 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention that does not Explain Away
Sep 29, 2020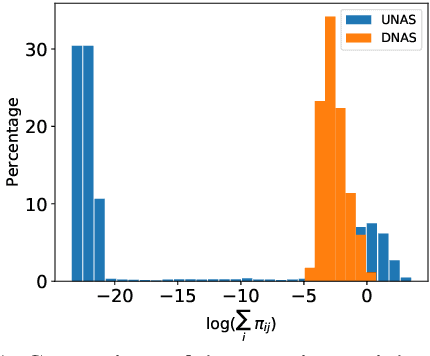

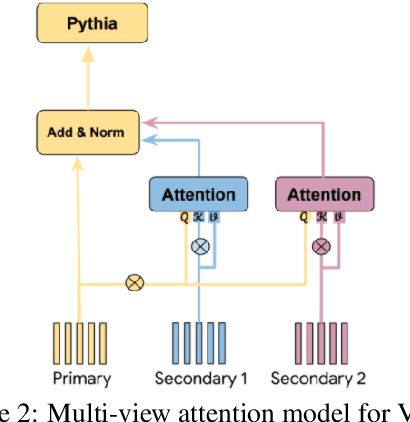

Models based on the Transformer architecture have achieved better accuracy than the ones based on competing architectures for a large set of tasks. A unique feature of the Transformer is its universal application of a self-attention mechanism, which allows for free information flow at arbitrary distances. Following a probabilistic view of the attention via the Gaussian mixture model, we find empirical evidence that the Transformer attention tends to "explain away" certain input neurons. To compensate for this, we propose a doubly-normalized attention scheme that is simple to implement and provides theoretical guarantees for avoiding the "explaining away" effect without introducing significant computational or memory cost. Empirically, we show that the new attention schemes result in improved performance on several well-known benchmarks.
Talking-Heads Attention
Mar 05, 2020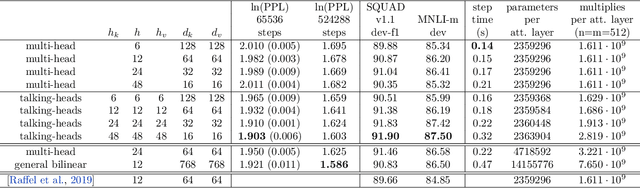
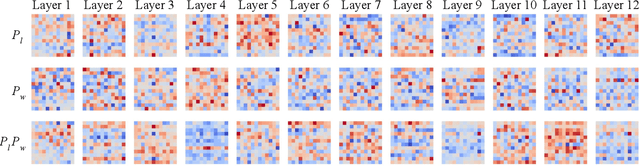


We introduce "talking-heads attention" - a variation on multi-head attention which includes linearprojections across the attention-heads dimension, immediately before and after the softmax operation.While inserting only a small number of additional parameters and a moderate amount of additionalcomputation, talking-heads attention leads to better perplexities on masked language modeling tasks, aswell as better quality when transfer-learning to language comprehension and question answering tasks.
iqiyi Submission to ActivityNet Challenge 2019 Kinetics-700 challenge: Hierarchical Group-wise Attention
Feb 07, 2020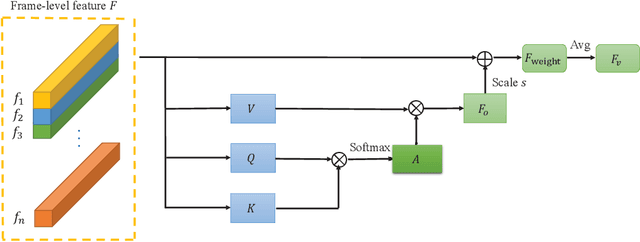

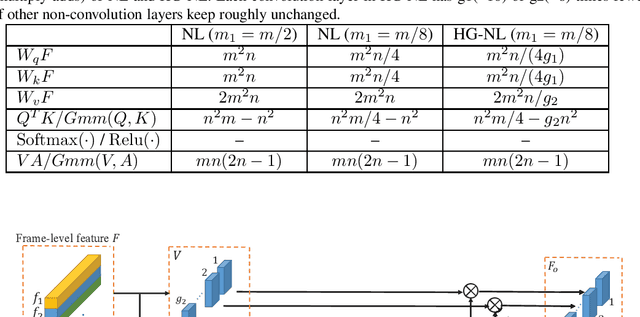
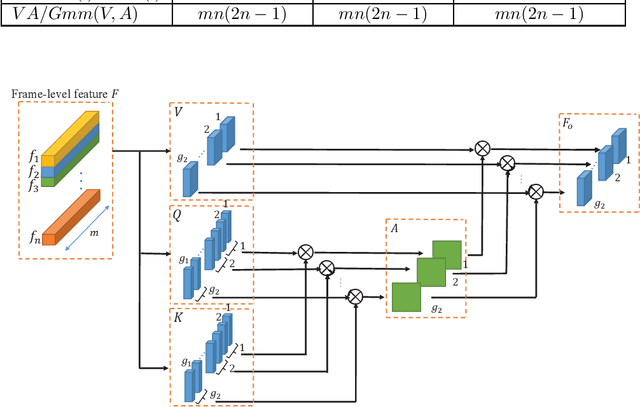
In this report, the method for the iqiyi submission to the task of ActivityNet 2019 Kinetics-700 challenge is described. Three models are involved in the model ensemble stage: TSN, HG-NL and StNet. We propose the hierarchical group-wise non-local (HG-NL) module for frame-level features aggregation for video classification. The standard non-local (NL) module is effective in aggregating frame-level features on the task of video classification but presents low parameters efficiency and high computational cost. The HG-NL method involves a hierarchical group-wise structure and generates multiple attention maps to enhance performance. Basing on this hierarchical group-wise structure, the proposed method has competitive accuracy, fewer parameters and smaller computational cost than the standard NL. For the task of ActivityNet 2019 Kinetics-700 challenge, after model ensemble, we finally obtain an averaged top-1 and top-5 error percentage 28.444% on the test set.
SHAPED: Shared-Private Encoder-Decoder for Text Style Adaptation
Apr 11, 2018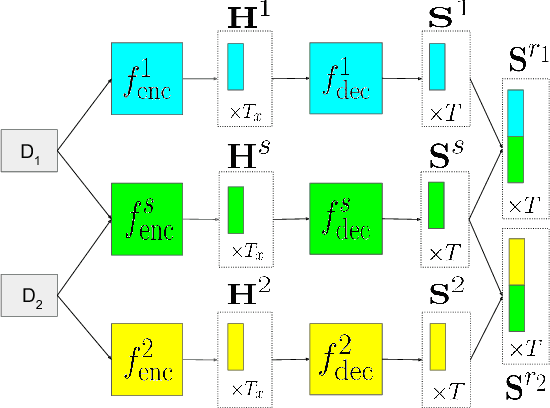
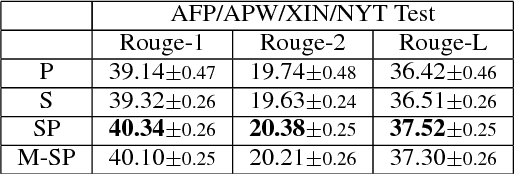
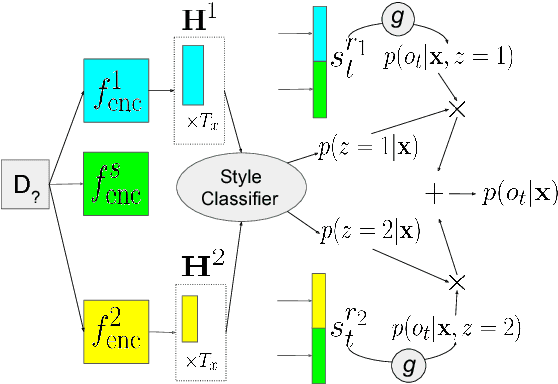

Supervised training of abstractive language generation models results in learning conditional probabilities over language sequences based on the supervised training signal. When the training signal contains a variety of writing styles, such models may end up learning an 'average' style that is directly influenced by the training data make-up and cannot be controlled by the needs of an application. We describe a family of model architectures capable of capturing both generic language characteristics via shared model parameters, as well as particular style characteristics via private model parameters. Such models are able to generate language according to a specific learned style, while still taking advantage of their power to model generic language phenomena. Furthermore, we describe an extension that uses a mixture of output distributions from all learned styles to perform on-the fly style adaptation based on the textual input alone. Experimentally, we find that the proposed models consistently outperform models that encapsulate single-style or average-style language generation capabilities.
Cold-Start Reinforcement Learning with Softmax Policy Gradient
Oct 13, 2017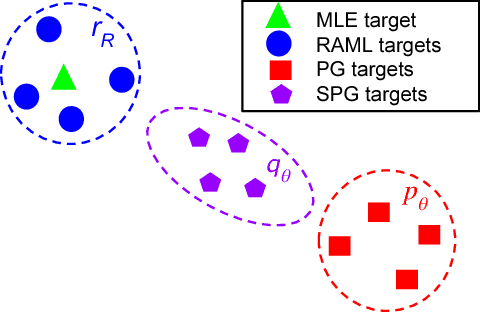

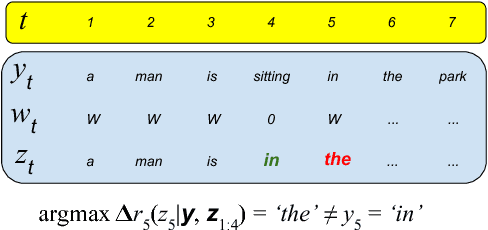

Policy-gradient approaches to reinforcement learning have two common and undesirable overhead procedures, namely warm-start training and sample variance reduction. In this paper, we describe a reinforcement learning method based on a softmax value function that requires neither of these procedures. Our method combines the advantages of policy-gradient methods with the efficiency and simplicity of maximum-likelihood approaches. We apply this new cold-start reinforcement learning method in training sequence generation models for structured output prediction problems. Empirical evidence validates this method on automatic summarization and image captioning tasks.
Understanding Image and Text Simultaneously: a Dual Vision-Language Machine Comprehension Task
Dec 22, 2016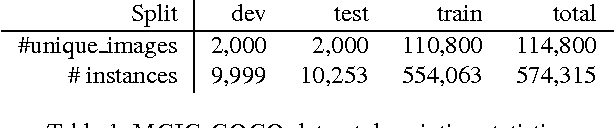

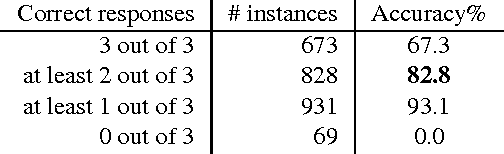

We introduce a new multi-modal task for computer systems, posed as a combined vision-language comprehension challenge: identifying the most suitable text describing a scene, given several similar options. Accomplishing the task entails demonstrating comprehension beyond just recognizing "keywords" (or key-phrases) and their corresponding visual concepts. Instead, it requires an alignment between the representations of the two modalities that achieves a visually-grounded "understanding" of various linguistic elements and their dependencies. This new task also admits an easy-to-compute and well-studied metric: the accuracy in detecting the true target among the decoys. The paper makes several contributions: an effective and extensible mechanism for generating decoys from (human-created) image captions; an instance of applying this mechanism, yielding a large-scale machine comprehension dataset (based on the COCO images and captions) that we make publicly available; human evaluation results on this dataset, informing a performance upper-bound; and several baseline and competitive learning approaches that illustrate the utility of the proposed task and dataset in advancing both image and language comprehension. We also show that, in a multi-task learning setting, the performance on the proposed task is positively correlated with the end-to-end task of image captioning.
Multilingual Word Embeddings using Multigraphs
Dec 14, 2016


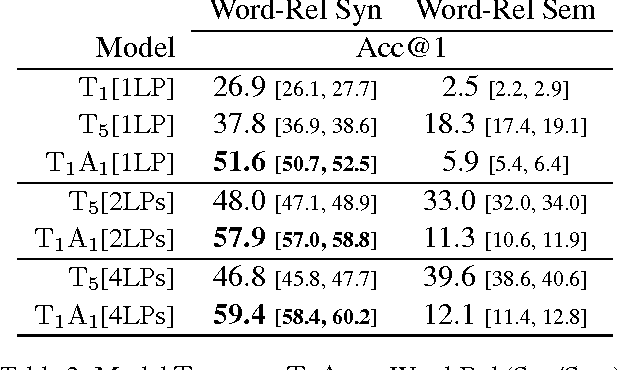
We present a family of neural-network--inspired models for computing continuous word representations, specifically designed to exploit both monolingual and multilingual text. This framework allows us to perform unsupervised training of embeddings that exhibit higher accuracy on syntactic and semantic compositionality, as well as multilingual semantic similarity, compared to previous models trained in an unsupervised fashion. We also show that such multilingual embeddings, optimized for semantic similarity, can improve the performance of statistical machine translation with respect to how it handles words not present in the parallel data.
Building Large Machine Reading-Comprehension Datasets using Paragraph Vectors
Dec 13, 2016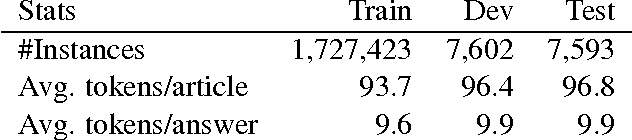
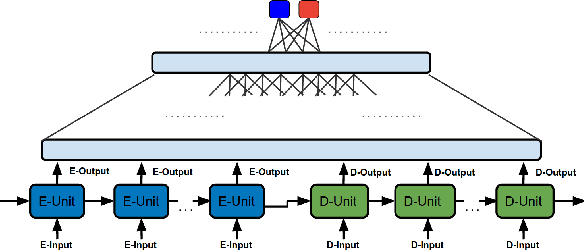


We present a dual contribution to the task of machine reading-comprehension: a technique for creating large-sized machine-comprehension (MC) datasets using paragraph-vector models; and a novel, hybrid neural-network architecture that combines the representation power of recurrent neural networks with the discriminative power of fully-connected multi-layered networks. We use the MC-dataset generation technique to build a dataset of around 2 million examples, for which we empirically determine the high-ceiling of human performance (around 91% accuracy), as well as the performance of a variety of computer models. Among all the models we have experimented with, our hybrid neural-network architecture achieves the highest performance (83.2% accuracy). The remaining gap to the human-performance ceiling provides enough room for future model improvements.
On the Convergence of Stochastic Gradient MCMC Algorithms with High-Order Integrators
Oct 21, 2016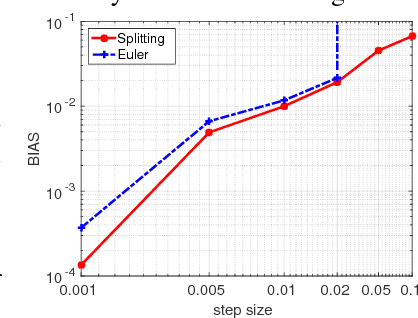
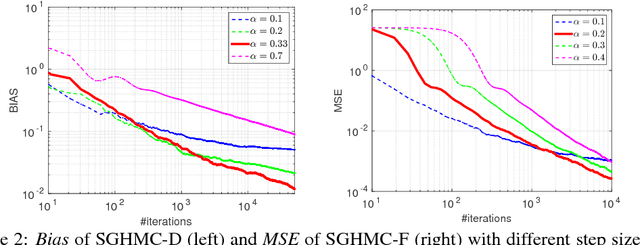
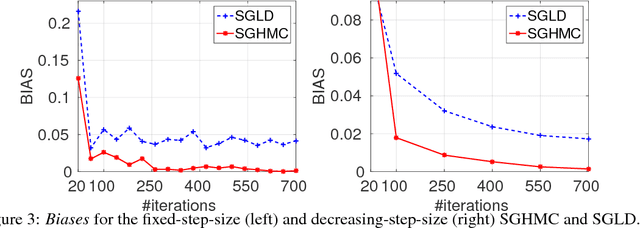
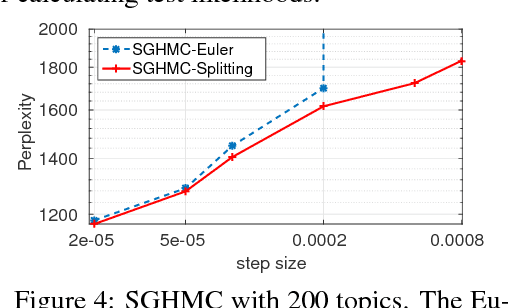
Recent advances in Bayesian learning with large-scale data have witnessed emergence of stochastic gradient MCMC algorithms (SG-MCMC), such as stochastic gradient Langevin dynamics (SGLD), stochastic gradient Hamiltonian MCMC (SGHMC), and the stochastic gradient thermostat. While finite-time convergence properties of the SGLD with a 1st-order Euler integrator have recently been studied, corresponding theory for general SG-MCMCs has not been explored. In this paper we consider general SG-MCMCs with high-order integrators, and develop theory to analyze finite-time convergence properties and their asymptotic invariant measures. Our theoretical results show faster convergence rates and more accurate invariant measures for SG-MCMCs with higher-order integrators. For example, with the proposed efficient 2nd-order symmetric splitting integrator, the {\em mean square error} (MSE) of the posterior average for the SGHMC achieves an optimal convergence rate of $L^{-4/5}$ at $L$ iterations, compared to $L^{-2/3}$ for the SGHMC and SGLD with 1st-order Euler integrators. Furthermore, convergence results of decreasing-step-size SG-MCMCs are also developed, with the same convergence rates as their fixed-step-size counterparts for a specific decreasing sequence. Experiments on both synthetic and real datasets verify our theory, and show advantages of the proposed method in two large-scale real applications.
Stochastic Gradient MCMC with Stale Gradients
Oct 21, 2016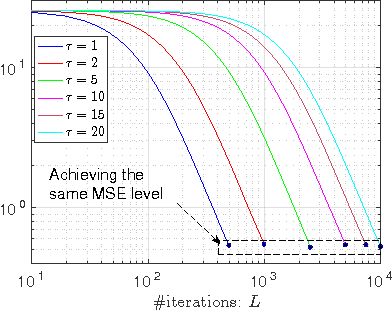
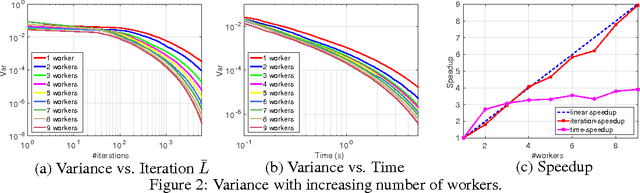
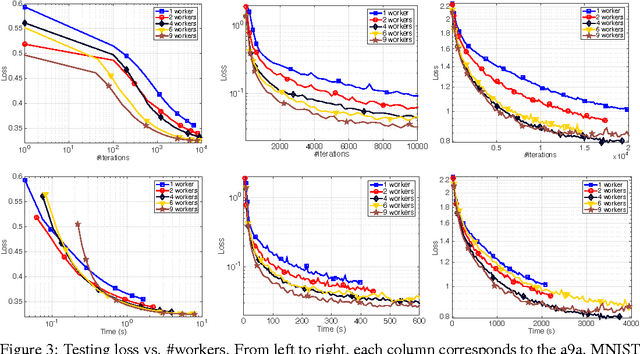
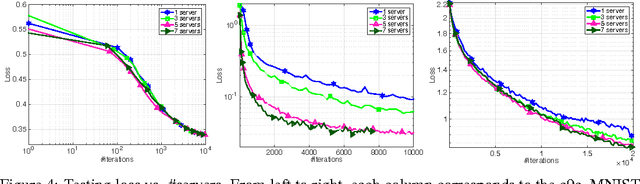
Stochastic gradient MCMC (SG-MCMC) has played an important role in large-scale Bayesian learning, with well-developed theoretical convergence properties. In such applications of SG-MCMC, it is becoming increasingly popular to employ distributed systems, where stochastic gradients are computed based on some outdated parameters, yielding what are termed stale gradients. While stale gradients could be directly used in SG-MCMC, their impact on convergence properties has not been well studied. In this paper we develop theory to show that while the bias and MSE of an SG-MCMC algorithm depend on the staleness of stochastic gradients, its estimation variance (relative to the expected estimate, based on a prescribed number of samples) is independent of it. In a simple Bayesian distributed system with SG-MCMC, where stale gradients are computed asynchronously by a set of workers, our theory indicates a linear speedup on the decrease of estimation variance w.r.t. the number of workers. Experiments on synthetic data and deep neural networks validate our theory, demonstrating the effectiveness and scalability of SG-MCMC with stale gradients.