 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Student Networks for Data-Free Model Stealing
Sep 18, 2023Existing data-free model stealing methods use a generator to produce samples in order to train a student model to match the target model outputs. To this end, the two main challenges are estimating gradients of the target model without access to its parameters, and generating a diverse set of training samples that thoroughly explores the input space. We propose a Dual Student method where two students are symmetrically trained in order to provide the generator a criterion to generate samples that the two students disagree on. On one hand, disagreement on a sample implies at least one student has classified the sample incorrectly when compared to the target model. This incentive towards disagreement implicitly encourages the generator to explore more diverse regions of the input space. On the other hand, our method utilizes gradients of student models to indirectly estimate gradients of the target model. We show that this novel training objective for the generator network is equivalent to optimizing a lower bound on the generator's loss if we had access to the target model gradients. We show that our new optimization framework provides more accurate gradient estimation of the target model and better accuracies on benchmark classification datasets. Additionally, our approach balances improved query efficiency with training computation cost. Finally, we demonstrate that our method serves as a better proxy model for transfer-based adversarial attacks than existing data-free model stealing methods.
CDFSL-V: Cross-Domain Few-Shot Learning for Videos
Sep 15, 2023



Few-shot video action recognition is an effective approach to recognizing new categories with only a few labeled examples, thereby reducing the challenges associated with collecting and annotating large-scale video datasets. Existing methods in video action recognition rely on large labeled datasets from the same domain. However, this setup is not realistic as novel categories may come from different data domains that may have different spatial and temporal characteristics. This dissimilarity between the source and target domains can pose a significant challenge, rendering traditional few-shot action recognition techniques ineffective. To address this issue, in this work, we propose a novel cross-domain few-shot video action recognition method that leverages self-supervised learning and curriculum learning to balance the information from the source and target domains. To be particular, our method employs a masked autoencoder-based self-supervised training objective to learn from both source and target data in a self-supervised manner. Then a progressive curriculum balances learning the discriminative information from the source dataset with the generic information learned from the target domain. Initially, our curriculum utilizes supervised learning to learn class discriminative features from the source data. As the training progresses, we transition to learning target-domain-specific features. We propose a progressive curriculum to encourage the emergence of rich features in the target domain based on class discriminative supervised features in the source domain. We evaluate our method on several challenging benchmark datasets and demonstrate that our approach outperforms existing cross-domain few-shot learning techniques. Our code is available at https://github.com/Sarinda251/CDFSL-V
Towards Realistic Semi-Supervised Learning
Jul 05, 2022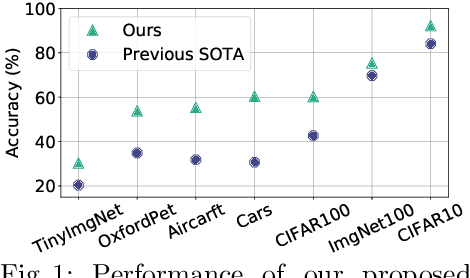
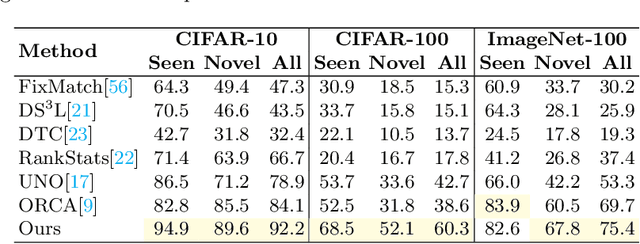


Deep learning is pushing the state-of-the-art in many computer vision applications. However, it relies on large annotated data repositories, and capturing the unconstrained nature of the real-world data is yet to be solved. Semi-supervised learning (SSL) complements the annotated training data with a large corpus of unlabeled data to reduce annotation cost. The standard SSL approach assumes unlabeled data are from the same distribution as annotated data. Recently, ORCA [9] introduce a more realistic SSL problem, called open-world SSL, by assuming that the unannotated data might contain samples from unknown classes. This work proposes a novel approach to tackle SSL in open-world setting, where we simultaneously learn to classify known and unknown classes. At the core of our method, we utilize sample uncertainty and incorporate prior knowledge about class distribution to generate reliable pseudo-labels for unlabeled data belonging to both known and unknown classes. Our extensive experimentation showcases the effectiveness of our approach on several benchmark datasets, where it substantially outperforms the existing state-of-the-art on seven diverse datasets including CIFAR-100 (17.6%), ImageNet-100 (5.7%), and Tiny ImageNet (9.9%).
OpenLDN: Learning to Discover Novel Classes for Open-World Semi-Supervised Learning
Jul 05, 2022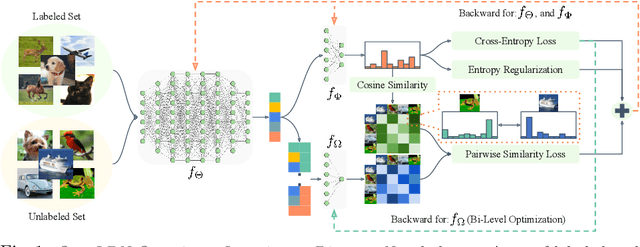

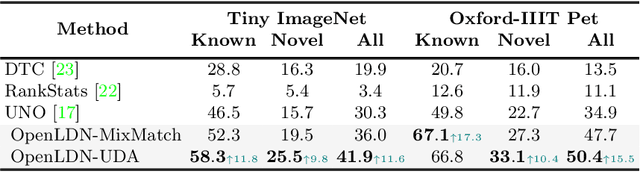
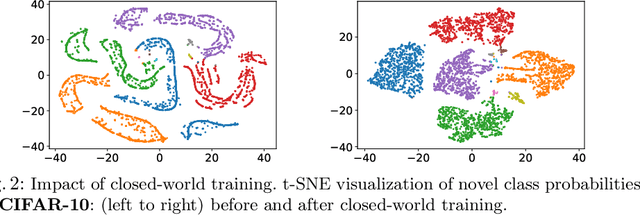
Semi-supervised learning (SSL) is one of the dominant approaches to address the annotation bottleneck of supervised learning. Recent SSL methods can effectively leverage a large repository of unlabeled data to improve performance while relying on a small set of labeled data. One common assumption in most SSL methods is that the labeled and unlabeled data are from the same underlying data distribution. However, this is hardly the case in many real-world scenarios, which limits their applicability. In this work, instead, we attempt to solve the recently proposed challenging open-world SSL problem that does not make such an assumption. In the open-world SSL problem, the objective is to recognize samples of known classes, and simultaneously detect and cluster samples belonging to novel classes present in unlabeled data. This work introduces OpenLDN that utilizes a pairwise similarity loss to discover novel classes. Using a bi-level optimization rule this pairwise similarity loss exploits the information available in the labeled set to implicitly cluster novel class samples, while simultaneously recognizing samples from known classes. After discovering novel classes, OpenLDN transforms the open-world SSL problem into a standard SSL problem to achieve additional performance gains using existing SSL methods. Our extensive experiments demonstrate that OpenLDN outperforms the current state-of-the-art methods on multiple popular classification benchmarks while providing a better accuracy/training time trade-off.
Threat of Adversarial Attacks on Deep Learning in Computer Vision: Survey II
Aug 01, 2021
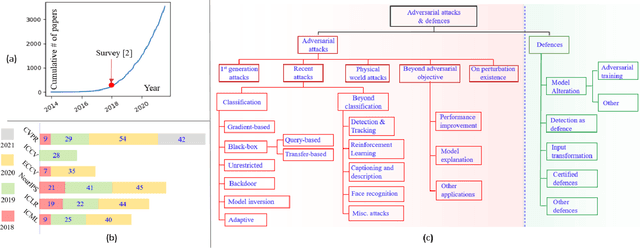


Deep Learning (DL) is the most widely used tool in the contemporary field of computer vision. Its ability to accurately solve complex problems is employed in vision research to learn deep neural models for a variety of tasks, including security critical applications. However, it is now known that DL is vulnerable to adversarial attacks that can manipulate its predictions by introducing visually imperceptible perturbations in images and videos. Since the discovery of this phenomenon in 2013~[1], it has attracted significant attention of researchers from multiple sub-fields of machine intelligence. In [2], we reviewed the contributions made by the computer vision community in adversarial attacks on deep learning (and their defenses) until the advent of year 2018. Many of those contributions have inspired new directions in this area, which has matured significantly since witnessing the first generation methods. Hence, as a legacy sequel of [2], this literature review focuses on the advances in this area since 2018. To ensure authenticity, we mainly consider peer-reviewed contributions published in the prestigious sources of computer vision and machine learning research. Besides a comprehensive literature review, the article also provides concise definitions of technical terminologies for non-experts in this domain. Finally, this article discusses challenges and future outlook of this direction based on the literature reviewed herein and [2].
Towards Consistent Predictive Confidence through Fitted Ensembles
Jun 22, 2021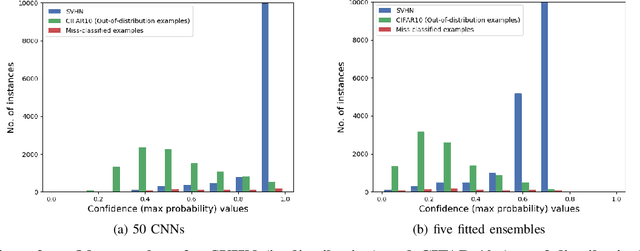
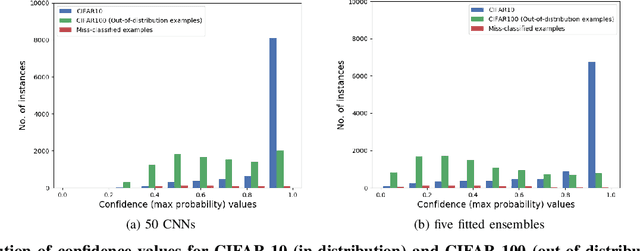
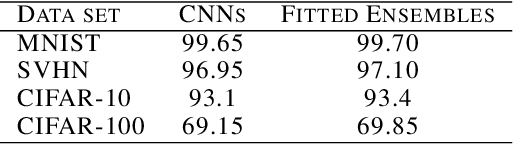

Deep neural networks are behind many of the recent successes in machine learning applications. However, these models can produce overconfident decisions while encountering out-of-distribution (OOD) examples or making a wrong prediction. This inconsistent predictive confidence limits the integration of independently-trained learning models into a larger system. This paper introduces separable concept learning framework to realistically measure the performance of classifiers in presence of OOD examples. In this setup, several instances of a classifier are trained on different parts of a partition of the set of classes. Later, the performance of the combination of these models is evaluated on a separate test set. Unlike current OOD detection techniques, this framework does not require auxiliary OOD datasets and does not separate classification from detection performance. Furthermore, we present a new strong baseline for more consistent predictive confidence in deep models, called fitted ensembles, where overconfident predictions are rectified by transformed versions of the original classification task. Fitted ensembles can naturally detect OOD examples without requiring auxiliary data by observing contradicting predictions among its components. Experiments on MNIST, SVHN, CIFAR-10/100, and ImageNet show fitted ensemble significantly outperform conventional ensembles on OOD examples and are possible to scale.
Fitted Learning: Models with Awareness of their Limits
Jul 09, 2018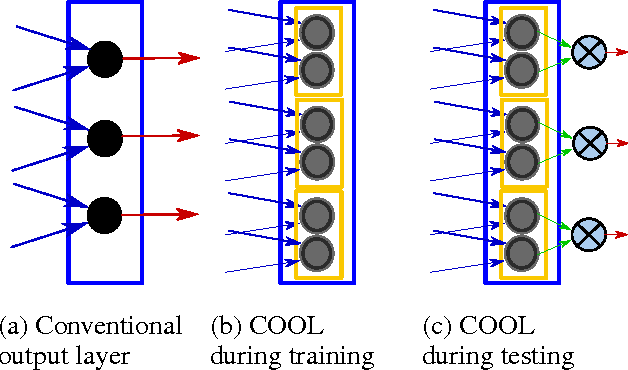
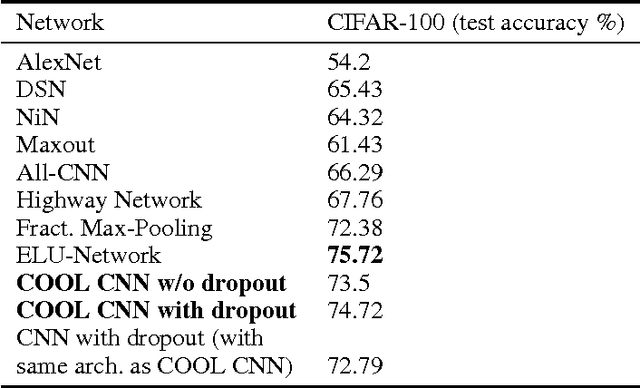
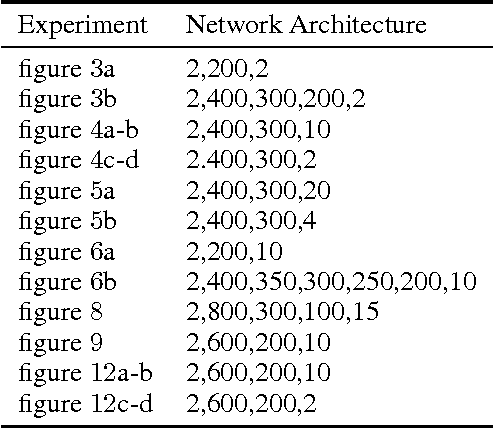
Though deep learning has pushed the boundaries of classification forward, in recent years hints of the limits of standard classification have begun to emerge. Problems such as fooling, adding new classes over time, and the need to retrain learning models only for small changes to the original problem all point to a potential shortcoming in the classic classification regime, where a comprehensive a priori knowledge of the possible classes or concepts is critical. Without such knowledge, classifiers misjudge the limits of their knowledge and overgeneralization therefore becomes a serious obstacle to consistent performance. In response to these challenges, this paper extends the classic regime by reframing classification instead with the assumption that concepts present in the training set are only a sample of the hypothetical final set of concepts. To bring learning models into this new paradigm, a novel elaboration of standard architectures called the competitive overcomplete output layer (COOL) neural network is introduced. Experiments demonstrate the effectiveness of COOL by applying it to fooling, separable concept learning, one-class neural networks, and standard classification benchmarks. The results suggest that, unlike conventional classifiers, the amount of generalization in COOL networks can be tuned to match the problem.