 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-FiLM: Conditioning GANs with self-supervised representations for bandwidth extension based speaker recognition
Mar 07, 2023



Speech super-resolution/Bandwidth Extension (BWE) can improve downstream tasks like Automatic Speaker Verification (ASV). We introduce a simple novel technique called Self-FiLM to inject self-supervision into existing BWE models via Feature-wise Linear Modulation. We hypothesize that such information captures domain/environment information, which can give zero-shot generalization. Self-FiLM Conditional GAN (CGAN) gives 18% relative improvement in Equal Error Rate and 8.5% in minimum Decision Cost Function using state-of-the-art ASV system on SRE21 test. We further by 1) deep feature loss from time-domain models and 2) re-training of data2vec 2.0 models on naturalistic wideband (VoxCeleb) and telephone data (SRE Superset etc.). Lastly, we integrate self-supervision with CycleGAN to present a completely unsupervised solution that matches the semi-supervised performance.
Time-domain speech super-resolution with GAN based modeling for telephony speaker verification
Sep 04, 2022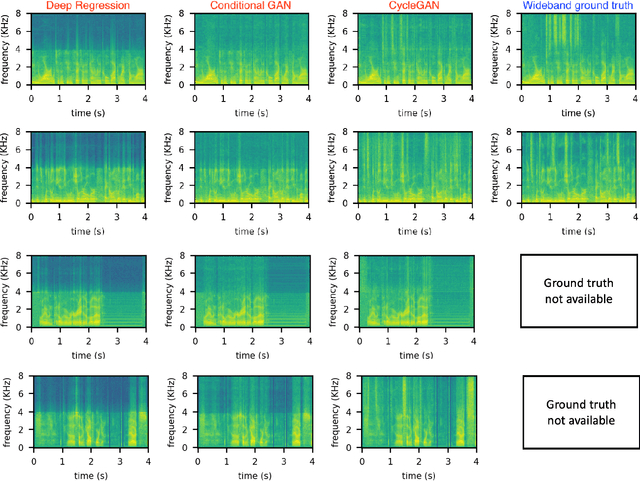
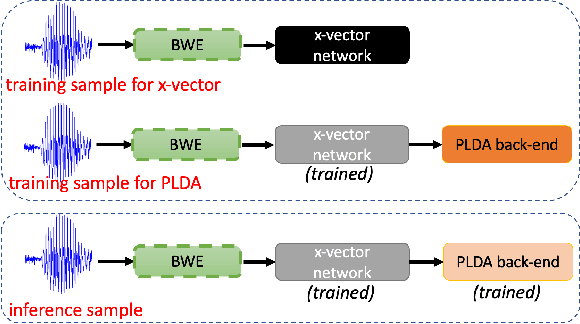
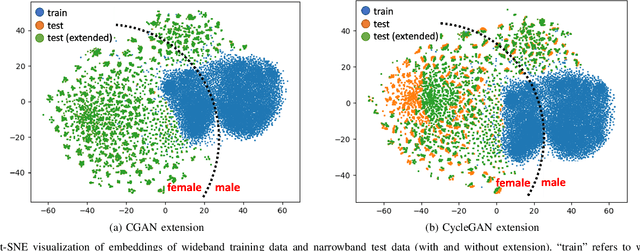
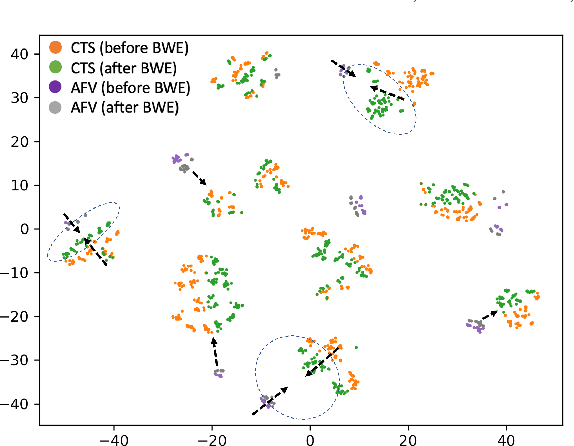
Automatic Speaker Verification (ASV) technology has become commonplace in virtual assistants. However, its performance suffers when there is a mismatch between the train and test domains. Mixed bandwidth training, i.e., pooling training data from both domains, is a preferred choice for developing a universal model that works for both narrowband and wideband domains. We propose complementing this technique by performing neural upsampling of narrowband signals, also known as bandwidth extension. Our main goal is to discover and analyze high-performing time-domain Generative Adversarial Network (GAN) based models to improve our downstream state-of-the-art ASV system. We choose GANs since they (1) are powerful for learning conditional distribution and (2) allow flexible plug-in usage as a pre-processor during the training of downstream task (ASV) with data augmentation. Prior works mainly focus on feature-domain bandwidth extension and limited experimental setups. We address these limitations by 1) using time-domain extension models, 2) reporting results on three real test sets, 2) extending training data, and 3) devising new test-time schemes. We compare supervised (conditional GAN) and unsupervised GANs (CycleGAN) and demonstrate average relative improvement in Equal Error Rate of 8.6% and 7.7%, respectively. For further analysis, we study changes in spectrogram visual quality, audio perceptual quality, t-SNE embeddings, and ASV score distributions. We show that our bandwidth extension leads to phenomena such as a shift of telephone (test) embeddings towards wideband (train) signals, a negative correlation of perceptual quality with downstream performance, and condition-independent score calibration.
Non-Contrastive Self-supervised Learning for Utterance-Level Information Extraction from Speech
Aug 10, 2022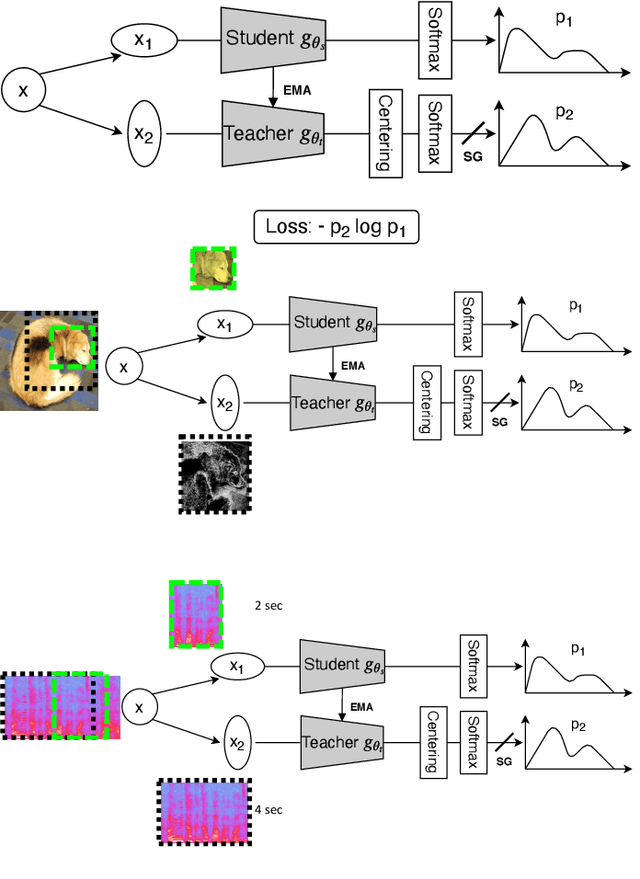
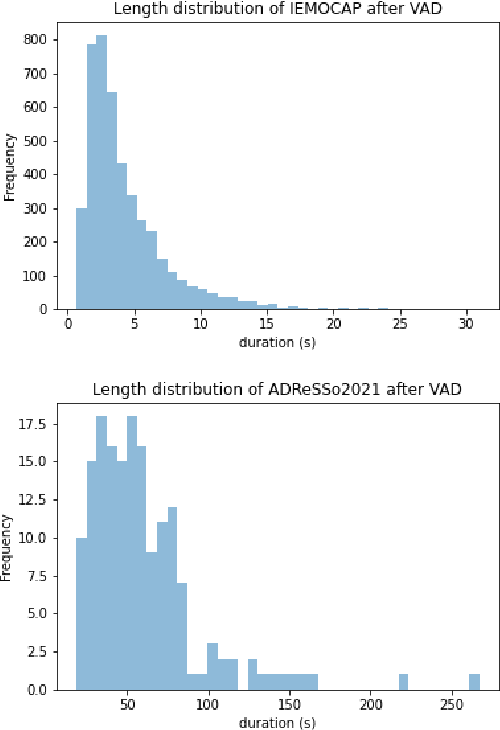
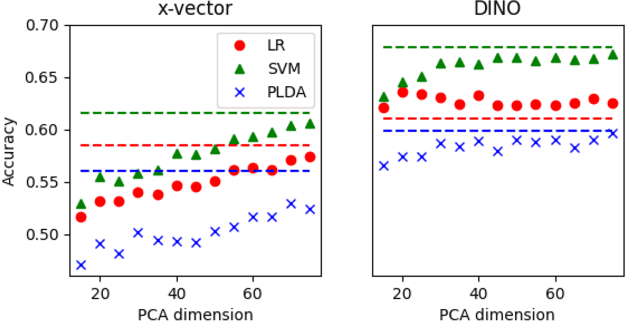
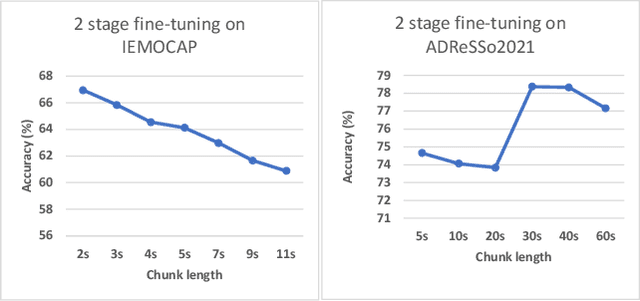
In recent studies, self-supervised pre-trained models tend to outperform supervised pre-trained models in transfer learning. In particular, self-supervised learning (SSL) of utterance-level speech representation can be used in speech applications that require discriminative representation of consistent attributes within an utterance: speaker, language, emotion, and age. Existing frame-level self-supervised speech representation, e.g., wav2vec, can be used as utterance-level representation with pooling, but the models are usually large. There are also SSL techniques to learn utterance-level representation. One of the most successful is a contrastive method, which requires negative sampling: selecting alternative samples to contrast with the current sample (anchor). However, this does not ensure that all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised method to learn utterance-level embeddings. We adapted DIstillation with NO labels (DINO) from computer vision to speech. Unlike contrastive methods, DINO does not require negative sampling. We compared DINO to x-vector trained in a supervised manner. When transferred to down-stream tasks (speaker verification, speech emotion recognition (SER), and Alzheimer's disease detection), DINO outperformed x-vector. We studied the influence of several aspects during transfer learning such as dividing the fine-tuning process into steps, chunk lengths, or augmentation. During fine-tuning, tuning the last affine layers first and then the whole network surpassed fine-tuning all at once. Using shorter chunk lengths, although they generate more diverse inputs, did not necessarily improve performance, implying speech segments at least with a specific length are required for better performance per application. Augmentation was helpful in SER.
Non-Contrastive Self-Supervised Learning of Utterance-Level Speech Representations
Aug 10, 2022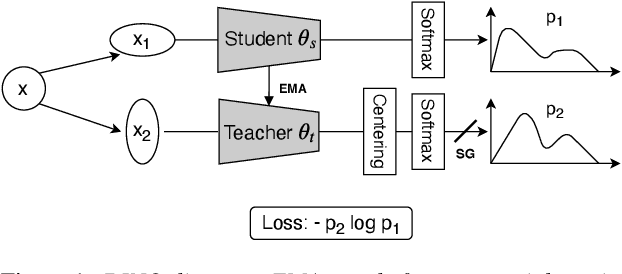
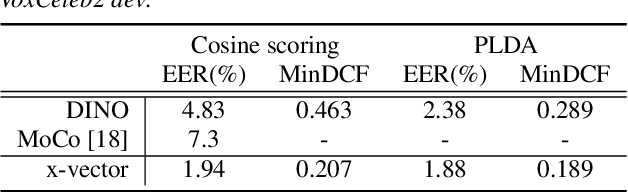
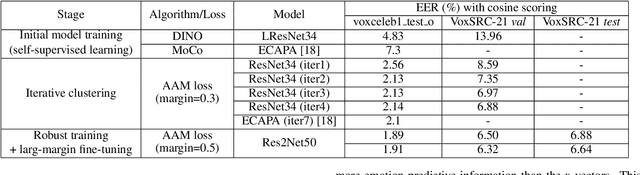
Considering the abundance of unlabeled speech data and the high labeling costs, unsupervised learning methods can be essential for better system development. One of the most successful methods is contrastive self-supervised methods, which require negative sampling: sampling alternative samples to contrast with the current sample (anchor). However, it is hard to ensure if all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised learning method on an unlabeled speech corpus to learn utterance-level embeddings. We used DIstillation with NO labels (DINO), proposed in computer vision, and adapted it to the speech domain. Unlike the contrastive methods, DINO does not require negative sampling. These embeddings were evaluated on speaker verification and emotion recognition. In speaker verification, the unsupervised DINO embedding with cosine scoring provided 4.38% EER on the VoxCeleb1 test trial. This outperforms the best contrastive self-supervised method by 40% relative in EER. An iterative pseudo-labeling training pipeline, not requiring speaker labels, further improved the EER to 1.89%. In emotion recognition, the DINO embedding performed 60.87, 79.21, and 56.98% in micro-f1 score on IEMOCAP, Crema-D, and MSP-Podcast, respectively. The results imply the generality of the DINO embedding to different speech applications.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
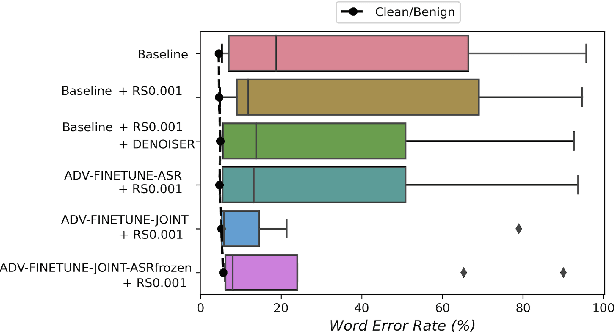

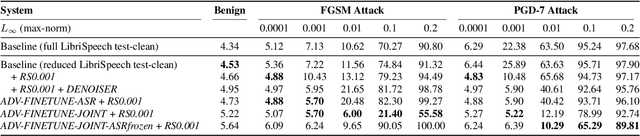
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
AdvEst: Adversarial Perturbation Estimation to Classify and Detect Adversarial Attacks against Speaker Identification
Apr 08, 2022
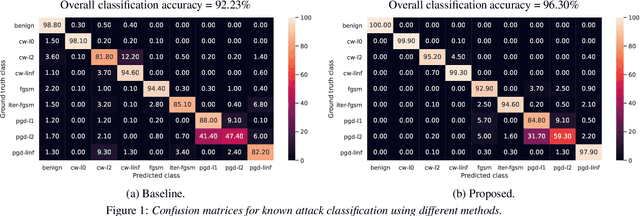

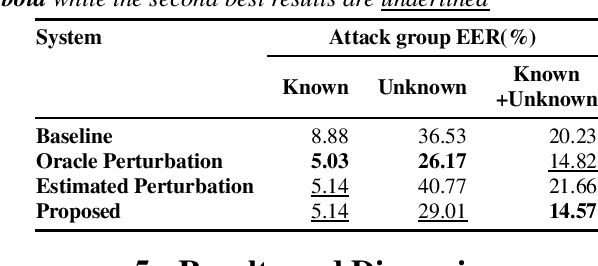
Adversarial attacks pose a severe security threat to the state-of-the-art speaker identification systems, thereby making it vital to propose countermeasures against them. Building on our previous work that used representation learning to classify and detect adversarial attacks, we propose an improvement to it using AdvEst, a method to estimate adversarial perturbation. First, we prove our claim that training the representation learning network using adversarial perturbations as opposed to adversarial examples (consisting of the combination of clean signal and adversarial perturbation) is beneficial because it eliminates nuisance information. At inference time, we use a time-domain denoiser to estimate the adversarial perturbations from adversarial examples. Using our improved representation learning approach to obtain attack embeddings (signatures), we evaluate their performance for three applications: known attack classification, attack verification, and unknown attack detection. We show that common attacks in the literature (Fast Gradient Sign Method (FGSM), Projected Gradient Descent (PGD), Carlini-Wagner (CW) with different Lp threat models) can be classified with an accuracy of ~96%. We also detect unknown attacks with an equal error rate (EER) of ~9%, which is absolute improvement of ~12% from our previous work.
Joint domain adaptation and speech bandwidth extension using time-domain GANs for speaker verification
Mar 30, 2022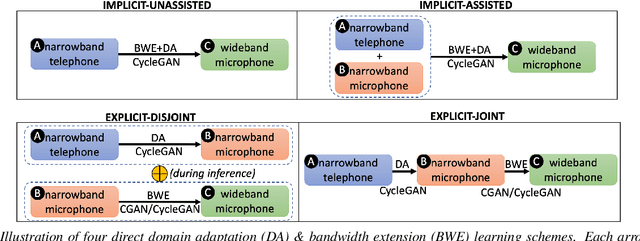
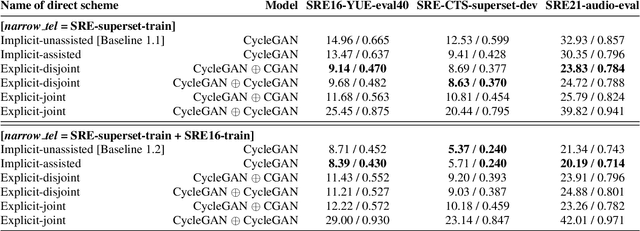
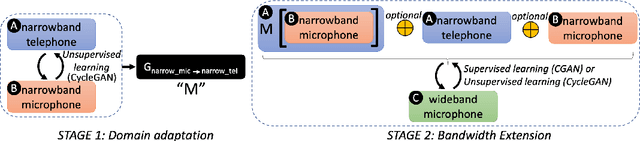

Speech systems developed for a particular choice of acoustic domain and sampling frequency do not translate easily to others. The usual practice is to learn domain adaptation and bandwidth extension models independently. Contrary to this, we propose to learn both tasks together. Particularly, we learn to map narrowband conversational telephone speech to wideband microphone speech. We developed parallel and non-parallel learning solutions which utilize both paired and unpaired data. First, we first discuss joint and disjoint training of multiple generative models for our tasks. Then, we propose a two-stage learning solution where we use a pre-trained domain adaptation system for pre-processing in bandwidth extension training. We evaluated our schemes on a Speaker Verification downstream task. We used the JHU-MIT experimental setup for NIST SRE21, which comprises SRE16, SRE-CTS Superset and SRE21. Our results provide the first evidence that learning both tasks is better than learning just one. On SRE16, our best system achieves 22% relative improvement in Equal Error Rate w.r.t. a direct learning baseline and 8% w.r.t. a strong bandwidth expansion system.
Discovering Phonetic Inventories with Crosslingual Automatic Speech Recognition
Jan 28, 2022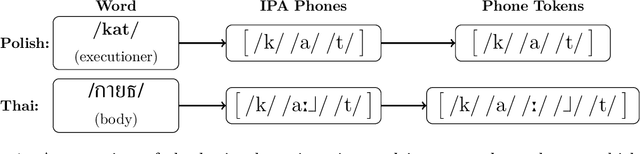
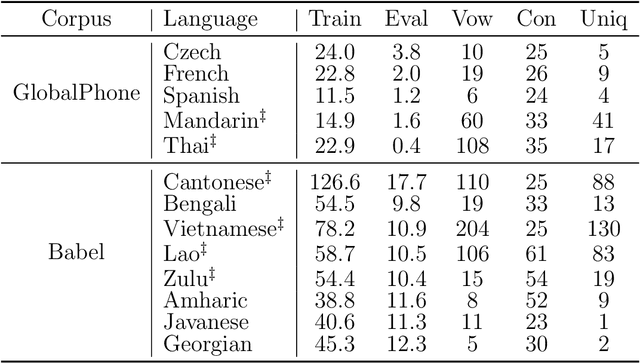
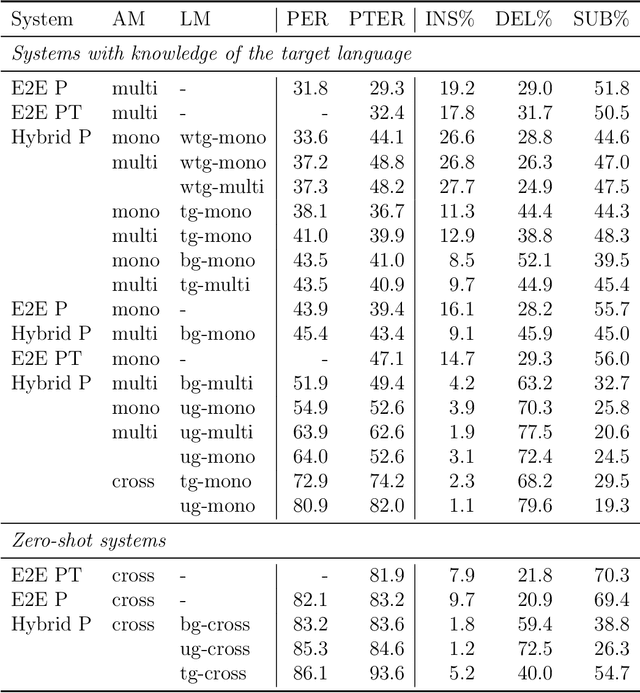
The high cost of data acquisition makes Automatic Speech Recognition (ASR) model training problematic for most existing languages, including languages that do not even have a written script, or for which the phone inventories remain unknown. Past works explored multilingual training, transfer learning, as well as zero-shot learning in order to build ASR systems for these low-resource languages. While it has been shown that the pooling of resources from multiple languages is helpful, we have not yet seen a successful application of an ASR model to a language unseen during training. A crucial step in the adaptation of ASR from seen to unseen languages is the creation of the phone inventory of the unseen language. The ultimate goal of our work is to build the phone inventory of a language unseen during training in an unsupervised way without any knowledge about the language. In this paper, we 1) investigate the influence of different factors (i.e., model architecture, phonotactic model, type of speech representation) on phone recognition in an unknown language; 2) provide an analysis of which phones transfer well across languages and which do not in order to understand the limitations of and areas for further improvement for automatic phone inventory creation; and 3) present different methods to build a phone inventory of an unseen language in an unsupervised way. To that end, we conducted mono-, multi-, and crosslingual experiments on a set of 13 phonetically diverse languages and several in-depth analyses. We found a number of universal phone tokens (IPA symbols) that are well-recognized cross-linguistically. Through a detailed analysis of results, we conclude that unique sounds, similar sounds, and tone languages remain a major challenge for phonetic inventory discovery.
Code-Switching Text Augmentation for Multilingual Speech Processing
Jan 07, 2022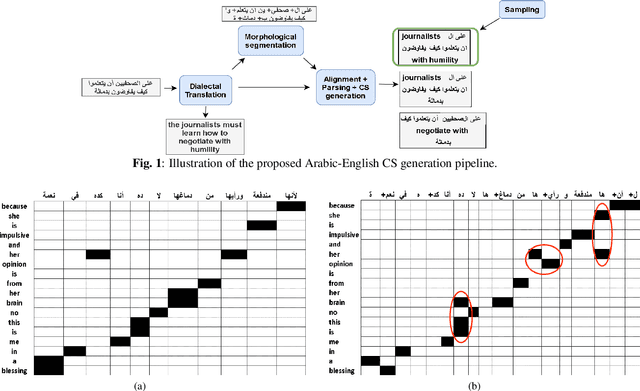
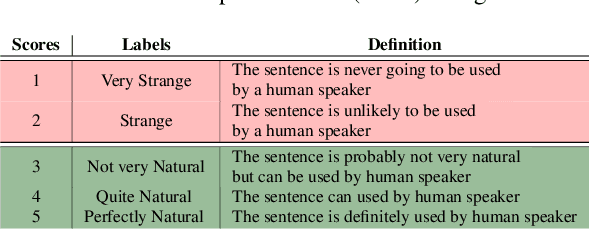
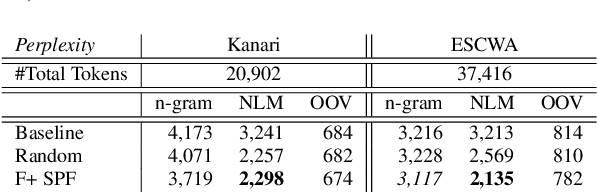
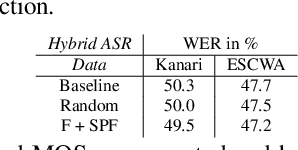
The pervasiveness of intra-utterance Code-switching (CS) in spoken content has enforced ASR systems to handle mixed input. Yet, designing a CS-ASR has many challenges, mainly due to the data scarcity, grammatical structure complexity, and mismatch along with unbalanced language usage distribution. Recent ASR studies showed the predominance of E2E-ASR using multilingual data to handle CS phenomena with little CS data. However, the dependency on the CS data still remains. In this work, we propose a methodology to augment the monolingual data for artificially generating spoken CS text to improve different speech modules. We based our approach on Equivalence Constraint theory while exploiting aligned translation pairs, to generate grammatically valid CS content. Our empirical results show a relative gain of 29-34 % in perplexity and around 2% in WER for two ecological and noisy CS test sets. Finally, the human evaluation suggests that 83.8% of the generated data is acceptable to humans.
Unsupervised Speech Segmentation and Variable Rate Representation Learning using Segmental Contrastive Predictive Coding
Oct 08, 2021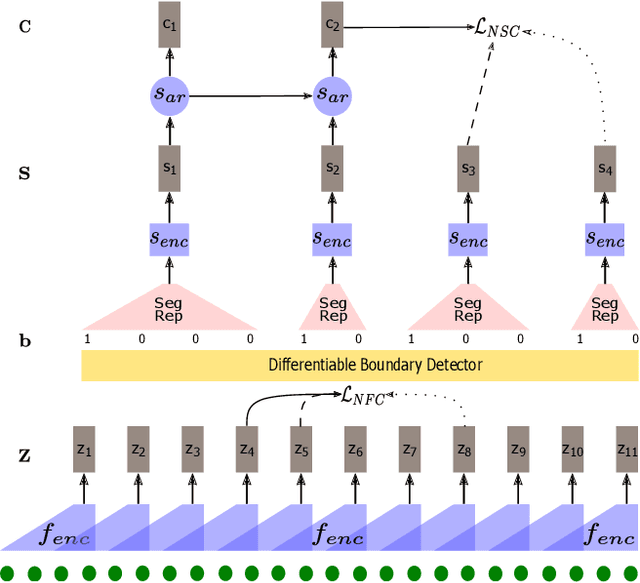
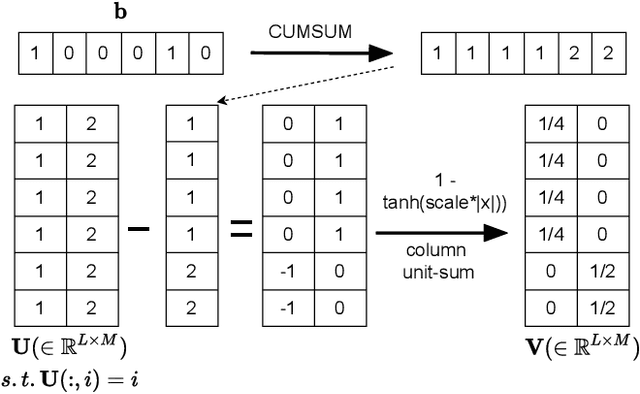
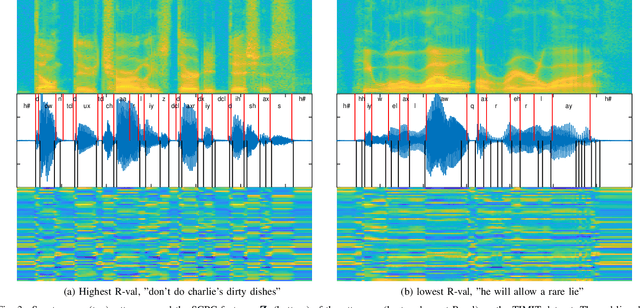
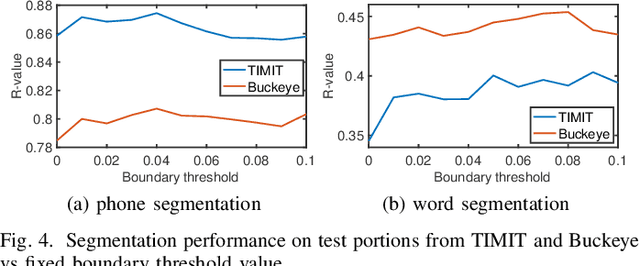
Typically, unsupervised segmentation of speech into the phone and word-like units are treated as separate tasks and are often done via different methods which do not fully leverage the inter-dependence of the two tasks. Here, we unify them and propose a technique that can jointly perform both, showing that these two tasks indeed benefit from each other. Recent attempts employ self-supervised learning, such as contrastive predictive coding (CPC), where the next frame is predicted given past context. However, CPC only looks at the audio signal's frame-level structure. We overcome this limitation with a segmental contrastive predictive coding (SCPC) framework to model the signal structure at a higher level, e.g., phone level. A convolutional neural network learns frame-level representation from the raw waveform via noise-contrastive estimation (NCE). A differentiable boundary detector finds variable-length segments, which are then used to optimize a segment encoder via NCE to learn segment representations. The differentiable boundary detector allows us to train frame-level and segment-level encoders jointly. Experiments show that our single model outperforms existing phone and word segmentation methods on TIMIT and Buckeye datasets. We discover that phone class impacts the boundary detection performance, and the boundaries between successive vowels or semivowels are the most difficult to identify. Finally, we use SCPC to extract speech features at the segment level rather than at uniformly spaced frame level (e.g., 10 ms) and produce variable rate representations that change according to the contents of the utterance. We can lower the feature extraction rate from the typical 100 Hz to as low as 14.5 Hz on average while still outperforming the MFCC features on the linear phone classification task.