 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical Teaching in Cooperative Multiagent Reinforcement Learning
Mar 07, 2019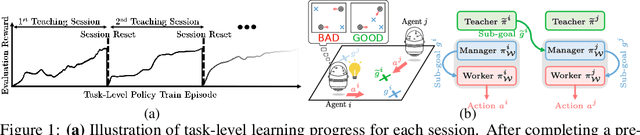
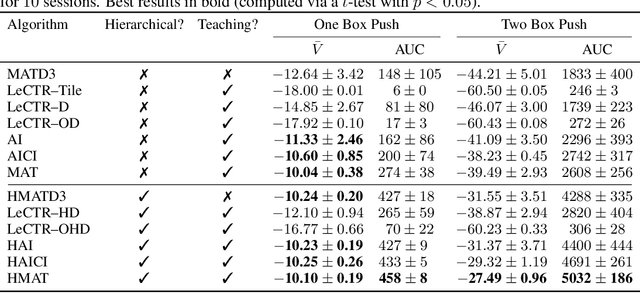
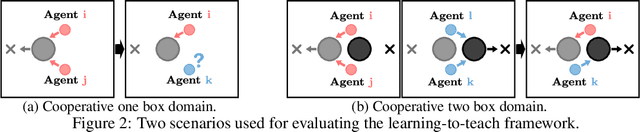

Heterogeneous knowledge naturally arises among different agents in cooperative multiagent reinforcement learning. As such, learning can be greatly improved if agents can effectively pass their knowledge on to other agents. Existing work has demonstrated that peer-to-peer knowledge transfer, a process referred to as action advising, improves team-wide learning. In contrast to previous frameworks that advise at the level of primitive actions, we aim to learn high-level teaching policies that decide when and what high-level action (e.g., sub-goal) to advise a teammate. We introduce a new learning to teach framework, called hierarchical multiagent teaching (HMAT). The proposed framework solves difficulties faced by prior work on multiagent teaching when operating in domains with long horizons, delayed rewards, and continuous states/actions by leveraging temporal abstraction and deep function approximation. Our empirical evaluations show that HMAT accelerates team-wide learning progress in difficult environments that are more complex than those explored in previous work. HMAT also learns teaching policies that can be transferred to different teammates/tasks and can even teach teammates with heterogeneous action spaces.
TED: Teaching AI to Explain its Decisions
Nov 12, 2018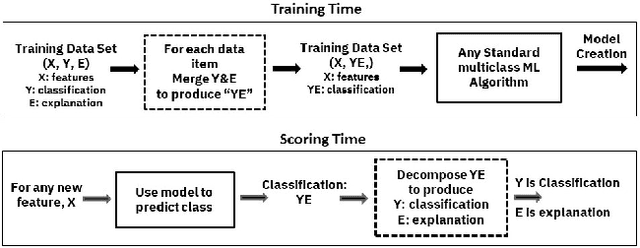
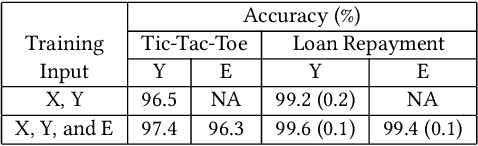

Artificial intelligence systems are being increasingly deployed due to their potential to increase the efficiency, scale, consistency, fairness, and accuracy of decisions. However, as many of these systems are opaque in their operation, there is a growing demand for such systems to provide explanations for their decisions. Conventional approaches to this problem attempt to expose or discover the inner workings of a machine learning model with the hope that the resulting explanations will be meaningful to the consumer. In contrast, this paper suggests a new approach to this problem. It introduces a simple, practical framework, called Teaching Explanations for Decisions (TED), that provides meaningful explanations that match the mental model of the consumer. We illustrate the generality and effectiveness of this approach with two different examples, resulting in highly accurate explanations with no loss of prediction accuracy for these two examples.
Interpretable Multi-Objective Reinforcement Learning through Policy Orchestration
Sep 21, 2018
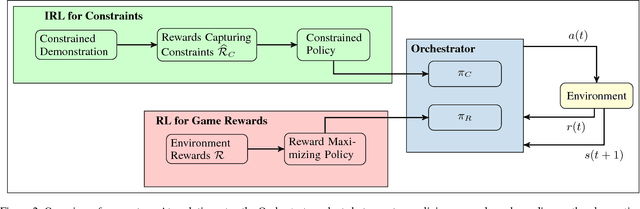
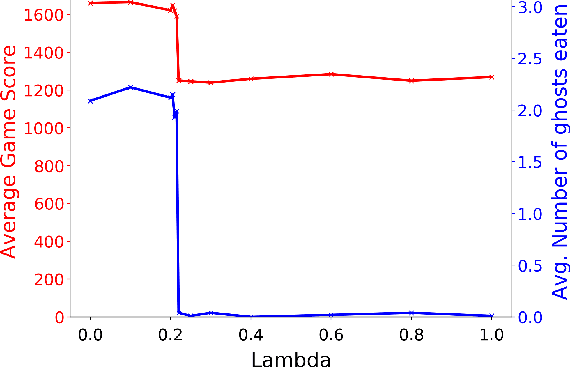
Autonomous cyber-physical agents and systems play an increasingly large role in our lives. To ensure that agents behave in ways aligned with the values of the societies in which they operate, we must develop techniques that allow these agents to not only maximize their reward in an environment, but also to learn and follow the implicit constraints of society. These constraints and norms can come from any number of sources including regulations, business process guidelines, laws, ethical principles, social norms, and moral values. We detail a novel approach that uses inverse reinforcement learning to learn a set of unspecified constraints from demonstrations of the task, and reinforcement learning to learn to maximize the environment rewards. More precisely, we assume that an agent can observe traces of behavior of members of the society but has no access to the explicit set of constraints that give rise to the observed behavior. Inverse reinforcement learning is used to learn such constraints, that are then combined with a possibly orthogonal value function through the use of a contextual bandit-based orchestrator that picks a contextually-appropriate choice between the two policies (constraint-based and environment reward-based) when taking actions. The contextual bandit orchestrator allows the agent to mix policies in novel ways, taking the best actions from either a reward maximizing or constrained policy. In addition, the orchestrator is transparent on which policy is being employed at each time step. We test our algorithms using a Pac-Man domain and show that the agent is able to learn to act optimally, act within the demonstrated constraints, and mix these two functions in complex ways.
Teaching Meaningful Explanations
Sep 11, 2018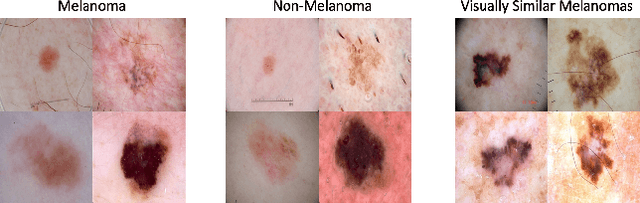
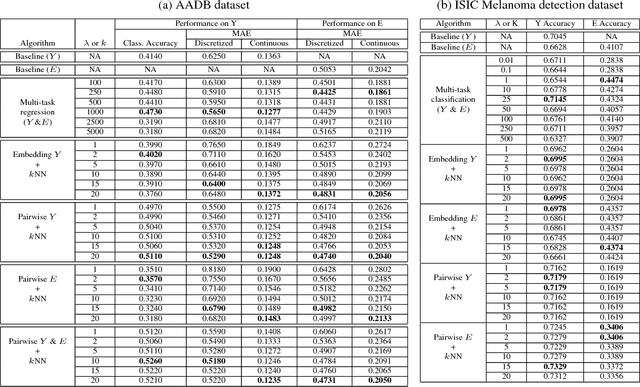
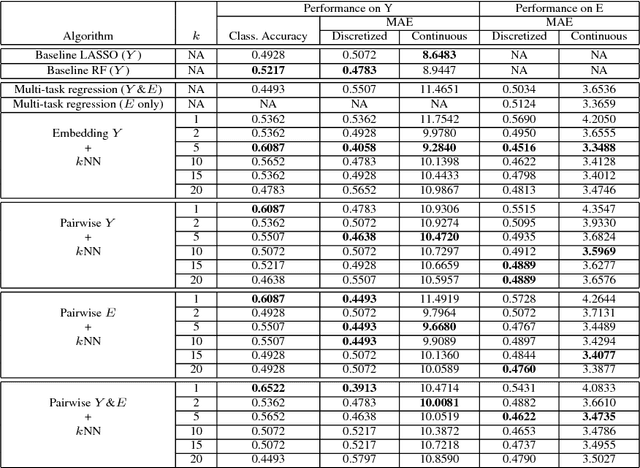
The adoption of machine learning in high-stakes applications such as healthcare and law has lagged in part because predictions are not accompanied by explanations comprehensible to the domain user, who often holds the ultimate responsibility for decisions and outcomes. In this paper, we propose an approach to generate such explanations in which training data is augmented to include, in addition to features and labels, explanations elicited from domain users. A joint model is then learned to produce both labels and explanations from the input features. This simple idea ensures that explanations are tailored to the complexity expectations and domain knowledge of the consumer. Evaluation spans multiple modeling techniques on a game dataset, a (visual) aesthetics dataset, a chemical odor dataset and a Melanoma dataset showing that our approach is generalizable across domains and algorithms. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, also improve modeling accuracy.
Learning to Teach in Cooperative Multiagent Reinforcement Learning
Aug 31, 2018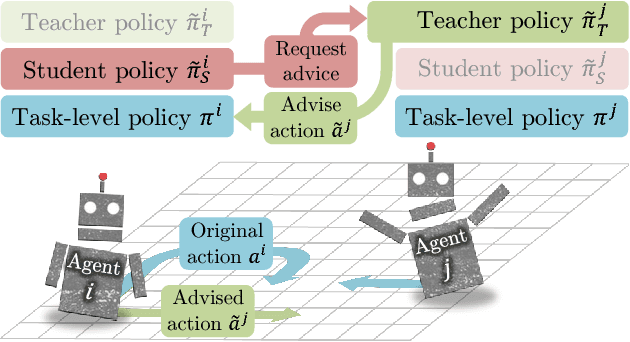

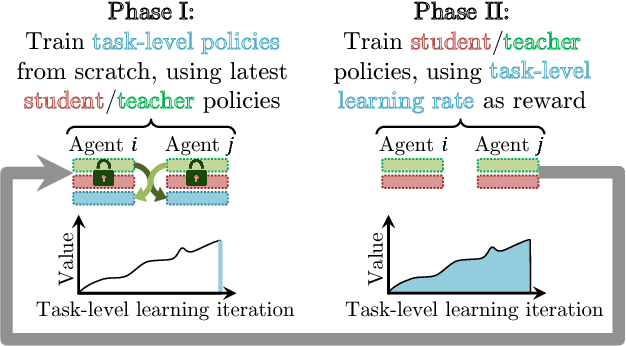
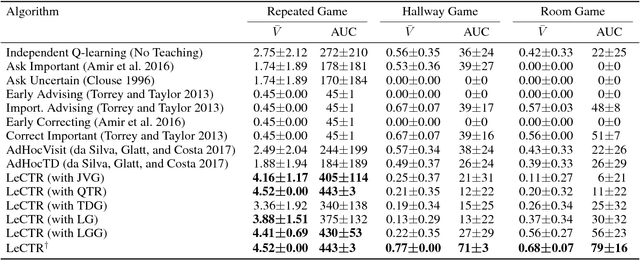
Collective human knowledge has clearly benefited from the fact that innovations by individuals are taught to others through communication. Similar to human social groups, agents in distributed learning systems would likely benefit from communication to share knowledge and teach skills. The problem of teaching to improve agent learning has been investigated by prior works, but these approaches make assumptions that prevent application of teaching to general multiagent problems, or require domain expertise for problems they can apply to. This learning to teach problem has inherent complexities related to measuring long-term impacts of teaching that compound the standard multiagent coordination challenges. In contrast to existing works, this paper presents the first general framework and algorithm for intelligent agents to learn to teach in a multiagent environment. Our algorithm, Learning to Coordinate and Teach Reinforcement (LeCTR), addresses peer-to-peer teaching in cooperative multiagent reinforcement learning. Each agent in our approach learns both when and what to advise, then uses the received advice to improve local learning. Importantly, these roles are not fixed; these agents learn to assume the role of student and/or teacher at the appropriate moments, requesting and providing advice in order to improve teamwide performance and learning. Empirical comparisons against state-of-the-art teaching methods show that our teaching agents not only learn significantly faster, but also learn to coordinate in tasks where existing methods fail.
Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering
Apr 26, 2018

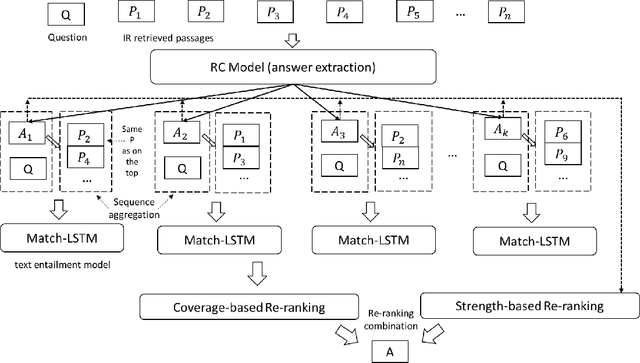
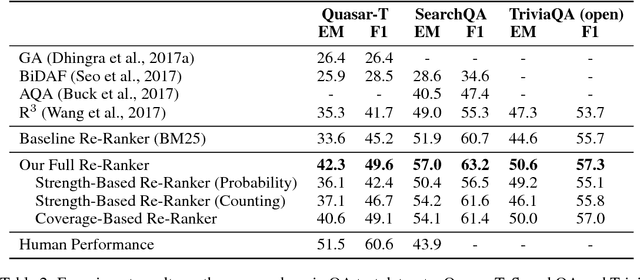
A popular recent approach to answering open-domain questions is to first search for question-related passages and then apply reading comprehension models to extract answers. Existing methods usually extract answers from single passages independently. But some questions require a combination of evidence from across different sources to answer correctly. In this paper, we propose two models which make use of multiple passages to generate their answers. Both use an answer-reranking approach which reorders the answer candidates generated by an existing state-of-the-art QA model. We propose two methods, namely, strength-based re-ranking and coverage-based re-ranking, to make use of the aggregated evidence from different passages to better determine the answer. Our models have achieved state-of-the-art results on three public open-domain QA datasets: Quasar-T, SearchQA and the open-domain version of TriviaQA, with about 8 percentage points of improvement over the former two datasets.
Eigenoption Discovery through the Deep Successor Representation
Feb 23, 2018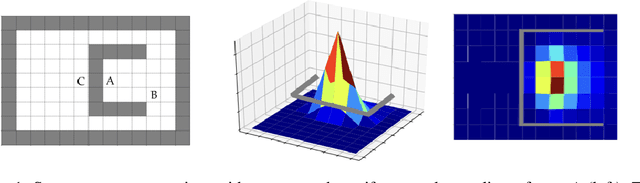
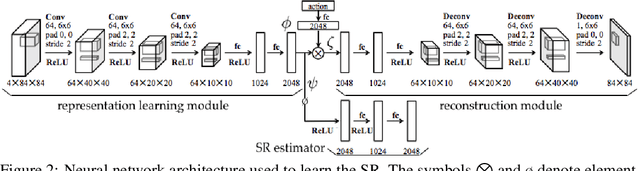
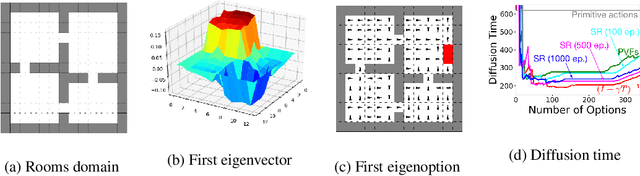
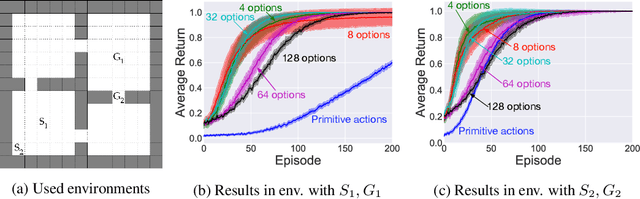
Options in reinforcement learning allow agents to hierarchically decompose a task into subtasks, having the potential to speed up learning and planning. However, autonomously learning effective sets of options is still a major challenge in the field. In this paper we focus on the recently introduced idea of using representation learning methods to guide the option discovery process. Specifically, we look at eigenoptions, options obtained from representations that encode diffusive information flow in the environment. We extend the existing algorithms for eigenoption discovery to settings with stochastic transitions and in which handcrafted features are not available. We propose an algorithm that discovers eigenoptions while learning non-linear state representations from raw pixels. It exploits recent successes in the deep reinforcement learning literature and the equivalence between proto-value functions and the successor representation. We use traditional tabular domains to provide intuition about our approach and Atari 2600 games to demonstrate its potential.
The Eigenoption-Critic Framework
Dec 11, 2017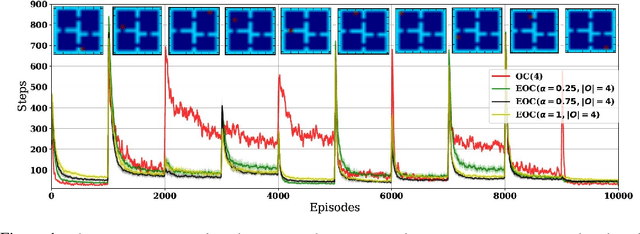
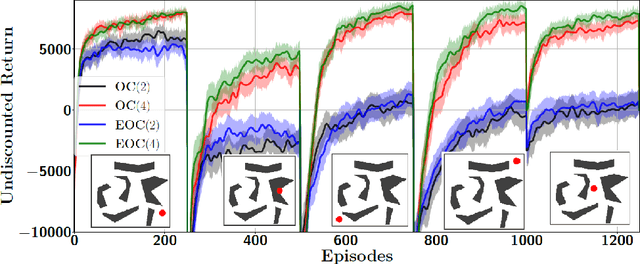
Eigenoptions (EOs) have been recently introduced as a promising idea for generating a diverse set of options through the graph Laplacian, having been shown to allow efficient exploration. Despite its initial promising results, a couple of issues in current algorithms limit its application, namely: (1) EO methods require two separate steps (eigenoption discovery and reward maximization) to learn a control policy, which can incur a significant amount of storage and computation; (2) EOs are only defined for problems with discrete state-spaces and; (3) it is not easy to take the environment's reward function into consideration when discovering EOs. To addresses these issues, we introduce an algorithm termed eigenoption-critic (EOC) based on the Option-critic (OC) framework [Bacon17], a general hierarchical reinforcement learning (RL) algorithm that allows learning the intra-option policies simultaneously with the policy over options. We also propose a generalization of EOC to problems with continuous state-spaces through the Nystr\"om approximation. EOC can also be seen as extending OC to nonstationary settings, where the discovered options are not tailored for a single task.
UbuntuWorld 1.0 LTS - A Platform for Automated Problem Solving & Troubleshooting in the Ubuntu OS
Aug 12, 2017
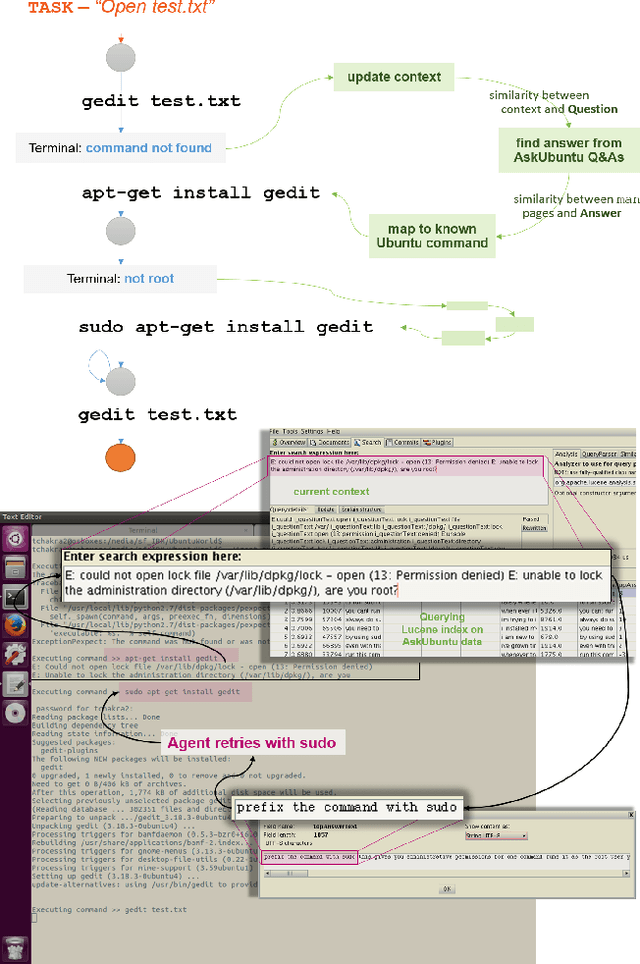
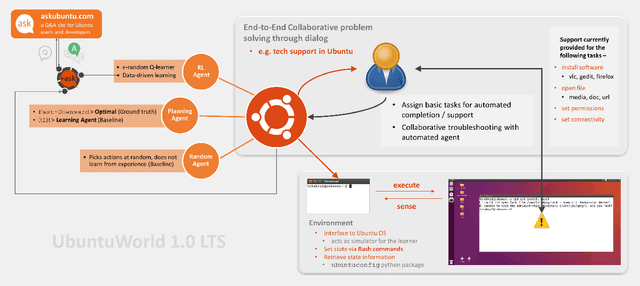
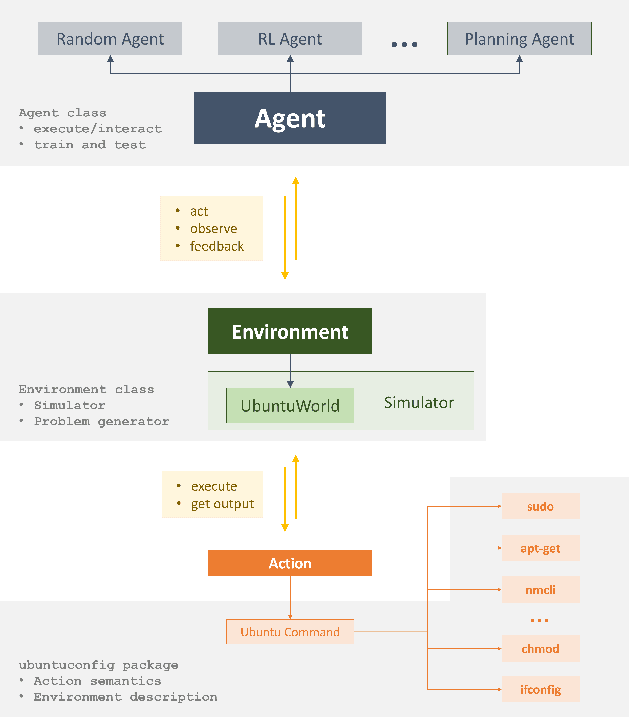
In this paper, we present UbuntuWorld 1.0 LTS - a platform for developing automated technical support agents in the Ubuntu operating system. Specifically, we propose to use the Bash terminal as a simulator of the Ubuntu environment for a learning-based agent and demonstrate the usefulness of adopting reinforcement learning (RL) techniques for basic problem solving and troubleshooting in this environment. We provide a plug-and-play interface to the simulator as a python package where different types of agents can be plugged in and evaluated, and provide pathways for integrating data from online support forums like AskUbuntu into an automated agent's learning process. Finally, we show that the use of this data significantly improves the agent's learning efficiency. We believe that this platform can be adopted as a real-world test bed for research on automated technical support.