 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDueling Network Architectures for Deep Reinforcement Learning
Apr 05, 2016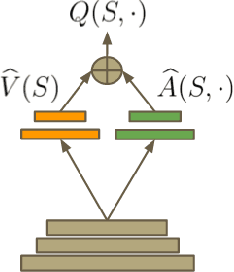
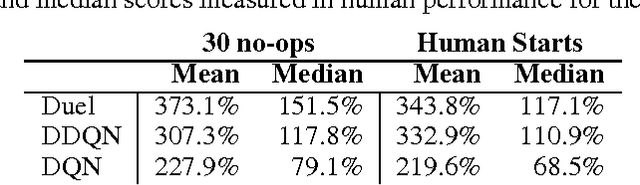
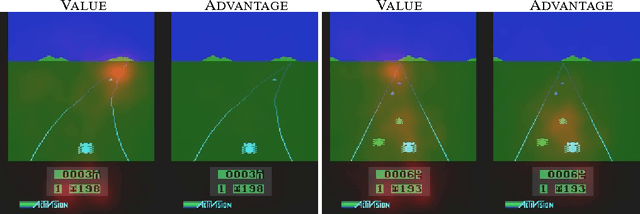
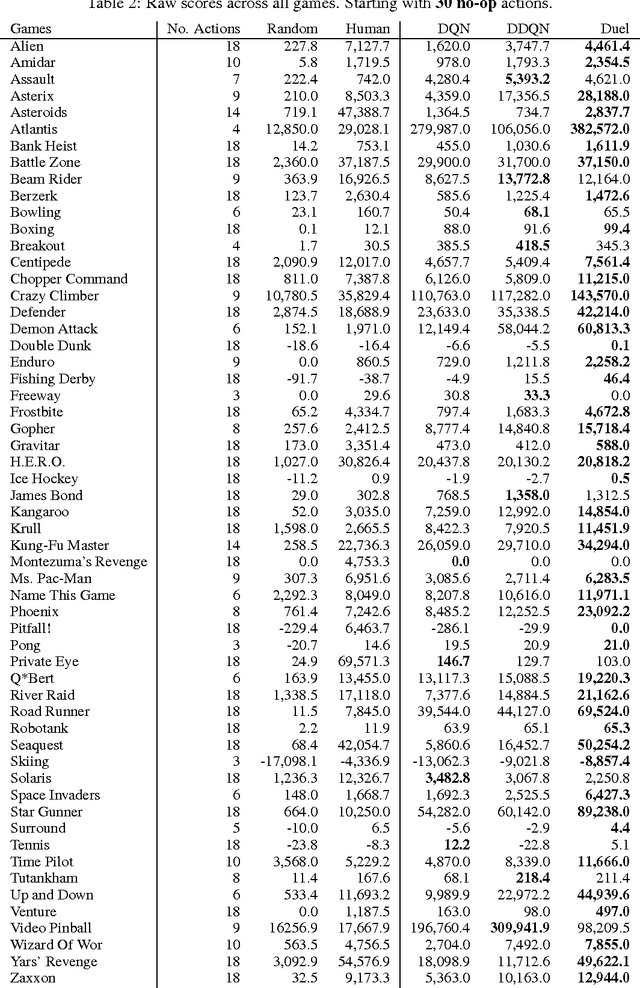
In recent years there have been many successes of using deep representations in reinforcement learning. Still, many of these applications use conventional architectures, such as convolutional networks, LSTMs, or auto-encoders. In this paper, we present a new neural network architecture for model-free reinforcement learning. Our dueling network represents two separate estimators: one for the state value function and one for the state-dependent action advantage function. The main benefit of this factoring is to generalize learning across actions without imposing any change to the underlying reinforcement learning algorithm. Our results show that this architecture leads to better policy evaluation in the presence of many similar-valued actions. Moreover, the dueling architecture enables our RL agent to outperform the state-of-the-art on the Atari 2600 domain.
ACDC: A Structured Efficient Linear Layer
Mar 19, 2016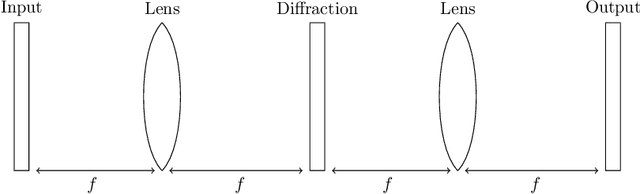
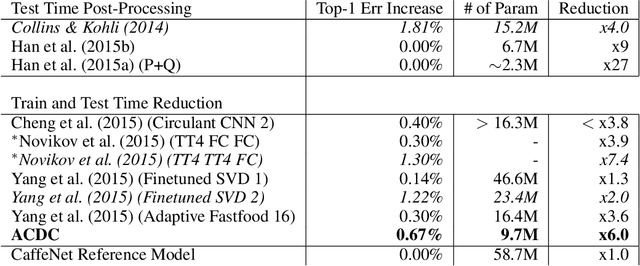

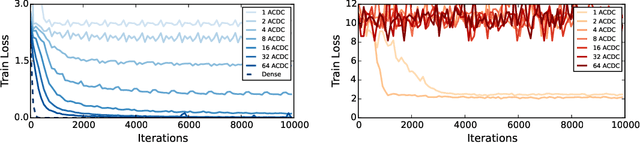
The linear layer is one of the most pervasive modules in deep learning representations. However, it requires $O(N^2)$ parameters and $O(N^2)$ operations. These costs can be prohibitive in mobile applications or prevent scaling in many domains. Here, we introduce a deep, differentiable, fully-connected neural network module composed of diagonal matrices of parameters, $\mathbf{A}$ and $\mathbf{D}$, and the discrete cosine transform $\mathbf{C}$. The core module, structured as $\mathbf{ACDC^{-1}}$, has $O(N)$ parameters and incurs $O(N log N )$ operations. We present theoretical results showing how deep cascades of ACDC layers approximate linear layers. ACDC is, however, a stand-alone module and can be used in combination with any other types of module. In our experiments, we show that it can indeed be successfully interleaved with ReLU modules in convolutional neural networks for image recognition. Our experiments also study critical factors in the training of these structured modules, including initialization and depth. Finally, this paper also provides a connection between structured linear transforms used in deep learning and the field of Fourier optics, illustrating how ACDC could in principle be implemented with lenses and diffractive elements.
Neural Programmer-Interpreters
Feb 29, 2016
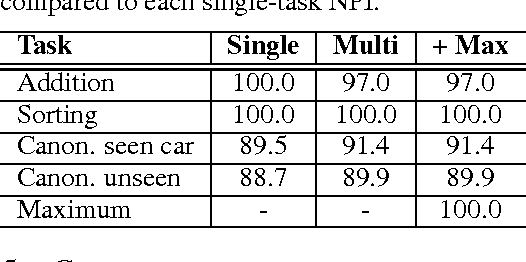
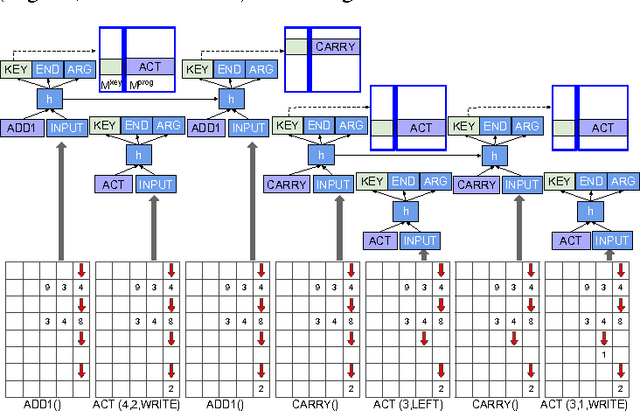
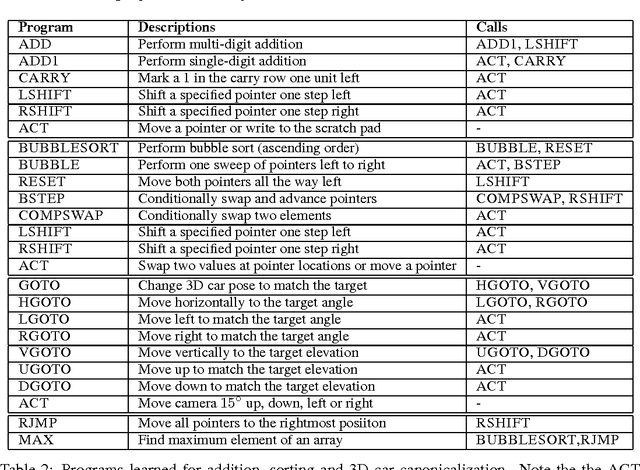
We propose the neural programmer-interpreter (NPI): a recurrent and compositional neural network that learns to represent and execute programs. NPI has three learnable components: a task-agnostic recurrent core, a persistent key-value program memory, and domain-specific encoders that enable a single NPI to operate in multiple perceptually diverse environments with distinct affordances. By learning to compose lower-level programs to express higher-level programs, NPI reduces sample complexity and increases generalization ability compared to sequence-to-sequence LSTMs. The program memory allows efficient learning of additional tasks by building on existing programs. NPI can also harness the environment (e.g. a scratch pad with read-write pointers) to cache intermediate results of computation, lessening the long-term memory burden on recurrent hidden units. In this work we train the NPI with fully-supervised execution traces; each program has example sequences of calls to the immediate subprograms conditioned on the input. Rather than training on a huge number of relatively weak labels, NPI learns from a small number of rich examples. We demonstrate the capability of our model to learn several types of compositional programs: addition, sorting, and canonicalizing 3D models. Furthermore, a single NPI learns to execute these programs and all 21 associated subprograms.
Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
Feb 08, 2016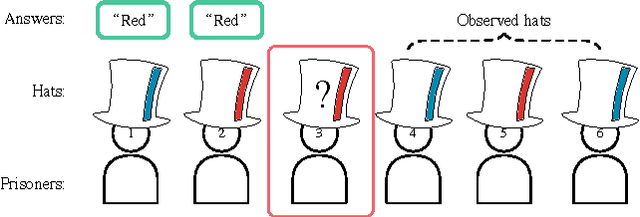
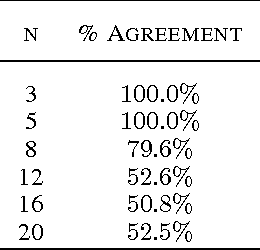
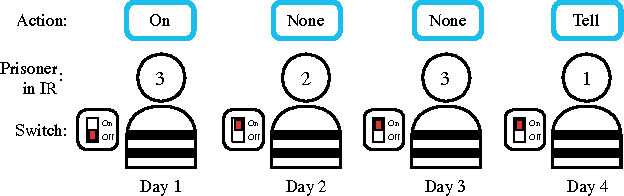
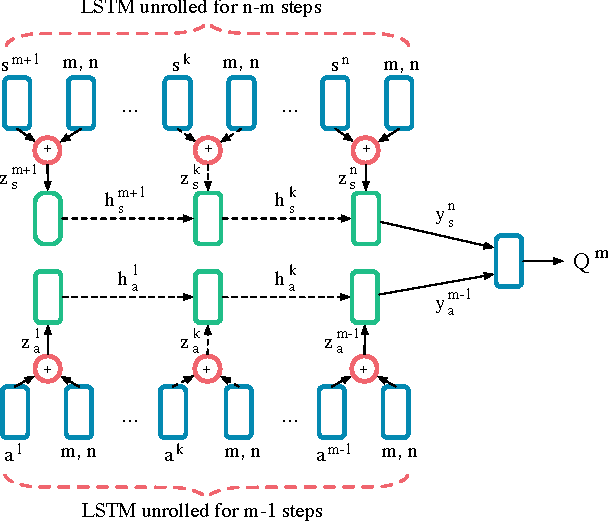
We propose deep distributed recurrent Q-networks (DDRQN), which enable teams of agents to learn to solve communication-based coordination tasks. In these tasks, the agents are not given any pre-designed communication protocol. Therefore, in order to successfully communicate, they must first automatically develop and agree upon their own communication protocol. We present empirical results on two multi-agent learning problems based on well-known riddles, demonstrating that DDRQN can successfully solve such tasks and discover elegant communication protocols to do so. To our knowledge, this is the first time deep reinforcement learning has succeeded in learning communication protocols. In addition, we present ablation experiments that confirm that each of the main components of the DDRQN architecture are critical to its success.
Bayesian Optimization in a Billion Dimensions via Random Embeddings
Jan 10, 2016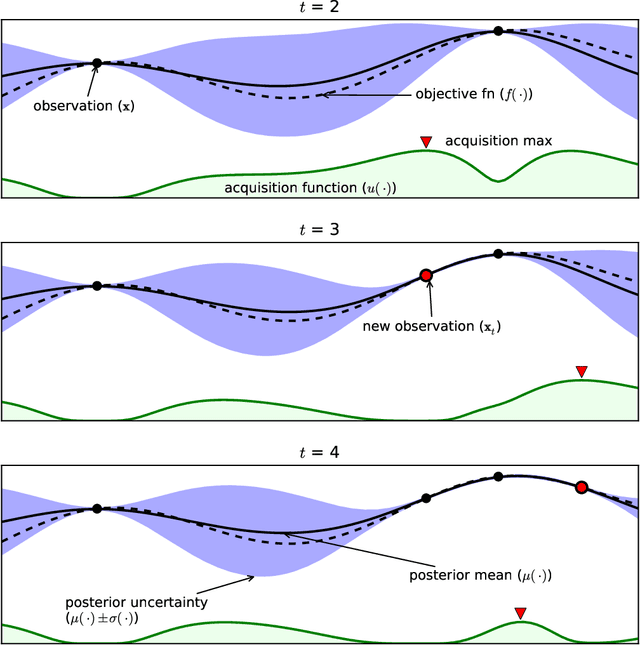
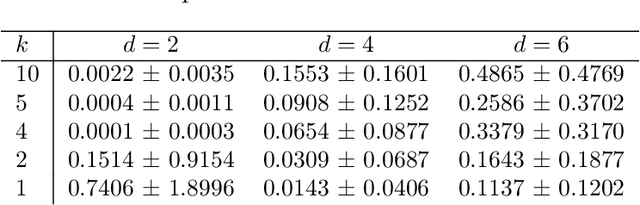
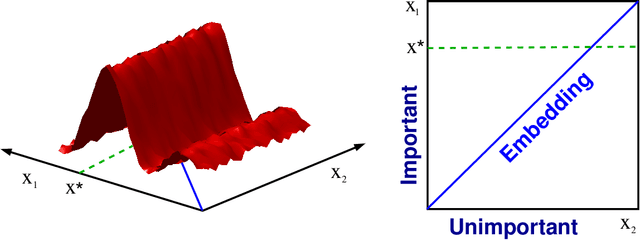

Bayesian optimization techniques have been successfully applied to robotics, planning, sensor placement, recommendation, advertising, intelligent user interfaces and automatic algorithm configuration. Despite these successes, the approach is restricted to problems of moderate dimension, and several workshops on Bayesian optimization have identified its scaling to high-dimensions as one of the holy grails of the field. In this paper, we introduce a novel random embedding idea to attack this problem. The resulting Random EMbedding Bayesian Optimization (REMBO) algorithm is very simple, has important invariance properties, and applies to domains with both categorical and continuous variables. We present a thorough theoretical analysis of REMBO. Empirical results confirm that REMBO can effectively solve problems with billions of dimensions, provided the intrinsic dimensionality is low. They also show that REMBO achieves state-of-the-art performance in optimizing the 47 discrete parameters of a popular mixed integer linear programming solver.
Unbounded Bayesian Optimization via Regularization
Aug 14, 2015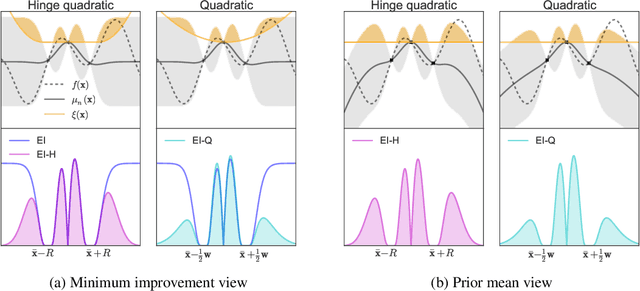
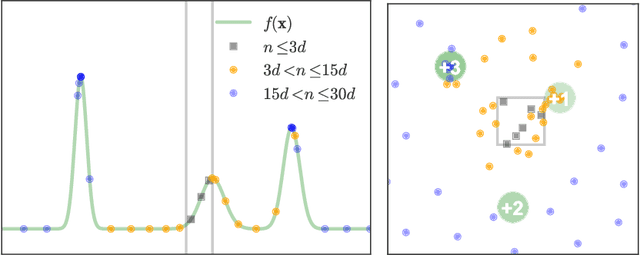
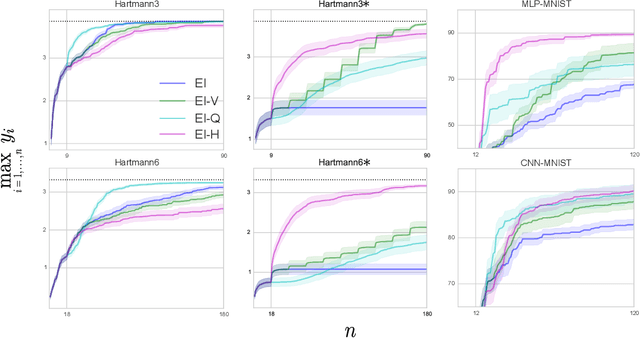
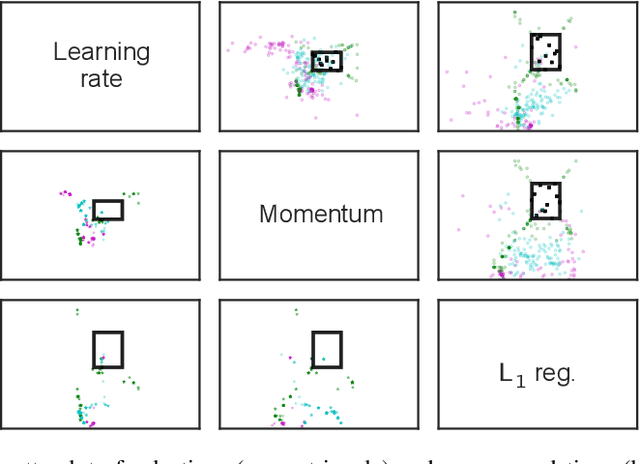
Bayesian optimization has recently emerged as a popular and efficient tool for global optimization and hyperparameter tuning. Currently, the established Bayesian optimization practice requires a user-defined bounding box which is assumed to contain the optimizer. However, when little is known about the probed objective function, it can be difficult to prescribe such bounds. In this work we modify the standard Bayesian optimization framework in a principled way to allow automatic resizing of the search space. We introduce two alternative methods and compare them on two common synthetic benchmarking test functions as well as the tasks of tuning the stochastic gradient descent optimizer of a multi-layered perceptron and a convolutional neural network on MNIST.
Deep Fried Convnets
Jul 17, 2015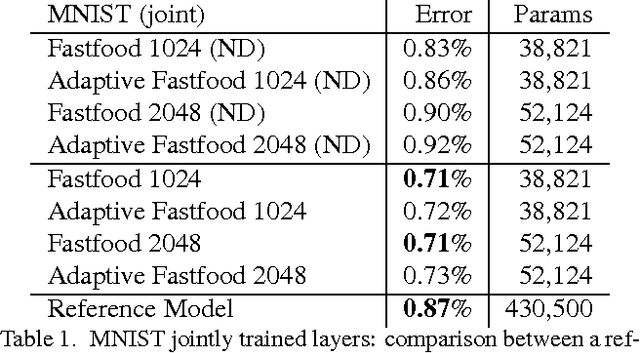
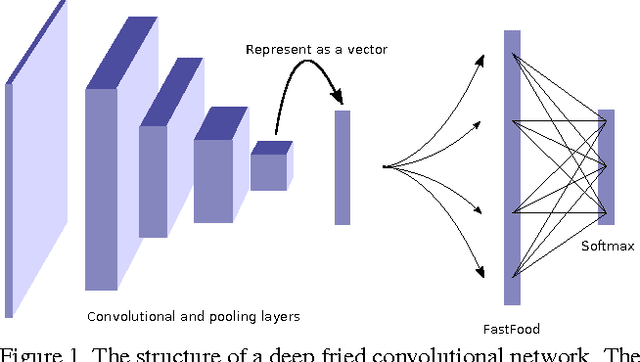
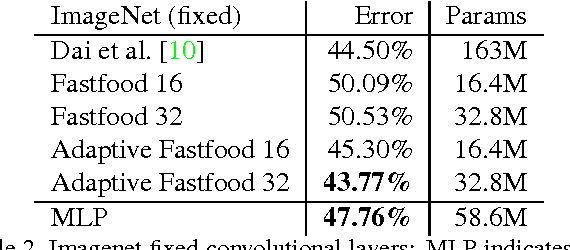
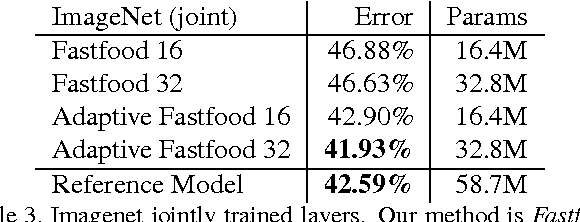
The fully connected layers of a deep convolutional neural network typically contain over 90% of the network parameters, and consume the majority of the memory required to store the network parameters. Reducing the number of parameters while preserving essentially the same predictive performance is critically important for operating deep neural networks in memory constrained environments such as GPUs or embedded devices. In this paper we show how kernel methods, in particular a single Fastfood layer, can be used to replace all fully connected layers in a deep convolutional neural network. This novel Fastfood layer is also end-to-end trainable in conjunction with convolutional layers, allowing us to combine them into a new architecture, named deep fried convolutional networks, which substantially reduces the memory footprint of convolutional networks trained on MNIST and ImageNet with no drop in predictive performance.
An Entropy Search Portfolio for Bayesian Optimization
Mar 04, 2015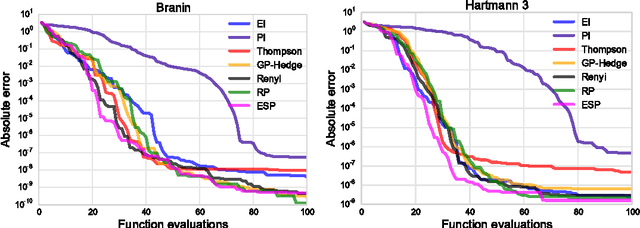
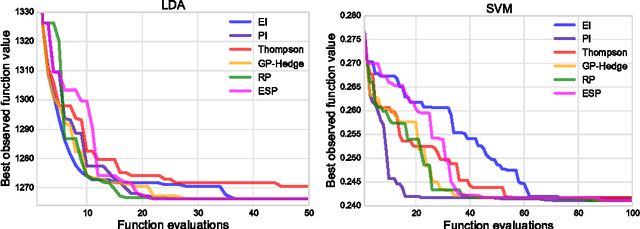
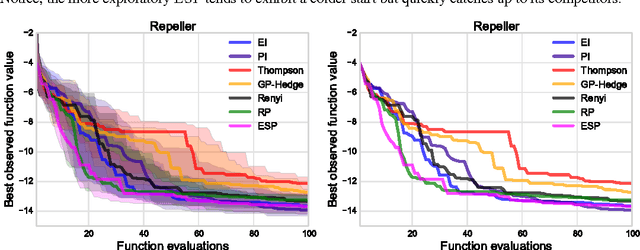
Bayesian optimization is a sample-efficient method for black-box global optimization. How- ever, the performance of a Bayesian optimization method very much depends on its exploration strategy, i.e. the choice of acquisition function, and it is not clear a priori which choice will result in superior performance. While portfolio methods provide an effective, principled way of combining a collection of acquisition functions, they are often based on measures of past performance which can be misleading. To address this issue, we introduce the Entropy Search Portfolio (ESP): a novel approach to portfolio construction which is motivated by information theoretic considerations. We show that ESP outperforms existing portfolio methods on several real and synthetic problems, including geostatistical datasets and simulated control tasks. We not only show that ESP is able to offer performance as good as the best, but unknown, acquisition function, but surprisingly it often gives better performance. Finally, over a wide range of conditions we find that ESP is robust to the inclusion of poor acquisition functions.
Heteroscedastic Treed Bayesian Optimisation
Mar 04, 2015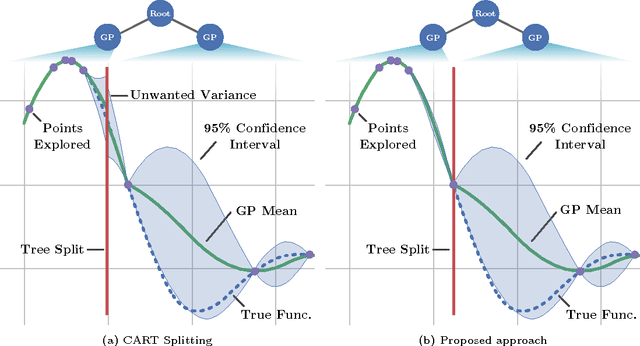
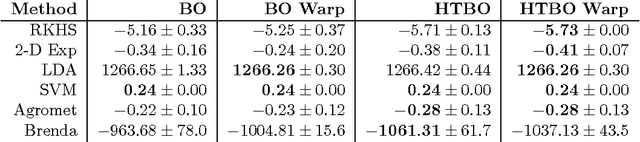
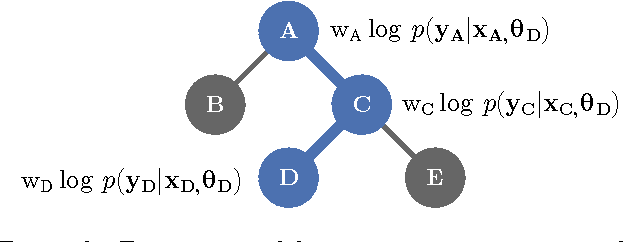
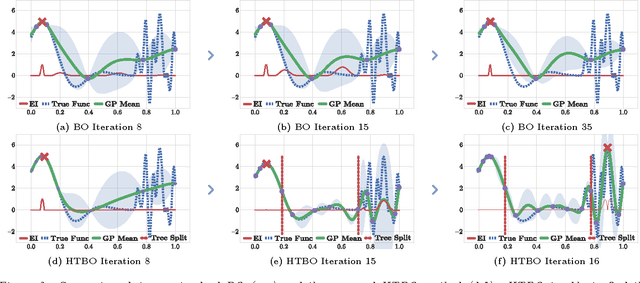
Optimising black-box functions is important in many disciplines, such as tuning machine learning models, robotics, finance and mining exploration. Bayesian optimisation is a state-of-the-art technique for the global optimisation of black-box functions which are expensive to evaluate. At the core of this approach is a Gaussian process prior that captures our belief about the distribution over functions. However, in many cases a single Gaussian process is not flexible enough to capture non-stationarity in the objective function. Consequently, heteroscedasticity negatively affects performance of traditional Bayesian methods. In this paper, we propose a novel prior model with hierarchical parameter learning that tackles the problem of non-stationarity in Bayesian optimisation. Our results demonstrate substantial improvements in a wide range of applications, including automatic machine learning and mining exploration.
Extraction of Salient Sentences from Labelled Documents
Feb 28, 2015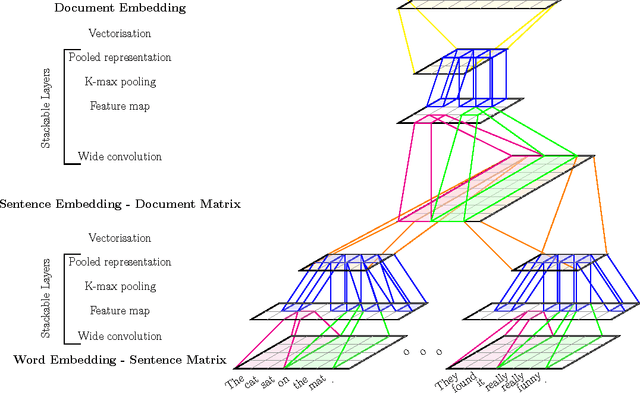
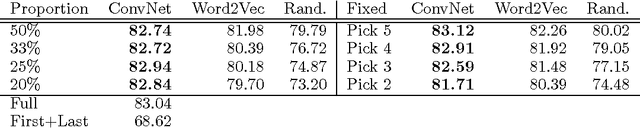
We present a hierarchical convolutional document model with an architecture designed to support introspection of the document structure. Using this model, we show how to use visualisation techniques from the computer vision literature to identify and extract topic-relevant sentences. We also introduce a new scalable evaluation technique for automatic sentence extraction systems that avoids the need for time consuming human annotation of validation data.