 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrowing the Gap: Random Forests In Theory and In Practice
Oct 04, 2013

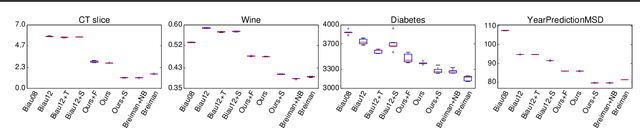
Despite widespread interest and practical use, the theoretical properties of random forests are still not well understood. In this paper we contribute to this understanding in two ways. We present a new theoretically tractable variant of random regression forests and prove that our algorithm is consistent. We also provide an empirical evaluation, comparing our algorithm and other theoretically tractable random forest models to the random forest algorithm used in practice. Our experiments provide insight into the relative importance of different simplifications that theoreticians have made to obtain tractable models for analysis.
Consistency of Online Random Forests
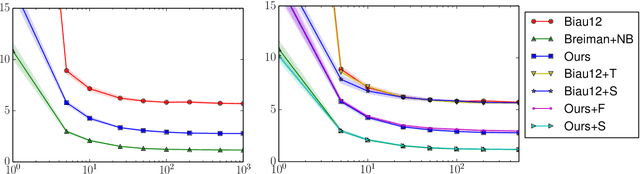
May 08, 2013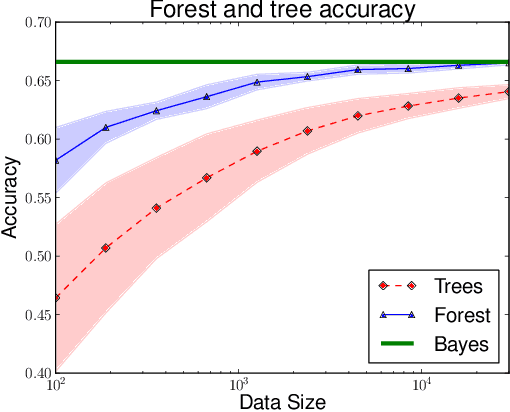
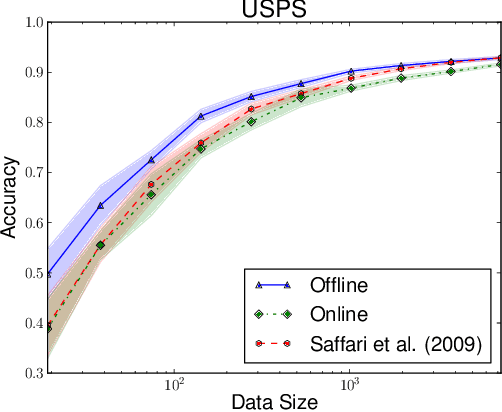
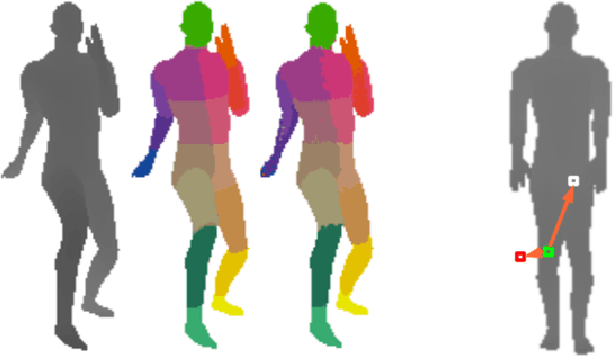
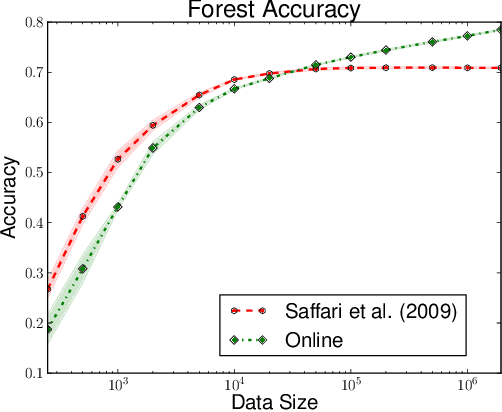
As a testament to their success, the theory of random forests has long been outpaced by their application in practice. In this paper, we take a step towards narrowing this gap by providing a consistency result for online random forests.
Herded Gibbs Sampling
Mar 16, 2013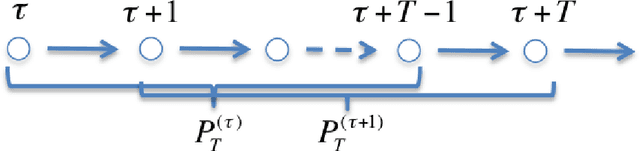
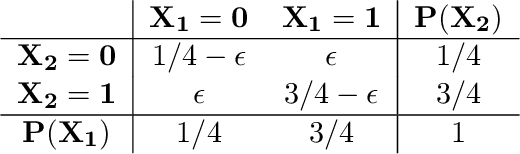
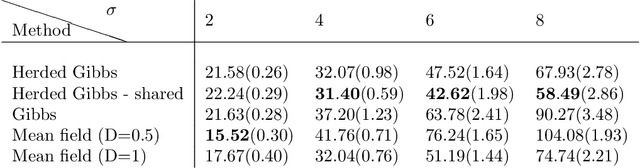
The Gibbs sampler is one of the most popular algorithms for inference in statistical models. In this paper, we introduce a herding variant of this algorithm, called herded Gibbs, that is entirely deterministic. We prove that herded Gibbs has an $O(1/T)$ convergence rate for models with independent variables and for fully connected probabilistic graphical models. Herded Gibbs is shown to outperform Gibbs in the tasks of image denoising with MRFs and named entity recognition with CRFs. However, the convergence for herded Gibbs for sparsely connected probabilistic graphical models is still an open problem.
Rao-Blackwellised Particle Filtering for Dynamic Bayesian Networks
Jan 16, 2013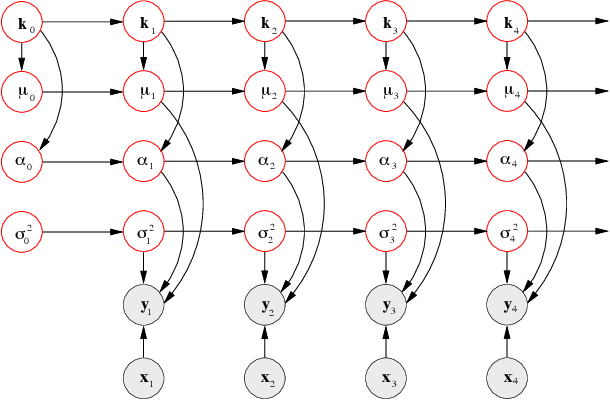
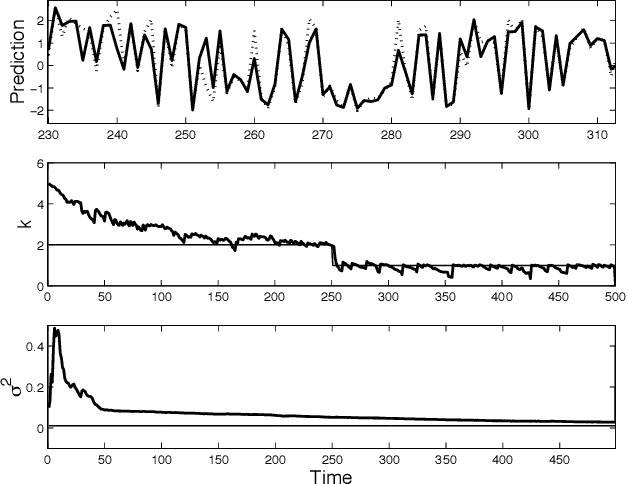
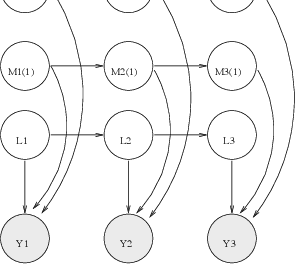
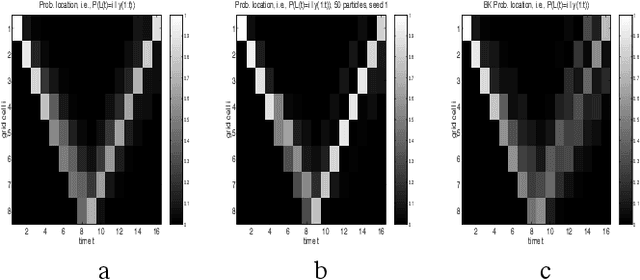
Particle filters (PFs) are powerful sampling-based inference/learning algorithms for dynamic Bayesian networks (DBNs). They allow us to treat, in a principled way, any type of probability distribution, nonlinearity and non-stationarity. They have appeared in several fields under such names as "condensation", "sequential Monte Carlo" and "survival of the fittest". In this paper, we show how we can exploit the structure of the DBN to increase the efficiency of particle filtering, using a technique known as Rao-Blackwellisation. Essentially, this samples some of the variables, and marginalizes out the rest exactly, using the Kalman filter, HMM filter, junction tree algorithm, or any other finite dimensional optimal filter. We show that Rao-Blackwellised particle filters (RBPFs) lead to more accurate estimates than standard PFs. We demonstrate RBPFs on two problems, namely non-stationary online regression with radial basis function networks and robot localization and map building. We also discuss other potential application areas and provide references to some finite dimensional optimal filters.
Reversible Jump MCMC Simulated Annealing for Neural Networks
Jan 16, 2013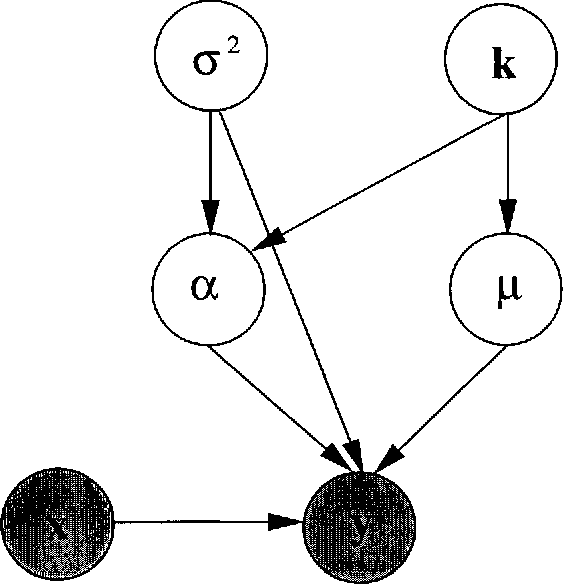
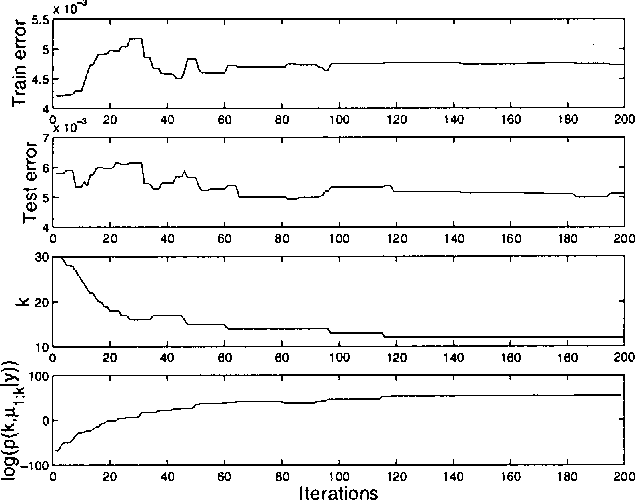
We propose a novel reversible jump Markov chain Monte Carlo (MCMC) simulated annealing algorithm to optimize radial basis function (RBF) networks. This algorithm enables us to maximize the joint posterior distribution of the network parameters and the number of basis functions. It performs a global search in the joint space of the parameters and number of parameters, thereby surmounting the problem of local minima. We also show that by calibrating a Bayesian model, we can obtain the classical AIC, BIC and MDL model selection criteria within a penalized likelihood framework. Finally, we show theoretically and empirically that the algorithm converges to the modes of the full posterior distribution in an efficient way.
Variational MCMC
Jan 10, 2013We propose a new class of learning algorithms that combines variational approximation and Markov chain Monte Carlo (MCMC) simulation. Naive algorithms that use the variational approximation as proposal distribution can perform poorly because this approximation tends to underestimate the true variance and other features of the data. We solve this problem by introducing more sophisticated MCMC algorithms. One of these algorithms is a mixture of two MCMC kernels: a random walk Metropolis kernel and a blockMetropolis-Hastings (MH) kernel with a variational approximation as proposaldistribution. The MH kernel allows one to locate regions of high probability efficiently. The Metropolis kernel allows us to explore the vicinity of these regions. This algorithm outperforms variationalapproximations because it yields slightly better estimates of the mean and considerably better estimates of higher moments, such as covariances. It also outperforms standard MCMC algorithms because it locates theregions of high probability quickly, thus speeding up convergence. We demonstrate this algorithm on the problem of Bayesian parameter estimation for logistic (sigmoid) belief networks.
Recklessly Approximate Sparse Coding
Jan 06, 2013
It has recently been observed that certain extremely simple feature encoding techniques are able to achieve state of the art performance on several standard image classification benchmarks including deep belief networks, convolutional nets, factored RBMs, mcRBMs, convolutional RBMs, sparse autoencoders and several others. Moreover, these "triangle" or "soft threshold" encodings are ex- tremely efficient to compute. Several intuitive arguments have been put forward to explain this remarkable performance, yet no mathematical justification has been offered. The main result of this report is to show that these features are realized as an approximate solution to the a non-negative sparse coding problem. Using this connection we describe several variants of the soft threshold features and demonstrate their effectiveness on two image classification benchmark tasks.
From Fields to Trees
Jul 11, 2012

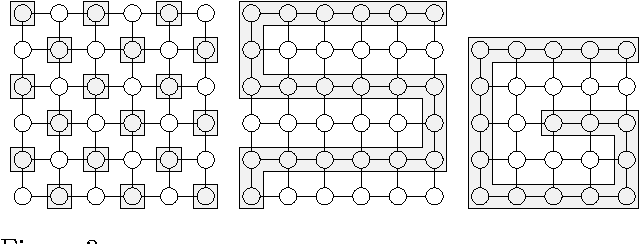
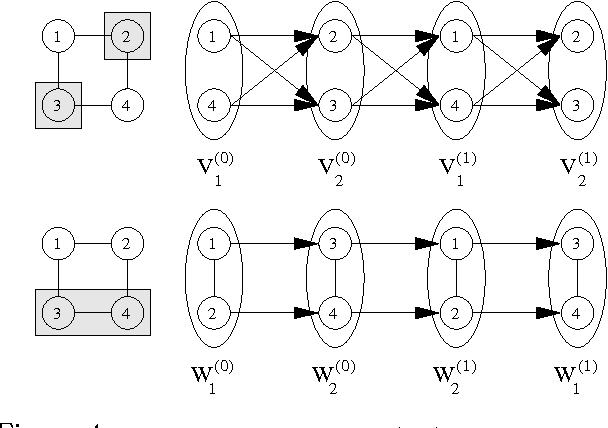
We present new MCMC algorithms for computing the posterior distributions and expectations of the unknown variables in undirected graphical models with regular structure. For demonstration purposes, we focus on Markov Random Fields (MRFs). By partitioning the MRFs into non-overlapping trees, it is possible to compute the posterior distribution of a particular tree exactly by conditioning on the remaining tree. These exact solutions allow us to construct efficient blocked and Rao-Blackwellised MCMC algorithms. We show empirically that tree sampling is considerably more efficient than other partitioned sampling schemes and the naive Gibbs sampler, even in cases where loopy belief propagation fails to converge. We prove that tree sampling exhibits lower variance than the naive Gibbs sampler and other naive partitioning schemes using the theoretical measure of maximal correlation. We also construct new information theory tools for comparing different MCMC schemes and show that, under these, tree sampling is more efficient.
Toward Practical N2 Monte Carlo: the Marginal Particle Filter
Jul 04, 2012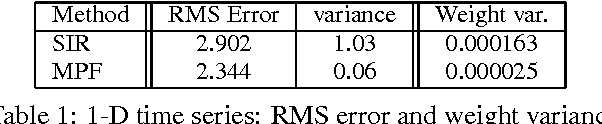


Sequential Monte Carlo techniques are useful for state estimation in non-linear, non-Gaussian dynamic models. These methods allow us to approximate the joint posterior distribution using sequential importance sampling. In this framework, the dimension of the target distribution grows with each time step, thus it is necessary to introduce some resampling steps to ensure that the estimates provided by the algorithm have a reasonable variance. In many applications, we are only interested in the marginal filtering distribution which is defined on a space of fixed dimension. We present a Sequential Monte Carlo algorithm called the Marginal Particle Filter which operates directly on the marginal distribution, hence avoiding having to perform importance sampling on a space of growing dimension. Using this idea, we also derive an improved version of the auxiliary particle filter. We show theoretic and empirical results which demonstrate a reduction in variance over conventional particle filtering, and present techniques for reducing the cost of the marginal particle filter with N particles from O(N2) to O(N logN).
Learning about individuals from group statistics
Jul 04, 2012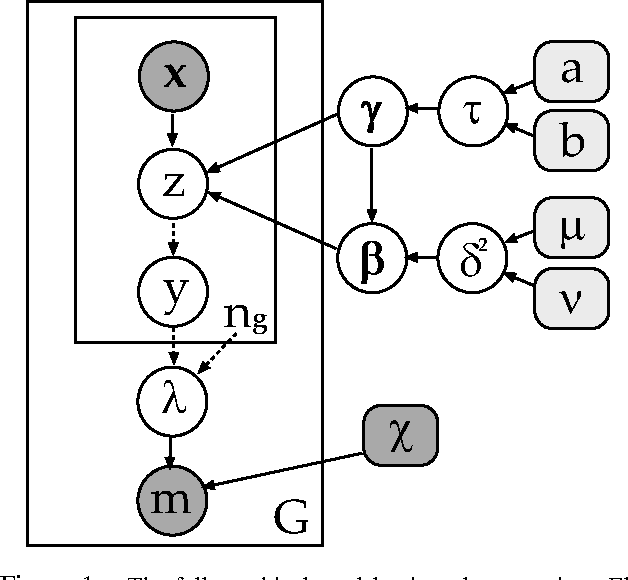
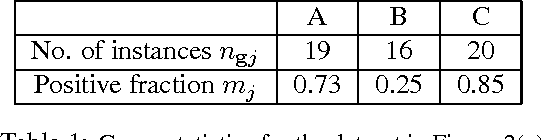
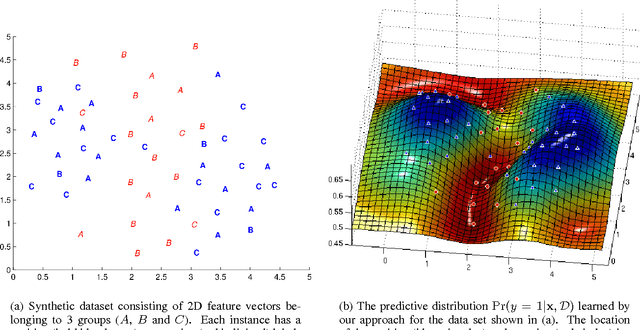
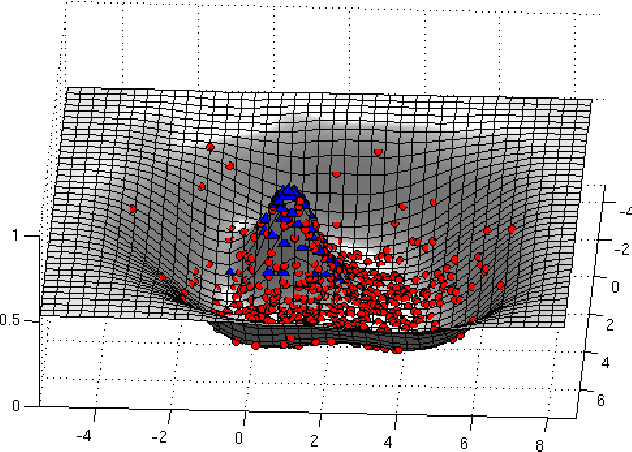
We propose a new problem formulation which is similar to, but more informative than, the binary multiple-instance learning problem. In this setting, we are given groups of instances (described by feature vectors) along with estimates of the fraction of positively-labeled instances per group. The task is to learn an instance level classifier from this information. That is, we are trying to estimate the unknown binary labels of individuals from knowledge of group statistics. We propose a principled probabilistic model to solve this problem that accounts for uncertainty in the parameters and in the unknown individual labels. This model is trained with an efficient MCMC algorithm. Its performance is demonstrated on both synthetic and real-world data arising in general object recognition.