 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlue Data Intelligence Layer: Streaming Data and Agents for Multi-source Multi-modal Data-Centric Applications
Apr 16, 2026NL2SQL systems aim to address the growing need for natural language interaction with data. However, real-world information rarely maps to a single SQL query because (1) users express queries iteratively (2) questions often span multiple data sources beyond the closed-world assumption of a single database, and (3) queries frequently rely on commonsense or external knowledge. Consequently, satisfying realistic data needs require integrating heterogeneous sources, modalities, and contextual data. In this paper, we present Blue's Data Intelligence Layer (DIL) designed to support multi-source, multi-modal, and data-centric applications. Blue is a compound AI system that orchestrates agents and data for enterprise settings. DIL serves as the data intelligence layer for agentic data processing, to bridge the semantic gap between user intent and available information by unifying structured enterprise data, world knowledge accessible through LLMs, and personal context obtained through interaction. At the core of DIL is a data registry that stores metadata for diverse data sources and modalities to enable both native and natural language queries. DIL treats LLMs, the Web, and the User as source 'databases', each with their own query interface, elevating them to first-class data sources. DIL relies on data planners to transform user queries into executable query plans. These plans are declarative abstractions that unify relational operators with other operators spanning multiple modalities. DIL planners support decomposition of complex requests into subqueries, retrieval from diverse sources, and finally reasoning and integration to produce final results. We demonstrate DIL through two interactive scenarios in which user queries dynamically trigger multi-source retrieval, cross-modal reasoning, and result synthesis, illustrating how compound AI systems can move beyond single database NL2SQL.
Align then Train: Efficient Retrieval Adapter Learning
Apr 03, 2026Dense retrieval systems increasingly need to handle complex queries. In many realistic settings, users express intent through long instructions or task-specific descriptions, while target documents remain relatively simple and static. This asymmetry creates a retrieval mismatch: understanding queries may require strong reasoning and instruction-following, whereas efficient document indexing favors lightweight encoders. Existing retrieval systems often address this mismatch by directly improving the embedding model, but fine-tuning large embedding models to better follow such instructions is computationally expensive, memory-intensive, and operationally burdensome. To address this challenge, we propose Efficient Retrieval Adapter (ERA), a label-efficient framework that trains retrieval adapters in two stages: self-supervised alignment and supervised adaptation. Inspired by the pre-training and supervised fine-tuning stages of LLMs, ERA first aligns the embedding spaces of a large query embedder and a lightweight document embedder, and then uses limited labeled data to adapt the query-side representation, bridging both the representation gap between embedding models and the semantic gap between complex queries and simple documents without re-indexing the corpus. Experiments on the MAIR benchmark, spanning 126 retrieval tasks across 6 domains, show that ERA improves retrieval in low-label settings, outperforms methods that rely on larger amounts of labeled data, and effectively combines stronger query embedders with weaker document embedders across domains.
Towards Reliable Benchmarking: A Contamination Free, Controllable Evaluation Framework for Multi-step LLM Function Calling
Sep 30, 2025



As language models gain access to external tools via structured function calls, they become increasingly more capable of solving complex, multi-step tasks. However, existing benchmarks for tool-augmented language models (TaLMs) provide insufficient control over factors such as the number of functions accessible, task complexity, and input size, and remain vulnerable to data contamination. We present FuncBenchGen, a unified, contamination-free framework that evaluates TaLMs by generating synthetic multi-step tool-use tasks. The key idea is to cast tool use as traversal over a hidden function-dependency DAG where nodes are function calls and an edge between nodes represents one function consuming the output of another. Given a set of external function schemas, initial variable values, and a target variable, models must compose the correct call sequence to compute the target variable. FuncBenchGen allows users to precisely control task difficulty (e.g., graph size, dependency depth, and distractor functions) while avoiding data leakage. We apply our FuncBenchGen framework to evaluate seven LLMs on tool use tasks of varying difficulty. Reasoning-optimized models consistently outperform general-purpose models with GPT-5 significantly outperforming other models. Performance declines sharply as dependency depth increases. Furthermore, connected irrelevant functions prove especially difficult to handle. We find that strong models often make syntactically valid function calls but propagate incorrect or stale argument values across steps, revealing brittle state tracking by LLMs in multi-turn tool use. Motivated by this observation, we introduce a simple mitigation strategy that explicitly restates prior variable values to the agent at each step. Surprisingly, this lightweight change yields substantial gains across models. e.g., yielding a success rate improvement from 62.5% to 81.3% for GPT-5.
Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-$k$
Jun 10, 2025Retrieval-augmented generation (RAG) and long-context language models (LCLMs) both address context limitations of LLMs in open-domain question answering (QA). However, optimal external context to retrieve remains an open problem: fixing the retrieval size risks either wasting tokens or omitting key evidence. Existing adaptive methods like Self-RAG and Self-Route rely on iterative LLM prompting and perform well on factoid QA, but struggle with aggregation QA, where the optimal context size is both unknown and variable. We present Adaptive-$k$ retrieval, a simple and effective single-pass method that adaptively selects the number of passages based on the distribution of the similarity scores between the query and the candidate passages. It does not require model fine-tuning, extra LLM inferences or changes to existing retriever-reader pipelines. On both factoid and aggregation QA benchmarks, Adaptive-$k$ matches or outperforms fixed-$k$ baselines while using up to 10x fewer tokens than full-context input, yet still retrieves 70% of relevant passages. It improves accuracy across five LCLMs and two embedding models, highlighting that dynamically adjusting context size leads to more efficient and accurate QA.
From Single to Multi: How LLMs Hallucinate in Multi-Document Summarization
Oct 17, 2024



Although many studies have investigated and reduced hallucinations in large language models (LLMs) for single-document tasks, research on hallucination in multi-document summarization (MDS) tasks remains largely unexplored. Specifically, it is unclear how the challenges arising from handling multiple documents (e.g., repetition and diversity of information) affect models outputs. In this work, we investigate how hallucinations manifest in LLMs when summarizing topic-specific information from multiple documents. Since no benchmarks exist for investigating hallucinations in MDS, we use existing news and conversation datasets, annotated with topic-specific insights, to create two novel multi-document benchmarks. When evaluating 5 LLMs on our benchmarks, we observe that on average, up to 75% of the content in LLM-generated summary is hallucinated, with hallucinations more likely to occur towards the end of the summaries. Moreover, when summarizing non-existent topic-related information, gpt-3.5-turbo and GPT-4o still generate summaries about 79.35% and 44% of the time, raising concerns about their tendency to fabricate content. To understand the characteristics of these hallucinations, we manually evaluate 700+ insights and find that most errors stem from either failing to follow instructions or producing overly generic insights. Motivated by these observations, we investigate the efficacy of simple post-hoc baselines in mitigating hallucinations but find them only moderately effective. Our results underscore the need for more effective approaches to systematically mitigate hallucinations in MDS. We release our dataset and code at github.com/megagonlabs/Hallucination_MDS.
Holistic Reasoning with Long-Context LMs: A Benchmark for Database Operations on Massive Textual Data
Oct 15, 2024



The rapid increase in textual information means we need more efficient methods to sift through, organize, and understand it all. While retrieval-augmented generation (RAG) models excel in accessing information from large document collections, they struggle with complex tasks that require aggregation and reasoning over information spanning across multiple documents--what we call holistic reasoning. Long-context language models (LCLMs) have great potential for managing large-scale documents, but their holistic reasoning capabilities remain unclear. In this work, we introduce HoloBench, a novel framework that brings database reasoning operations into text-based contexts, making it easier to systematically evaluate how LCLMs handle holistic reasoning across large documents. Our approach adjusts key factors such as context length, information density, distribution of information, and query complexity to evaluate LCLMs comprehensively. Our experiments show that the amount of information in the context has a bigger influence on LCLM performance than the actual context length. Furthermore, the complexity of queries affects performance more than the amount of information, particularly for different types of queries. Interestingly, queries that involve finding maximum or minimum values are easier for LCLMs and are less affected by context length, even though they pose challenges for RAG systems. However, tasks requiring the aggregation of multiple pieces of information show a noticeable drop in accuracy as context length increases. Additionally, we find that while grouping relevant information generally improves performance, the optimal positioning varies across models. Our findings surface both the advancements and the ongoing challenges in achieving a holistic understanding of long contexts.
Retrieval Helps or Hurts? A Deeper Dive into the Efficacy of Retrieval Augmentation to Language Models
Feb 21, 2024While large language models (LMs) demonstrate remarkable performance, they encounter challenges in providing accurate responses when queried for information beyond their pre-trained memorization. Although augmenting them with relevant external information can mitigate these issues, failure to consider the necessity of retrieval may adversely affect overall performance. Previous research has primarily focused on examining how entities influence retrieval models and knowledge recall in LMs, leaving other aspects relatively unexplored. In this work, our goal is to offer a more detailed, fact-centric analysis by exploring the effects of combinations of entities and relations. To facilitate this, we construct a new question answering (QA) dataset called WiTQA (Wikipedia Triple Question Answers). This dataset includes questions about entities and relations of various popularity levels, each accompanied by a supporting passage. Our extensive experiments with diverse LMs and retrievers reveal when retrieval does not consistently enhance LMs from the viewpoints of fact-centric popularity.Confirming earlier findings, we observe that larger LMs excel in recalling popular facts. However, they notably encounter difficulty with infrequent entity-relation pairs compared to retrievers. Interestingly, they can effectively retain popular relations of less common entities. We demonstrate the efficacy of our finer-grained metric and insights through an adaptive retrieval system that selectively employs retrieval and recall based on the frequencies of entities and relations in the question.
Why Using Either Aggregated Features or Adjacency Lists in Directed or Undirected Graph? Empirical Study and Simple Classification Method
Jun 14, 2023Node classification is one of the hottest tasks in graph analysis. In this paper, we focus on the choices of node representations (aggregated features vs. adjacency lists) and the edge direction of an input graph (directed vs. undirected), which have a large influence on classification results. We address the first empirical study to benchmark the performance of various GNNs that use either combination of node representations and edge directions. Our experiments demonstrate that no single combination stably achieves state-of-the-art results across datasets, which indicates that we need to select appropriate combinations depending on the characteristics of datasets. In response, we propose a simple yet holistic classification method A2DUG which leverages all combinations of node representation variants in directed and undirected graphs. We demonstrate that A2DUG stably performs well on various datasets. Surprisingly, it largely outperforms the current state-of-the-art methods in several datasets. This result validates the importance of the adaptive effect control on the combinations of node representations and edge directions.
GNN Transformation Framework for Improving Efficiency and Scalability
Jul 25, 2022
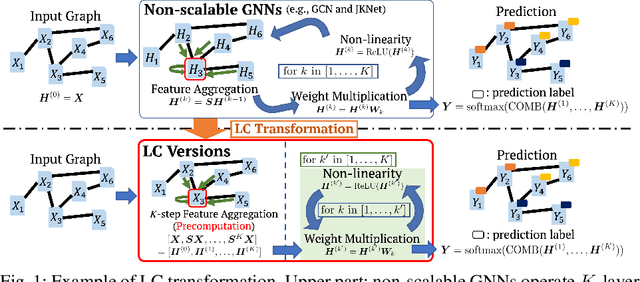
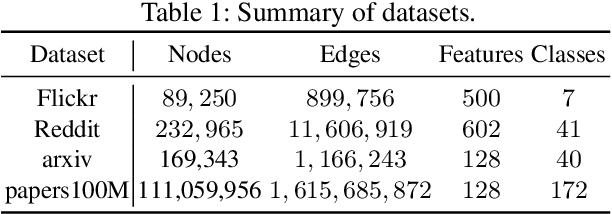
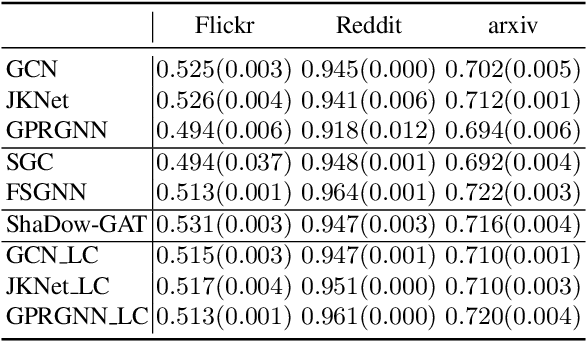
We propose a framework that automatically transforms non-scalable GNNs into precomputation-based GNNs which are efficient and scalable for large-scale graphs. The advantages of our framework are two-fold; 1) it transforms various non-scalable GNNs to scale well to large-scale graphs by separating local feature aggregation from weight learning in their graph convolution, 2) it efficiently executes precomputation on GPU for large-scale graphs by decomposing their edges into small disjoint and balanced sets. Through extensive experiments with large-scale graphs, we demonstrate that the transformed GNNs run faster in training time than existing GNNs while achieving competitive accuracy to the state-of-the-art GNNs. Consequently, our transformation framework provides simple and efficient baselines for future research on scalable GNNs.
Beyond Real-world Benchmark Datasets: An Empirical Study of Node Classification with GNNs
Jun 18, 2022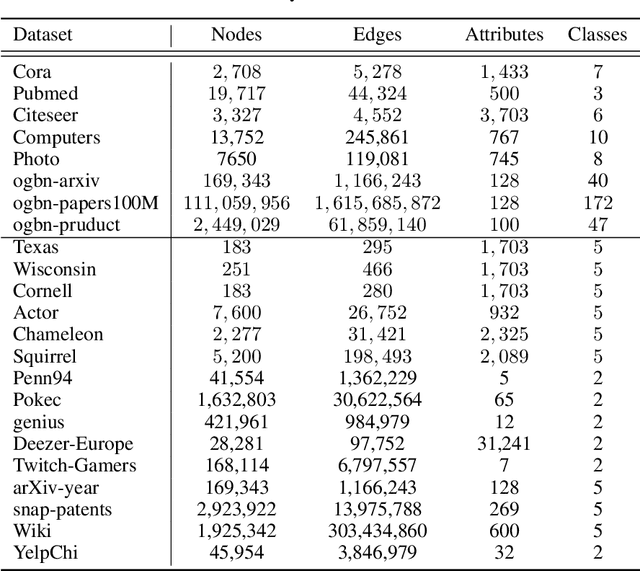
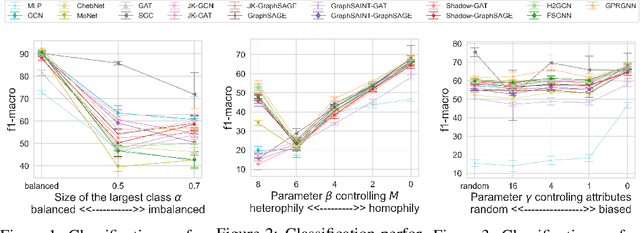

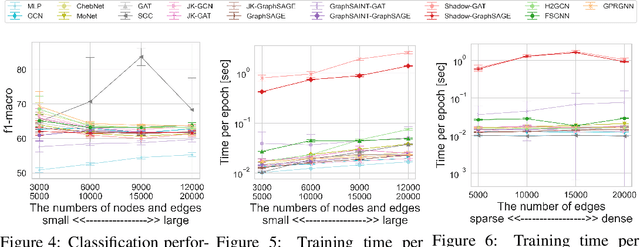
Graph Neural Networks (GNNs) have achieved great success on a node classification task. Despite the broad interest in developing and evaluating GNNs, they have been assessed with limited benchmark datasets. As a result, the existing evaluation of GNNs lacks fine-grained analysis from various characteristics of graphs. Motivated by this, we conduct extensive experiments with a synthetic graph generator that can generate graphs having controlled characteristics for fine-grained analysis. Our empirical studies clarify the strengths and weaknesses of GNNs from four major characteristics of real-world graphs with class labels of nodes, i.e., 1) class size distributions (balanced vs. imbalanced), 2) edge connection proportions between classes (homophilic vs. heterophilic), 3) attribute values (biased vs. random), and 4) graph sizes (small vs. large). In addition, to foster future research on GNNs, we publicly release our codebase that allows users to evaluate various GNNs with various graphs. We hope this work offers interesting insights for future research.