 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Control with Adversarial Disturbances
Feb 23, 2019We study the control of a linear dynamical system with adversarial disturbances (as opposed to statistical noise). The objective we consider is one of regret: we desire an online control procedure that can do nearly as well as that of a procedure that has full knowledge of the disturbances in hindsight. Our main result is an efficient algorithm that provides nearly tight regret bounds for this problem. From a technical standpoint, this work generalizes upon previous work in two main aspects: our model allows for adversarial noise in the dynamics, and allows for general convex costs.
Extreme Tensoring for Low-Memory Preconditioning
Feb 12, 2019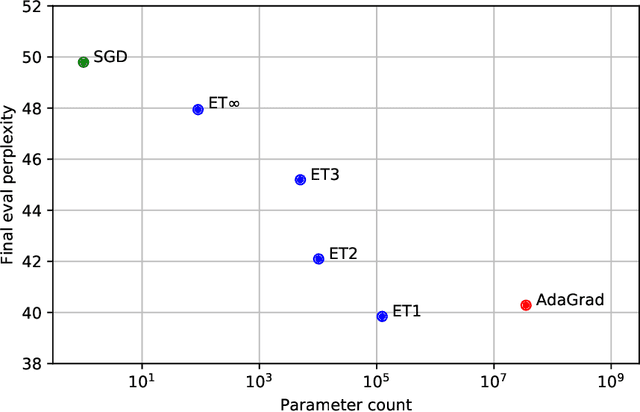
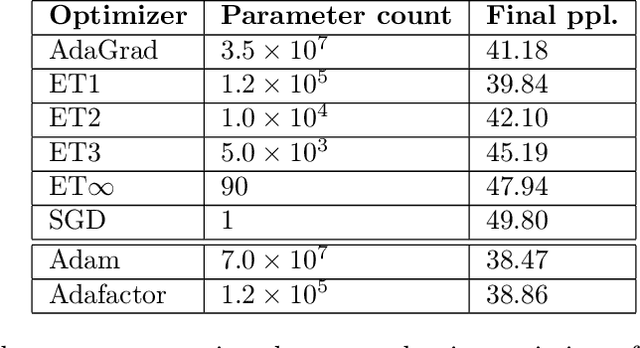

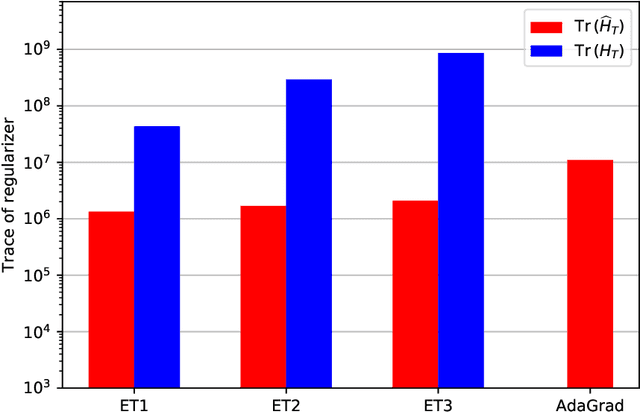
State-of-the-art models are now trained with billions of parameters, reaching hardware limits in terms of memory consumption. This has created a recent demand for memory-efficient optimizers. To this end, we investigate the limits and performance tradeoffs of memory-efficient adaptively preconditioned gradient methods. We propose extreme tensoring for high-dimensional stochastic optimization, showing that an optimizer needs very little memory to benefit from adaptive preconditioning. Our technique applies to arbitrary models (not necessarily with tensor-shaped parameters), and is accompanied by regret and convergence guarantees, which shed light on the tradeoffs between preconditioner quality and expressivity. On a large-scale NLP model, we reduce the optimizer memory overhead by three orders of magnitude, without degrading performance.
Effective Dimension of Exp-concave Optimization
Jun 25, 2018We investigate the role of the effective (a.k.a. statistical) dimension in determining both the statistical and the computational costs associated with exp-concave stochastic minimization. We derive sample complexity bounds that scale with $\frac{d_{\lambda}}{\epsilon}$, where $d_{\lambda}$ is the effective dimension associated with the regularization parameter $\lambda$. These are the first fast rates in this setting that do not exhibit any explicit dependence either on the intrinsic dimension or the $\ell_{2}$-norm of the optimal classifier. We also propose fast preconditioned method that solves the ERM problem in time $\tilde{O} \left(\min \left \{\frac{\lambda'}{\lambda} \left( nnz(A)+d_{\lambda'}^{2}d\right) :~\lambda' \ge \lambda \right \} \right)$, where $nnz(A)$ is the number of nonzero entries in the data. Our analysis emphasizes interesting connections between leverage scores, algorithmic stability and regularization. In particular, our algorithm involves a novel technique for optimizing a tradeoff between oracle complexity and effective dimension. All of our results extend to the kernel setting.
The Case for Full-Matrix Adaptive Regularization
Jun 08, 2018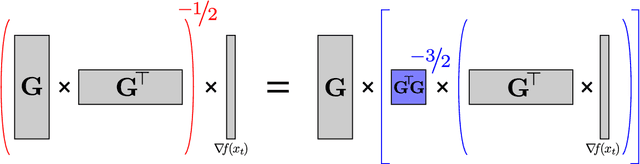
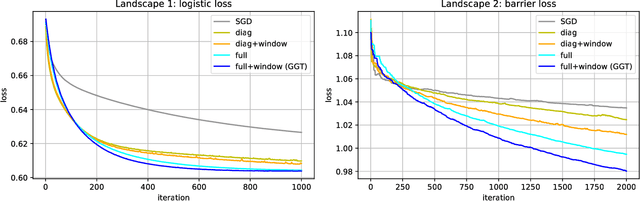
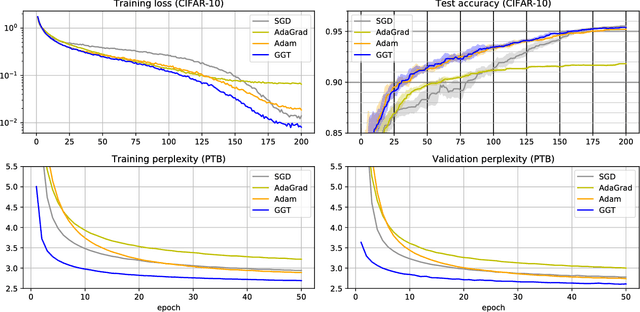
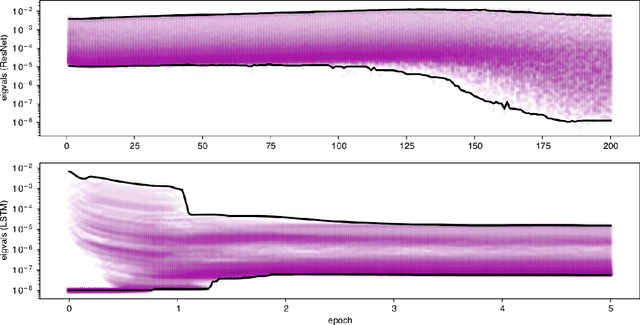
Adaptive regularization methods come in diagonal and full-matrix variants. However, only the former have enjoyed widespread adoption in training large-scale deep models. This is due to the computational overhead of manipulating a full matrix in high dimension. In this paper, we show how to make full-matrix adaptive regularization practical and useful. We present GGT, a truly scalable full-matrix adaptive optimizer. At the heart of our algorithm is an efficient method for computing the inverse square root of a low-rank matrix. We show that GGT converges to first-order local minima, providing the first rigorous theoretical analysis of adaptive regularization in non-convex optimization. In preliminary experiments, GGT trains faster across a variety of synthetic tasks and standard deep learning benchmarks.
cpSGD: Communication-efficient and differentially-private distributed SGD
May 27, 2018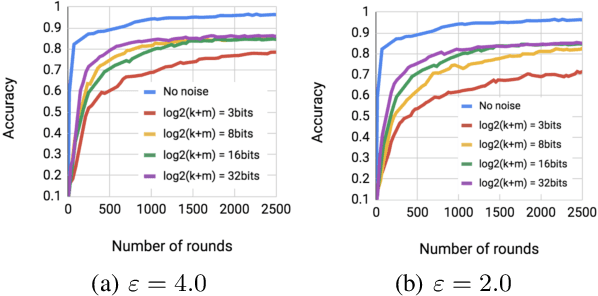
Distributed stochastic gradient descent is an important subroutine in distributed learning. A setting of particular interest is when the clients are mobile devices, where two important concerns are communication efficiency and the privacy of the clients. Several recent works have focused on reducing the communication cost or introducing privacy guarantees, but none of the proposed communication efficient methods are known to be privacy preserving and none of the known privacy mechanisms are known to be communication efficient. To this end, we study algorithms that achieve both communication efficiency and differential privacy. For $d$ variables and $n \approx d$ clients, the proposed method uses $O(\log \log(nd))$ bits of communication per client per coordinate and ensures constant privacy. We also extend and improve previous analysis of the \emph{Binomial mechanism} showing that it achieves nearly the same utility as the Gaussian mechanism, while requiring fewer representation bits, which can be of independent interest.
Second-Order Stochastic Optimization for Machine Learning in Linear Time
Nov 30, 2017
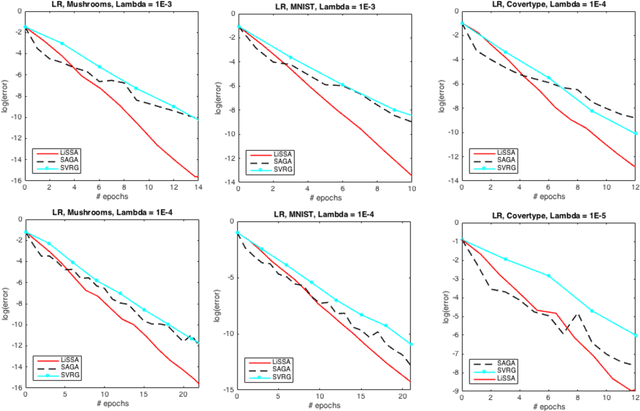

First-order stochastic methods are the state-of-the-art in large-scale machine learning optimization owing to efficient per-iteration complexity. Second-order methods, while able to provide faster convergence, have been much less explored due to the high cost of computing the second-order information. In this paper we develop second-order stochastic methods for optimization problems in machine learning that match the per-iteration cost of gradient based methods, and in certain settings improve upon the overall running time over popular first-order methods. Furthermore, our algorithm has the desirable property of being implementable in time linear in the sparsity of the input data.
Leverage Score Sampling for Faster Accelerated Regression and ERM
Nov 22, 2017Given a matrix $\mathbf{A}\in\mathbb{R}^{n\times d}$ and a vector $b \in\mathbb{R}^{d}$, we show how to compute an $\epsilon$-approximate solution to the regression problem $ \min_{x\in\mathbb{R}^{d}}\frac{1}{2} \|\mathbf{A} x - b\|_{2}^{2} $ in time $ \tilde{O} ((n+\sqrt{d\cdot\kappa_{\text{sum}}})\cdot s\cdot\log\epsilon^{-1}) $ where $\kappa_{\text{sum}}=\mathrm{tr}\left(\mathbf{A}^{\top}\mathbf{A}\right)/\lambda_{\min}(\mathbf{A}^{T}\mathbf{A})$ and $s$ is the maximum number of non-zero entries in a row of $\mathbf{A}$. Our algorithm improves upon the previous best running time of $ \tilde{O} ((n+\sqrt{n \cdot\kappa_{\text{sum}}})\cdot s\cdot\log\epsilon^{-1})$. We achieve our result through a careful combination of leverage score sampling techniques, proximal point methods, and accelerated coordinate descent. Our method not only matches the performance of previous methods, but further improves whenever leverage scores of rows are small (up to polylogarithmic factors). We also provide a non-linear generalization of these results that improves the running time for solving a broader class of ERM problems.
Lower Bounds for Higher-Order Convex Optimization
Oct 27, 2017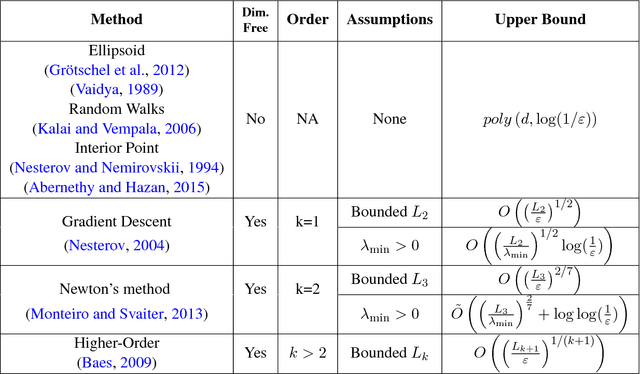

State-of-the-art methods in convex and non-convex optimization employ higher-order derivative information, either implicitly or explicitly. We explore the limitations of higher-order optimization and prove that even for convex optimization, a polynomial dependence on the approximation guarantee and higher-order smoothness parameters is necessary. As a special case, we show Nesterov's accelerated cubic regularization method to be nearly tight.
The Price of Differential Privacy For Online Learning
Jun 13, 2017

We design differentially private algorithms for the problem of online linear optimization in the full information and bandit settings with optimal $\tilde{O}(\sqrt{T})$ regret bounds. In the full-information setting, our results demonstrate that $\epsilon$-differential privacy may be ensured for free -- in particular, the regret bounds scale as $O(\sqrt{T})+\tilde{O}\left(\frac{1}{\epsilon}\right)$. For bandit linear optimization, and as a special case, for non-stochastic multi-armed bandits, the proposed algorithm achieves a regret of $\tilde{O}\left(\frac{1}{\epsilon}\sqrt{T}\right)$, while the previously known best regret bound was $\tilde{O}\left(\frac{1}{\epsilon}T^{\frac{2}{3}}\right)$.
Finding Approximate Local Minima Faster than Gradient Descent
Apr 24, 2017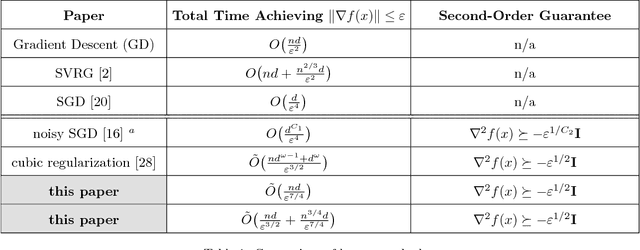
We design a non-convex second-order optimization algorithm that is guaranteed to return an approximate local minimum in time which scales linearly in the underlying dimension and the number of training examples. The time complexity of our algorithm to find an approximate local minimum is even faster than that of gradient descent to find a critical point. Our algorithm applies to a general class of optimization problems including training a neural network and other non-convex objectives arising in machine learning.