 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-Agnostic Multi-Object Navigation
May 10, 2023The Multi-Object Navigation (MultiON) task requires a robot to localize an instance (each) of multiple object classes. It is a fundamental task for an assistive robot in a home or a factory. Existing methods for MultiON have viewed this as a direct extension of Object Navigation (ON), the task of localising an instance of one object class, and are pre-sequenced, i.e., the sequence in which the object classes are to be explored is provided in advance. This is a strong limitation in practical applications characterized by dynamic changes. This paper describes a deep reinforcement learning framework for sequence-agnostic MultiON based on an actor-critic architecture and a suitable reward specification. Our framework leverages past experiences and seeks to reward progress toward individual as well as multiple target object classes. We use photo-realistic scenes from the Gibson benchmark dataset in the AI Habitat 3D simulation environment to experimentally show that our method performs better than a pre-sequenced approach and a state of the art ON method extended to MultiON.
Toward a Framework for Adaptive ImpedancenControl of an Upper-limb Prosthesis
Sep 11, 2022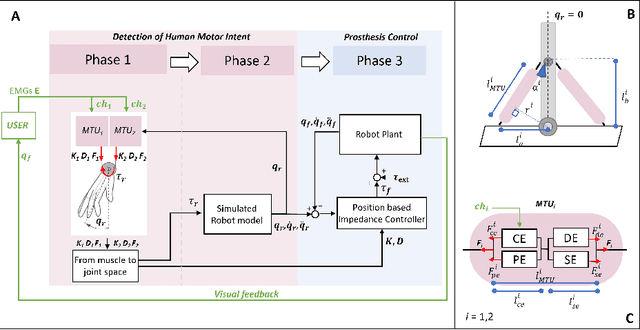
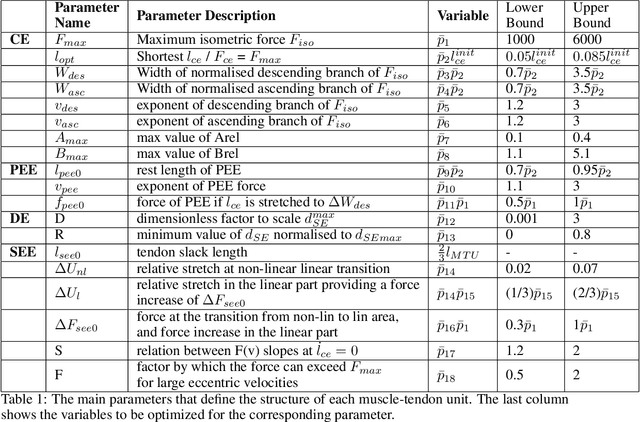
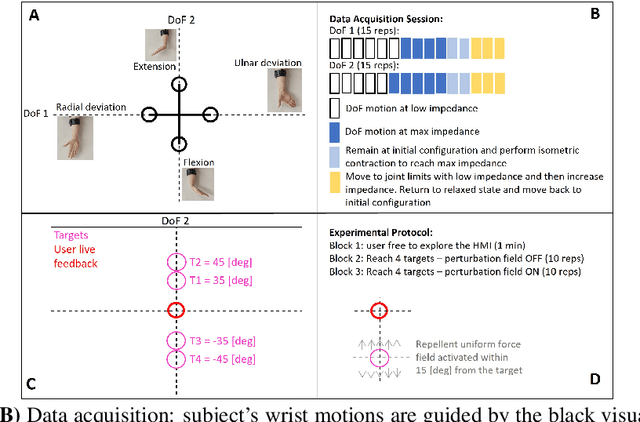
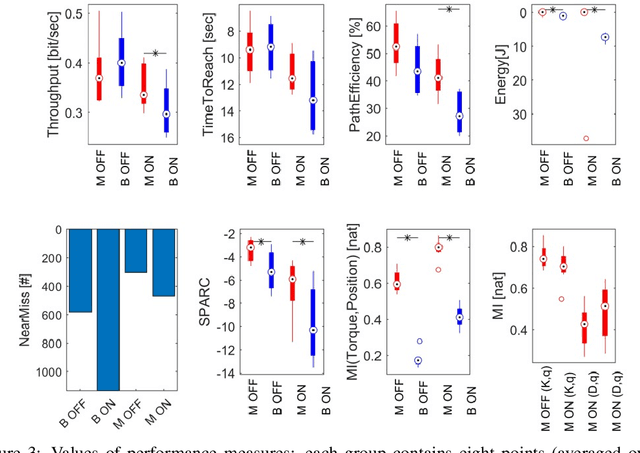
This paper describes a novel framework for a human-machine interface that can be used to control an upper-limb prosthesis. The objective is to estimate the human's motor intent from noisy surface electromyography signals and to execute the motor intent on the prosthesis (i.e., the robot) even in the presence of previously unseen perturbations. The framework includes muscle-tendon models for each degree of freedom, a method for learning the parameter values of models used to estimate the user's motor intent, and a variable impedance controller that uses the stiffness and damping values obtained from the muscle models to adapt the prosthesis' motion trajectory and dynamics. We experimentally evaluate our framework in the context of able-bodied humans using a simulated version of the human-machine interface to perform reaching tasks that primarily actuate one degree of freedom in the wrist, and consider external perturbations in the form of a uniform force field that pushes the wrist away from the target. We demonstrate that our framework provides the desired adaptive performance, and substantially improves performance in comparison with a data-driven baseline.
Spatial Relation Graph and Graph Convolutional Network for Object Goal Navigation
Aug 27, 2022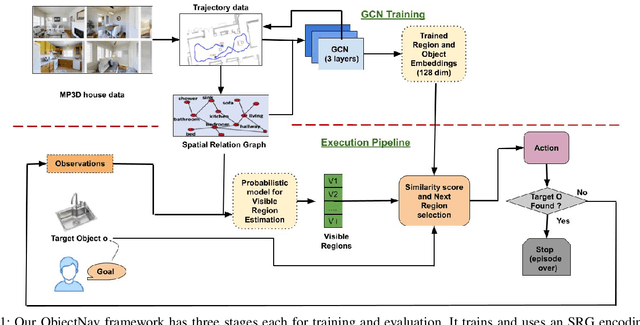
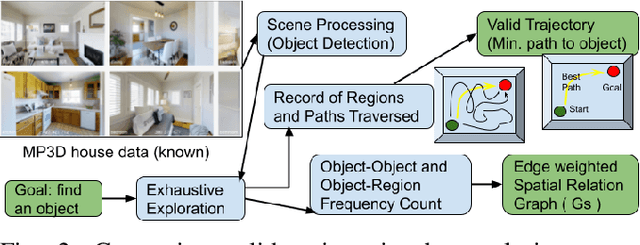
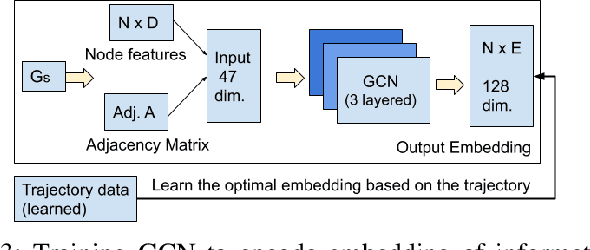
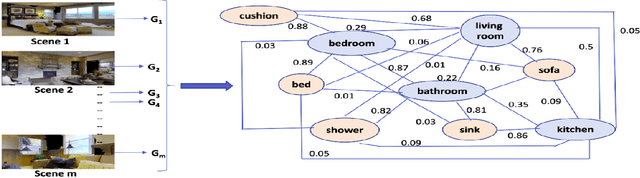
This paper describes a framework for the object-goal navigation task, which requires a robot to find and move to the closest instance of a target object class from a random starting position. The framework uses a history of robot trajectories to learn a Spatial Relational Graph (SRG) and Graph Convolutional Network (GCN)-based embeddings for the likelihood of proximity of different semantically-labeled regions and the occurrence of different object classes in these regions. To locate a target object instance during evaluation, the robot uses Bayesian inference and the SRG to estimate the visible regions, and uses the learned GCN embeddings to rank visible regions and select the region to explore next.
Object Goal Navigation using Data Regularized Q-Learning
Aug 27, 2022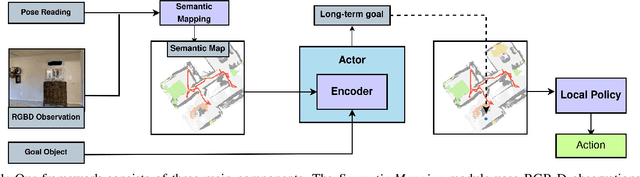
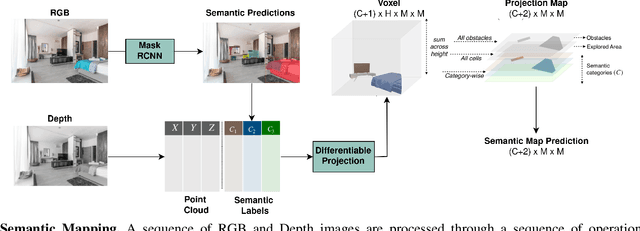
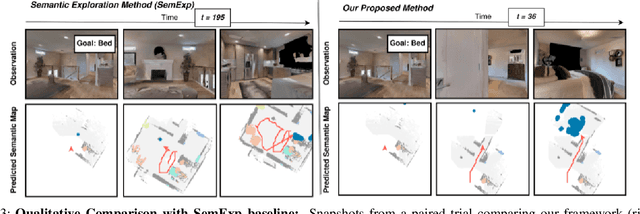

Object Goal Navigation requires a robot to find and navigate to an instance of a target object class in a previously unseen environment. Our framework incrementally builds a semantic map of the environment over time, and then repeatedly selects a long-term goal ('where to go') based on the semantic map to locate the target object instance. Long-term goal selection is formulated as a vision-based deep reinforcement learning problem. Specifically, an Encoder Network is trained to extract high-level features from a semantic map and select a long-term goal. In addition, we incorporate data augmentation and Q-function regularization to make the long-term goal selection more effective. We report experimental results using the photo-realistic Gibson benchmark dataset in the AI Habitat 3D simulation environment to demonstrate substantial performance improvement on standard measures in comparison with a state of the art data-driven baseline.
Toward a Reasoning and Learning Architecture for Ad Hoc Teamwork
Aug 24, 2022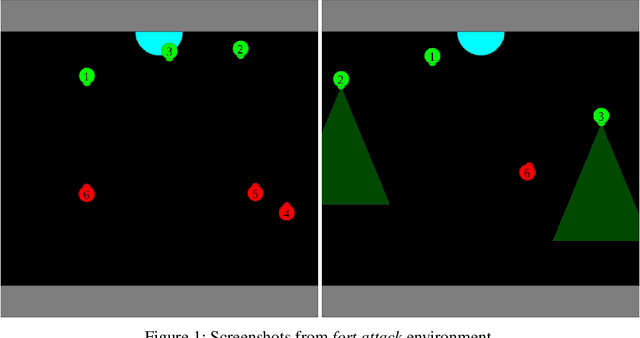

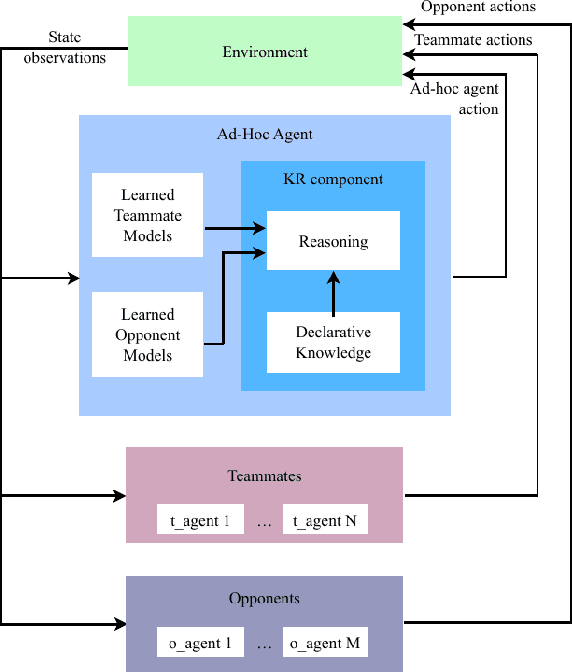
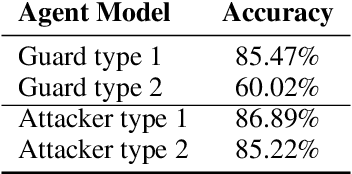
We present an architecture for ad hoc teamwork, which refers to collaboration in a team of agents without prior coordination. State of the art methods for this problem often include a data-driven component that uses a long history of prior observations to model the behaviour of other agents (or agent types) and to determine the ad hoc agent's behavior. In many practical domains, it is challenging to find large training datasets, and necessary to understand and incrementally extend the existing models to account for changes in team composition or domain attributes. Our architecture combines the principles of knowledge-based and data-driven reasoning and learning. Specifically, we enable an ad hoc agent to perform non-monotonic logical reasoning with prior commonsense domain knowledge and incrementally-updated simple predictive models of other agents' behaviour. We use the benchmark simulated multiagent collaboration domain Fort Attack to demonstrate that our architecture supports adaptation to unforeseen changes, incremental learning and revision of models of other agents' behaviour from limited samples, transparency in the ad hoc agent's decision making, and better performance than a data-driven baseline.
BURG-Toolkit: Robot Grasping Experiments in Simulation and the Real World
May 27, 2022
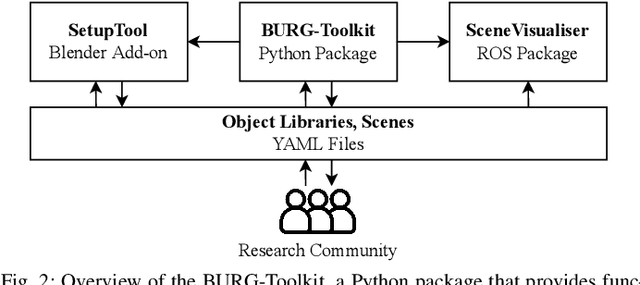

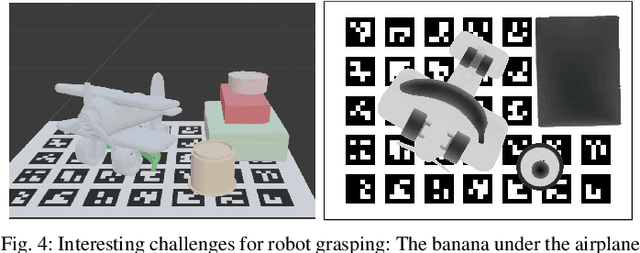
This paper presents BURG-Toolkit, a set of open-source tools for Benchmarking and Understanding Robotic Grasping. Our tools allow researchers to: (1) create virtual scenes for generating training data and performing grasping in simulation; (2) recreate the scene by arranging the corresponding objects accurately in the physical world for real robot experiments, supporting an analysis of the sim-to-real gap; and (3) share the scenes with other researchers to foster comparability and reproducibility of experimental results. We explain how to use our tools by describing some potential use cases. We further provide proof-of-concept experimental results quantifying the sim-to-real gap for robot grasping in some example scenes. The tools are available at: https://mrudorfer.github.io/burg-toolkit/
Generating Task-specific Robotic Grasps
Mar 20, 2022

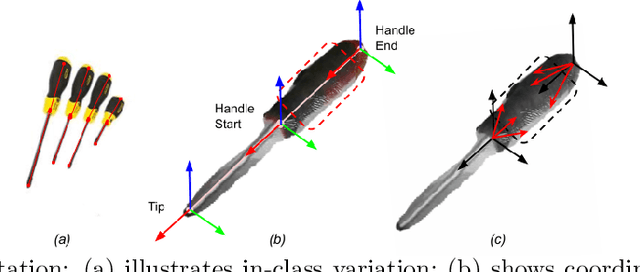
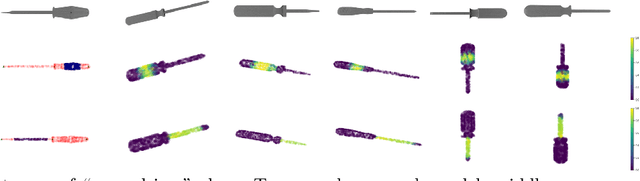
This paper describes a method for generating robot grasps by jointly considering stability and other task and object-specific constraints. We introduce a three-level representation that is acquired for each object class from a small number of exemplars of objects, tasks, and relevant grasps. The representation encodes task-specific knowledge for each object class as a relationship between a keypoint skeleton and suitable grasp points that is preserved despite intra-class variations in scale and orientation. The learned models are queried at run time by a simple sampling-based method to guide the generation of grasps that balance task and stability constraints. We ground and evaluate our method in the context of a Franka Emika Panda robot assisting a human in picking tabletop objects for which the robot does not have prior CAD models. Experimental results demonstrate that in comparison with a baseline method that only focuses on stability, our method is able to provide suitable grasps for different tasks.
A Survey of Ad Hoc Teamwork: Definitions, Methods, and Open Problems
Feb 16, 2022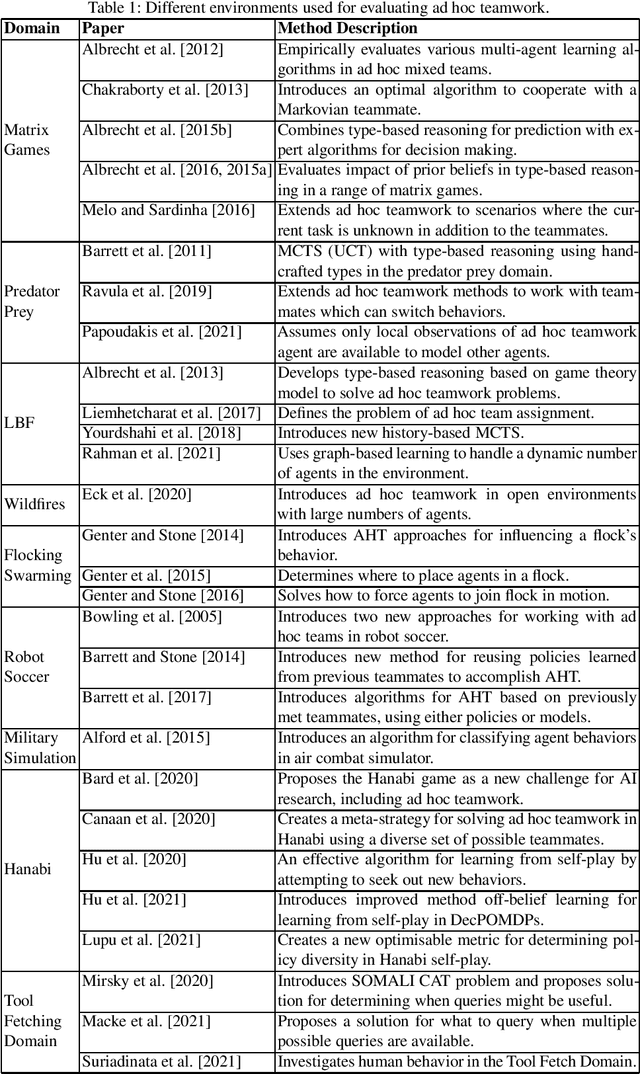
Ad hoc teamwork is the well-established research problem of designing agents that can collaborate with new teammates without prior coordination. This survey makes a two-fold contribution. First, it provides a structured description of the different facets of the ad hoc teamwork problem. Second, it discusses the progress that has been made in the field so far, and identifies the immediate and long-term open problems that need to be addressed in the field of ad hoc teamwork.
Combining Commonsense Reasoning and Knowledge Acquisition to Guide Deep Learning in Robotics
Jan 25, 2022
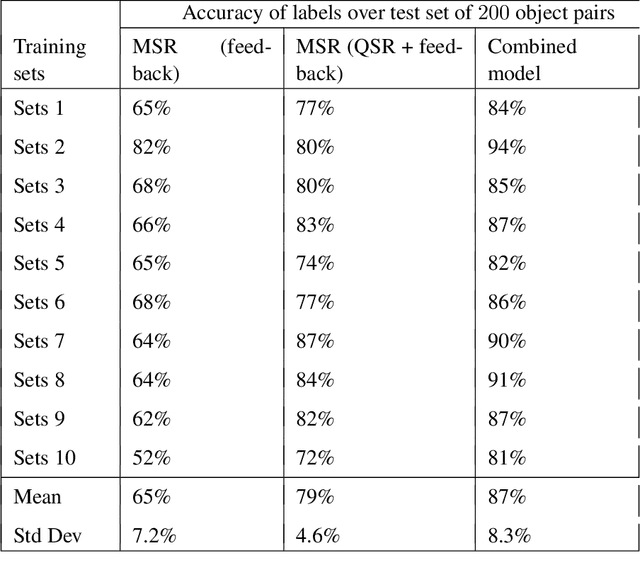
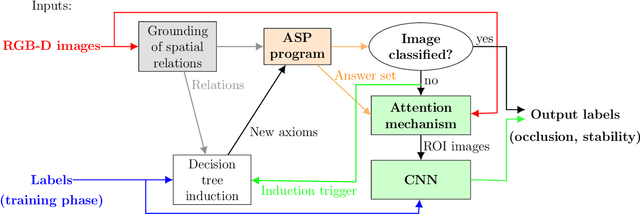

Algorithms based on deep network models are being used for many pattern recognition and decision-making tasks in robotics and AI. Training these models requires a large labeled dataset and considerable computational resources, which are not readily available in many domains. Also, it is difficult to explore the internal representations and reasoning mechanisms of these models. As a step towards addressing the underlying knowledge representation, reasoning, and learning challenges, the architecture described in this paper draws inspiration from research in cognitive systems. As a motivating example, we consider an assistive robot trying to reduce clutter in any given scene by reasoning about the occlusion of objects and stability of object configurations in an image of the scene. In this context, our architecture incrementally learns and revises a grounding of the spatial relations between objects and uses this grounding to extract spatial information from input images. Non-monotonic logical reasoning with this information and incomplete commonsense domain knowledge is used to make decisions about stability and occlusion. For images that cannot be processed by such reasoning, regions relevant to the tasks at hand are automatically identified and used to train deep network models to make the desired decisions. Image regions used to train the deep networks are also used to incrementally acquire previously unknown state constraints that are merged with the existing knowledge for subsequent reasoning. Experimental evaluation performed using simulated and real-world images indicates that in comparison with baselines based just on deep networks, our architecture improves reliability of decision making and reduces the effort involved in training data-driven deep network models.
The Ninth Advances in Cognitive Systems (ACS) Conference
Jan 16, 2022ACS is an annual meeting for research on the initial goals of artificial intelligence and cognitive science, which aimed to explain the mind in computational terms and to reproduce the entire range of human cognitive abilities in computational artifacts. Many researchers remain committed to this original vision, and Advances in Cognitive Systems provides a place to present recent results and pose new challenges for the field. The meetings bring together researchers with interests in human-level intelligence, complex cognition, integrated intelligent systems, cognitive architectures, and related topics.