 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Augmented Graph Neural Networks: A Neuroscience Perspective
Sep 22, 2022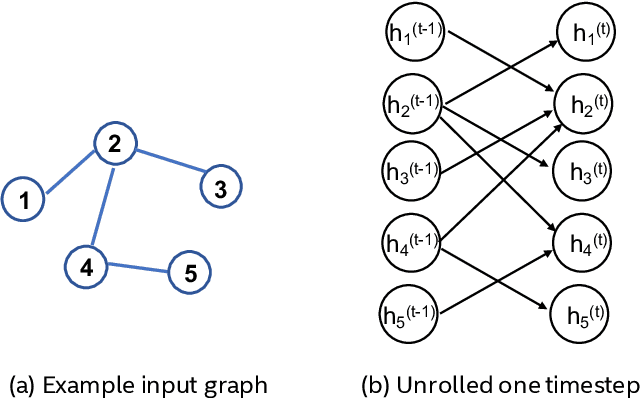
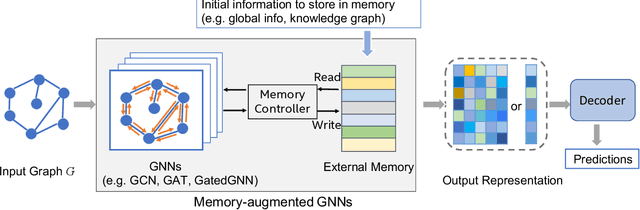
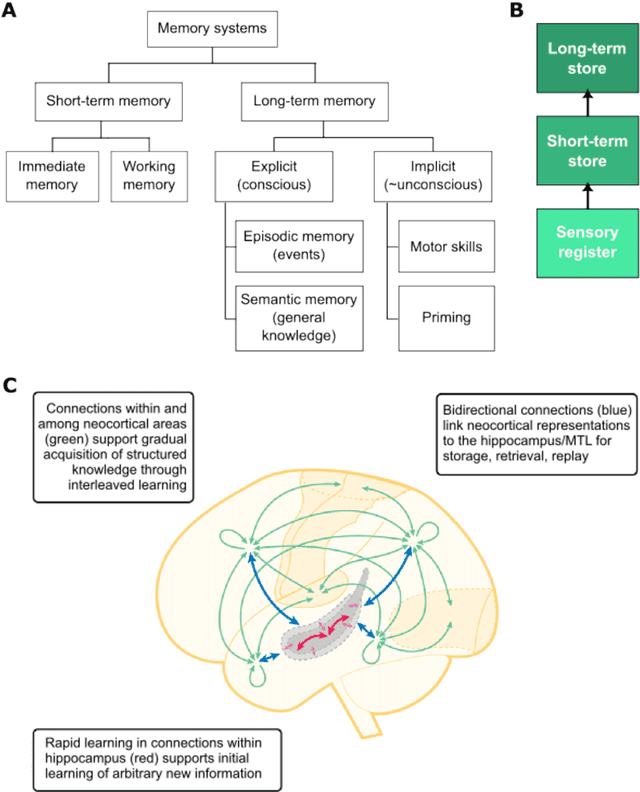
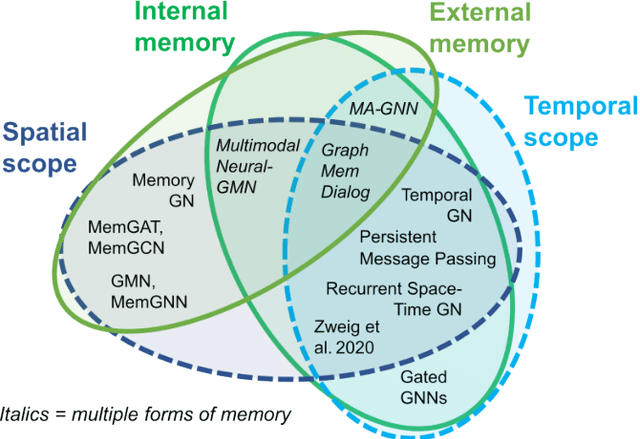
Graph neural networks (GNNs) have been extensively used for many domains where data are represented as graphs, including social networks, recommender systems, biology, chemistry, etc. Recently, the expressive power of GNNs has drawn much interest. It has been shown that, despite the promising empirical results achieved by GNNs for many applications, there are some limitations in GNNs that hinder their performance for some tasks. For example, since GNNs update node features mainly based on local information, they have limited expressive power in capturing long-range dependencies among nodes in graphs. To address some of the limitations of GNNs, several recent works started to explore augmenting GNNs with memory for improving their expressive power in the relevant tasks. In this paper, we provide a comprehensive review of the existing literature of memory-augmented GNNs. We review these works through the lens of psychology and neuroscience, which has established multiple memory systems and mechanisms in biological brains. We propose a taxonomy of the memory GNN works, as well as a set of criteria for comparing the memory mechanisms. We also provide critical discussions on the limitations of these works. Finally, we discuss the challenges and future directions for this area.
End-to-end Mapping in Heterogeneous Systems Using Graph Representation Learning
Apr 25, 2022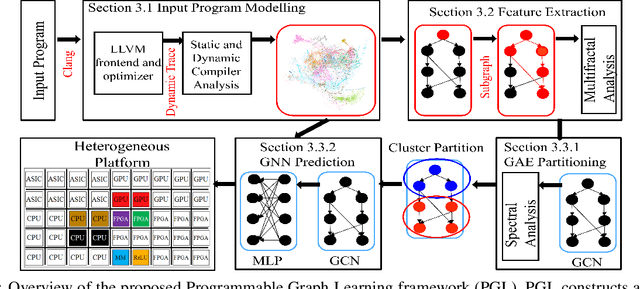
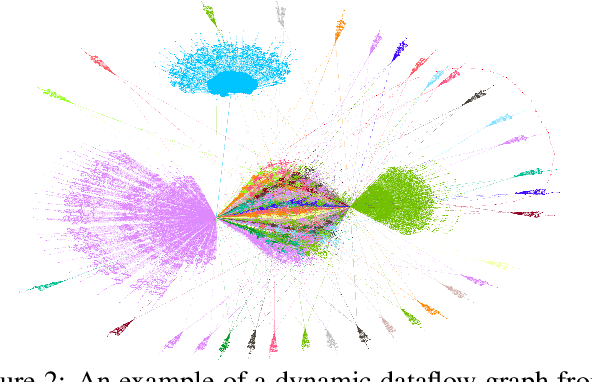
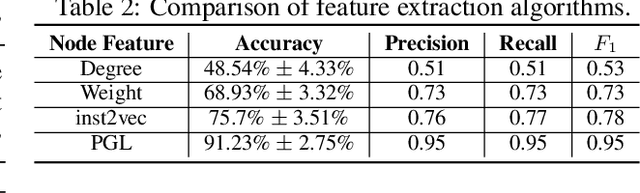
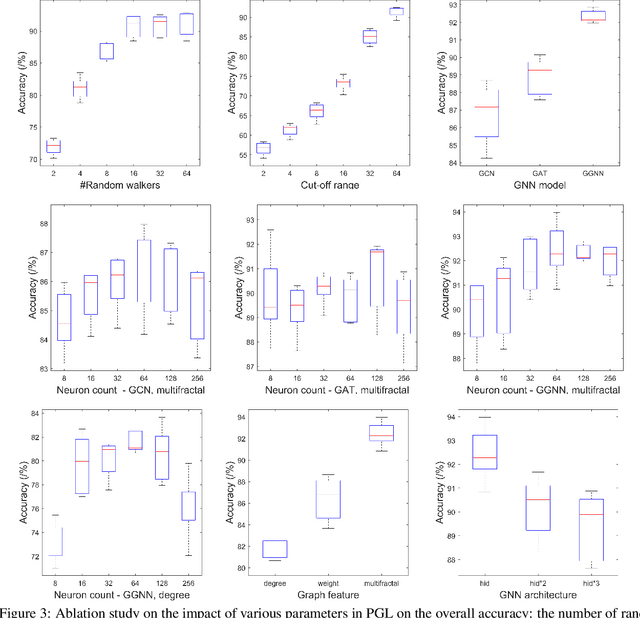
To enable heterogeneous computing systems with autonomous programming and optimization capabilities, we propose a unified, end-to-end, programmable graph representation learning (PGL) framework that is capable of mining the complexity of high-level programs down to the universal intermediate representation, extracting the specific computational patterns and predicting which code segments would run best on a specific core in heterogeneous hardware platforms. The proposed framework extracts multi-fractal topological features from code graphs, utilizes graph autoencoders to learn how to partition the graph into computational kernels, and exploits graph neural networks (GNN) to predict the correct assignment to a processor type. In the evaluation, we validate the PGL framework and demonstrate a maximum speedup of 6.42x compared to the thread-based execution, and 2.02x compared to the state-of-the-art technique.
Joint Learning of Hierarchical Community Structure and Node Representations: An Unsupervised Approach
Jan 22, 2022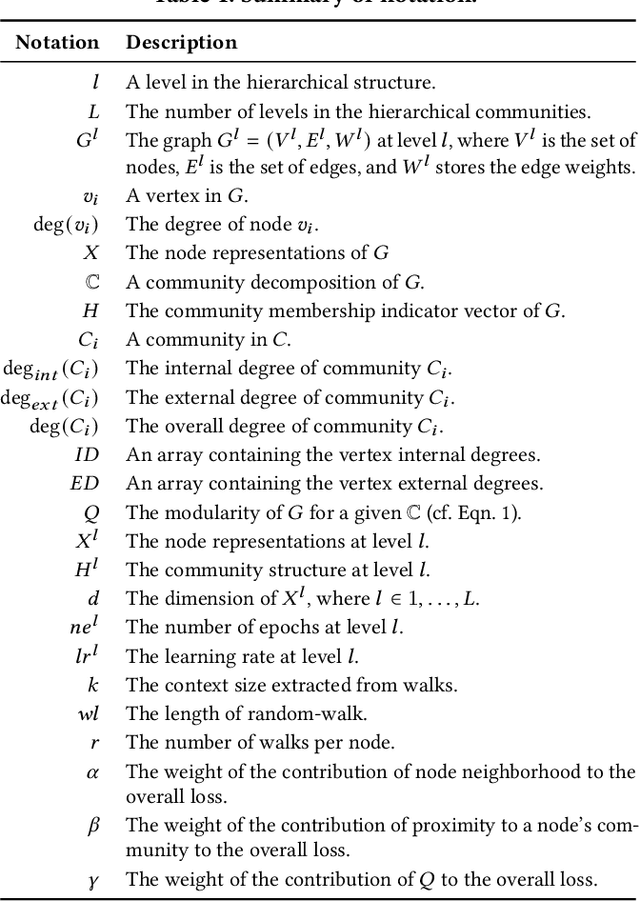

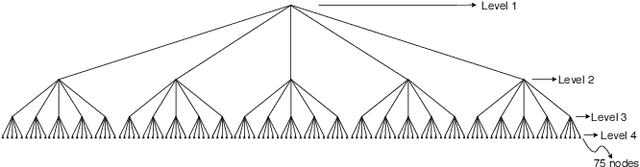
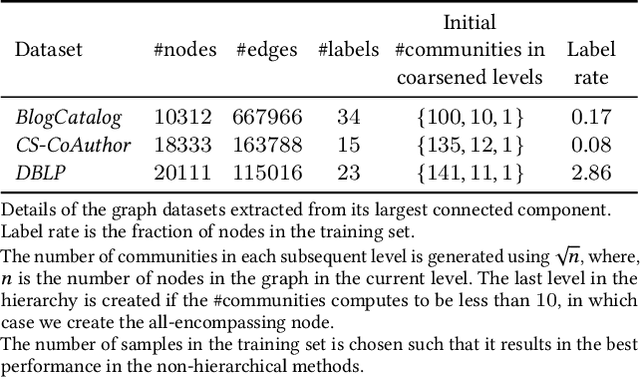
Graph representation learning has demonstrated improved performance in tasks such as link prediction and node classification across a range of domains. Research has shown that many natural graphs can be organized in hierarchical communities, leading to approaches that use these communities to improve the quality of node representations. However, these approaches do not take advantage of the learned representations to also improve the quality of the discovered communities and establish an iterative and joint optimization of representation learning and community discovery. In this work, we present Mazi, an algorithm that jointly learns the hierarchical community structure and the node representations of the graph in an unsupervised fashion. To account for the structure in the node representations, Mazi generates node representations at each level of the hierarchy, and utilizes them to influence the node representations of the original graph. Further, the communities at each level are discovered by simultaneously maximizing the modularity metric and minimizing the distance between the representations of a node and its community. Using multi-label node classification and link prediction tasks, we evaluate our method on a variety of synthetic and real-world graphs and demonstrate that Mazi outperforms other hierarchical and non-hierarchical methods.
DistGNN: Scalable Distributed Training for Large-Scale Graph Neural Networks
Apr 16, 2021
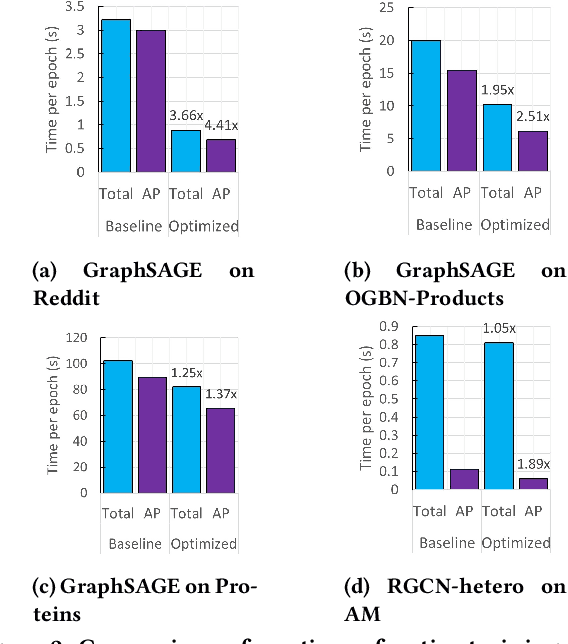
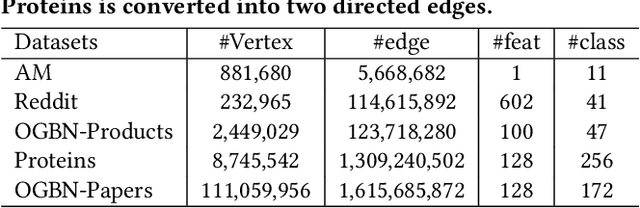
Full-batch training on Graph Neural Networks (GNN) to learn the structure of large graphs is a critical problem that needs to scale to hundreds of compute nodes to be feasible. It is challenging due to large memory capacity and bandwidth requirements on a single compute node and high communication volumes across multiple nodes. In this paper, we present DistGNN that optimizes the well-known Deep Graph Library (DGL) for full-batch training on CPU clusters via an efficient shared memory implementation, communication reduction using a minimum vertex-cut graph partitioning algorithm and communication avoidance using a family of delayed-update algorithms. Our results on four common GNN benchmark datasets: Reddit, OGB-Products, OGB-Papers and Proteins, show up to 3.7x speed-up using a single CPU socket and up to 97x speed-up using 128 CPU sockets, respectively, over baseline DGL implementations running on a single CPU socket
Personalized Visualization Recommendation
Feb 12, 2021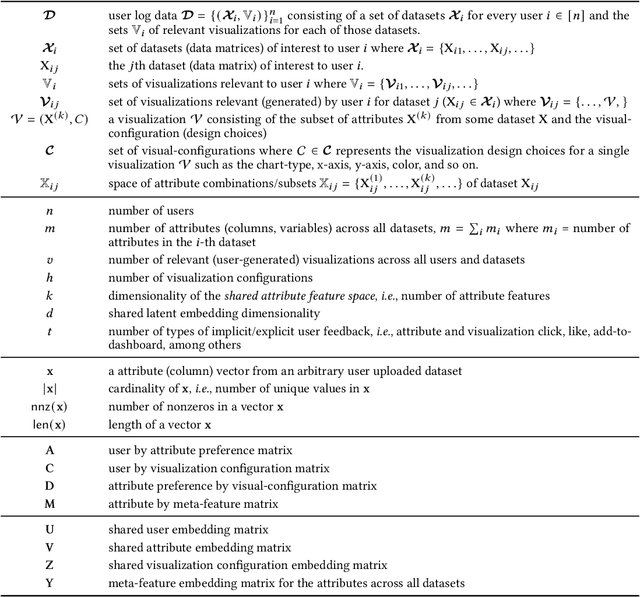

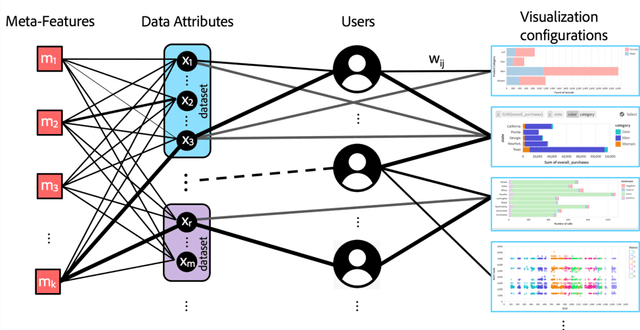
Visualization recommendation work has focused solely on scoring visualizations based on the underlying dataset and not the actual user and their past visualization feedback. These systems recommend the same visualizations for every user, despite that the underlying user interests, intent, and visualization preferences are likely to be fundamentally different, yet vitally important. In this work, we formally introduce the problem of personalized visualization recommendation and present a generic learning framework for solving it. In particular, we focus on recommending visualizations personalized for each individual user based on their past visualization interactions (e.g., viewed, clicked, manually created) along with the data from those visualizations. More importantly, the framework can learn from visualizations relevant to other users, even if the visualizations are generated from completely different datasets. Experiments demonstrate the effectiveness of the approach as it leads to higher quality visualization recommendations tailored to the specific user intent and preferences. To support research on this new problem, we release our user-centric visualization corpus consisting of 17.4k users exploring 94k datasets with 2.3 million attributes and 32k user-generated visualizations.
Heterogeneous Graphlets
Oct 23, 2020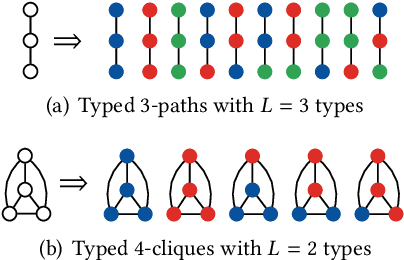


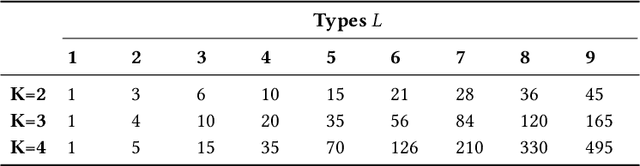
In this paper, we introduce a generalization of graphlets to heterogeneous networks called typed graphlets. Informally, typed graphlets are small typed induced subgraphs. Typed graphlets generalize graphlets to rich heterogeneous networks as they explicitly capture the higher-order typed connectivity patterns in such networks. To address this problem, we describe a general framework for counting the occurrences of such typed graphlets. The proposed algorithms leverage a number of combinatorial relationships for different typed graphlets. For each edge, we count a few typed graphlets, and with these counts along with the combinatorial relationships, we obtain the exact counts of the other typed graphlets in o(1) constant time. Notably, the worst-case time complexity of the proposed approach matches the time complexity of the best known untyped algorithm. In addition, the approach lends itself to an efficient lock-free and asynchronous parallel implementation. While there are no existing methods for typed graphlets, there has been some work that focused on computing a different and much simpler notion called colored graphlet. The experiments confirm that our proposed approach is orders of magnitude faster and more space-efficient than methods for computing the simpler notion of colored graphlet. Unlike these methods that take hours on small networks, the proposed approach takes only seconds on large networks with millions of edges. Notably, since typed graphlet is more general than colored graphlet (and untyped graphlets), the counts of various typed graphlets can be combined to obtain the counts of the much simpler notion of colored graphlets. The proposed methods give rise to new opportunities and applications for typed graphlets.
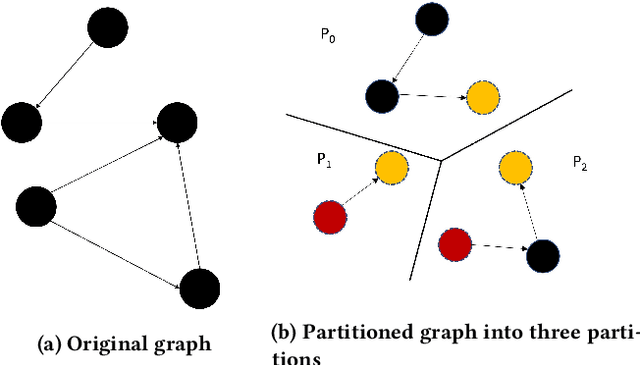
A Vertex Cut based Framework for Load Balancing and Parallelism Optimization in Multi-core Systems
Oct 09, 2020

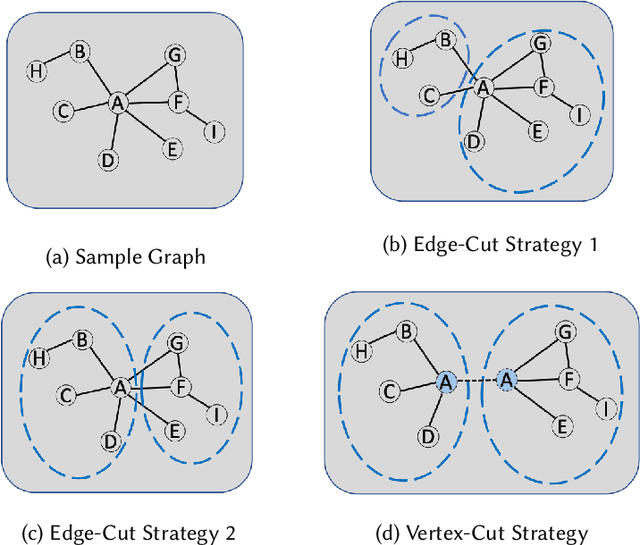
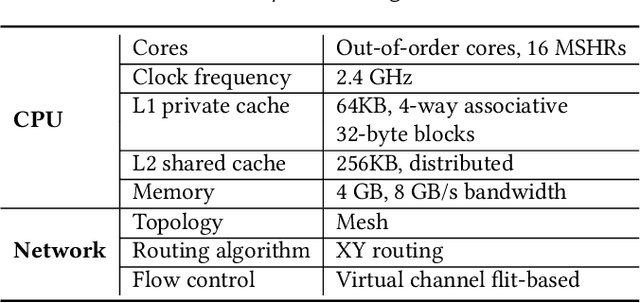
High-level applications, such as machine learning, are evolving from simple models based on multilayer perceptrons for simple image recognition to much deeper and more complex neural networks for self-driving vehicle control systems.The rapid increase in the consumption of memory and computational resources by these models demands the use of multi-core parallel systems to scale the execution of the complex emerging applications that depend on them. However, parallel programs running on high-performance computers often suffer from data communication bottlenecks, limited memory bandwidth, and synchronization overhead due to irregular critical sections. In this paper, we propose a framework to reduce the data communication and improve the scalability and performance of these applications in multi-core systems. We design a vertex cut framework for partitioning LLVM IR graphs into clusters while taking into consideration the data communication and workload balance among clusters. First, we construct LLVM graphs by compiling high-level programs into LLVM IR, instrumenting code to obtain the execution order of basic blocks and the execution time for each memory operation, and analyze data dependencies in dynamic LLVM traces. Next, we formulate the problem as Weight Balanced $p$-way Vertex Cut, and propose a generic and flexible framework, wherein four different greedy algorithms are proposed for solving this problem. Lastly, we propose a memory-centric run-time mapping of the linear time complexity to map clusters generated from the vertex cut algorithms onto a multi-core platform. We conclude that our best algorithm, WB-Libra, provides performance improvements of 1.56x and 1.86x over existing state-of-the-art approaches for 8 and 1024 clusters running on a multi-core platform, respectively.
Graph Neural Networks with Heterophily
Sep 28, 2020Graph Neural Networks (GNNs) have proven to be useful for many different practical applications. However, most existing GNN models have an implicit assumption of homophily among the nodes connected in the graph, and therefore have largely overlooked the important setting of heterophily. In this work, we propose a novel framework called CPGNN that generalizes GNNs for graphs with either homophily or heterophily. The proposed framework incorporates an interpretable compatibility matrix for modeling the heterophily or homophily level in the graph, which can be learned in an end-to-end fashion, enabling it to go beyond the assumption of strong homophily. Theoretically, we show that replacing the compatibility matrix in our framework with the identity (which represents pure homophily) reduces to GCN. Our extensive experiments demonstrate the effectiveness of our approach in more realistic and challenging experimental settings with significantly less training data compared to previous works: CPGNN variants achieve state-of-the-art results in heterophily settings with or without contextual node features, while maintaining comparable performance in homophily settings.
Deep Graph Similarity Learning: A Survey
Dec 25, 2019
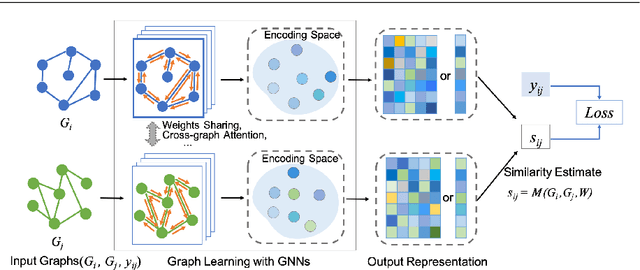
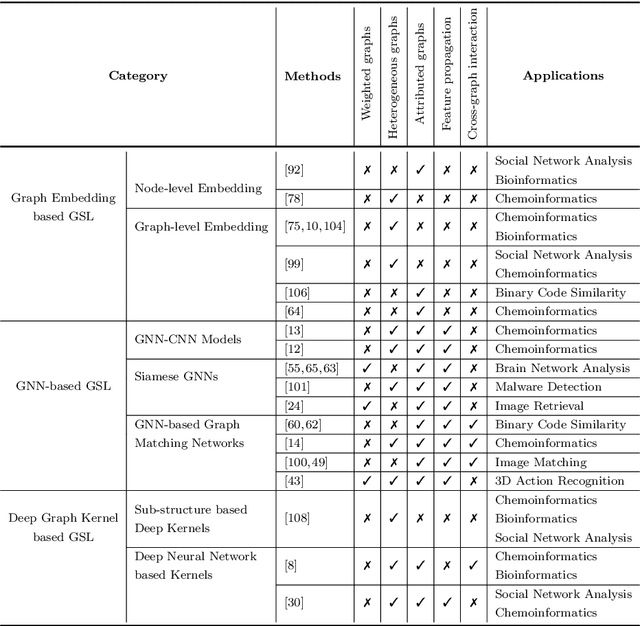
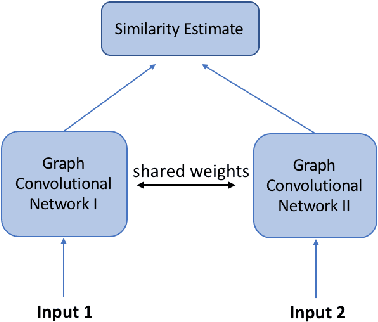
In many domains where data are represented as graphs, learning a similarity metric among graphs is considered a key problem, which can further facilitate various learning tasks, such as classification, clustering, and similarity search. Recently, there has been an increasing interest in deep graph similarity learning, where the key idea is to learn a deep learning model that maps input graphs to a target space such that the distance in the target space approximates the structural distance in the input space. Here, we provide a comprehensive review of the existing literature of deep graph similarity learning. We propose a systematic taxonomy for the methods and applications. Finally, we discuss the challenges and future directions for this problem.
Temporal Network Sampling
Oct 18, 2019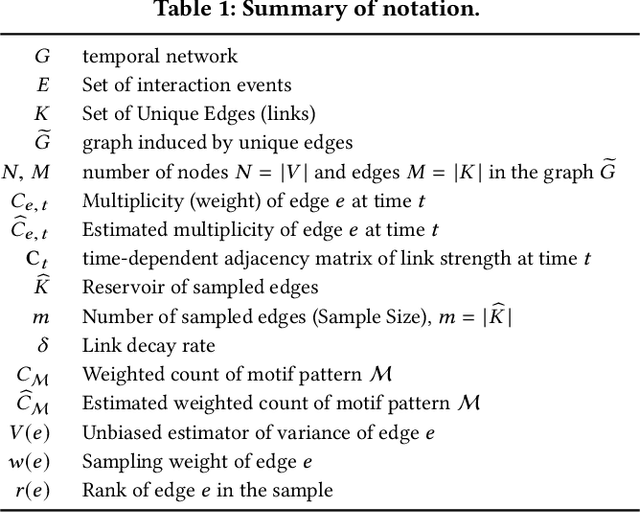
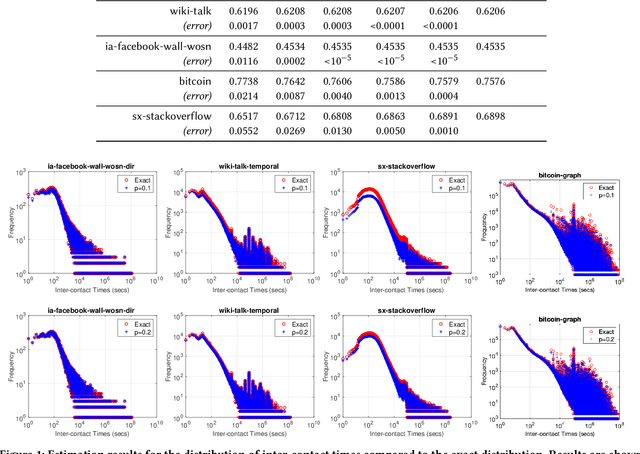
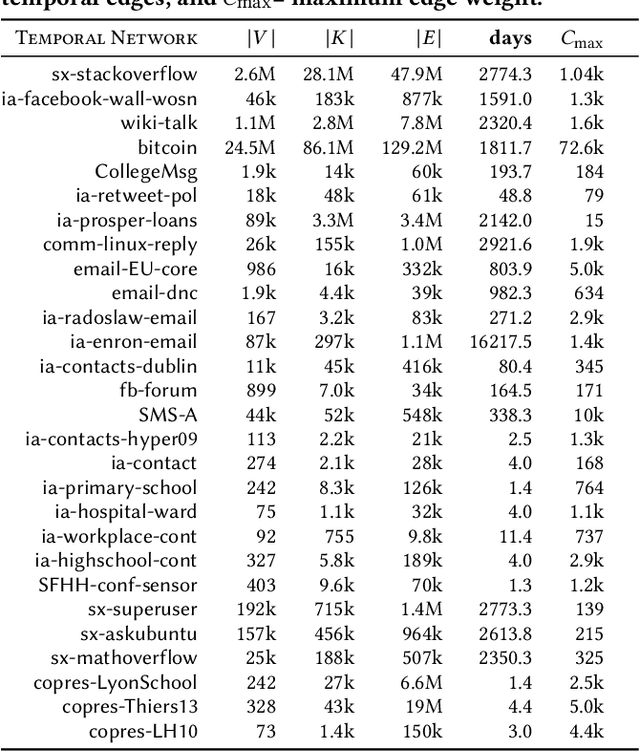
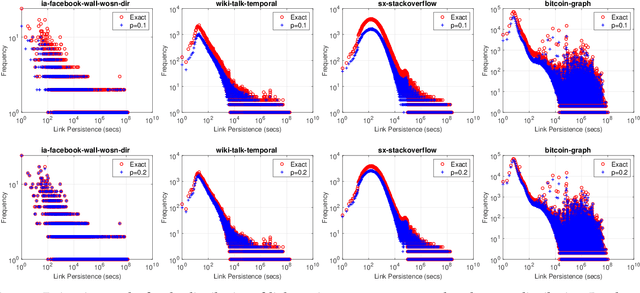
Temporal networks representing a stream of timestamped edges are seemingly ubiquitous in the real-world. However, the massive size and continuous nature of these networks make them fundamentally challenging to analyze and leverage for descriptive and predictive modeling tasks. In this work, we propose a general framework for temporal network sampling with unbiased estimation. We develop online, single-pass sampling algorithms and unbiased estimators for temporal network sampling. The proposed algorithms enable fast, accurate, and memory-efficient statistical estimation of temporal network patterns and properties. In addition, we propose a temporally decaying sampling algorithm with unbiased estimators for studying networks that evolve in continuous time, where the strength of links is a function of time, and the motif patterns are temporally-weighted. In contrast to the prior notion of a $\bigtriangleup t$-temporal motif, the proposed formulation and algorithms for counting temporally weighted motifs are useful for forecasting tasks in networks such as predicting future links, or a future time-series variable of nodes and links. Finally, extensive experiments on a variety of temporal networks from different domains demonstrate the effectiveness of the proposed algorithms.