 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from learning machines: a new generation of AI technology to meet the needs of science
Nov 27, 2021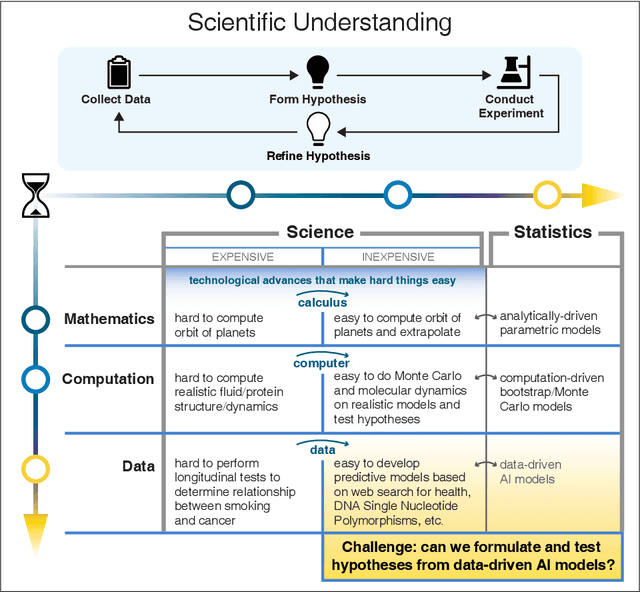

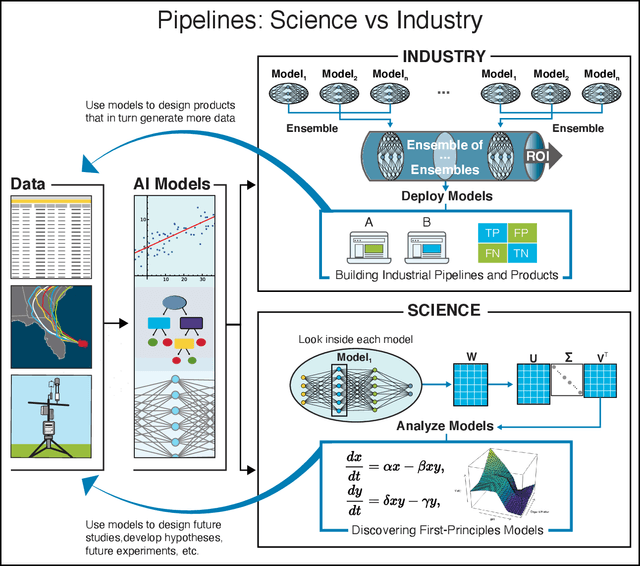
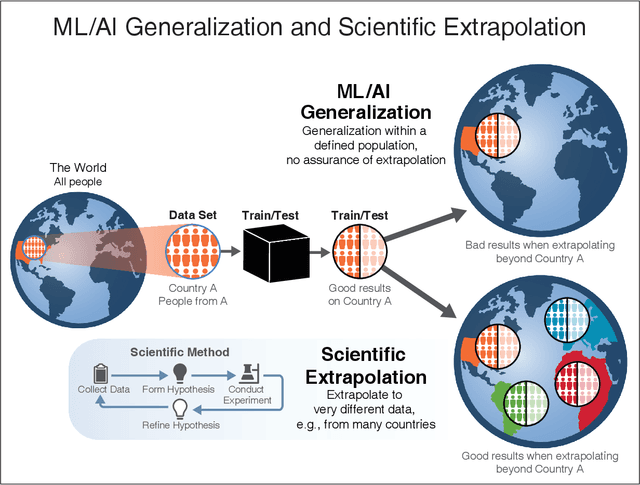
We outline emerging opportunities and challenges to enhance the utility of AI for scientific discovery. The distinct goals of AI for industry versus the goals of AI for science create tension between identifying patterns in data versus discovering patterns in the world from data. If we address the fundamental challenges associated with "bridging the gap" between domain-driven scientific models and data-driven AI learning machines, then we expect that these AI models can transform hypothesis generation, scientific discovery, and the scientific process itself.
Few Shot Activity Recognition Using Variational Inference
Aug 20, 2021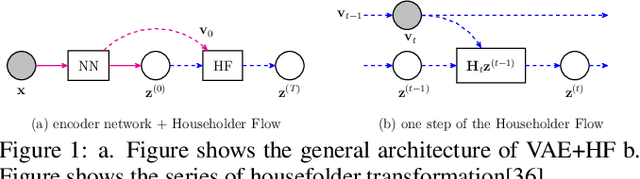
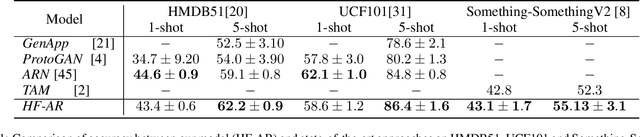
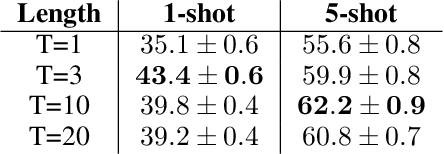
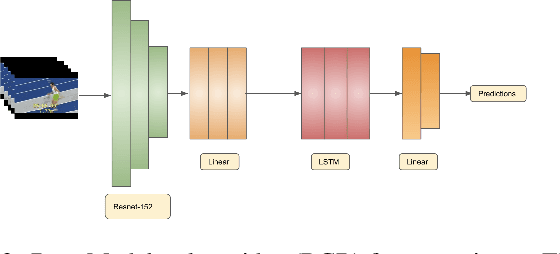
There has been a remarkable progress in learning a model which could recognise novel classes with only a few labeled examples in the last few years. Few-shot learning (FSL) for action recognition is a challenging task of recognising novel action categories which are represented by few instances in the training data. We propose a novel variational inference based architectural framework (HF-AR) for few shot activity recognition. Our framework leverages volume-preserving Householder Flow to learn a flexible posterior distribution of the novel classes. This results in better performance as compared to state-of-the-art few shot approaches for human activity recognition. approach consists of base model and an adapter model. Our architecture consists of a base model and an adapter model. The base model is trained on seen classes and it computes an embedding that represent the spatial and temporal insights extracted from the input video, e.g. combination of Resnet-152 and LSTM based encoder-decoder model. The adapter model applies a series of Householder transformations to compute a flexible posterior distribution that lends higher accuracy in the few shot approach. Extensive experiments on three well-known datasets: UCF101, HMDB51 and Something-Something-V2, demonstrate similar or better performance on 1-shot and 5-shot classification as compared to state-of-the-art few shot approaches that use only RGB frame sequence as input. To the best of our knowledge, we are the first to explore variational inference along with householder transformations to capture the full rank covariance matrix of posterior distribution, for few shot learning in activity recognition.
Spatial Graph Attention and Curiosity-driven Policy for Antiviral Drug Discovery
Jun 20, 2021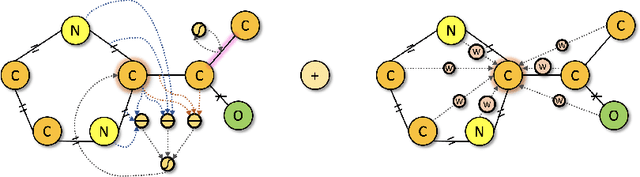
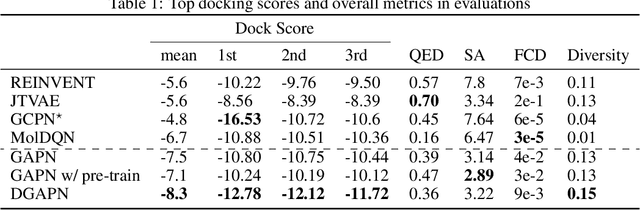
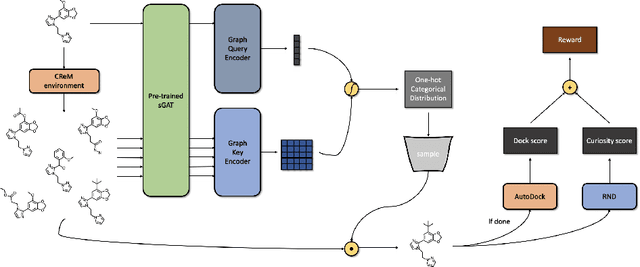
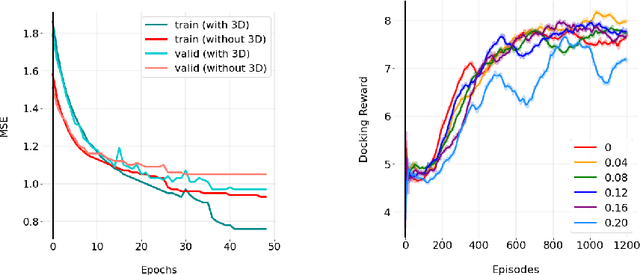
We developed Distilled Graph Attention Policy Networks (DGAPNs), a curiosity-driven reinforcement learning model to generate novel graph-structured chemical representations that optimize user-defined objectives by efficiently navigating a physically constrained domain. The framework is examined on the task of generating molecules that are designed to bind, noncovalently, to functional sites of SARS-CoV-2 proteins. We present a spatial Graph Attention Network (sGAT) that leverages self-attention over both node and edge attributes as well as encoding spatial structure -- this capability is of considerable interest in areas such as molecular and synthetic biology and drug discovery. An attentional policy network is then introduced to learn decision rules for a dynamic, fragment-based chemical environment, and state-of-the-art policy gradient techniques are employed to train the network with enhanced stability. Exploration is efficiently encouraged by incorporating innovation reward bonuses learned and proposed by random network distillation. In experiments, our framework achieved outstanding results compared to state-of-the-art algorithms, while increasing the diversity of proposed molecules and reducing the complexity of paths to chemical synthesis.
Security in Next Generation Mobile Payment Systems: A Comprehensive Survey
May 25, 2021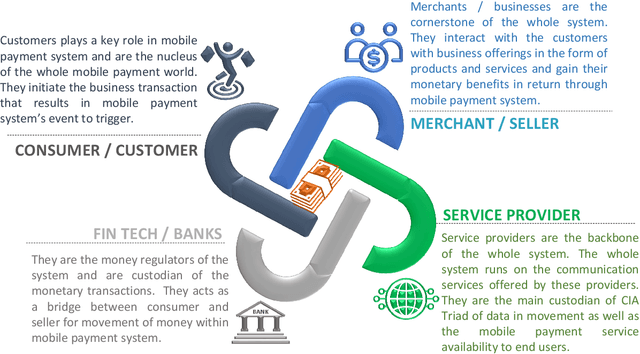
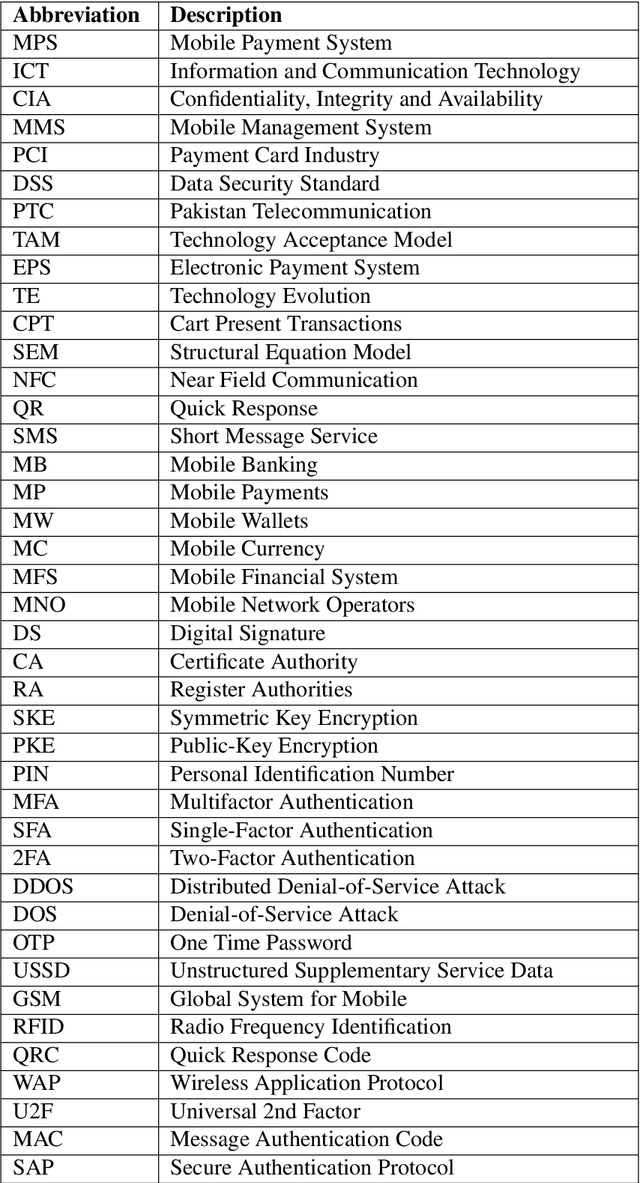
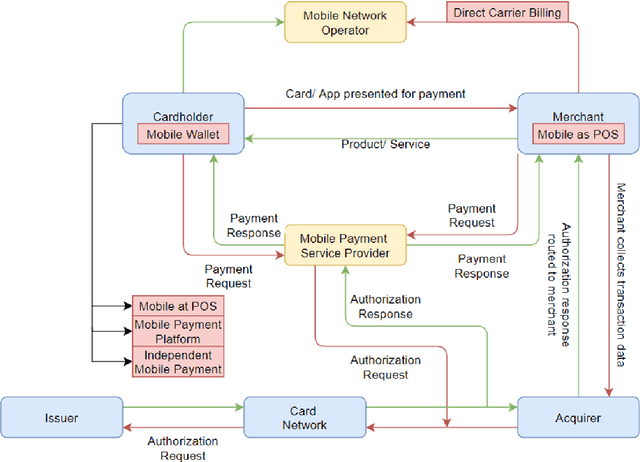
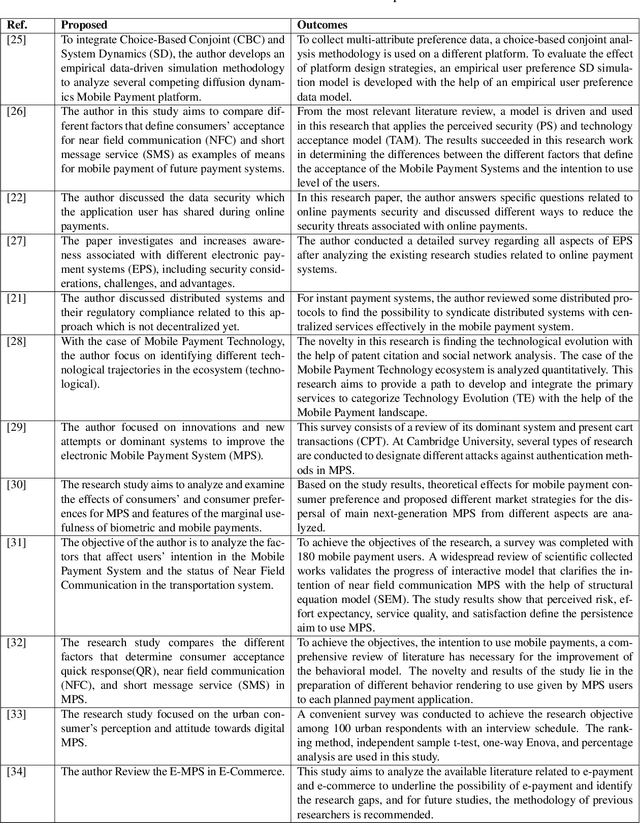
Cash payment is still king in several markets, accounting for more than 90\ of the payments in almost all the developing countries. The usage of mobile phones is pretty ordinary in this present era. Mobile phones have become an inseparable friend for many users, serving much more than just communication tools. Every subsequent person is heavily relying on them due to multifaceted usage and affordability. Every person wants to manage his/her daily transactions and related issues by using his/her mobile phone. With the rise and advancements of mobile-specific security, threats are evolving as well. In this paper, we provide a survey of various security models for mobile phones. We explore multiple proposed models of the mobile payment system (MPS), their technologies and comparisons, payment methods, different security mechanisms involved in MPS, and provide analysis of the encryption technologies, authentication methods, and firewall in MPS. We also present current challenges and future directions of mobile phone security.
Evening the Score: Targeting SARS-CoV-2 Protease Inhibition in Graph Generative Models for Therapeutic Candidates
May 07, 2021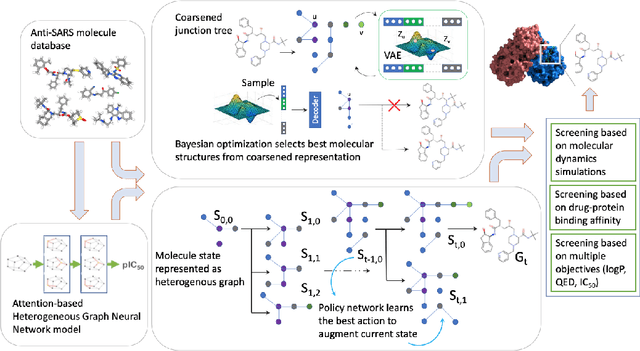
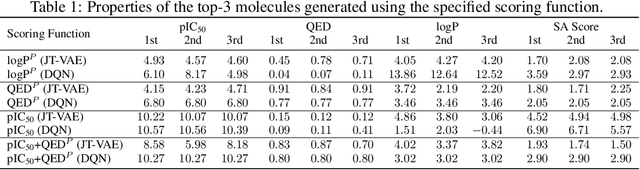
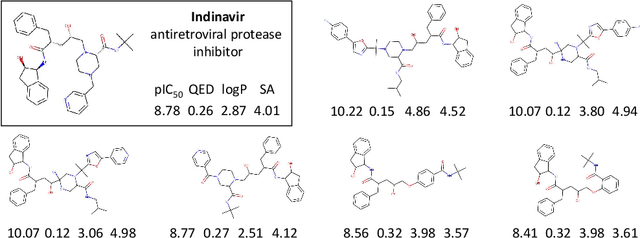
We examine a pair of graph generative models for the therapeutic design of novel drug candidates targeting SARS-CoV-2 viral proteins. Due to a sense of urgency, we chose well-validated models with unique strengths: an autoencoder that generates molecules with similar structures to a dataset of drugs with anti-SARS activity and a reinforcement learning algorithm that generates highly novel molecules. During generation, we explore optimization toward several design targets to balance druglikeness, synthetic accessability, and anti-SARS activity based on \icfifty. This generative framework\footnote{https://github.com/exalearn/covid-drug-design} will accelerate drug discovery in future pandemics through the high-throughput generation of targeted therapeutic candidates.
* arXiv admin note: substantial text overlap with arXiv:2102.04977
FedDPGAN: Federated Differentially Private Generative Adversarial Networks Framework for the Detection of COVID-19 Pneumonia
Apr 26, 2021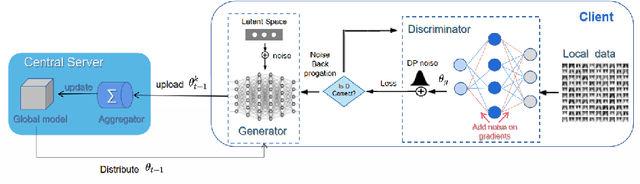
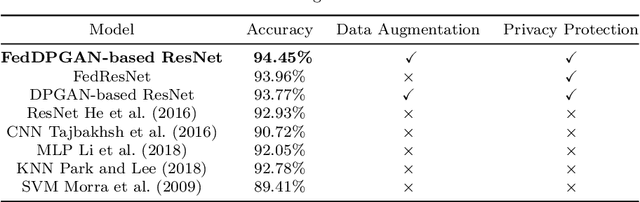

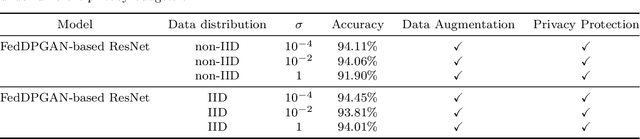
Existing deep learning technologies generally learn the features of chest X-ray data generated by Generative Adversarial Networks (GAN) to diagnose COVID-19 pneumonia. However, the above methods have a critical challenge: data privacy. GAN will leak the semantic information of the training data which can be used to reconstruct the training samples by attackers, thereby this method will leak the privacy of the patient. Furthermore, for this reason that is the limitation of the training data sample, different hospitals jointly train the model through data sharing, which will also cause the privacy leakage. To solve this problem, we adopt the Federated Learning (FL) frame-work which is a new technique being used to protect the data privacy. Under the FL framework and Differentially Private thinking, we propose a FederatedDifferentially Private Generative Adversarial Network (FedDPGAN) to detectCOVID-19 pneumonia for sustainable smart cities. Specifically, we use DP-GAN to privately generate diverse patient data in which differential privacy technology is introduced to make sure the privacy protection of the semantic information of training dataset. Furthermore, we leverage FL to allow hospitals to collaboratively train COVID-19 models without sharing the original data. Under Independent and Identically Distributed (IID) and non-IID settings, The evaluation of the proposed model is on three types of chest X-ray (CXR) images dataset (COVID-19, normal, and normal pneumonia). A large number of the truthful reports make the verification of our model can effectively diagnose COVID-19 without compromising privacy.
One Shot Audio to Animated Video Generation
Feb 19, 2021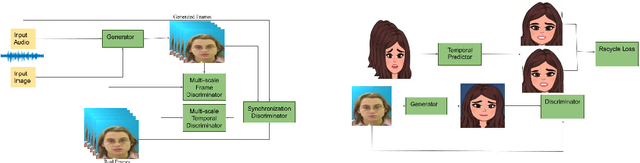
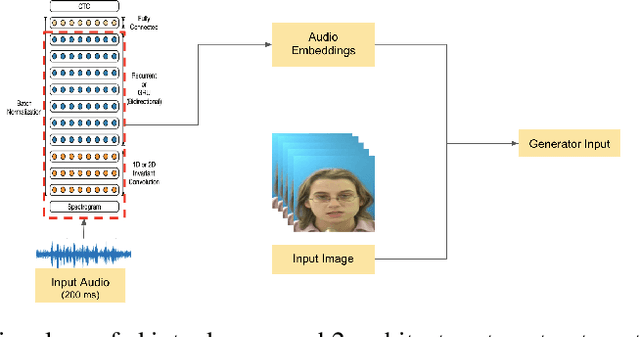


We consider the challenging problem of audio to animated video generation. We propose a novel method OneShotAu2AV to generate an animated video of arbitrary length using an audio clip and a single unseen image of a person as an input. The proposed method consists of two stages. In the first stage, OneShotAu2AV generates the talking-head video in the human domain given an audio and a person's image. In the second stage, the talking-head video from the human domain is converted to the animated domain. The model architecture of the first stage consists of spatially adaptive normalization based multi-level generator and multiple multilevel discriminators along with multiple adversarial and non-adversarial losses. The second stage leverages attention based normalization driven GAN architecture along with temporal predictor based recycle loss and blink loss coupled with lipsync loss, for unsupervised generation of animated video. In our approach, the input audio clip is not restricted to any specific language, which gives the method multilingual applicability. OneShotAu2AV can generate animated videos that have: (a) lip movements that are in sync with the audio, (b) natural facial expressions such as blinks and eyebrow movements, (c) head movements. Experimental evaluation demonstrates superior performance of OneShotAu2AV as compared to U-GAT-IT and RecycleGan on multiple quantitative metrics including KID(Kernel Inception Distance), Word error rate, blinks/sec
Artificial Intelligence based Autonomous Molecular Design for Medical Therapeutic: A Perspective
Feb 10, 2021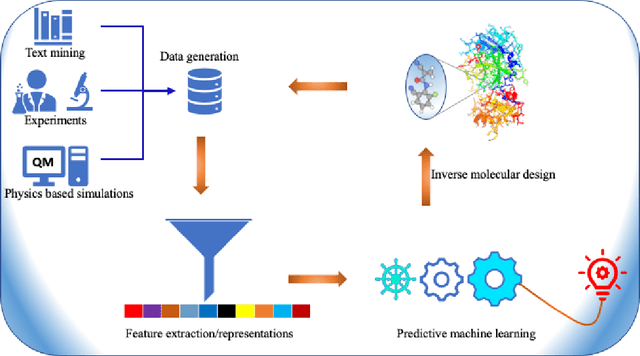

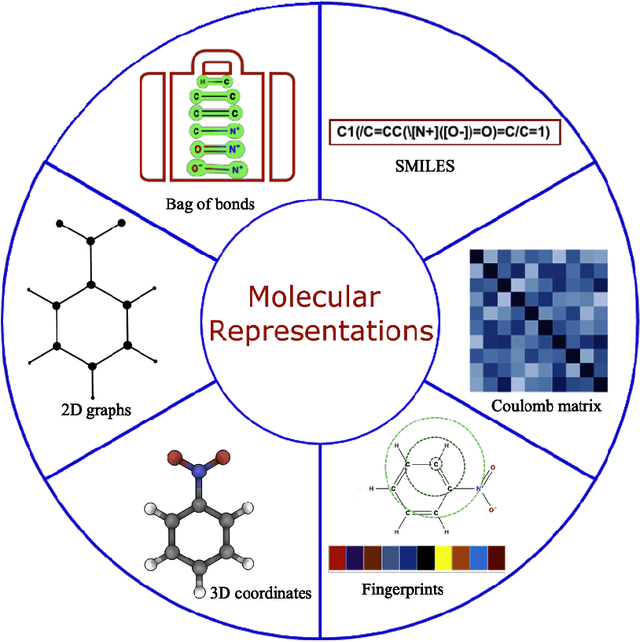
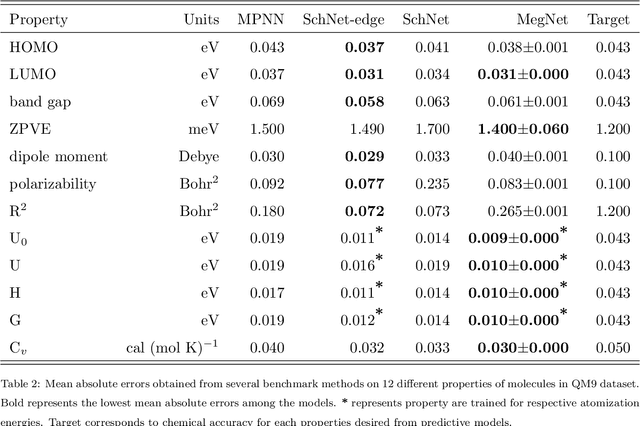
Domain-aware machine learning (ML) models have been increasingly adopted for accelerating small molecule therapeutic design in the recent years. These models have been enabled by significant advancement in state-of-the-art artificial intelligence (AI) and computing infrastructures. Several ML architectures are pre-dominantly and independently used either for predicting the properties of small molecules, or for generating lead therapeutic candidates. Synergetically using these individual components along with robust representation and data generation techniques autonomously in closed loops holds enormous promise for accelerated drug design which is a time consuming and expensive task otherwise. In this perspective, we present the most recent breakthrough achieved by each of the components, and how such autonomous AI and ML workflow can be realized to radically accelerate the hit identification and lead optimization. Taken together, this could significantly shorten the timeline for end-to-end antiviral discovery and optimization times to weeks upon the arrival of a novel zoonotic transmission event. Our perspective serves as a guide for researchers to practice autonomous molecular design in therapeutic discovery.
Benchmarking Deep Graph Generative Models for Optimizing New Drug Molecules for COVID-19
Feb 09, 2021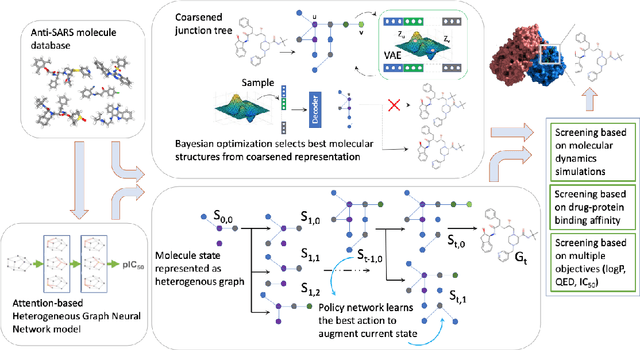
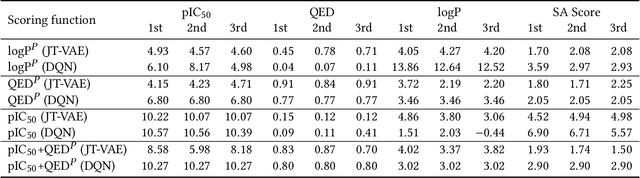
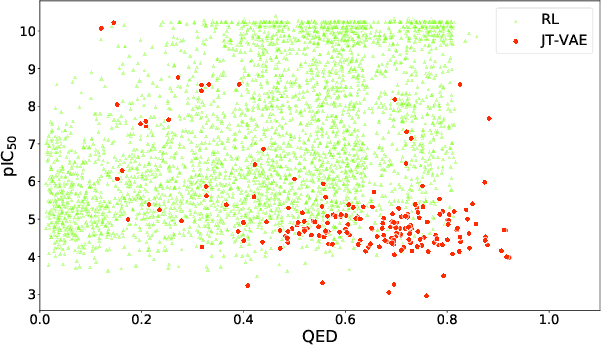
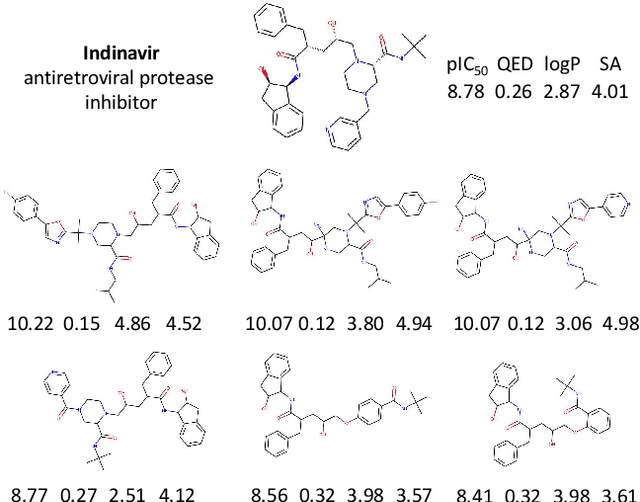
Design of new drug compounds with target properties is a key area of research in generative modeling. We present a small drug molecule design pipeline based on graph-generative models and a comparison study of two state-of-the-art graph generative models for designing COVID-19 targeted drug candidates: 1) a variational autoencoder-based approach (VAE) that uses prior knowledge of molecules that have been shown to be effective for earlier coronavirus treatments and 2) a deep Q-learning method (DQN) that generates optimized molecules without any proximity constraints. We evaluate the novelty of the automated molecule generation approaches by validating the candidate molecules with drug-protein binding affinity models. The VAE method produced two novel molecules with similar structures to the antiretroviral protease inhibitor Indinavir that show potential binding affinity for the SARS-CoV-2 protein target 3-chymotrypsin-like protease (3CL-protease).
Robust One Shot Audio to Video Generation
Dec 14, 2020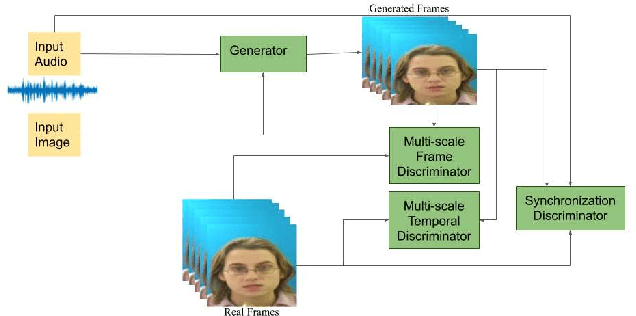
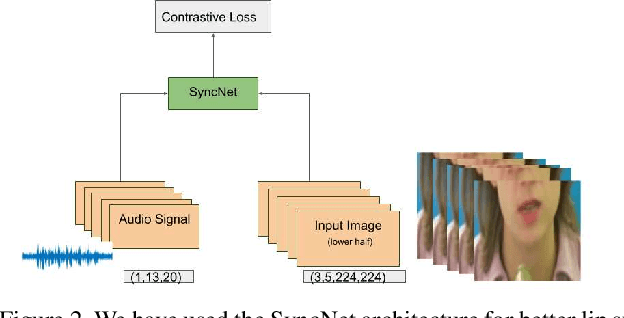

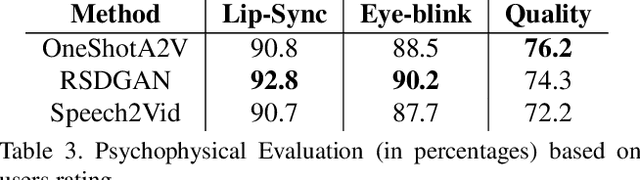
Audio to Video generation is an interesting problem that has numerous applications across industry verticals including film making, multi-media, marketing, education and others. High-quality video generation with expressive facial movements is a challenging problem that involves complex learning steps for generative adversarial networks. Further, enabling one-shot learning for an unseen single image increases the complexity of the problem while simultaneously making it more applicable to practical scenarios. In the paper, we propose a novel approach OneShotA2V to synthesize a talking person video of arbitrary length using as input: an audio signal and a single unseen image of a person. OneShotA2V leverages curriculum learning to learn movements of expressive facial components and hence generates a high-quality talking-head video of the given person. Further, it feeds the features generated from the audio input directly into a generative adversarial network and it adapts to any given unseen selfie by applying fewshot learning with only a few output updation epochs. OneShotA2V leverages spatially adaptive normalization based multi-level generator and multiple multi-level discriminators based architecture. The input audio clip is not restricted to any specific language, which gives the method multilingual applicability. Experimental evaluation demonstrates superior performance of OneShotA2V as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [43], Speech2Vid [8], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio) and CPBD (image sharpness). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.