 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models in Vision: A Survey
Sep 10, 2022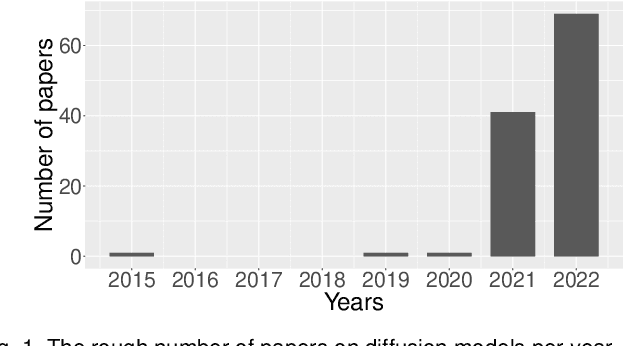
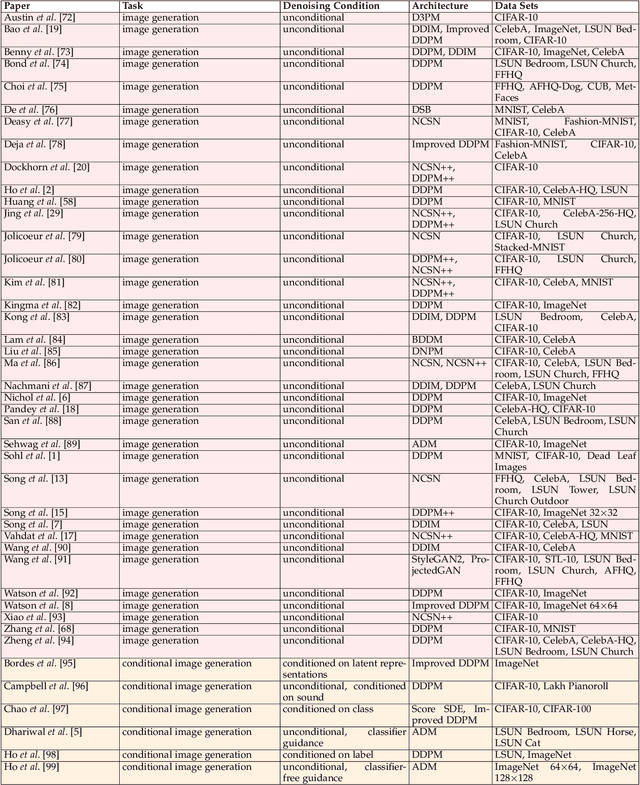
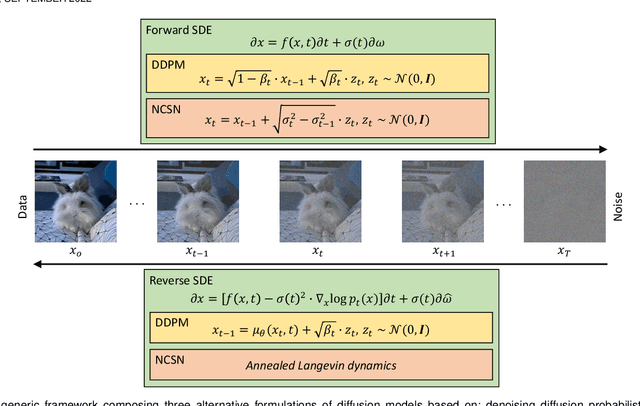

Denoising diffusion models represent a recent emerging topic in computer vision, demonstrating remarkable results in the area of generative modeling. A diffusion model is a deep generative model that is based on two stages, a forward diffusion stage and a reverse diffusion stage. In the forward diffusion stage, the input data is gradually perturbed over several steps by adding Gaussian noise. In the reverse stage, a model is tasked at recovering the original input data by learning to gradually reverse the diffusion process, step by step. Diffusion models are widely appreciated for the quality and diversity of the generated samples, despite their known computational burdens, i.e. low speeds due to the high number of steps involved during sampling. In this survey, we provide a comprehensive review of articles on denoising diffusion models applied in vision, comprising both theoretical and practical contributions in the field. First, we identify and present three generic diffusion modeling frameworks, which are based on denoising diffusion probabilistic models, noise conditioned score networks, and stochastic differential equations. We further discuss the relations between diffusion models and other deep generative models, including variational auto-encoders, generative adversarial networks, energy-based models, autoregressive models and normalizing flows. Then, we introduce a multi-perspective categorization of diffusion models applied in computer vision. Finally, we illustrate the current limitations of diffusion models and envision some interesting directions for future research.
On Higher Adversarial Susceptibility of Contrastive Self-Supervised Learning
Jul 22, 2022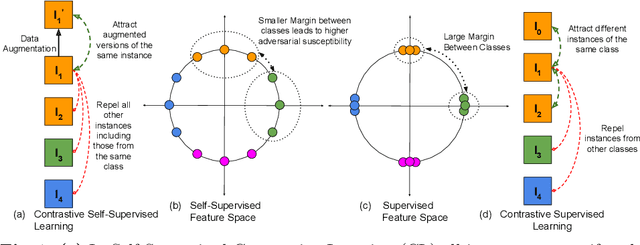

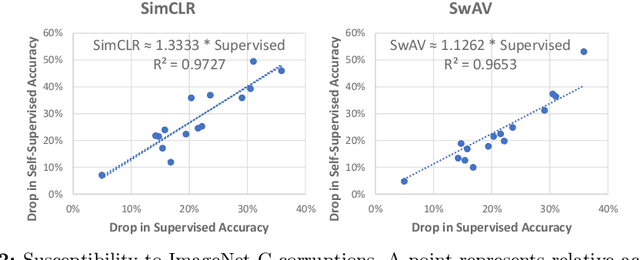

Contrastive self-supervised learning (CSL) has managed to match or surpass the performance of supervised learning in image and video classification. However, it is still largely unknown if the nature of the representation induced by the two learning paradigms is similar. We investigate this under the lens of adversarial robustness. Our analytical treatment of the problem reveals intrinsic higher sensitivity of CSL over supervised learning. It identifies the uniform distribution of data representation over a unit hypersphere in the CSL representation space as the key contributor to this phenomenon. We establish that this increases model sensitivity to input perturbations in the presence of false negatives in the training data. Our finding is supported by extensive experiments for image and video classification using adversarial perturbations and other input corruptions. Building on the insights, we devise strategies that are simple, yet effective in improving model robustness with CSL training. We demonstrate up to 68% reduction in the performance gap between adversarially attacked CSL and its supervised counterpart. Finally, we contribute to robust CSL paradigm by incorporating our findings in adversarial self-supervised learning. We demonstrate an average gain of about 5% over two different state-of-the-art methods in this domain.
SSMTL++: Revisiting Self-Supervised Multi-Task Learning for Video Anomaly Detection
Jul 16, 2022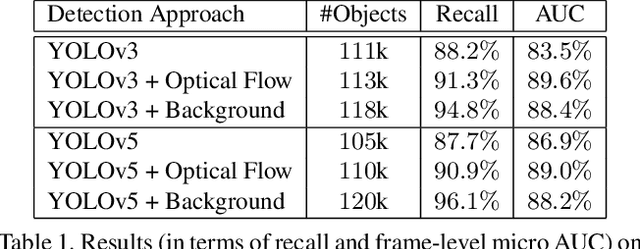
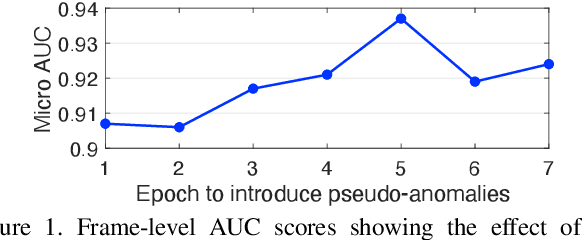
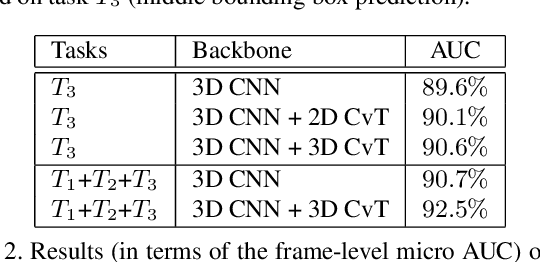
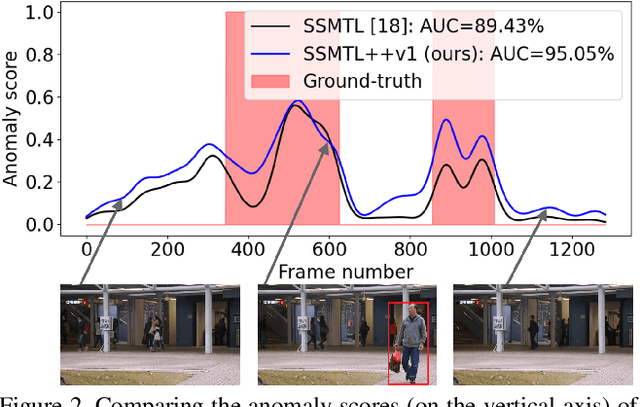
A self-supervised multi-task learning (SSMTL) framework for video anomaly detection was recently introduced in literature. Due to its highly accurate results, the method attracted the attention of many researchers. In this work, we revisit the self-supervised multi-task learning framework, proposing several updates to the original method. First, we study various detection methods, e.g. based on detecting high-motion regions using optical flow or background subtraction, since we believe the currently used pre-trained YOLOv3 is suboptimal, e.g. objects in motion or objects from unknown classes are never detected. Second, we modernize the 3D convolutional backbone by introducing multi-head self-attention modules, inspired by the recent success of vision transformers. As such, we alternatively introduce both 2D and 3D convolutional vision transformer (CvT) blocks. Third, in our attempt to further improve the model, we study additional self-supervised learning tasks, such as predicting segmentation maps through knowledge distillation, solving jigsaw puzzles, estimating body pose through knowledge distillation, predicting masked regions (inpainting), and adversarial learning with pseudo-anomalies. We conduct experiments to assess the performance impact of the introduced changes. Upon finding more promising configurations of the framework, dubbed SSMTL++v1 and SSMTL++v2, we extend our preliminary experiments to more data sets, demonstrating that our performance gains are consistent across all data sets. In most cases, our results on Avenue, ShanghaiTech and UBnormal raise the state-of-the-art performance to a new level.
GAMa: Cross-view Video Geo-localization
Jul 06, 2022
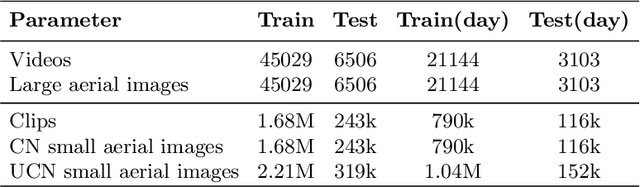


The existing work in cross-view geo-localization is based on images where a ground panorama is matched to an aerial image. In this work, we focus on ground videos instead of images which provides additional contextual cues which are important for this task. There are no existing datasets for this problem, therefore we propose GAMa dataset, a large-scale dataset with ground videos and corresponding aerial images. We also propose a novel approach to solve this problem. At clip-level, a short video clip is matched with corresponding aerial image and is later used to get video-level geo-localization of a long video. Moreover, we propose a hierarchical approach to further improve the clip-level geolocalization. It is a challenging dataset, unaligned and limited field of view, and our proposed method achieves a Top-1 recall rate of 19.4% and 45.1% @1.0mile. Code and dataset are available at following link: https://github.com/svyas23/GAMa.
Weakly Supervised Grounding for VQA in Vision-Language Transformers
Jul 05, 2022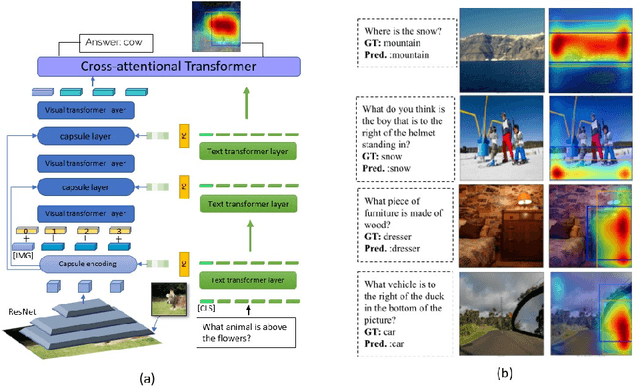
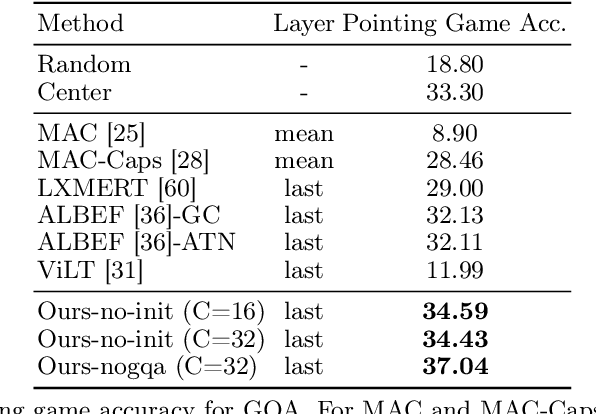
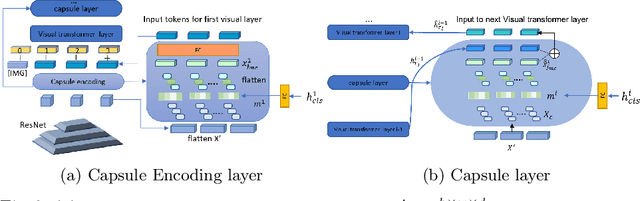
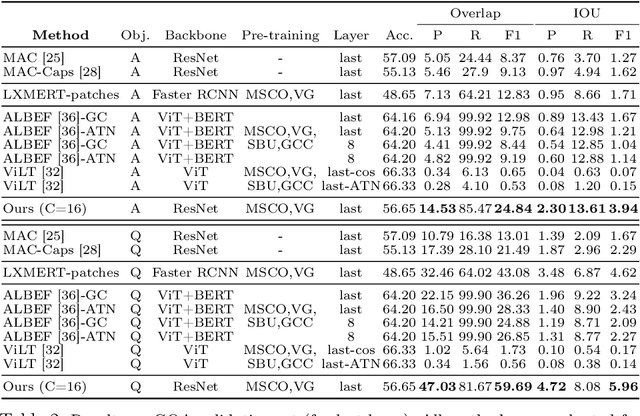
Transformers for visual-language representation learning have been getting a lot of interest and shown tremendous performance on visual question answering (VQA) and grounding. But most systems that show good performance of those tasks still rely on pre-trained object detectors during training, which limits their applicability to the object classes available for those detectors. To mitigate this limitation, the following paper focuses on the problem of weakly supervised grounding in context of visual question answering in transformers. The approach leverages capsules by grouping each visual token in the visual encoder and uses activations from language self-attention layers as a text-guided selection module to mask those capsules before they are forwarded to the next layer. We evaluate our approach on the challenging GQA as well as VQA-HAT dataset for VQA grounding. Our experiments show that: while removing the information of masked objects from standard transformer architectures leads to a significant drop in performance, the integration of capsules significantly improves the grounding ability of such systems and provides new state-of-the-art results compared to other approaches in the field.
Towards Realistic Semi-Supervised Learning
Jul 05, 2022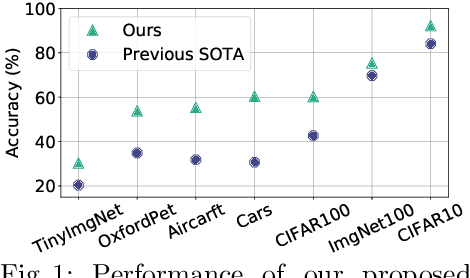
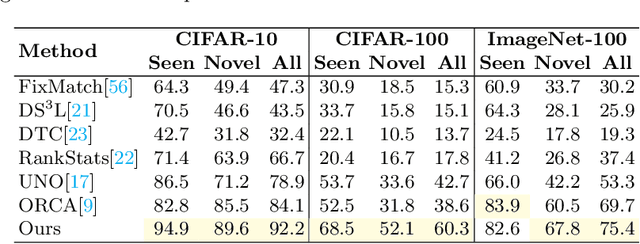


Deep learning is pushing the state-of-the-art in many computer vision applications. However, it relies on large annotated data repositories, and capturing the unconstrained nature of the real-world data is yet to be solved. Semi-supervised learning (SSL) complements the annotated training data with a large corpus of unlabeled data to reduce annotation cost. The standard SSL approach assumes unlabeled data are from the same distribution as annotated data. Recently, ORCA [9] introduce a more realistic SSL problem, called open-world SSL, by assuming that the unannotated data might contain samples from unknown classes. This work proposes a novel approach to tackle SSL in open-world setting, where we simultaneously learn to classify known and unknown classes. At the core of our method, we utilize sample uncertainty and incorporate prior knowledge about class distribution to generate reliable pseudo-labels for unlabeled data belonging to both known and unknown classes. Our extensive experimentation showcases the effectiveness of our approach on several benchmark datasets, where it substantially outperforms the existing state-of-the-art on seven diverse datasets including CIFAR-100 (17.6%), ImageNet-100 (5.7%), and Tiny ImageNet (9.9%).
OpenLDN: Learning to Discover Novel Classes for Open-World Semi-Supervised Learning
Jul 05, 2022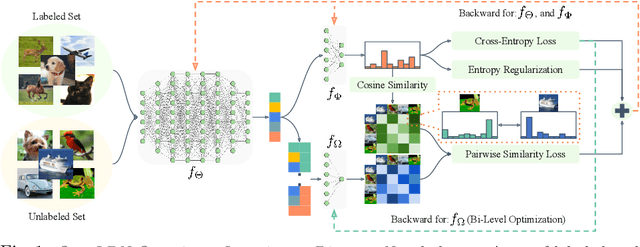

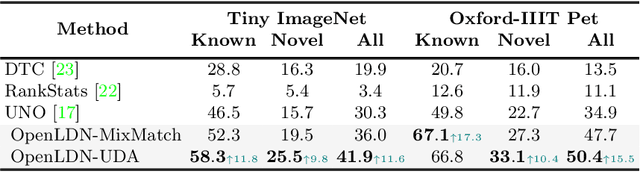
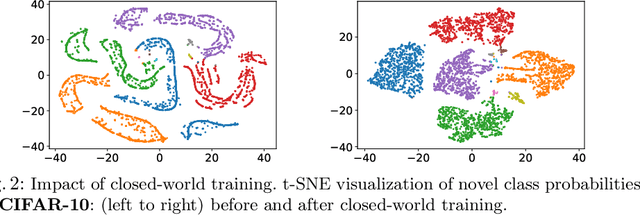
Semi-supervised learning (SSL) is one of the dominant approaches to address the annotation bottleneck of supervised learning. Recent SSL methods can effectively leverage a large repository of unlabeled data to improve performance while relying on a small set of labeled data. One common assumption in most SSL methods is that the labeled and unlabeled data are from the same underlying data distribution. However, this is hardly the case in many real-world scenarios, which limits their applicability. In this work, instead, we attempt to solve the recently proposed challenging open-world SSL problem that does not make such an assumption. In the open-world SSL problem, the objective is to recognize samples of known classes, and simultaneously detect and cluster samples belonging to novel classes present in unlabeled data. This work introduces OpenLDN that utilizes a pairwise similarity loss to discover novel classes. Using a bi-level optimization rule this pairwise similarity loss exploits the information available in the labeled set to implicitly cluster novel class samples, while simultaneously recognizing samples from known classes. After discovering novel classes, OpenLDN transforms the open-world SSL problem into a standard SSL problem to achieve additional performance gains using existing SSL methods. Our extensive experiments demonstrate that OpenLDN outperforms the current state-of-the-art methods on multiple popular classification benchmarks while providing a better accuracy/training time trade-off.
Learning with Capsules: A Survey
Jun 06, 2022
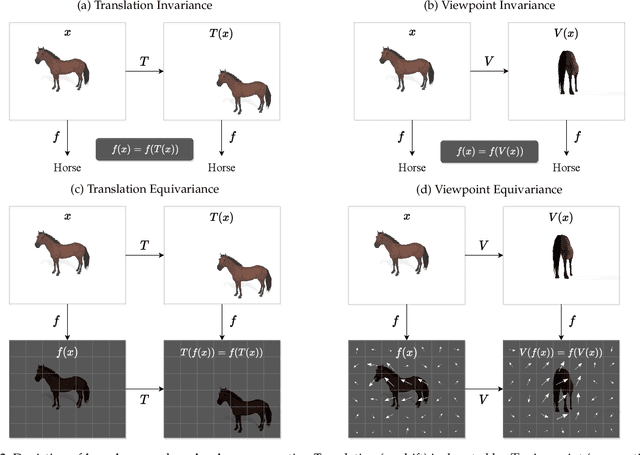
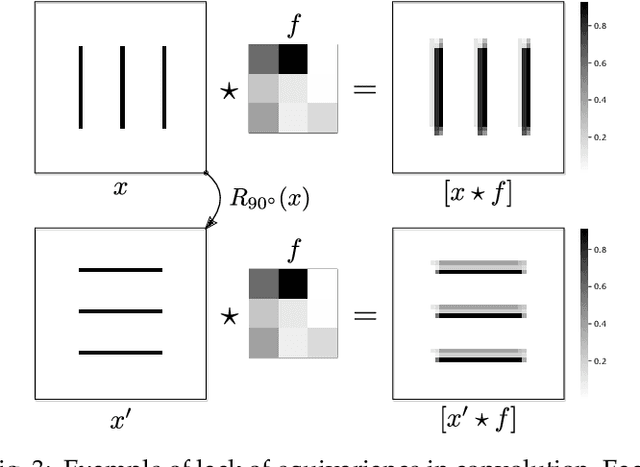
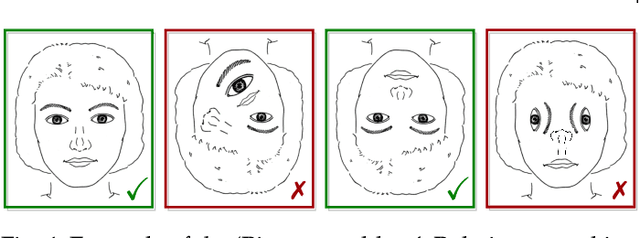
Capsule networks were proposed as an alternative approach to Convolutional Neural Networks (CNNs) for learning object-centric representations, which can be leveraged for improved generalization and sample complexity. Unlike CNNs, capsule networks are designed to explicitly model part-whole hierarchical relationships by using groups of neurons to encode visual entities, and learn the relationships between those entities. Promising early results achieved by capsule networks have motivated the deep learning community to continue trying to improve their performance and scalability across several application areas. However, a major hurdle for capsule network research has been the lack of a reliable point of reference for understanding their foundational ideas and motivations. The aim of this survey is to provide a comprehensive overview of the capsule network research landscape, which will serve as a valuable resource for the community going forward. To that end, we start with an introduction to the fundamental concepts and motivations behind capsule networks, such as equivariant inference in computer vision. We then cover the technical advances in the capsule routing mechanisms and the various formulations of capsule networks, e.g. generative and geometric. Additionally, we provide a detailed explanation of how capsule networks relate to the popular attention mechanism in Transformers, and highlight non-trivial conceptual similarities between them in the context of representation learning. Afterwards, we explore the extensive applications of capsule networks in computer vision, video and motion, graph representation learning, natural language processing, medical imaging and many others. To conclude, we provide an in-depth discussion regarding the main hurdles in capsule network research, and highlight promising research directions for future work.
EBM Life Cycle: MCMC Strategies for Synthesis, Defense, and Density Modeling
May 24, 2022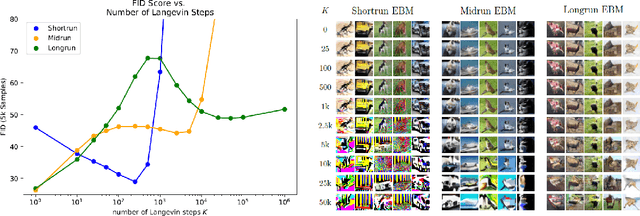

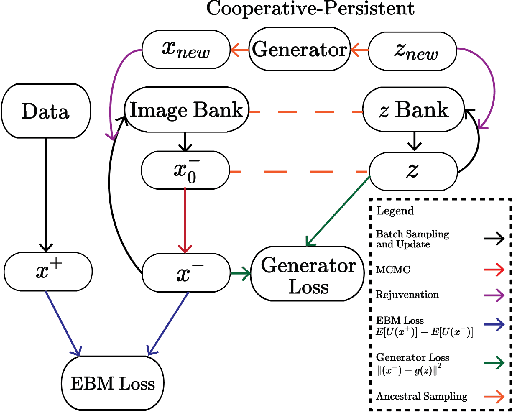
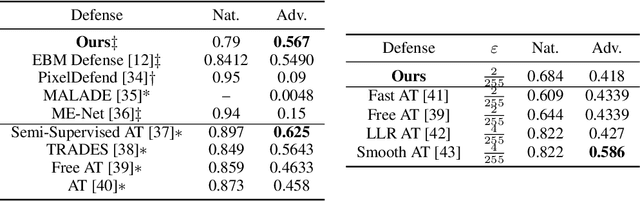
This work presents strategies to learn an Energy-Based Model (EBM) according to the desired length of its MCMC sampling trajectories. MCMC trajectories of different lengths correspond to models with different purposes. Our experiments cover three different trajectory magnitudes and learning outcomes: 1) shortrun sampling for image generation; 2) midrun sampling for classifier-agnostic adversarial defense; and 3) longrun sampling for principled modeling of image probability densities. To achieve these outcomes, we introduce three novel methods of MCMC initialization for negative samples used in Maximum Likelihood (ML) learning. With standard network architectures and an unaltered ML objective, our MCMC initialization methods alone enable significant performance gains across the three applications that we investigate. Our results include state-of-the-art FID scores for unnormalized image densities on the CIFAR-10 and ImageNet datasets; state-of-the-art adversarial defense on CIFAR-10 among purification methods and the first EBM defense on ImageNet; and scalable techniques for learning valid probability densities. Code for this project can be found at https://github.com/point0bar1/ebm-life-cycle.
Self-Supervised Video Object Segmentation via Cutout Prediction and Tagging
Apr 22, 2022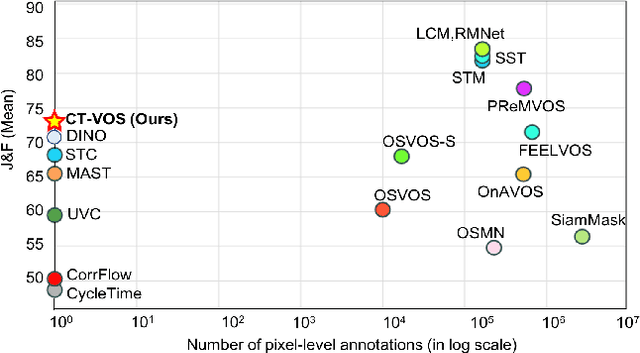
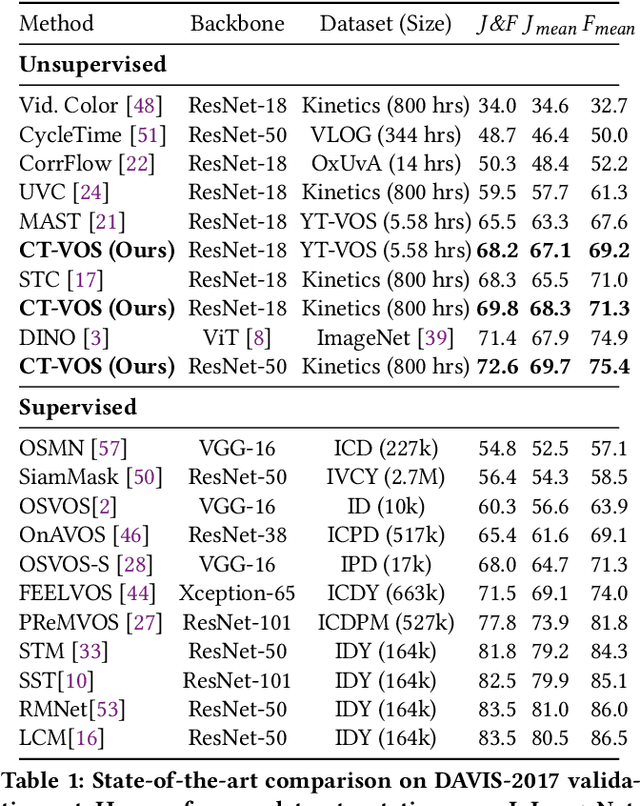
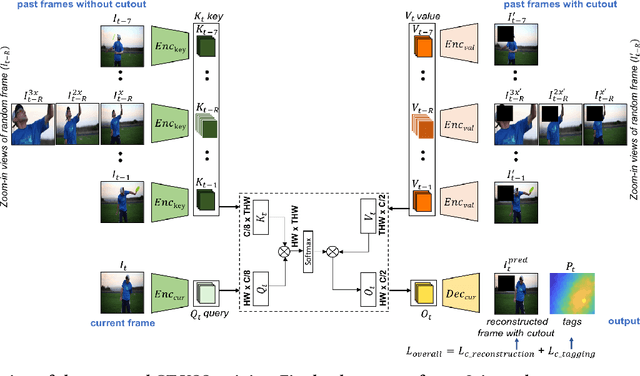
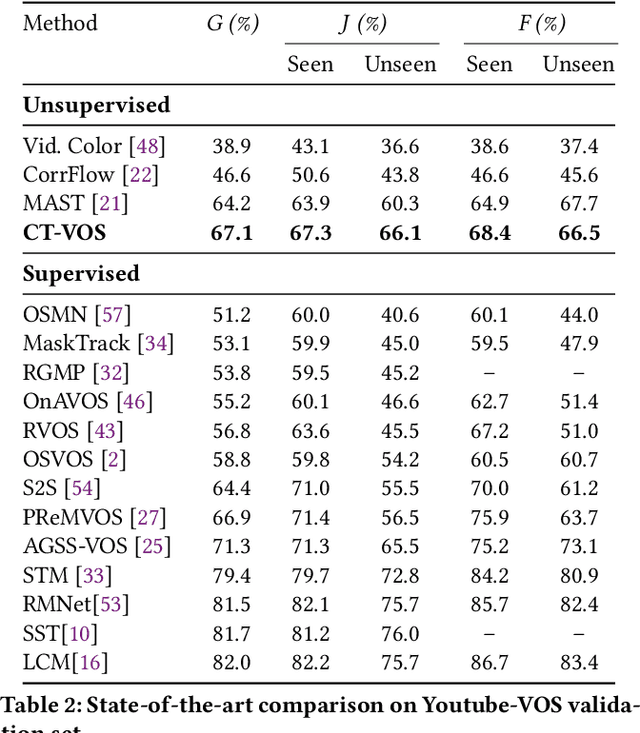
We propose a novel self-supervised Video Object Segmentation (VOS) approach that strives to achieve better object-background discriminability for accurate object segmentation. Distinct from previous self-supervised VOS methods, our approach is based on a discriminative learning loss formulation that takes into account both object and background information to ensure object-background discriminability, rather than using only object appearance. The discriminative learning loss comprises cutout-based reconstruction (cutout region represents part of a frame, whose pixels are replaced with some constant values) and tag prediction loss terms. The cutout-based reconstruction term utilizes a simple cutout scheme to learn the pixel-wise correspondence between the current and previous frames in order to reconstruct the original current frame with added cutout region in it. The introduced cutout patch guides the model to focus as much on the significant features of the object of interest as the less significant ones, thereby implicitly equipping the model to address occlusion-based scenarios. Next, the tag prediction term encourages object-background separability by grouping tags of all pixels in the cutout region that are similar, while separating them from the tags of the rest of the reconstructed frame pixels. Additionally, we introduce a zoom-in scheme that addresses the problem of small object segmentation by capturing fine structural information at multiple scales. Our proposed approach, termed CT-VOS, achieves state-of-the-art results on two challenging benchmarks: DAVIS-2017 and Youtube-VOS. A detailed ablation showcases the importance of the proposed loss formulation to effectively capture object-background discriminability and the impact of our zoom-in scheme to accurately segment small-sized objects.