 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL : Interactive Tool for Systematic Error Analysis and Labeling
Oct 11, 2022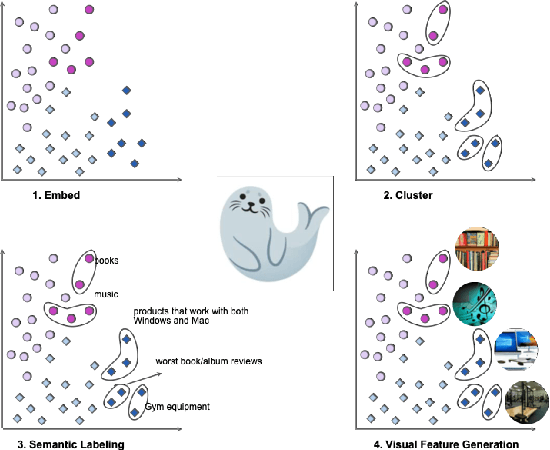
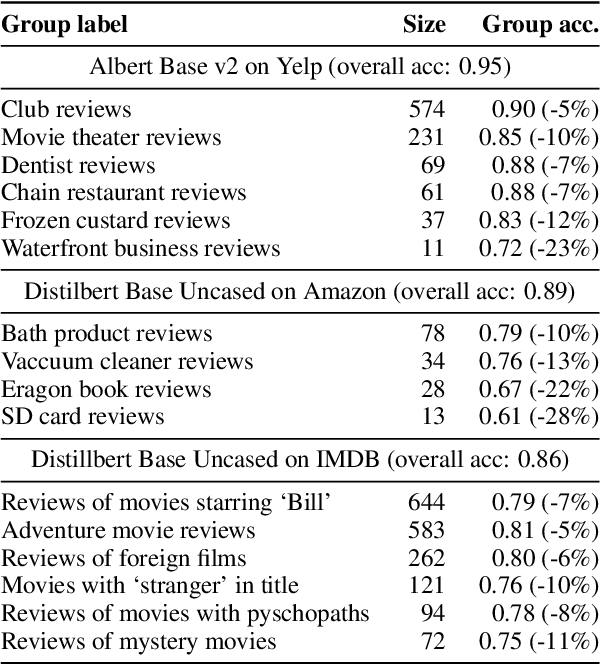

With the advent of Transformers, large language models (LLMs) have saturated well-known NLP benchmarks and leaderboards with high aggregate performance. However, many times these models systematically fail on tail data or rare groups not obvious in aggregate evaluation. Identifying such problematic data groups is even more challenging when there are no explicit labels (e.g., ethnicity, gender, etc.) and further compounded for NLP datasets due to the lack of visual features to characterize failure modes (e.g., Asian males, animals indoors, waterbirds on land, etc.). This paper introduces an interactive Systematic Error Analysis and Labeling (\seal) tool that uses a two-step approach to first identify high error slices of data and then, in the second step, introduce methods to give human-understandable semantics to those underperforming slices. We explore a variety of methods for coming up with coherent semantics for the error groups using language models for semantic labeling and a text-to-image model for generating visual features. SEAL toolkit and demo screencast is available at https://huggingface.co/spaces/nazneen/seal.
Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
Oct 06, 2022
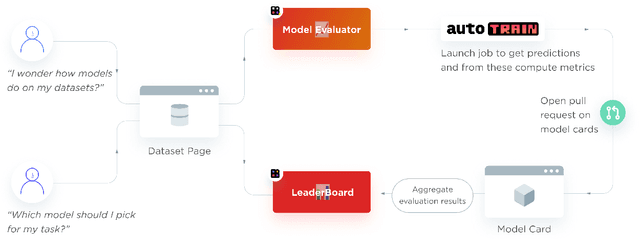
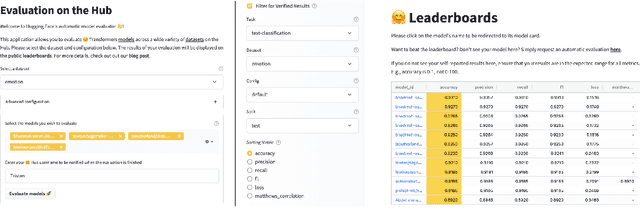
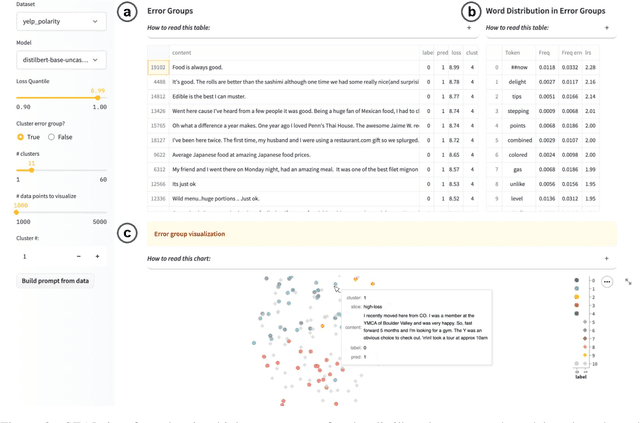
Evaluation is a key part of machine learning (ML), yet there is a lack of support and tooling to enable its informed and systematic practice. We introduce Evaluate and Evaluation on the Hub --a set of tools to facilitate the evaluation of models and datasets in ML. Evaluate is a library to support best practices for measurements, metrics, and comparisons of data and models. Its goal is to support reproducibility of evaluation, centralize and document the evaluation process, and broaden evaluation to cover more facets of model performance. It includes over 50 efficient canonical implementations for a variety of domains and scenarios, interactive documentation, and the ability to easily share implementations and outcomes. The library is available at https://github.com/huggingface/evaluate. In addition, we introduce Evaluation on the Hub, a platform that enables the large-scale evaluation of over 75,000 models and 11,000 datasets on the Hugging Face Hub, for free, at the click of a button. Evaluation on the Hub is available at https://huggingface.co/autoevaluate.
Interactive Model Cards: A Human-Centered Approach to Model Documentation
May 05, 2022
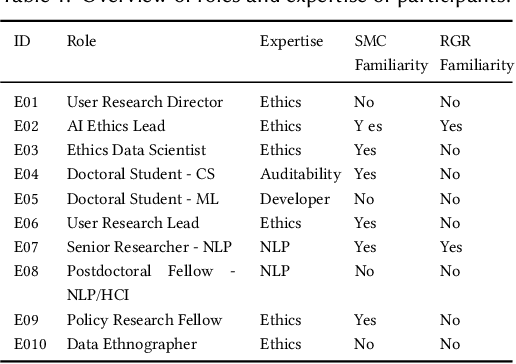
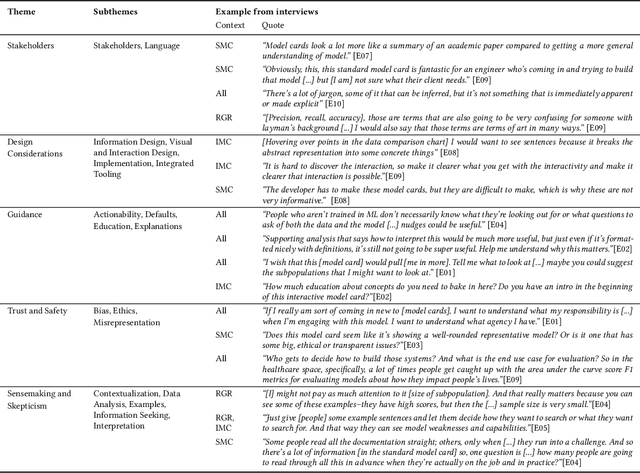

Deep learning models for natural language processing (NLP) are increasingly adopted and deployed by analysts without formal training in NLP or machine learning (ML). However, the documentation intended to convey the model's details and appropriate use is tailored primarily to individuals with ML or NLP expertise. To address this gap, we conduct a design inquiry into interactive model cards, which augment traditionally static model cards with affordances for exploring model documentation and interacting with the models themselves. Our investigation consists of an initial conceptual study with experts in ML, NLP, and AI Ethics, followed by a separate evaluative study with non-expert analysts who use ML models in their work. Using a semi-structured interview format coupled with a think-aloud protocol, we collected feedback from a total of 30 participants who engaged with different versions of standard and interactive model cards. Through a thematic analysis of the collected data, we identified several conceptual dimensions that summarize the strengths and limitations of standard and interactive model cards, including: stakeholders; design; guidance; understandability & interpretability; sensemaking & skepticism; and trust & safety. Our findings demonstrate the importance of carefully considered design and interactivity for orienting and supporting non-expert analysts using deep learning models, along with a need for consideration of broader sociotechnical contexts and organizational dynamics. We have also identified design elements, such as language, visual cues, and warnings, among others, that support interactivity and make non-interactive content accessible. We summarize our findings as design guidelines and discuss their implications for a human-centered approach towards AI/ML documentation.
iSEA: An Interactive Pipeline for Semantic Error Analysis of NLP Models
Mar 08, 2022
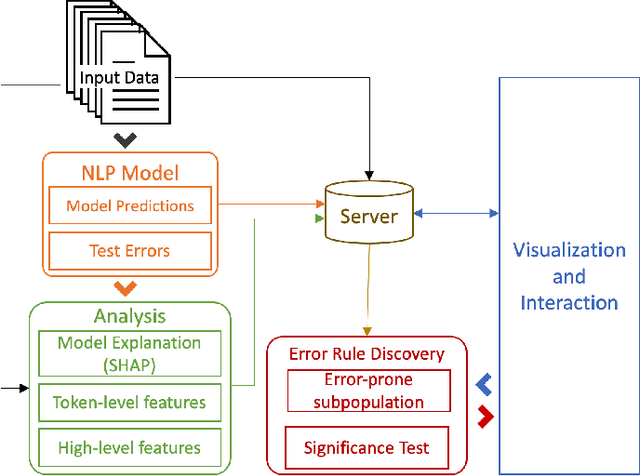
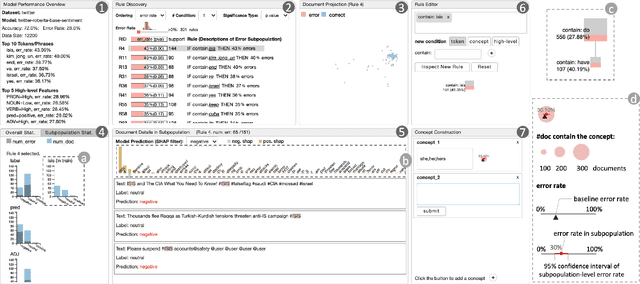
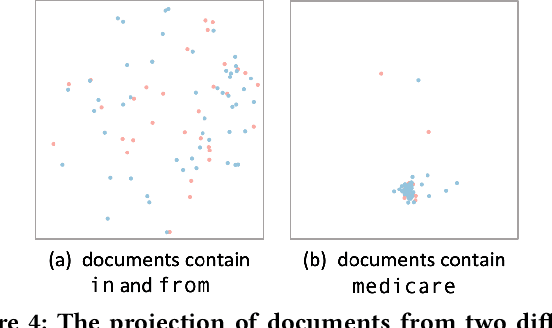
Error analysis in NLP models is essential to successful model development and deployment. One common approach for diagnosing errors is to identify subpopulations in the dataset where the model produces the most errors. However, existing approaches typically define subpopulations based on pre-defined features, which requires users to form hypotheses of errors in advance. To complement these approaches, we propose iSEA, an Interactive Pipeline for Semantic Error Analysis in NLP Models, which automatically discovers semantically-grounded subpopulations with high error rates in the context of a human-in-the-loop interactive system. iSEA enables model developers to learn more about their model errors through discovered subpopulations, validate the sources of errors through interactive analysis on the discovered subpopulations, and test hypotheses about model errors by defining custom subpopulations. The tool supports semantic descriptions of error-prone subpopulations at the token and concept level, as well as pre-defined higher-level features. Through use cases and expert interviews, we demonstrate how iSEA can assist error understanding and analysis.
P-Adapters: Robustly Extracting Factual Information from Language Models with Diverse Prompts
Oct 14, 2021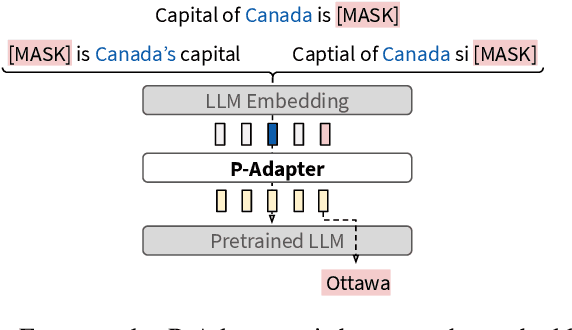
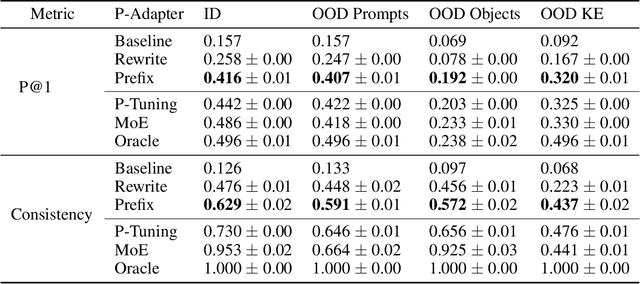
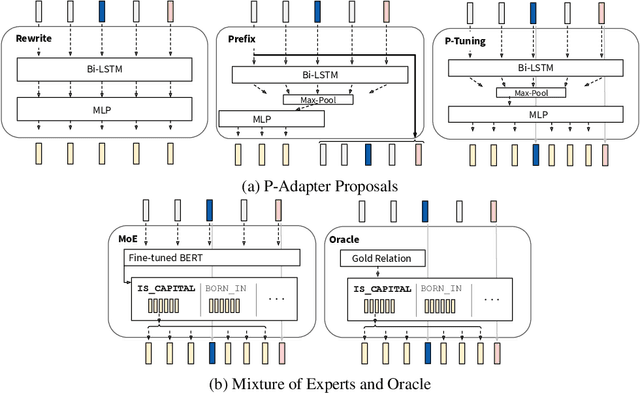
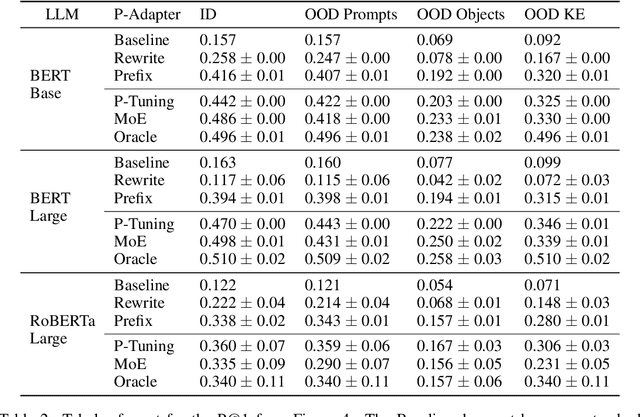
Recent work (e.g. LAMA (Petroni et al., 2019)) has found that the quality of the factual information extracted from Large Language Models (LLMs) depends on the prompts used to query them. This inconsistency is problematic because different users will query LLMs for the same information using different wording, but should receive the same, accurate responses regardless. In this work we aim to address this shortcoming by introducing P-Adapters: lightweight models that sit between the embedding layer and first attention layer of LLMs. They take LLM embeddings as input and output continuous prompts that are used to query the LLM. Additionally, we investigate Mixture of Experts (MoE) models that learn a set of continuous prompts ("experts") and select one to query the LLM. They require a separate classifier trained on human-annotated data to map natural language prompts to the continuous ones. P-Adapters perform comparably to the more complex MoE models in extracting factual information from BERT and RoBERTa while eliminating the need for additional annotations. P-Adapters show between 12-26% absolute improvement in precision and 36-50% absolute improvement in consistency over a baseline of only using natural language queries. Finally, we investigate what makes a P-adapter successful and conclude that access to the LLM's embeddings of the original natural language prompt, particularly the subject of the entity pair being asked about, is a significant factor.
Stage-wise Fine-tuning for Graph-to-Text Generation
May 30, 2021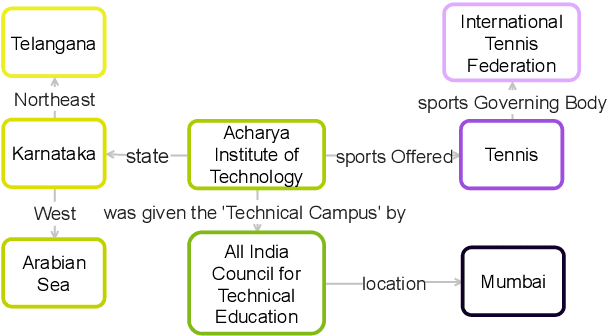

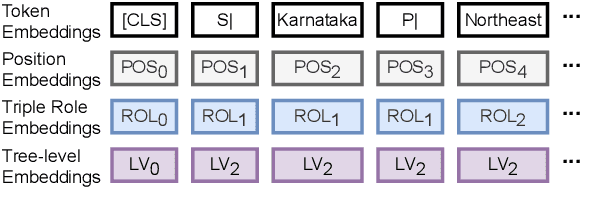
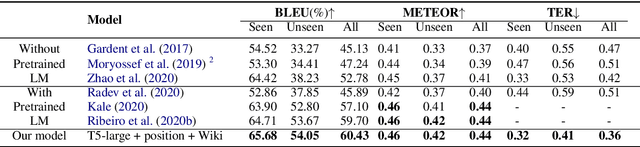
Graph-to-text generation has benefited from pre-trained language models (PLMs) in achieving better performance than structured graph encoders. However, they fail to fully utilize the structure information of the input graph. In this paper, we aim to further improve the performance of the pre-trained language model by proposing a structured graph-to-text model with a two-step fine-tuning mechanism which first fine-tunes the model on Wikipedia before adapting to the graph-to-text generation. In addition to using the traditional token and position embeddings to encode the knowledge graph (KG), we propose a novel tree-level embedding method to capture the inter-dependency structures of the input graph. This new approach has significantly improved the performance of all text generation metrics for the English WebNLG 2017 dataset.
BookSum: A Collection of Datasets for Long-form Narrative Summarization
May 18, 2021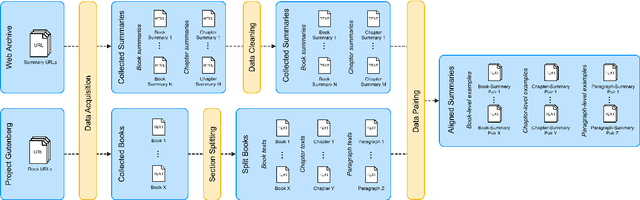
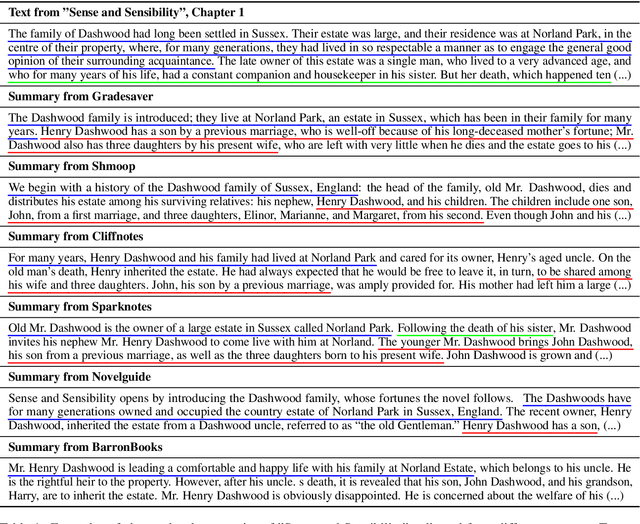
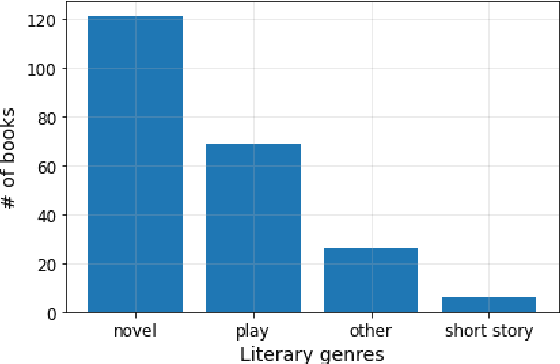
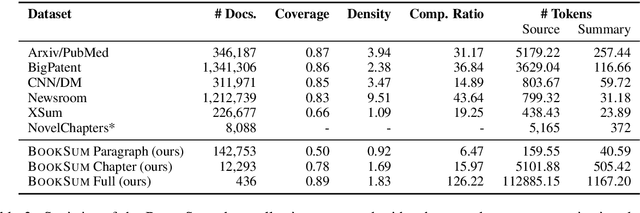
The majority of available text summarization datasets include short-form source documents that lack long-range causal and temporal dependencies, and often contain strong layout and stylistic biases. While relevant, such datasets will offer limited challenges for future generations of text summarization systems. We address these issues by introducing BookSum, a collection of datasets for long-form narrative summarization. Our dataset covers source documents from the literature domain, such as novels, plays and stories, and includes highly abstractive, human written summaries on three levels of granularity of increasing difficulty: paragraph-, chapter-, and book-level. The domain and structure of our dataset poses a unique set of challenges for summarization systems, which include: processing very long documents, non-trivial causal and temporal dependencies, and rich discourse structures. To facilitate future work, we trained and evaluated multiple extractive and abstractive summarization models as baselines for our dataset.
Robustness Gym: Unifying the NLP Evaluation Landscape
Jan 13, 2021Despite impressive performance on standard benchmarks, deep neural networks are often brittle when deployed in real-world systems. Consequently, recent research has focused on testing the robustness of such models, resulting in a diverse set of evaluation methodologies ranging from adversarial attacks to rule-based data transformations. In this work, we identify challenges with evaluating NLP systems and propose a solution in the form of Robustness Gym (RG), a simple and extensible evaluation toolkit that unifies 4 standard evaluation paradigms: subpopulations, transformations, evaluation sets, and adversarial attacks. By providing a common platform for evaluation, Robustness Gym enables practitioners to compare results from all 4 evaluation paradigms with just a few clicks, and to easily develop and share novel evaluation methods using a built-in set of abstractions. To validate Robustness Gym's utility to practitioners, we conducted a real-world case study with a sentiment-modeling team, revealing performance degradations of 18%+. To verify that Robustness Gym can aid novel research analyses, we perform the first study of state-of-the-art commercial and academic named entity linking (NEL) systems, as well as a fine-grained analysis of state-of-the-art summarization models. For NEL, commercial systems struggle to link rare entities and lag their academic counterparts by 10%+, while state-of-the-art summarization models struggle on examples that require abstraction and distillation, degrading by 9%+. Robustness Gym can be found at https://robustnessgym.com/
CTRLsum: Towards Generic Controllable Text Summarization
Dec 08, 2020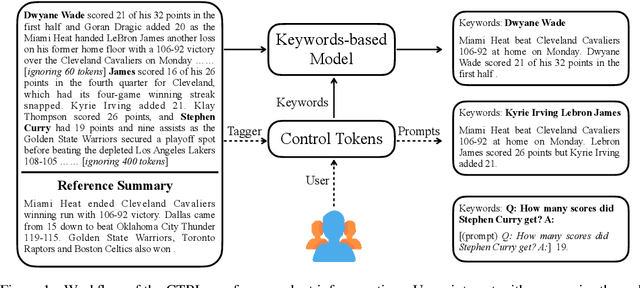
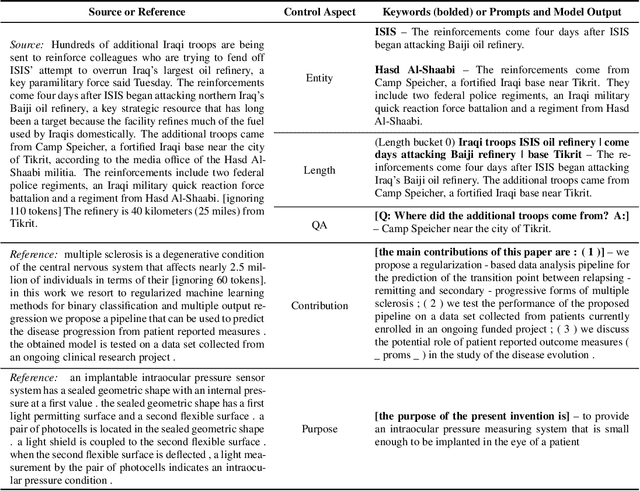
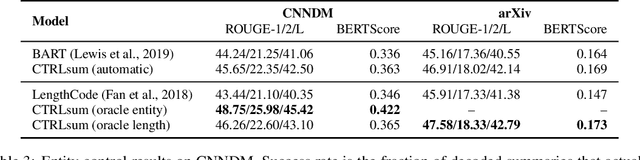
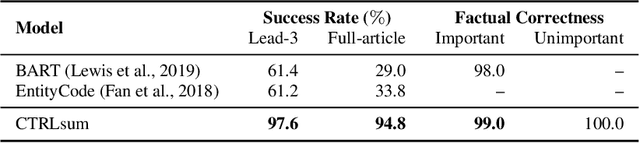
Current summarization systems yield generic summaries that are disconnected from users' preferences and expectations. To address this limitation, we present CTRLsum, a novel framework for controllable summarization. Our approach enables users to control multiple aspects of generated summaries by interacting with the summarization system through textual input in the form of a set of keywords or descriptive prompts. Using a single unified model, CTRLsum is able to achieve a broad scope of summary manipulation at inference time without requiring additional human annotations or pre-defining a set of control aspects during training. We quantitatively demonstrate the effectiveness of our approach on three domains of summarization datasets and five control aspects: 1) entity-centric and 2) length-controllable summarization, 3) contribution summarization on scientific papers, 4) invention purpose summarization on patent filings, and 5) question-guided summarization on news articles in a reading comprehension setting. Moreover, when used in a standard, uncontrolled summarization setting, CTRLsum achieves state-of-the-art results on the CNN/DailyMail dataset. Code and model checkpoints are available at https://github.com/salesforce/ctrl-sum
What's New? Summarizing Contributions in Scientific Literature
Nov 09, 2020
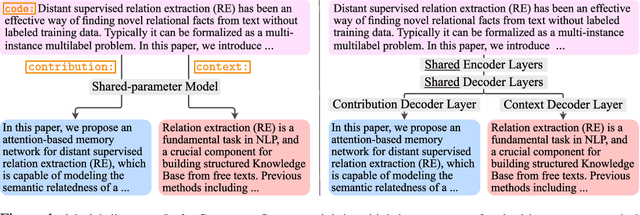
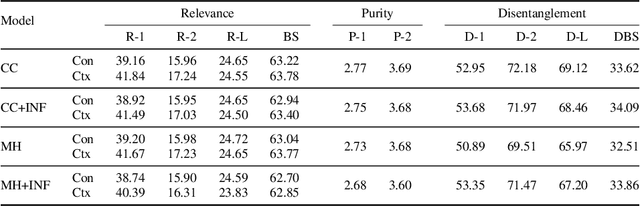

With thousands of academic articles shared on a daily basis, it has become increasingly difficult to keep up with the latest scientific findings. To overcome this problem, we introduce a new task of disentangled paper summarization, which seeks to generate separate summaries for the paper contributions and the context of the work, making it easier to identify the key findings shared in articles. For this purpose, we extend the S2ORC corpus of academic articles, which spans a diverse set of domains ranging from economics to psychology, by adding disentangled "contribution" and "context" reference labels. Together with the dataset, we introduce and analyze three baseline approaches: 1) a unified model controlled by input code prefixes, 2) a model with separate generation heads specialized in generating the disentangled outputs, and 3) a training strategy that guides the model using additional supervision coming from inbound and outbound citations. We also propose a comprehensive automatic evaluation protocol which reports the relevance, novelty, and disentanglement of generated outputs. Through a human study involving expert annotators, we show that in 79%, of cases our new task is considered more helpful than traditional scientific paper summarization.