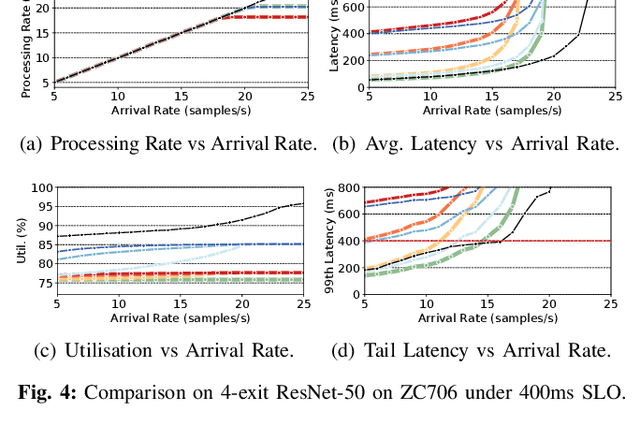
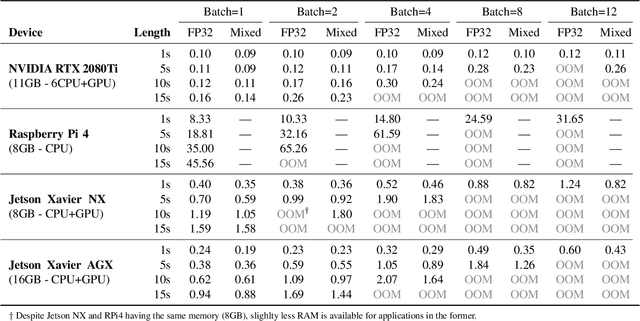
With deep neural networks (DNNs) emerging as the backbone in a multitude of computer vision tasks, their adoption in real-world consumer applications broadens continuously. Given the abundance and omnipresence of smart devices, "smart ecosystems" are being formed where sensing happens simultaneously rather than standalone. This is shifting the on-device inference paradigm towards deploying centralised neural processing units (NPUs) at the edge, where multiple devices (e.g. in smart homes or autonomous vehicles) can stream their data for processing with dynamic rates. While this provides enhanced potential for input batching, naive solutions can lead to subpar performance and quality of experience, especially under spiking loads. At the same time, the deployment of dynamic DNNs, comprising stochastic computation graphs (e.g. early-exit (EE) models), introduces a new dimension of dynamic behaviour in such systems. In this work, we propose a novel early-exit-aware scheduling algorithm that allows sample preemption at run time, to account for the dynamicity introduced both by the arrival and early-exiting processes. At the same time, we introduce two novel dimensions to the design space of the NPU hardware architecture, namely Fluid Batching and Stackable Processing Elements, that enable run-time adaptability to different batch sizes and significantly improve the NPU utilisation even at small batch sizes. Our evaluation shows that our system achieves an average 1.97x and 6.7x improvement over state-of-the-art DNN streaming systems in terms of average latency and tail latency SLO satisfaction, respectively.
Adaptable Butterfly Accelerator for Attention-based NNs via Hardware and Algorithm Co-design
Sep 20, 2022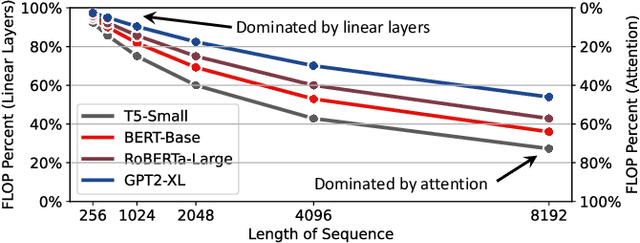
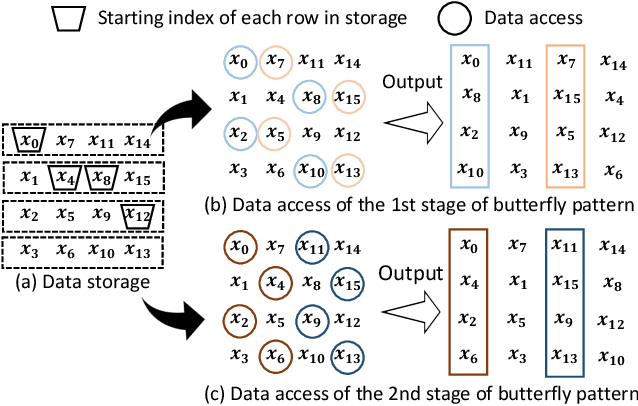
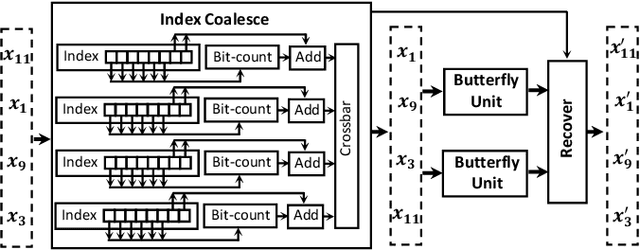
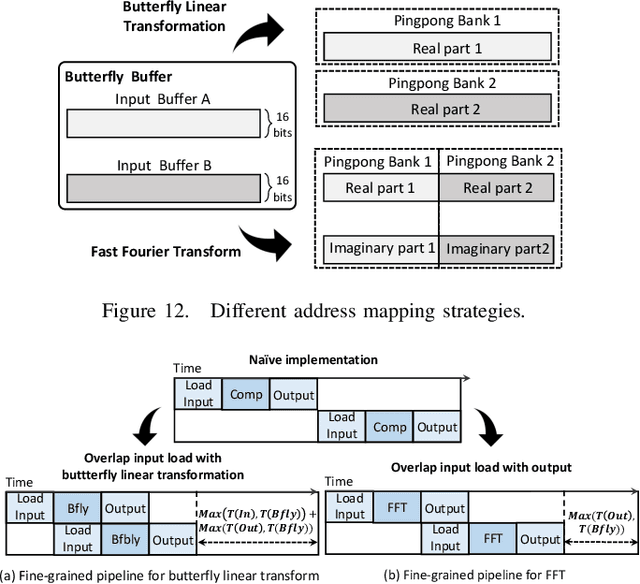
Attention-based neural networks have become pervasive in many AI tasks. Despite their excellent algorithmic performance, the use of the attention mechanism and feed-forward network (FFN) demands excessive computational and memory resources, which often compromises their hardware performance. Although various sparse variants have been introduced, most approaches only focus on mitigating the quadratic scaling of attention on the algorithm level, without explicitly considering the efficiency of mapping their methods on real hardware designs. Furthermore, most efforts only focus on either the attention mechanism or the FFNs but without jointly optimizing both parts, causing most of the current designs to lack scalability when dealing with different input lengths. This paper systematically considers the sparsity patterns in different variants from a hardware perspective. On the algorithmic level, we propose FABNet, a hardware-friendly variant that adopts a unified butterfly sparsity pattern to approximate both the attention mechanism and the FFNs. On the hardware level, a novel adaptable butterfly accelerator is proposed that can be configured at runtime via dedicated hardware control to accelerate different butterfly layers using a single unified hardware engine. On the Long-Range-Arena dataset, FABNet achieves the same accuracy as the vanilla Transformer while reducing the amount of computation by 10 to 66 times and the number of parameters 2 to 22 times. By jointly optimizing the algorithm and hardware, our FPGA-based butterfly accelerator achieves 14.2 to 23.2 times speedup over state-of-the-art accelerators normalized to the same computational budget. Compared with optimized CPU and GPU designs on Raspberry Pi 4 and Jetson Nano, our system is up to 273.8 and 15.1 times faster under the same power budget.
Protea: Client Profiling within Federated Systems using Flower
Jul 03, 2022
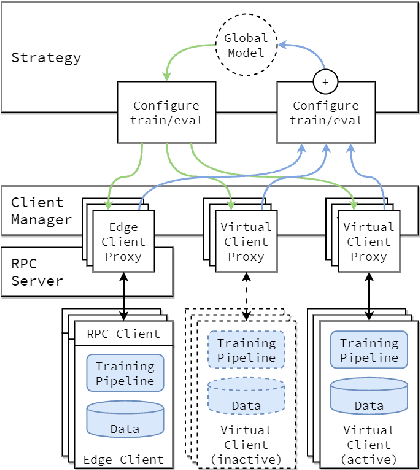
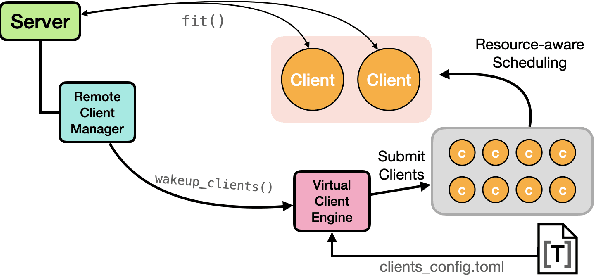
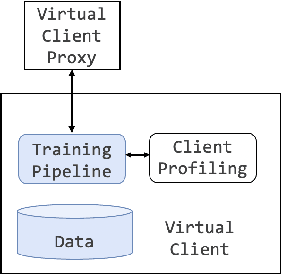
Federated Learning (FL) has emerged as a prospective solution that facilitates the training of a high-performing centralised model without compromising the privacy of users. While successful, research is currently limited by the possibility of establishing a realistic large-scale FL system at the early stages of experimentation. Simulation can help accelerate this process. To facilitate efficient scalable FL simulation of heterogeneous clients, we design and implement Protea, a flexible and lightweight client profiling component within federated systems using the FL framework Flower. It allows automatically collecting system-level statistics and estimating the resources needed for each client, thus running the simulation in a resource-aware fashion. The results show that our design successfully increases parallelism for 1.66 $\times$ faster wall-clock time and 2.6$\times$ better GPU utilisation, which enables large-scale experiments on heterogeneous clients.
Multi-DNN Accelerators for Next-Generation AI Systems
May 19, 2022

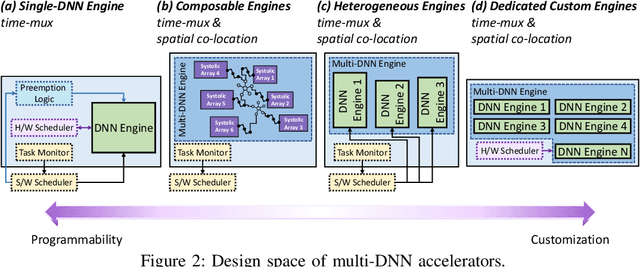
As the use of AI-powered applications widens across multiple domains, so do increase the computational demands. Primary driver of AI technology are the deep neural networks (DNNs). When focusing either on cloud-based systems that serve multiple AI queries from different users each with their own DNN model, or on mobile robots and smartphones employing pipelines of various models or parallel DNNs for the concurrent processing of multi-modal data, the next generation of AI systems will have multi-DNN workloads at their core. Large-scale deployment of AI services and integration across mobile and embedded systems require additional breakthroughs in the computer architecture front, with processors that can maintain high performance as the number of DNNs increases while meeting the quality-of-service requirements, giving rise to the topic of multi-DNN accelerator design.
Secure Aggregation for Federated Learning in Flower
May 12, 2022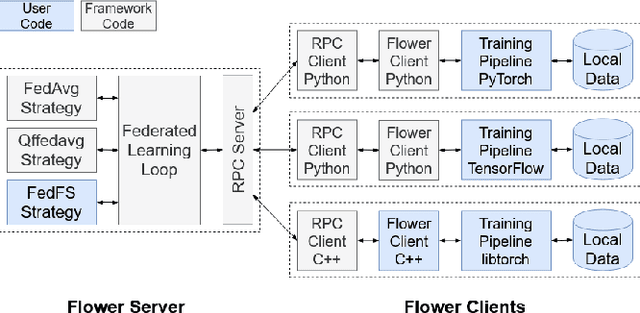
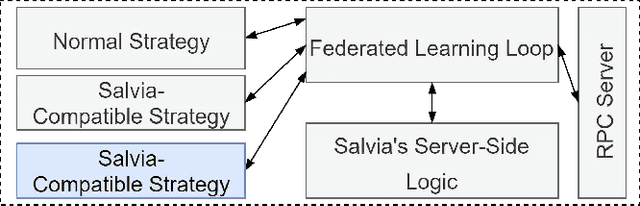
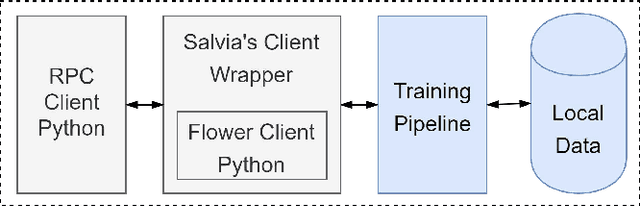
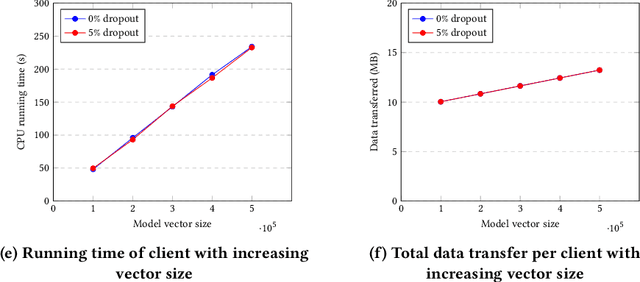
Federated Learning (FL) allows parties to learn a shared prediction model by delegating the training computation to clients and aggregating all the separately trained models on the server. To prevent private information being inferred from local models, Secure Aggregation (SA) protocols are used to ensure that the server is unable to inspect individual trained models as it aggregates them. However, current implementations of SA in FL frameworks have limitations, including vulnerability to client dropouts or configuration difficulties. In this paper, we present Salvia, an implementation of SA for Python users in the Flower FL framework. Based on the SecAgg(+) protocols for a semi-honest threat model, Salvia is robust against client dropouts and exposes a flexible and easy-to-use API that is compatible with various machine learning frameworks. We show that Salvia's experimental performance is consistent with SecAgg(+)'s theoretical computation and communication complexities.
Federated Self-supervised Speech Representations: Are We There Yet?
Apr 06, 2022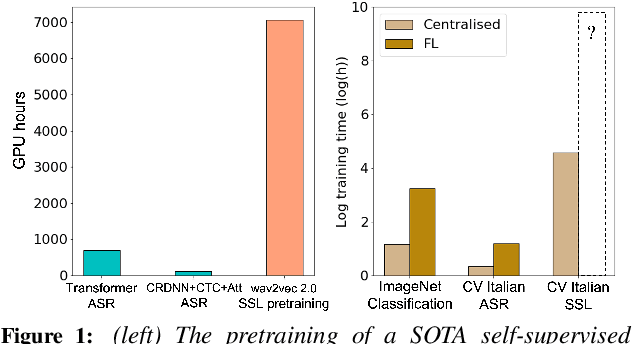
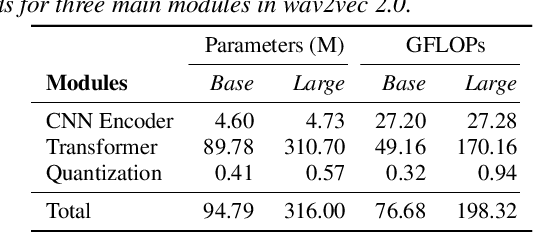
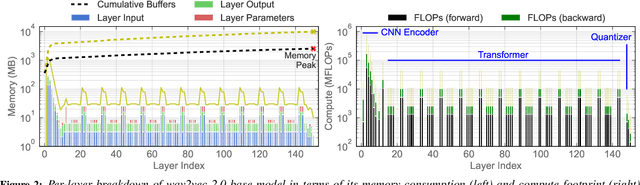
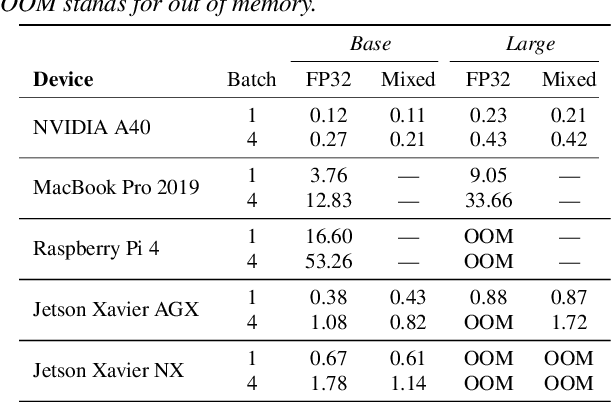
The ubiquity of microphone-enabled devices has lead to large amounts of unlabelled audio data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of speech representations. In this paper, we provide a first-of-its-kind systematic study of the feasibility and complexities for training speech SSL models under FL scenarios from the perspective of algorithms, hardware, and systems limits. Despite the high potential of their combination, we find existing system constraints and algorithmic behaviour make SSL and FL systems nearly impossible to build today. Yet critically, our results indicate specific performance bottlenecks and research opportunities that would allow this situation to be reversed. While our analysis suggests that, given existing trends in hardware, hybrid SSL and FL speech systems will not be viable until 2027. We believe this study can act as a roadmap to accelerate work towards reaching this milestone much earlier.
Differentiable Network Pruning for Microcontrollers
Oct 15, 2021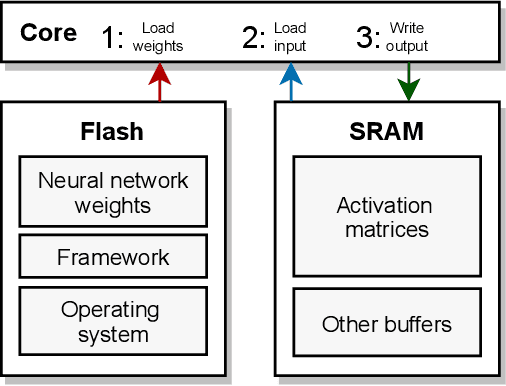
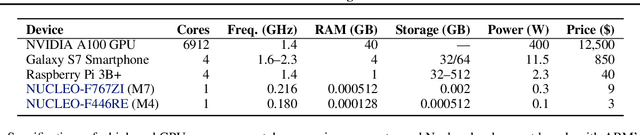
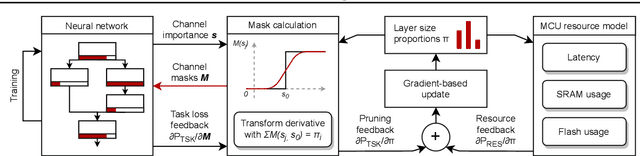
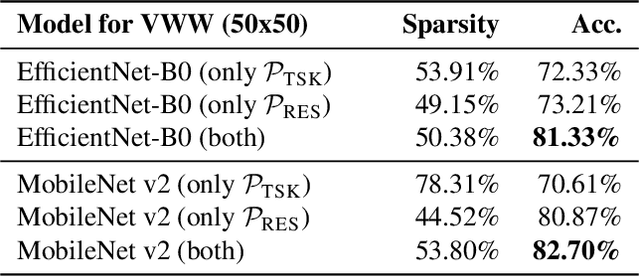
Embedded and personal IoT devices are powered by microcontroller units (MCUs), whose extreme resource scarcity is a major obstacle for applications relying on on-device deep learning inference. Orders of magnitude less storage, memory and computational capacity, compared to what is typically required to execute neural networks, impose strict structural constraints on the network architecture and call for specialist model compression methodology. In this work, we present a differentiable structured network pruning method for convolutional neural networks, which integrates a model's MCU-specific resource usage and parameter importance feedback to obtain highly compressed yet accurate classification models. Our methodology (a) improves key resource usage of models up to 80x; (b) prunes iteratively while a model is trained, resulting in little to no overhead or even improved training time; (c) produces compressed models with matching or improved resource usage up to 1.7x in less time compared to prior MCU-specific methods. Compressed models are available for download.