 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOTReg:Coupled Optimal Transport based Point Cloud Registration
Dec 29, 2021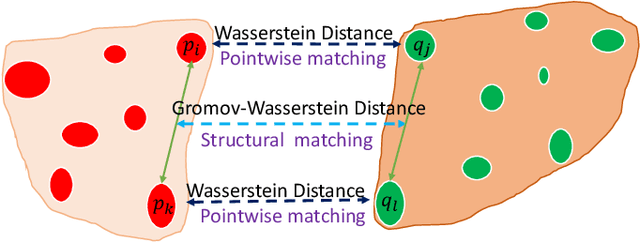

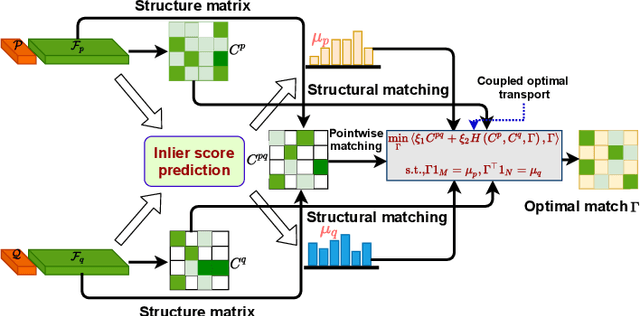
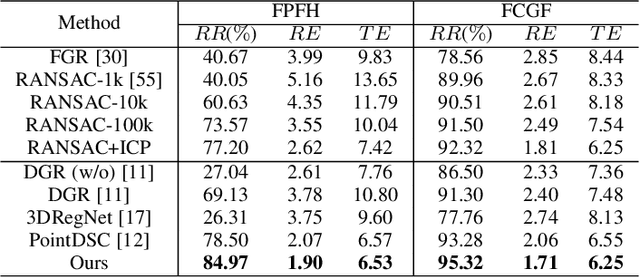
Generating a set of high-quality correspondences or matches is one of the most critical steps in point cloud registration. This paper proposes a learning framework COTReg by jointly considering the pointwise and structural matchings to predict correspondences of 3D point cloud registration. Specifically, we transform the two matchings into a Wasserstein distance-based and a Gromov-Wasserstein distance-based optimizations, respectively. Thus the task of establishing the correspondences can be naturally reshaped to a coupled optimal transport problem. Furthermore, we design a network to predict the confidence score of being an inlier for each point of the point clouds, which provides the overlap region information to generate correspondences. Our correspondence prediction pipeline can be easily integrated into either learning-based features like FCGF or traditional descriptors like FPFH. We conducted comprehensive experiments on 3DMatch, KITTI, 3DCSR, and ModelNet40 benchmarks, showing the state-of-art performance of the proposed method.
Explainable Artificial Intelligence for Pharmacovigilance: What Features Are Important When Predicting Adverse Outcomes?
Dec 25, 2021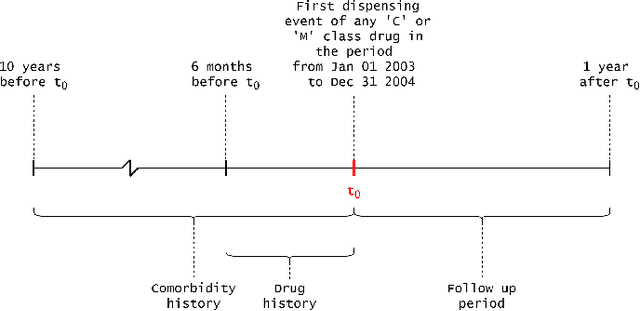

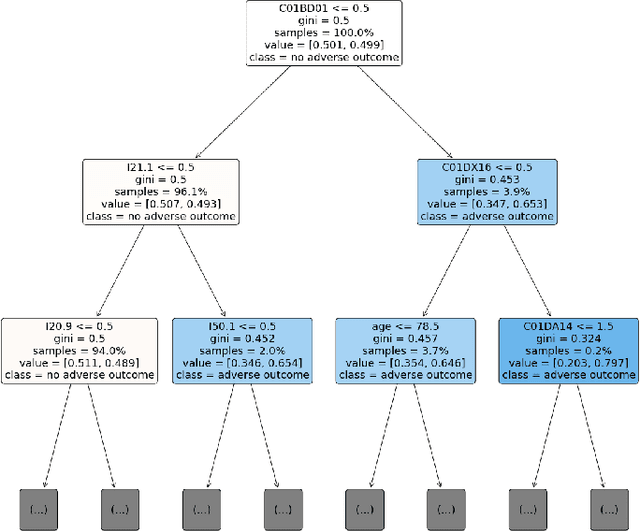
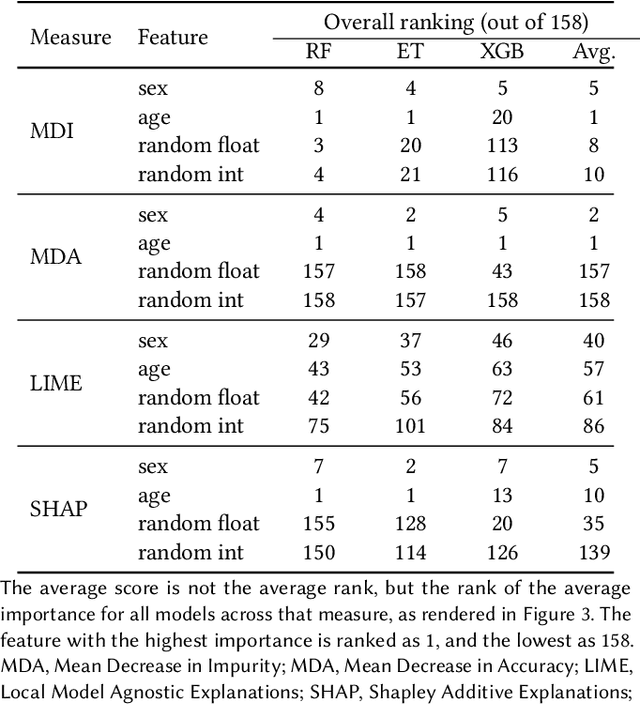
Explainable Artificial Intelligence (XAI) has been identified as a viable method for determining the importance of features when making predictions using Machine Learning (ML) models. In this study, we created models that take an individual's health information (e.g. their drug history and comorbidities) as inputs, and predict the probability that the individual will have an Acute Coronary Syndrome (ACS) adverse outcome. Using XAI, we quantified the contribution that specific drugs had on these ACS predictions, thus creating an XAI-based technique for pharmacovigilance monitoring, using ACS as an example of the adverse outcome to detect. Individuals aged over 65 who were supplied Musculo-skeletal system (anatomical therapeutic chemical (ATC) class M) or Cardiovascular system (ATC class C) drugs between 1993 and 2009 were identified, and their drug histories, comorbidities, and other key features were extracted from linked Western Australian datasets. Multiple ML models were trained to predict if these individuals would have an ACS related adverse outcome (i.e., death or hospitalisation with a discharge diagnosis of ACS), and a variety of ML and XAI techniques were used to calculate which features -- specifically which drugs -- led to these predictions. The drug dispensing features for rofecoxib and celecoxib were found to have a greater than zero contribution to ACS related adverse outcome predictions (on average), and it was found that ACS related adverse outcomes can be predicted with 72% accuracy. Furthermore, the XAI libraries LIME and SHAP were found to successfully identify both important and unimportant features, with SHAP slightly outperforming LIME. ML models trained on linked administrative health datasets in tandem with XAI algorithms can successfully quantify feature importance, and with further development, could potentially be used as pharmacovigilance monitoring techniques.
Generalized Closed-form Formulae for Feature-based Subpixel Alignment in Patch-based Matching
Dec 02, 2021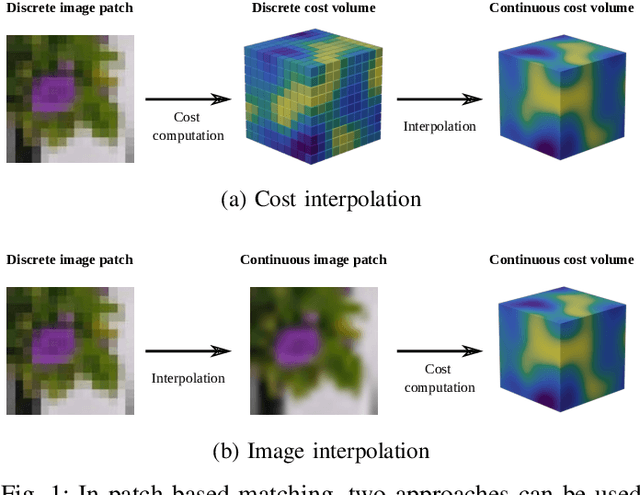

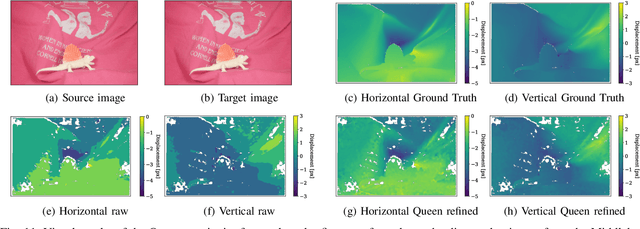
Cost-based image patch matching is at the core of various techniques in computer vision, photogrammetry and remote sensing. When the subpixel disparity between the reference patch in the source and target images is required, either the cost function or the target image have to be interpolated. While cost-based interpolation is the easiest to implement, multiple works have shown that image based interpolation can increase the accuracy of the subpixel matching, but usually at the cost of expensive search procedures. This, however, is problematic, especially for very computation intensive applications such as stereo matching or optical flow computation. In this paper, we show that closed form formulae for subpixel disparity computation for the case of one dimensional matching, e.g., in the case of rectified stereo images where the search space is of one dimension, exists when using the standard NCC, SSD and SAD cost functions. We then demonstrate how to generalize the proposed formulae to the case of high dimensional search spaces, which is required for unrectified stereo matching and optical flow extraction. We also compare our results with traditional cost volume interpolation formulae as well as with state-of-the-art cost-based refinement methods, and show that the proposed formulae bring a small improvement over the state-of-the-art cost-based methods in the case of one dimensional search spaces, and a significant improvement when the search space is two dimensional.
Social Fraud Detection Review: Methods, Challenges and Analysis
Nov 10, 2021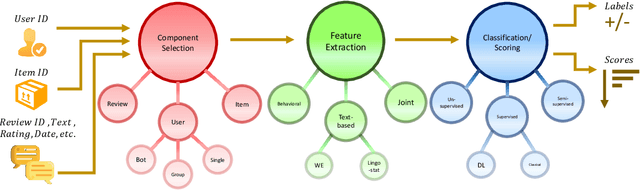
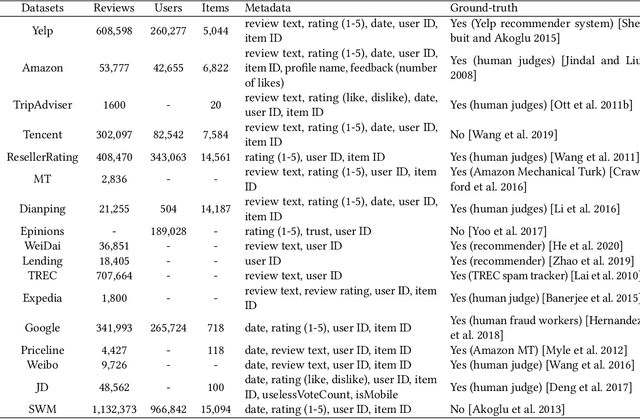
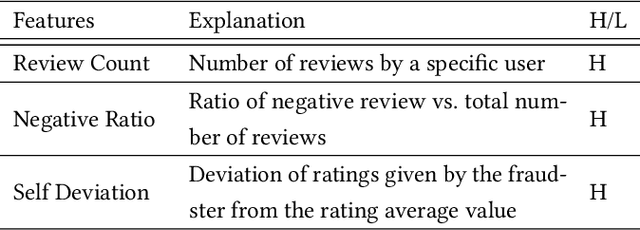
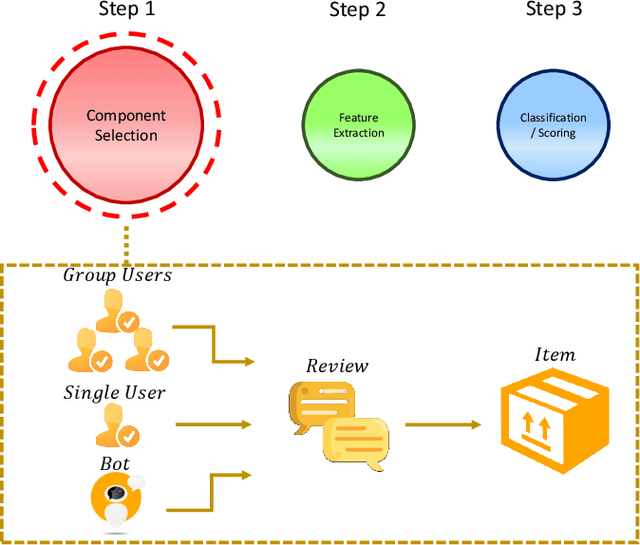
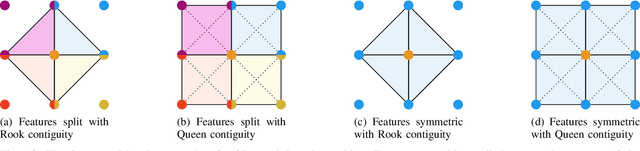
Social reviews have dominated the web and become a plausible source of product information. People and businesses use such information for decision-making. Businesses also make use of social information to spread fake information using a single user, groups of users, or a bot trained to generate fraudulent content. Many studies proposed approaches based on user behaviors and review text to address the challenges of fraud detection. To provide an exhaustive literature review, social fraud detection is reviewed using a framework that considers three key components: the review itself, the user who carries out the review, and the item being reviewed. As features are extracted for the component representation, a feature-wise review is provided based on behavioral, text-based features and their combination. With this framework, a comprehensive overview of approaches is presented including supervised, semi-supervised, and unsupervised learning. The supervised approaches for fraud detection are introduced and categorized into two sub-categories; classical, and deep learning. The lack of labeled datasets is explained and potential solutions are suggested. To help new researchers in the area develop a better understanding, a topic analysis and an overview of future directions is provided in each step of the proposed systematic framework.
Training Spiking Neural Networks Using Lessons From Deep Learning
Oct 01, 2021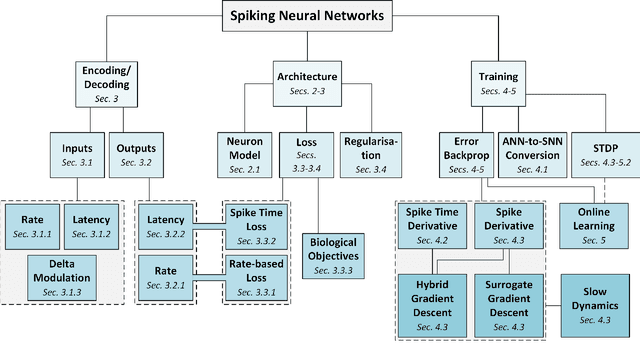

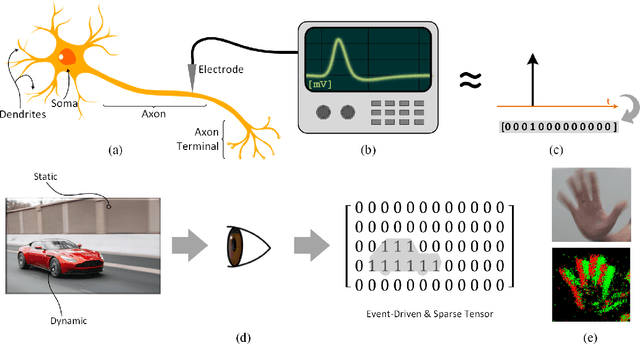

The brain is the perfect place to look for inspiration to develop more efficient neural networks. The inner workings of our synapses and neurons provide a glimpse at what the future of deep learning might look like. This paper serves as a tutorial and perspective showing how to apply the lessons learnt from several decades of research in deep learning, gradient descent, backpropagation and neuroscience to biologically plausible spiking neural neural networks. We also explore the delicate interplay between encoding data as spikes and the learning process; the challenges and solutions of applying gradient-based learning to spiking neural networks; the subtle link between temporal backpropagation and spike timing dependent plasticity, and how deep learning might move towards biologically plausible online learning. Some ideas are well accepted and commonly used amongst the neuromorphic engineering community, while others are presented or justified for the first time here. A series of companion interactive tutorials complementary to this paper using our Python package, snnTorch, are also made available: https://snntorch.readthedocs.io/en/latest/tutorials/index.html
Deep Bayesian Image Set Classification: A Defence Approach against Adversarial Attacks
Aug 23, 2021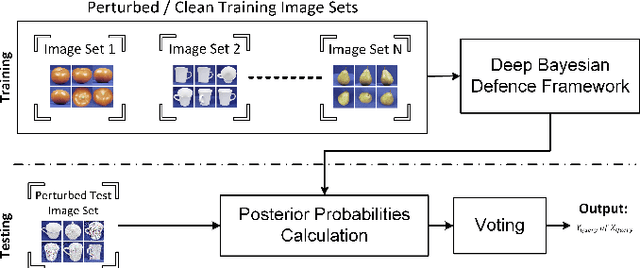
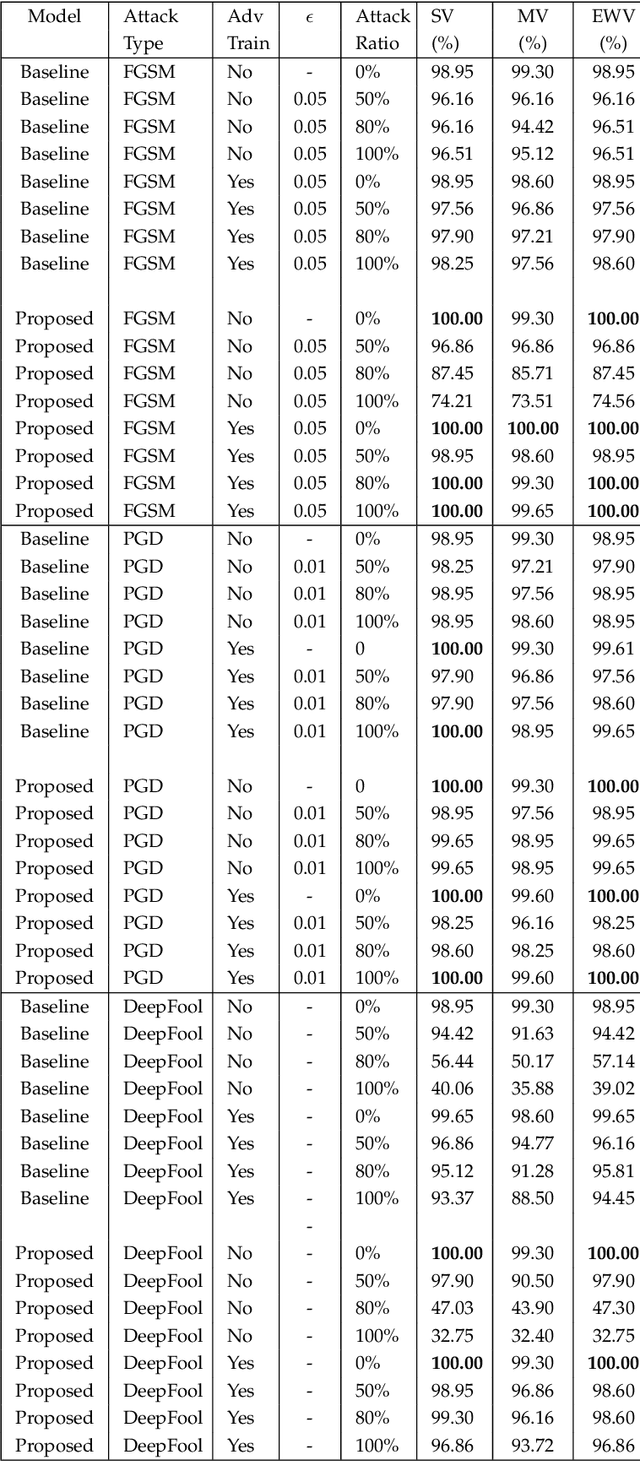
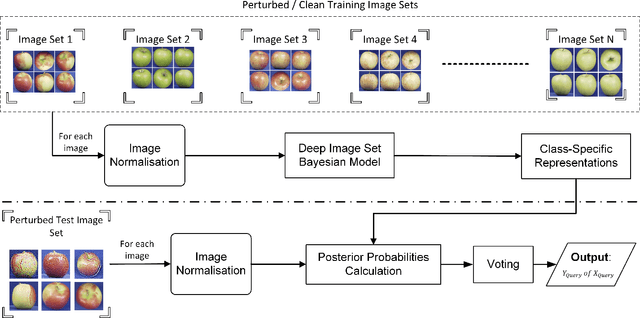
Deep learning has become an integral part of various computer vision systems in recent years due to its outstanding achievements for object recognition, facial recognition, and scene understanding. However, deep neural networks (DNNs) are susceptible to be fooled with nearly high confidence by an adversary. In practice, the vulnerability of deep learning systems against carefully perturbed images, known as adversarial examples, poses a dire security threat in the physical world applications. To address this phenomenon, we present, what to our knowledge, is the first ever image set based adversarial defence approach. Image set classification has shown an exceptional performance for object and face recognition, owing to its intrinsic property of handling appearance variability. We propose a robust deep Bayesian image set classification as a defence framework against a broad range of adversarial attacks. We extensively experiment the performance of the proposed technique with several voting strategies. We further analyse the effects of image size, perturbation magnitude, along with the ratio of perturbed images in each image set. We also evaluate our technique with the recent state-of-the-art defence methods, and single-shot recognition task. The empirical results demonstrate superior performance on CIFAR-10, MNIST, ETH-80, and Tiny ImageNet datasets.
Tensor Pooling Driven Instance Segmentation Framework for Baggage Threat Recognition
Aug 22, 2021
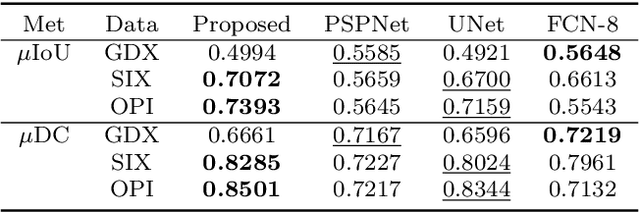
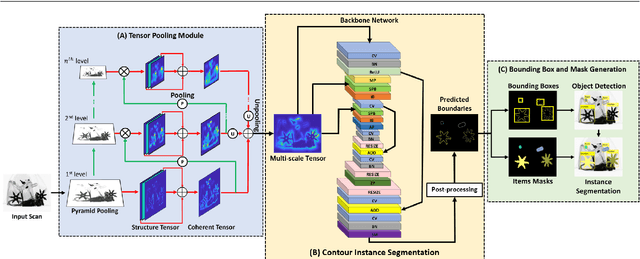
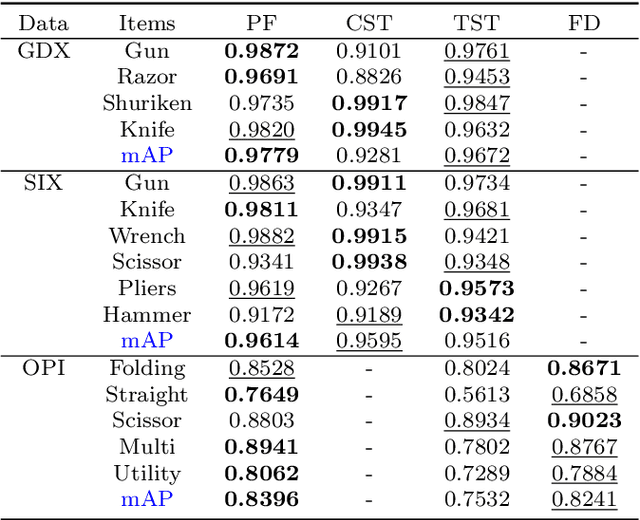
Automated systems designed for screening contraband items from the X-ray imagery are still facing difficulties with high clutter, concealment, and extreme occlusion. In this paper, we addressed this challenge using a novel multi-scale contour instance segmentation framework that effectively identifies the cluttered contraband data within the baggage X-ray scans. Unlike standard models that employ region-based or keypoint-based techniques to generate multiple boxes around objects, we propose to derive proposals according to the hierarchy of the regions defined by the contours. The proposed framework is rigorously validated on three public datasets, dubbed GDXray, SIXray, and OPIXray, where it outperforms the state-of-the-art methods by achieving the mean average precision score of 0.9779, 0.9614, and 0.8396, respectively. Furthermore, to the best of our knowledge, this is the first contour instance segmentation framework that leverages multi-scale information to recognize cluttered and concealed contraband data from the colored and grayscale security X-ray imagery.
Self-Supervised Video Object Segmentation by Motion-Aware Mask Propagation
Jul 27, 2021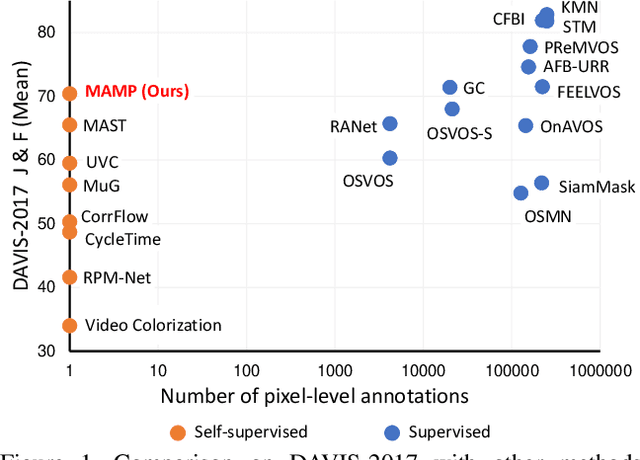

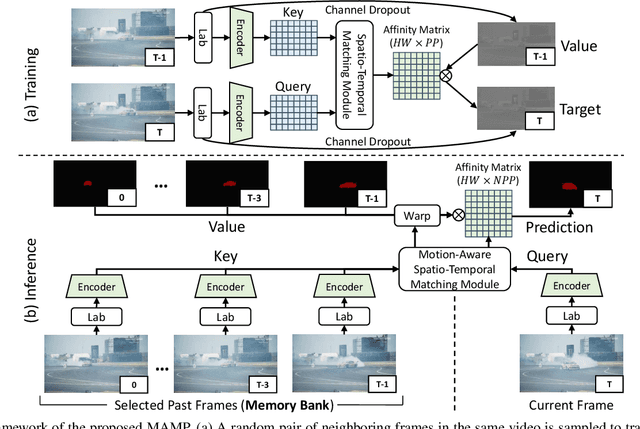
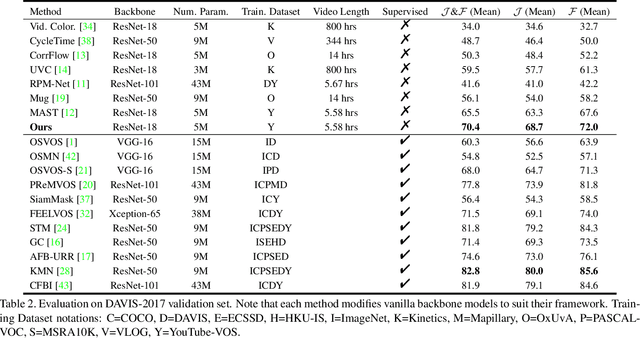
We propose a self-supervised spatio-temporal matching method coined Motion-Aware Mask Propagation (MAMP) for semi-supervised video object segmentation. During training, MAMP leverages the frame reconstruction task to train the model without the need for annotations. During inference, MAMP extracts high-resolution features from each frame to build a memory bank from the features as well as the predicted masks of selected past frames. MAMP then propagates the masks from the memory bank to subsequent frames according to our motion-aware spatio-temporal matching module, also proposed in this paper. Evaluation on DAVIS-2017 and YouTube-VOS datasets show that MAMP achieves state-of-the-art performance with stronger generalization ability compared to existing self-supervised methods, i.e. 4.9\% higher mean $\mathcal{J}\&\mathcal{F}$ on DAVIS-2017 and 4.85\% higher mean $\mathcal{J}\&\mathcal{F}$ on the unseen categories of YouTube-VOS than the nearest competitor. Moreover, MAMP performs on par with many supervised video object segmentation methods. Our code is available at: \url{https://github.com/bo-miao/MAMP}.
Leveraging Auxiliary Tasks with Affinity Learning for Weakly Supervised Semantic Segmentation
Jul 27, 2021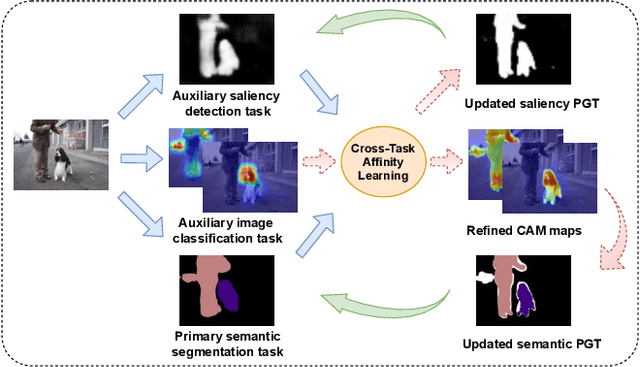
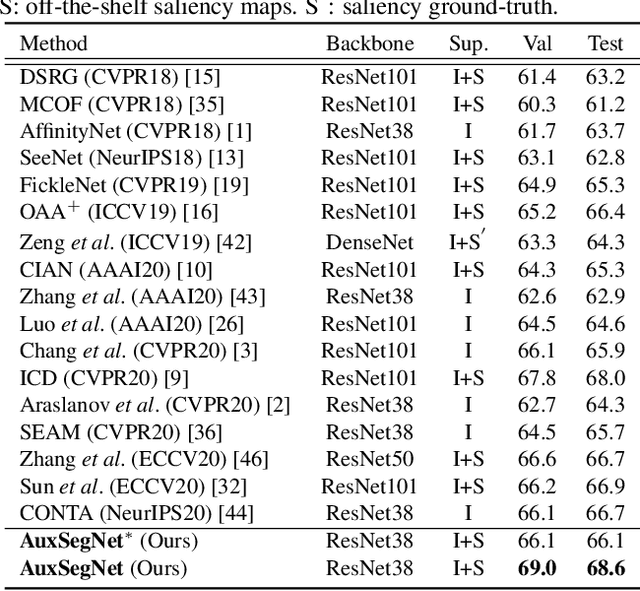
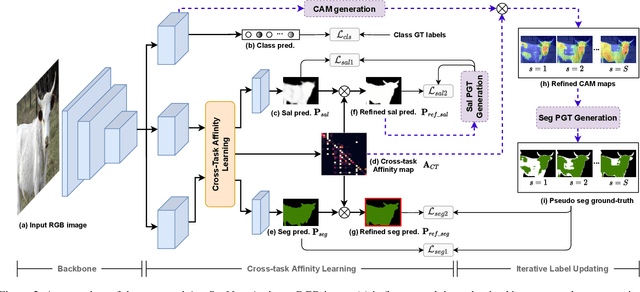

Semantic segmentation is a challenging task in the absence of densely labelled data. Only relying on class activation maps (CAM) with image-level labels provides deficient segmentation supervision. Prior works thus consider pre-trained models to produce coarse saliency maps to guide the generation of pseudo segmentation labels. However, the commonly used off-line heuristic generation process cannot fully exploit the benefits of these coarse saliency maps. Motivated by the significant inter-task correlation, we propose a novel weakly supervised multi-task framework termed as AuxSegNet, to leverage saliency detection and multi-label image classification as auxiliary tasks to improve the primary task of semantic segmentation using only image-level ground-truth labels. Inspired by their similar structured semantics, we also propose to learn a cross-task global pixel-level affinity map from the saliency and segmentation representations. The learned cross-task affinity can be used to refine saliency predictions and propagate CAM maps to provide improved pseudo labels for both tasks. The mutual boost between pseudo label updating and cross-task affinity learning enables iterative improvements on segmentation performance. Extensive experiments demonstrate the effectiveness of the proposed auxiliary learning network structure and the cross-task affinity learning method. The proposed approach achieves state-of-the-art weakly supervised segmentation performance on the challenging PASCAL VOC 2012 and MS COCO benchmarks.
Unsupervised Anomaly Instance Segmentation for Baggage Threat Recognition
Jul 16, 2021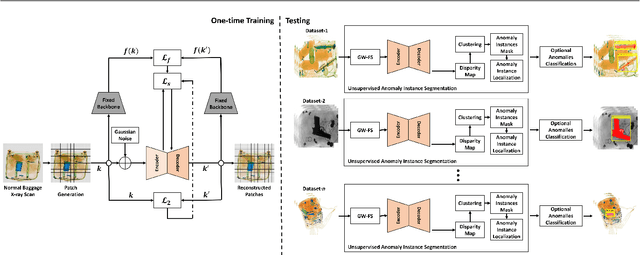
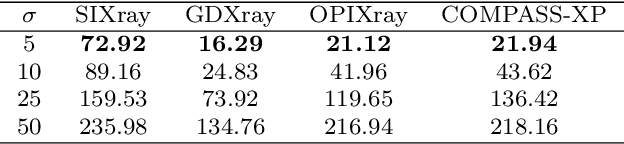


Identifying potential threats concealed within the baggage is of prime concern for the security staff. Many researchers have developed frameworks that can detect baggage threats from X-ray scans. However, to the best of our knowledge, all of these frameworks require extensive training on large-scale and well-annotated datasets, which are hard to procure in the real world. This paper presents a novel unsupervised anomaly instance segmentation framework that recognizes baggage threats, in X-ray scans, as anomalies without requiring any ground truth labels. Furthermore, thanks to its stylization capacity, the framework is trained only once, and at the inference stage, it detects and extracts contraband items regardless of their scanner specifications. Our one-staged approach initially learns to reconstruct normal baggage content via an encoder-decoder network utilizing a proposed stylization loss function. The model subsequently identifies the abnormal regions by analyzing the disparities within the original and the reconstructed scans. The anomalous regions are then clustered and post-processed to fit a bounding box for their localization. In addition, an optional classifier can also be appended with the proposed framework to recognize the categories of these extracted anomalies. A thorough evaluation of the proposed system on four public baggage X-ray datasets, without any re-training, demonstrates that it achieves competitive performance as compared to the conventional fully supervised methods (i.e., the mean average precision score of 0.7941 on SIXray, 0.8591 on GDXray, 0.7483 on OPIXray, and 0.5439 on COMPASS-XP dataset) while outperforming state-of-the-art semi-supervised and unsupervised baggage threat detection frameworks by 67.37%, 32.32%, 47.19%, and 45.81% in terms of F1 score across SIXray, GDXray, OPIXray, and COMPASS-XP datasets, respectively.