 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOEVO: Co-Evolutionary Framework for Joint Functional Correctness and PPA Optimization in LLM-Based RTL Generation
Apr 16, 2026LLM-based RTL code generation methods increasingly target both functional correctness and PPA quality, yet existing approaches universally decouple the two objectives, optimizing PPA only after correctness is fully achieved. Whether through sequential multi-agent pipelines, evolutionary search with binary correctness gates, or hierarchical reward dependencies, partially correct but architecturally promising candidates are systematically discarded. Moreover, existing methods reduce the multi-objective PPA space to a single scalar fitness, obscuring the trade-offs among area, delay, and power. To address these limitations, we propose COEVO, a co-evolutionary framework that unifies correctness and PPA optimization within a single evolutionary loop. COEVO formulates correctness as a continuous co-optimization dimension alongside area, delay, and power, enabled by an enhanced testbench that provides fine-grained scoring and detailed diagnostic feedback. An adaptive correctness gate with annealing allows PPA-promising but partially correct candidates to guide the search toward jointly optimal solutions. To preserve the full PPA trade-off structure, COEVO employs four-dimensional Pareto-based non-dominated sorting with configurable intra-level sorting, replacing scalar fitness without manual weight tuning. Evaluated on VerilogEval 2.0 and RTLLM 2.0, COEVO achieves 97.5\% and 94.5\% Pass@1 with GPT-5.4-mini, surpassing all agentic baselines across four LLM backbones, while attaining the best PPA on 43 out of 49 synthesizable RTLLM designs.
OptiML: An End-to-End Framework for Program Synthesis and CUDA Kernel Optimization
Feb 12, 2026Generating high-performance CUDA kernels remains challenging due to the need to navigate a combinatorial space of low-level transformations under noisy and expensive hardware feedback. Although large language models can synthesize functionally correct CUDA code, achieving competitive performance requires systematic exploration and verification of optimization choices. We present OptiML, an end-to-end framework that maps either natural-language intent or input CUDA code to performance-optimized CUDA kernels by formulating kernel optimization as search under verification. OptiML consists of two decoupled stages. When the input is natural language, a Mixture-of-Thoughts generator (OptiML-G) acts as a proposal policy over kernel implementation strategies, producing an initial executable program. A search-based optimizer (OptiML-X) then refines either synthesized or user-provided kernels using Monte Carlo Tree Search over LLM-driven edits, guided by a hardware-aware reward derived from profiler feedback. Each candidate transformation is compiled, verified, and profiled with Nsight Compute, and evaluated by a composite objective that combines runtime with hardware bottleneck proxies and guardrails against regressions. We evaluate OptiML in both synthesis-and-optimize and optimization-only settings on a diverse suite of CUDA kernels. Results show that OptiML consistently discovers verified performance improvements over strong LLM baselines and produces interpretable optimization trajectories grounded in profiler evidence.
Auditing Multi-Agent LLM Reasoning Trees Outperforms Majority Vote and LLM-as-Judge
Feb 10, 2026Multi-agent systems (MAS) can substantially extend the reasoning capacity of large language models (LLMs), yet most frameworks still aggregate agent outputs with majority voting. This heuristic discards the evidential structure of reasoning traces and is brittle under the confabulation consensus, where agents share correlated biases and converge on the same incorrect rationale. We introduce AgentAuditor, which replaces voting with a path search over a Reasoning Tree that explicitly represents agreements and divergences among agent traces. AgentAuditor resolves conflicts by comparing reasoning branches at critical divergence points, turning global adjudication into efficient, localized verification. We further propose Anti-Consensus Preference Optimization (ACPO), which trains the adjudicator on majority-failure cases and rewards evidence-based minority selections over popular errors. AgentAuditor is agnostic to MAS setting, and we find across 5 popular settings that it yields up to 5% absolute accuracy improvement over a majority vote, and up to 3% over using LLM-as-Judge.
Towards Reducible Uncertainty Modeling for Reliable Large Language Model Agents
Feb 04, 2026Uncertainty quantification (UQ) for large language models (LLMs) is a key building block for safety guardrails of daily LLM applications. Yet, even as LLM agents are increasingly deployed in highly complex tasks, most UQ research still centers on single-turn question-answering. We argue that UQ research must shift to realistic settings with interactive agents, and that a new principled framework for agent UQ is needed. This paper presents the first general formulation of agent UQ that subsumes broad classes of existing UQ setups. Under this formulation, we show that prior works implicitly treat LLM UQ as an uncertainty accumulation process, a viewpoint that breaks down for interactive agents in an open world. In contrast, we propose a novel perspective, a conditional uncertainty reduction process, that explicitly models reducible uncertainty over an agent's trajectory by highlighting "interactivity" of actions. From this perspective, we outline a conceptual framework to provide actionable guidance for designing UQ in LLM agent setups. Finally, we conclude with practical implications of the agent UQ in frontier LLM development and domain-specific applications, as well as open remaining problems.
Structural Complexity of Brain MRI reveals age-associated patterns
Jan 23, 2026We adapt structural complexity analysis to three-dimensional signals, with an emphasis on brain magnetic resonance imaging (MRI). This framework captures the multiscale organization of volumetric data by coarse-graining the signal at progressively larger spatial scales and quantifying the information lost between successive resolutions. While the traditional block-based approach can become unstable at coarse resolutions due to limited sampling, we introduce a sliding-window coarse-graining scheme that provides smoother estimates and improved robustness at large scales. Using this refined method, we analyze large structural MRI datasets spanning mid- to late adulthood and find that structural complexity decreases systematically with age, with the strongest effects emerging at coarser scales. These findings highlight structural complexity as a reliable signal processing tool for multiscale analysis of 3D imaging data, while also demonstrating its utility in predicting biological age from brain MRI.
Analyzing Neural Network Information Flow Using Differential Geometry
Jan 22, 2026This paper provides a fresh view of the neural network (NN) data flow problem, i.e., identifying the NN connections that are most important for the performance of the full model, through the lens of graph theory. Understanding the NN data flow provides a tool for symbolic NN analysis, e.g.,~robustness analysis or model repair. Unlike the standard approach to NN data flow analysis, which is based on information theory, we employ the notion of graph curvature, specifically Ollivier-Ricci curvature (ORC). The ORC has been successfully used to identify important graph edges in various domains such as road traffic analysis, biological and social networks. In particular, edges with negative ORC are considered bottlenecks and as such are critical to the graph's overall connectivity, whereas positive-ORC edges are not essential. We use this intuition for the case of NNs as well: we 1)~construct a graph induced by the NN structure and introduce the notion of neural curvature (NC) based on the ORC; 2)~calculate curvatures based on activation patterns for a set of input examples; 3)~aim to demonstrate that NC can indeed be used to rank edges according to their importance for the overall NN functionality. We evaluate our method through pruning experiments and show that removing negative-ORC edges quickly degrades the overall NN performance, whereas positive-ORC edges have little impact. The proposed method is evaluated on a variety of models trained on three image datasets, namely MNIST, CIFAR-10 and CIFAR-100. The results indicate that our method can identify a larger number of unimportant edges as compared to state-of-the-art pruning methods.
EMoE: Eigenbasis-Guided Routing for Mixture-of-Experts
Jan 17, 2026The relentless scaling of deep learning models has led to unsustainable computational demands, positioning Mixture-of-Experts (MoE) architectures as a promising path towards greater efficiency. However, MoE models are plagued by two fundamental challenges: 1) a load imbalance problem known as the``rich get richer" phenomenon, where a few experts are over-utilized, and 2) an expert homogeneity problem, where experts learn redundant representations, negating their purpose. Current solutions typically employ an auxiliary load-balancing loss that, while mitigating imbalance, often exacerbates homogeneity by enforcing uniform routing at the expense of specialization. To resolve this, we introduce the Eigen-Mixture-of-Experts (EMoE), a novel architecture that leverages a routing mechanism based on a learned orthonormal eigenbasis. EMoE projects input tokens onto this shared eigenbasis and routes them based on their alignment with the principal components of the feature space. This principled, geometric partitioning of data intrinsically promotes both balanced expert utilization and the development of diverse, specialized experts, all without the need for a conflicting auxiliary loss function. Our code is publicly available at https://github.com/Belis0811/EMoE.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025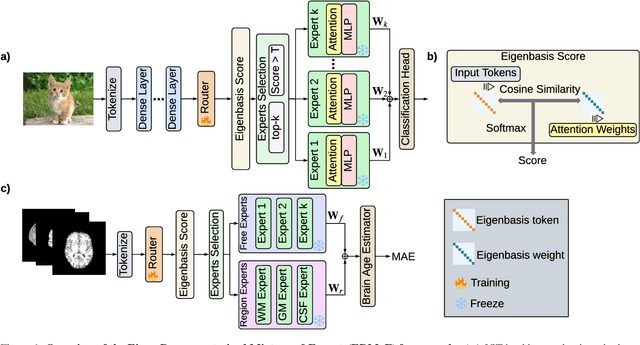



Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
Maestro: Learning to Collaborate via Conditional Listwise Policy Optimization for Multi-Agent LLMs
Nov 08, 2025Multi-agent systems (MAS) built on Large Language Models (LLMs) are being used to approach complex problems and can surpass single model inference. However, their success hinges on navigating a fundamental cognitive tension: the need to balance broad, divergent exploration of the solution space with a principled, convergent synthesis to the optimal solution. Existing paradigms often struggle to manage this duality, leading to premature consensus, error propagation, and a critical credit assignment problem that fails to distinguish between genuine reasoning and superficially plausible arguments. To resolve this core challenge, we propose the Multi-Agent Exploration-Synthesis framework Through Role Orchestration (Maestro), a principled paradigm for collaboration that structurally decouples these cognitive modes. Maestro uses a collective of parallel Execution Agents for diverse exploration and a specialized Central Agent for convergent, evaluative synthesis. To operationalize this critical synthesis phase, we introduce Conditional Listwise Policy Optimization (CLPO), a reinforcement learning objective that disentangles signals for strategic decisions and tactical rationales. By combining decision-focused policy gradients with a list-wise ranking loss over justifications, CLPO achieves clean credit assignment and stronger comparative supervision. Experiments on mathematical reasoning and general problem-solving benchmarks demonstrate that Maestro, coupled with CLPO, consistently outperforms existing state-of-the-art multi-agent approaches, delivering absolute accuracy gains of 6% on average and up to 10% at best.
VeriMoA: A Mixture-of-Agents Framework for Spec-to-HDL Generation
Oct 31, 2025



Automation of Register Transfer Level (RTL) design can help developers meet increasing computational demands. Large Language Models (LLMs) show promise for Hardware Description Language (HDL) generation, but face challenges due to limited parametric knowledge and domain-specific constraints. While prompt engineering and fine-tuning have limitations in knowledge coverage and training costs, multi-agent architectures offer a training-free paradigm to enhance reasoning through collaborative generation. However, current multi-agent approaches suffer from two critical deficiencies: susceptibility to noise propagation and constrained reasoning space exploration. We propose VeriMoA, a training-free mixture-of-agents (MoA) framework with two synergistic innovations. First, a quality-guided caching mechanism to maintain all intermediate HDL outputs and enables quality-based ranking and selection across the entire generation process, encouraging knowledge accumulation over layers of reasoning. Second, a multi-path generation strategy that leverages C++ and Python as intermediate representations, decomposing specification-to-HDL translation into two-stage processes that exploit LLM fluency in high-resource languages while promoting solution diversity. Comprehensive experiments on VerilogEval 2.0 and RTLLM 2.0 benchmarks demonstrate that VeriMoA achieves 15--30% improvements in Pass@1 across diverse LLM backbones, especially enabling smaller models to match larger models and fine-tuned alternatives without requiring costly training.