 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Eigenoption-Critic Framework
Paper and Code
Dec 11, 2017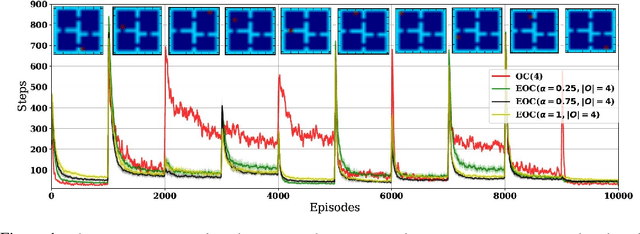
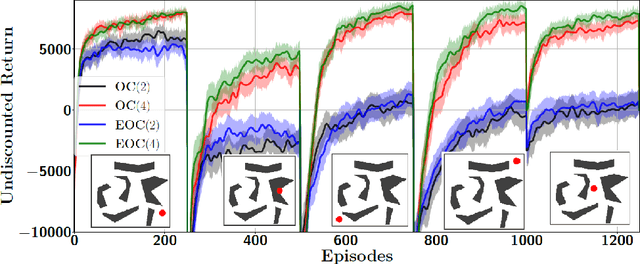
Eigenoptions (EOs) have been recently introduced as a promising idea for generating a diverse set of options through the graph Laplacian, having been shown to allow efficient exploration. Despite its initial promising results, a couple of issues in current algorithms limit its application, namely: (1) EO methods require two separate steps (eigenoption discovery and reward maximization) to learn a control policy, which can incur a significant amount of storage and computation; (2) EOs are only defined for problems with discrete state-spaces and; (3) it is not easy to take the environment's reward function into consideration when discovering EOs. To addresses these issues, we introduce an algorithm termed eigenoption-critic (EOC) based on the Option-critic (OC) framework [Bacon17], a general hierarchical reinforcement learning (RL) algorithm that allows learning the intra-option policies simultaneously with the policy over options. We also propose a generalization of EOC to problems with continuous state-spaces through the Nystr\"om approximation. EOC can also be seen as extending OC to nonstationary settings, where the discovered options are not tailored for a single task.