 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards credible visual model interpretation with path attribution
May 23, 2023Originally inspired by game-theory, path attribution framework stands out among the post-hoc model interpretation tools due to its axiomatic nature. However, recent developments show that this framework can still suffer from counter-intuitive results. Moreover, specifically for deep visual models, the existing path-based methods also fall short on conforming to the original intuitions that are the basis of the claimed axiomatic properties of this framework. We address these problems with a systematic investigation, and pinpoint the conditions in which the counter-intuitive results can be avoided for deep visual model interpretation with the path attribution strategy. We also devise a scheme to preclude the conditions in which visual model interpretation can invalidate the axiomatic properties of path attribution. These insights are combined into a method that enables reliable visual model interpretation. Our findings are establish empirically with multiple datasets, models and evaluation metrics. Extensive experiments show a consistent performance gain of our method over the baselines.
Attack to Fool and Explain Deep Networks
Jun 20, 2021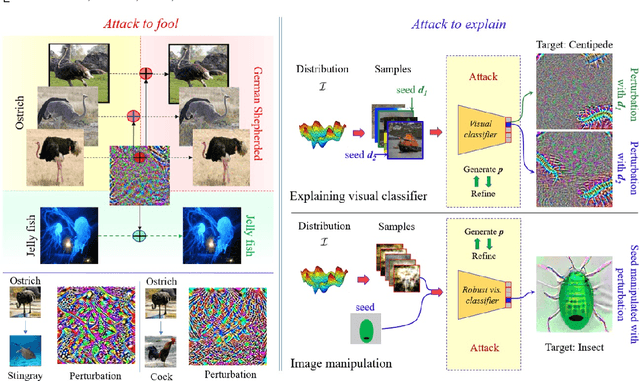
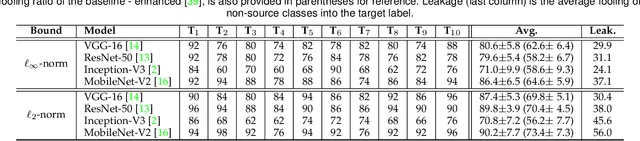
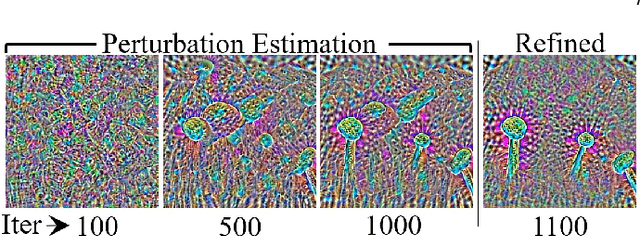
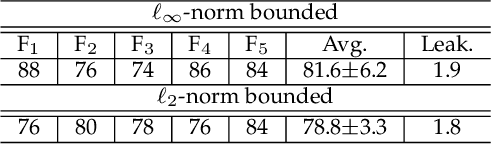
Deep visual models are susceptible to adversarial perturbations to inputs. Although these signals are carefully crafted, they still appear noise-like patterns to humans. This observation has led to the argument that deep visual representation is misaligned with human perception. We counter-argue by providing evidence of human-meaningful patterns in adversarial perturbations. We first propose an attack that fools a network to confuse a whole category of objects (source class) with a target label. Our attack also limits the unintended fooling by samples from non-sources classes, thereby circumscribing human-defined semantic notions for network fooling. We show that the proposed attack not only leads to the emergence of regular geometric patterns in the perturbations, but also reveals insightful information about the decision boundaries of deep models. Exploring this phenomenon further, we alter the `adversarial' objective of our attack to use it as a tool to `explain' deep visual representation. We show that by careful channeling and projection of the perturbations computed by our method, we can visualize a model's understanding of human-defined semantic notions. Finally, we exploit the explanability properties of our perturbations to perform image generation, inpainting and interactive image manipulation by attacking adversarialy robust `classifiers'.In all, our major contribution is a novel pragmatic adversarial attack that is subsequently transformed into a tool to interpret the visual models. The article also makes secondary contributions in terms of establishing the utility of our attack beyond the adversarial objective with multiple interesting applications.