 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Collection of Medical Image Datasets for Deep Learning
Jun 24, 2021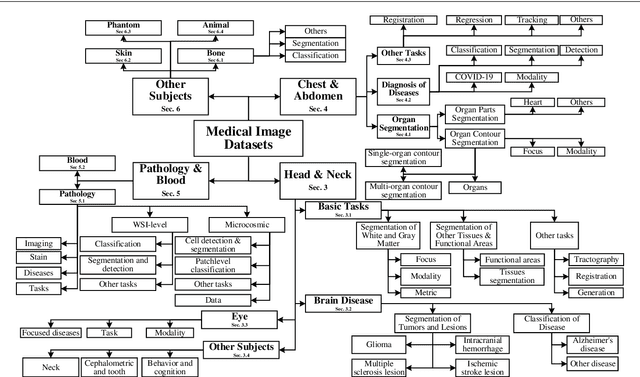
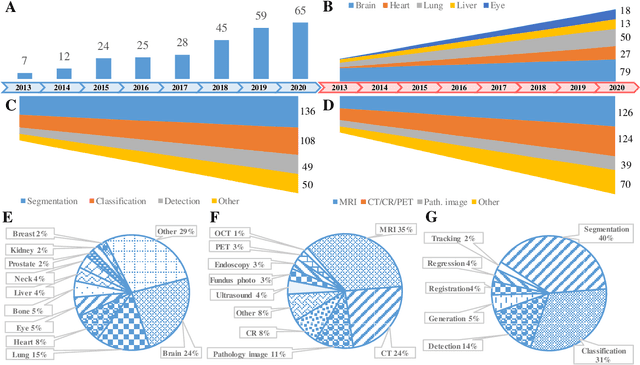
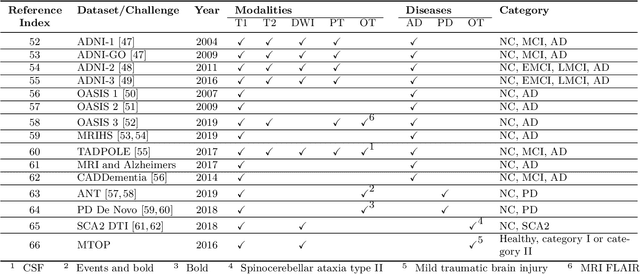
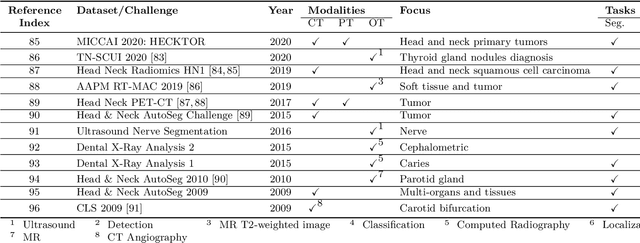
The astounding success made by artificial intelligence (AI) in healthcare and other fields proves that AI can achieve human-like performance. However, success always comes with challenges. Deep learning algorithms are data-dependent and require large datasets for training. The lack of data in the medical imaging field creates a bottleneck for the application of deep learning to medical image analysis. Medical image acquisition, annotation, and analysis are costly, and their usage is constrained by ethical restrictions. They also require many resources, such as human expertise and funding. That makes it difficult for non-medical researchers to have access to useful and large medical data. Thus, as comprehensive as possible, this paper provides a collection of medical image datasets with their associated challenges for deep learning research. We have collected information of around three hundred datasets and challenges mainly reported between 2013 and 2020 and categorized them into four categories: head & neck, chest & abdomen, pathology & blood, and ``others''. Our paper has three purposes: 1) to provide a most up to date and complete list that can be used as a universal reference to easily find the datasets for clinical image analysis, 2) to guide researchers on the methodology to test and evaluate their methods' performance and robustness on relevant datasets, 3) to provide a ``route'' to relevant algorithms for the relevant medical topics, and challenge leaderboards.
CAMERAS: Enhanced Resolution And Sanity preserving Class Activation Mapping for image saliency
Jun 20, 2021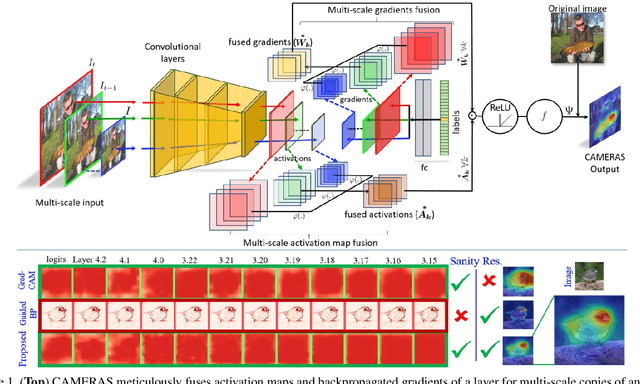
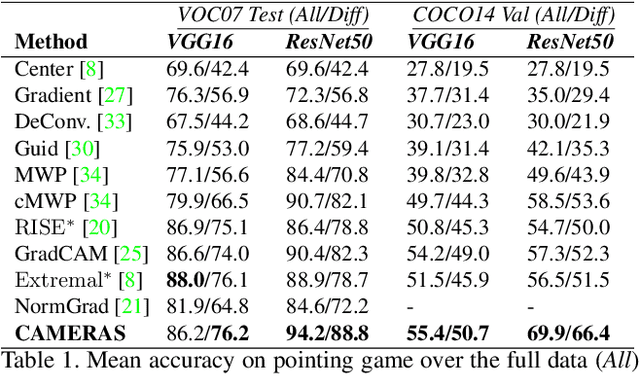
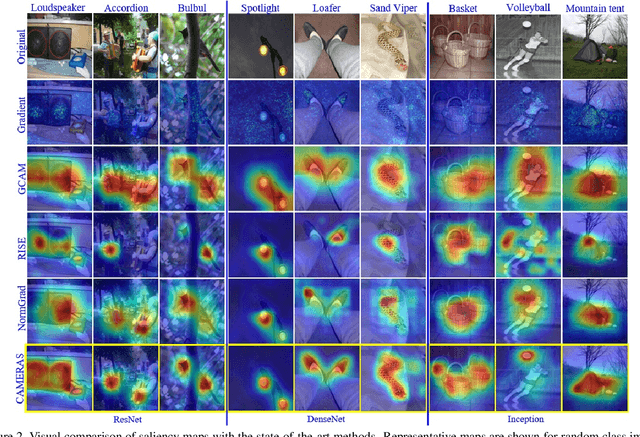
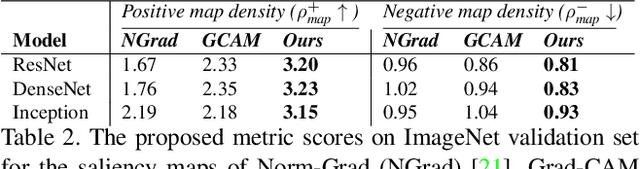
Backpropagation image saliency aims at explaining model predictions by estimating model-centric importance of individual pixels in the input. However, class-insensitivity of the earlier layers in a network only allows saliency computation with low resolution activation maps of the deeper layers, resulting in compromised image saliency. Remedifying this can lead to sanity failures. We propose CAMERAS, a technique to compute high-fidelity backpropagation saliency maps without requiring any external priors and preserving the map sanity. Our method systematically performs multi-scale accumulation and fusion of the activation maps and backpropagated gradients to compute precise saliency maps. From accurate image saliency to articulation of relative importance of input features for different models, and precise discrimination between model perception of visually similar objects, our high-resolution mapping offers multiple novel insights into the black-box deep visual models, which are presented in the paper. We also demonstrate the utility of our saliency maps in adversarial setup by drastically reducing the norm of attack signals by focusing them on the precise regions identified by our maps. Our method also inspires new evaluation metrics and a sanity check for this developing research direction. Code is available here https://github.com/VisMIL/CAMERAS
Attack to Fool and Explain Deep Networks
Jun 20, 2021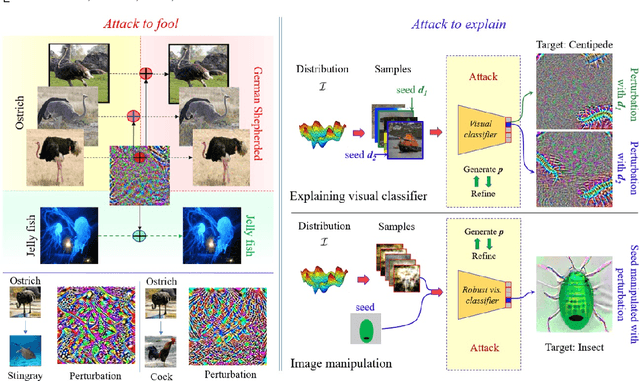
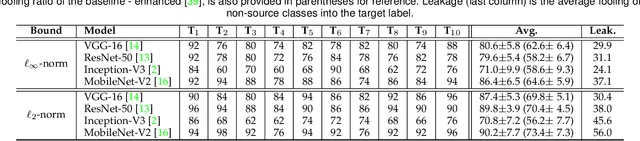
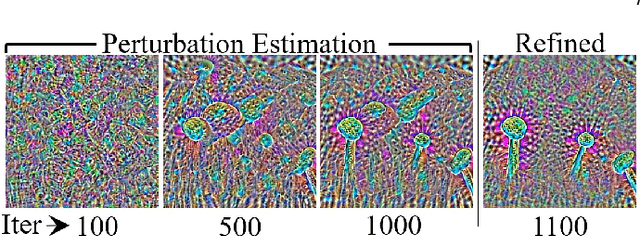
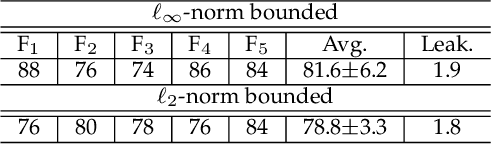
Deep visual models are susceptible to adversarial perturbations to inputs. Although these signals are carefully crafted, they still appear noise-like patterns to humans. This observation has led to the argument that deep visual representation is misaligned with human perception. We counter-argue by providing evidence of human-meaningful patterns in adversarial perturbations. We first propose an attack that fools a network to confuse a whole category of objects (source class) with a target label. Our attack also limits the unintended fooling by samples from non-sources classes, thereby circumscribing human-defined semantic notions for network fooling. We show that the proposed attack not only leads to the emergence of regular geometric patterns in the perturbations, but also reveals insightful information about the decision boundaries of deep models. Exploring this phenomenon further, we alter the `adversarial' objective of our attack to use it as a tool to `explain' deep visual representation. We show that by careful channeling and projection of the perturbations computed by our method, we can visualize a model's understanding of human-defined semantic notions. Finally, we exploit the explanability properties of our perturbations to perform image generation, inpainting and interactive image manipulation by attacking adversarialy robust `classifiers'.In all, our major contribution is a novel pragmatic adversarial attack that is subsequently transformed into a tool to interpret the visual models. The article also makes secondary contributions in terms of establishing the utility of our attack beyond the adversarial objective with multiple interesting applications.
q-RBFNN:A Quantum Calculus-based RBF Neural Network
Jun 02, 2021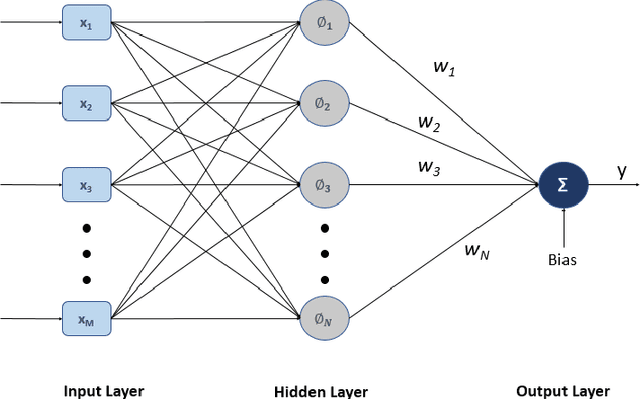
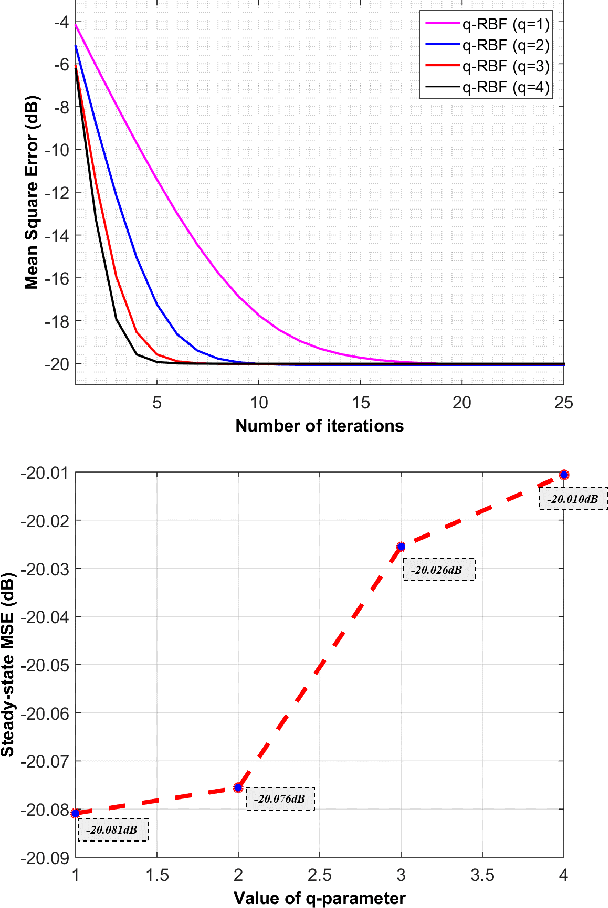
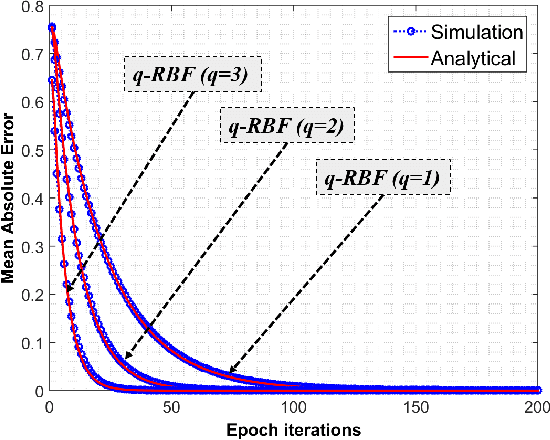
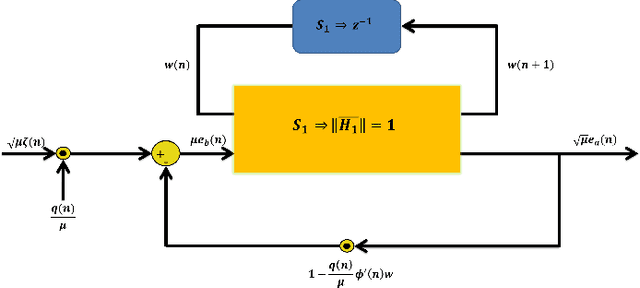
In this research a novel stochastic gradient descent based learning approach for the radial basis function neural networks (RBFNN) is proposed. The proposed method is based on the q-gradient which is also known as Jackson derivative. In contrast to the conventional gradient, which finds the tangent, the q-gradient finds the secant of the function and takes larger steps towards the optimal solution. The proposed $q$-RBFNN is analyzed for its convergence performance in the context of least square algorithm. In particular, a closed form expression of the Wiener solution is obtained, and stability bounds of the learning rate (step-size) is derived. The analytical results are validated through computer simulation. Additionally, we propose an adaptive technique for the time-varying $q$-parameter to improve convergence speed with no trade-offs in the steady state performance.
HIN-RNN: A Graph Representation Learning Neural Network for Fraudster Group Detection With No Handcrafted Features
May 25, 2021



Social reviews are indispensable resources for modern consumers' decision making. For financial gain, companies pay fraudsters preferably in groups to demote or promote products and services since consumers are more likely to be misled by a large number of similar reviews from groups. Recent approaches on fraudster group detection employed handcrafted features of group behaviors without considering the semantic relation between reviews from the reviewers in a group. In this paper, we propose the first neural approach, HIN-RNN, a Heterogeneous Information Network (HIN) Compatible RNN for fraudster group detection that requires no handcrafted features. HIN-RNN provides a unifying architecture for representation learning of each reviewer, with the initial vector as the sum of word embeddings of all review text written by the same reviewer, concatenated by the ratio of negative reviews. Given a co-review network representing reviewers who have reviewed the same items with the same ratings and the reviewers' vector representation, a collaboration matrix is acquired through HIN-RNN training. The proposed approach is confirmed to be effective with marked improvement over state-of-the-art approaches on both the Yelp (22% and 12% in terms of recall and F1-value, respectively) and Amazon (4% and 2% in terms of recall and F1-value, respectively) datasets.
Human Action Recognition from Various Data Modalities: A Review
Jan 29, 2021
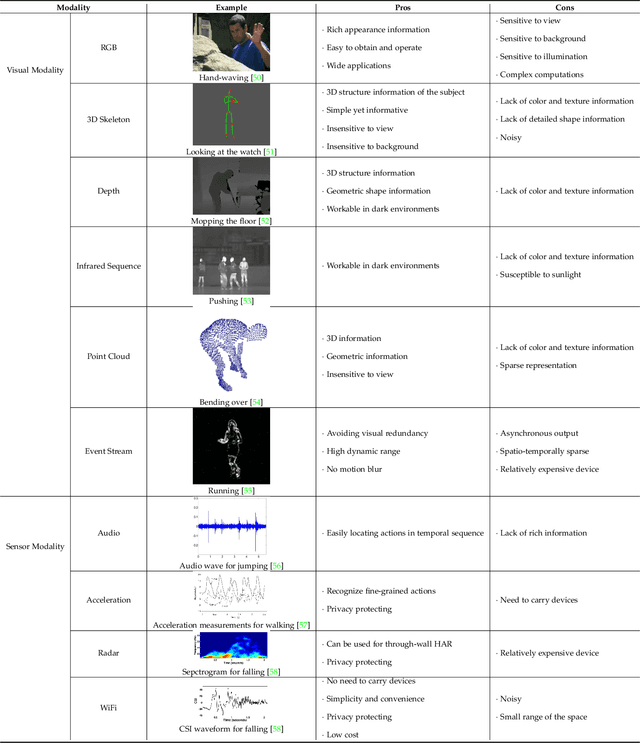

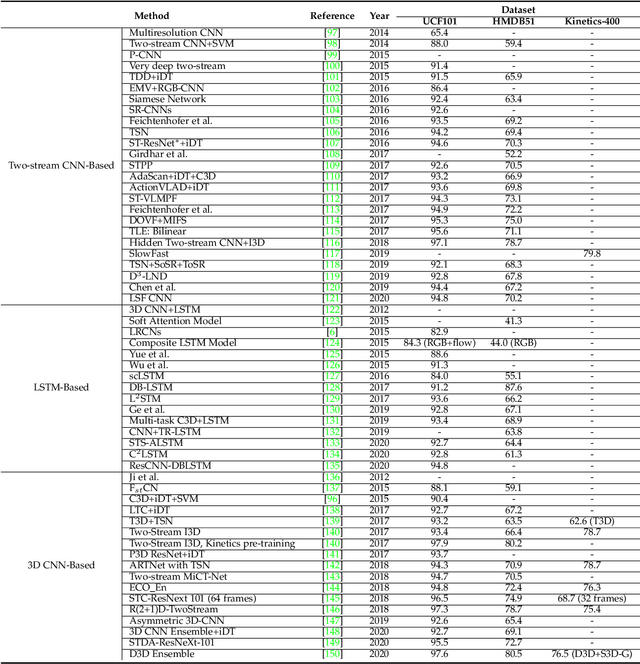
Human Action Recognition (HAR) aims to understand human behavior and assign a label to each action. It has a wide range of applications, and therefore has been attracting increasing attention in the field of computer vision. Human actions can be represented using various data modalities, such as RGB, skeleton, depth, infrared, point cloud, event stream, audio, acceleration, radar, and WiFi signal, which encode different sources of useful yet distinct information and have various advantages depending on the application scenarios. Consequently, lots of existing works have attempted to investigate different types of approaches for HAR using various modalities. In this paper, we present a comprehensive survey of recent progress in deep learning methods for HAR based on the type of input data modality. Specifically, we review the current mainstream deep learning methods for single data modalities and multiple data modalities, including the fusion-based and the co-learning-based frameworks. We also present comparative results on several benchmark datasets for HAR, together with insightful observations and inspiring future research directions.
4D Atlas: Statistical Analysis of the Spatiotemporal Variability in Longitudinal 3D Shape Data
Jan 23, 2021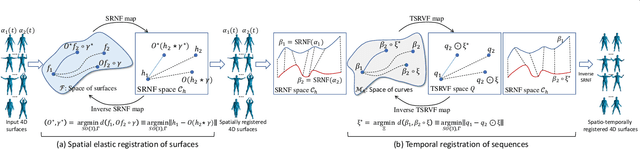
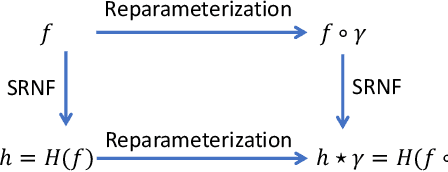
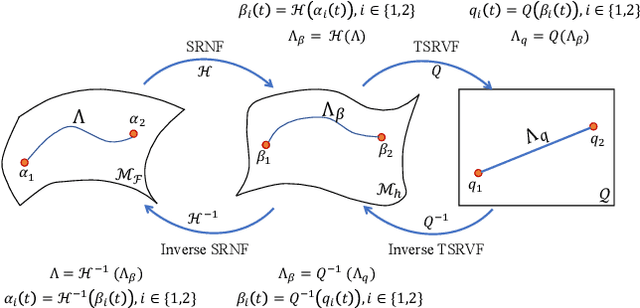

We propose a novel framework to learn the spatiotemporal variability in longitudinal 3D shape data sets, which contain observations of subjects that evolve and deform over time. This problem is challenging since surfaces come with arbitrary spatial and temporal parameterizations. Thus, they need to be spatially registered and temporally aligned onto each other. We solve this spatiotemporal registration problem using a Riemannian approach. We treat a 3D surface as a point in a shape space equipped with an elastic metric that measures the amount of bending and stretching that the surfaces undergo. A 4D surface can then be seen as a trajectory in this space. With this formulation, the statistical analysis of 4D surfaces becomes the problem of analyzing trajectories embedded in a nonlinear Riemannian manifold. However, computing spatiotemporal registration and statistics on nonlinear spaces relies on complex nonlinear optimizations. Our core contribution is the mapping of the surfaces to the space of Square-Root Normal Fields (SRNF) where the L2 metric is equivalent to the partial elastic metric in the space of surfaces. By solving the spatial registration in the SRNF space, analyzing 4D surfaces becomes the problem of analyzing trajectories embedded in the SRNF space, which is Euclidean. Here, we develop the building blocks that enable such analysis. These include the spatiotemporal registration of arbitrarily parameterized 4D surfaces even in the presence of large elastic deformations and large variations in their execution rates, the computation of geodesics between 4D surfaces, the computation of statistical summaries, such as means and modes of variation, and the synthesis of random 4D surfaces. We demonstrate the performance of the proposed framework using 4D facial surfaces and 4D human body shapes.
Dynamic Facial Expression Recognition under Partial Occlusion with Optical Flow Reconstruction
Dec 24, 2020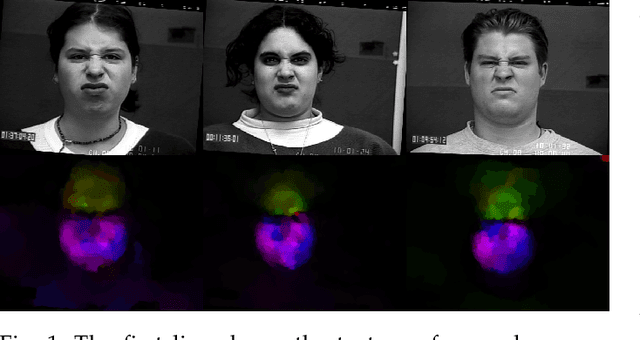
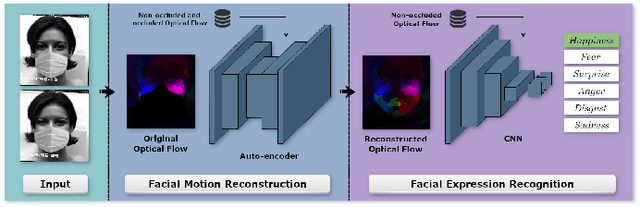
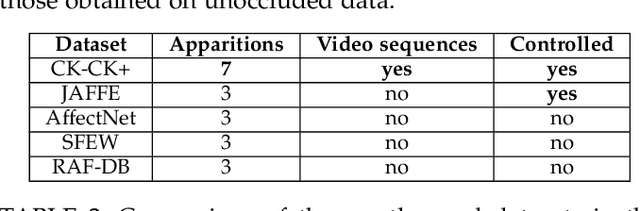
Video facial expression recognition is useful for many applications and received much interest lately. Although some solutions give really good results in a controlled environment (no occlusion), recognition in the presence of partial facial occlusion remains a challenging task. To handle occlusions, solutions based on the reconstruction of the occluded part of the face have been proposed. These solutions are mainly based on the texture or the geometry of the face. However, the similarity of the face movement between different persons doing the same expression seems to be a real asset for the reconstruction. In this paper we exploit this asset and propose a new solution based on an auto-encoder with skip connections to reconstruct the occluded part of the face in the optical flow domain. To the best of our knowledge, this is the first proposition to directly reconstruct the movement for facial expression recognition. We validated our approach in the controlled dataset CK+ on which different occlusions were generated. Our experiments show that the proposed method reduce significantly the gap, in terms of recognition accuracy, between occluded and non-occluded situations. We also compare our approach with existing state-of-the-art solutions. In order to lay the basis of a reproducible and fair comparison in the future, we also propose a new experimental protocol that includes occlusion generation and reconstruction evaluation.
WEmbSim: A Simple yet Effective Metric for Image Captioning
Dec 24, 2020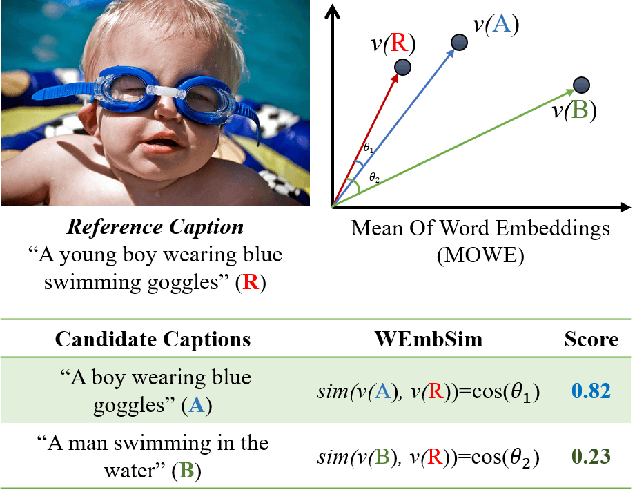
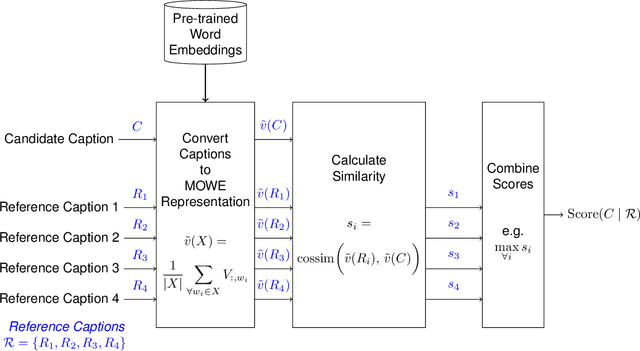

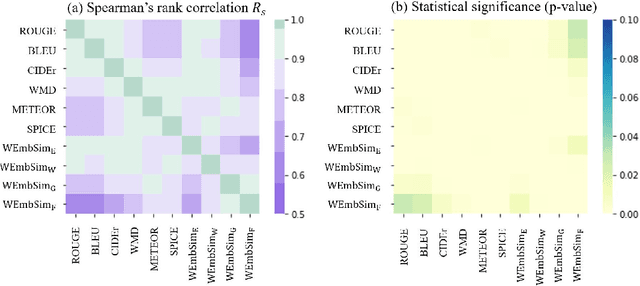
The area of automatic image caption evaluation is still undergoing intensive research to address the needs of generating captions which can meet adequacy and fluency requirements. Based on our past attempts at developing highly sophisticated learning-based metrics, we have discovered that a simple cosine similarity measure using the Mean of Word Embeddings(MOWE) of captions can actually achieve a surprisingly high performance on unsupervised caption evaluation. This inspires our proposed work on an effective metric WEmbSim, which beats complex measures such as SPICE, CIDEr and WMD at system-level correlation with human judgments. Moreover, it also achieves the best accuracy at matching human consensus scores for caption pairs, against commonly used unsupervised methods. Therefore, we believe that WEmbSim sets a new baseline for any complex metric to be justified.
* 7 pages
LCEval: Learned Composite Metric for Caption Evaluation
Dec 24, 2020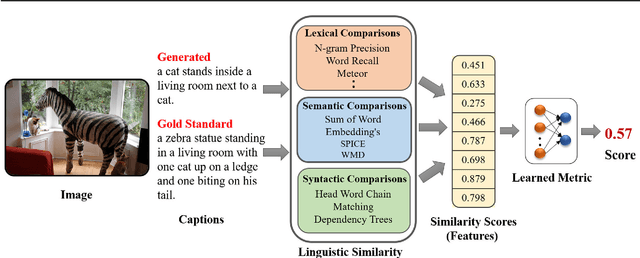

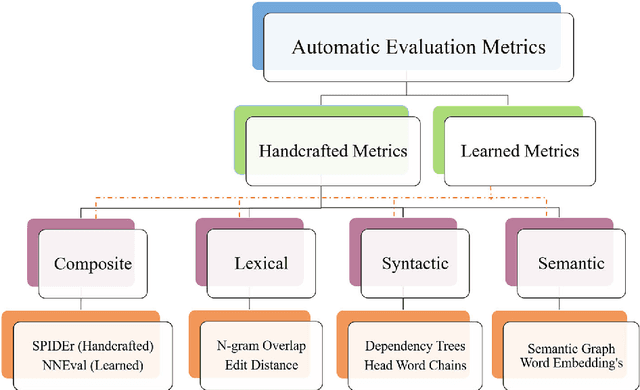
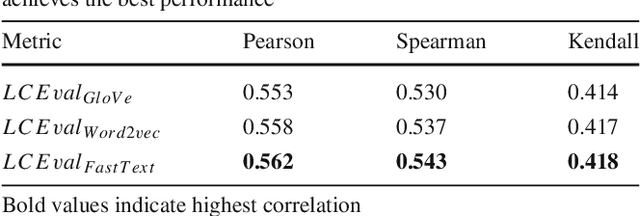
Automatic evaluation metrics hold a fundamental importance in the development and fine-grained analysis of captioning systems. While current evaluation metrics tend to achieve an acceptable correlation with human judgements at the system level, they fail to do so at the caption level. In this work, we propose a neural network-based learned metric to improve the caption-level caption evaluation. To get a deeper insight into the parameters which impact a learned metrics performance, this paper investigates the relationship between different linguistic features and the caption-level correlation of the learned metrics. We also compare metrics trained with different training examples to measure the variations in their evaluation. Moreover, we perform a robustness analysis, which highlights the sensitivity of learned and handcrafted metrics to various sentence perturbations. Our empirical analysis shows that our proposed metric not only outperforms the existing metrics in terms of caption-level correlation but it also shows a strong system-level correlation against human assessments.
* 18 pages