 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Network Subspaces
Feb 20, 2021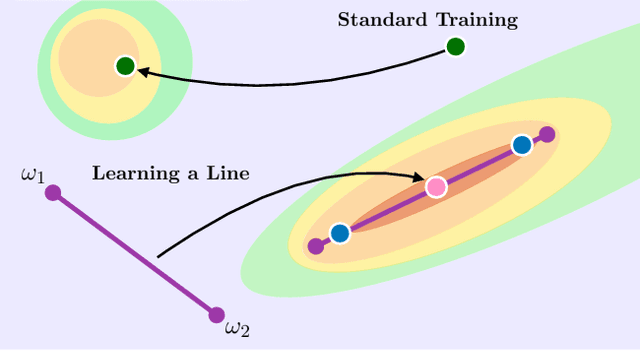


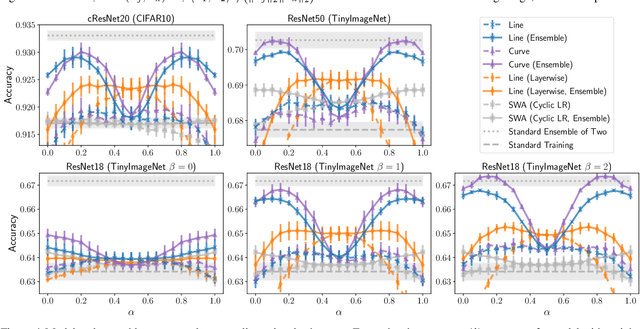
Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider minima offering improved performance. Previous methods observing diverse paths require multiple training runs. In contrast we aim to leverage both property (1) and (2) with a single method and in a single training run. With a similar computational cost as training one model, we learn lines, curves, and simplexes of high-accuracy neural networks. These neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost. Moreover, using the subspace midpoint boosts accuracy, calibration, and robustness to label noise, outperforming Stochastic Weight Averaging.
Layer-Wise Data-Free CNN Compression
Nov 18, 2020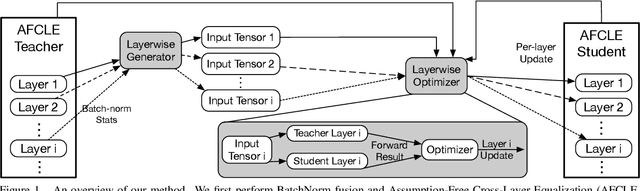
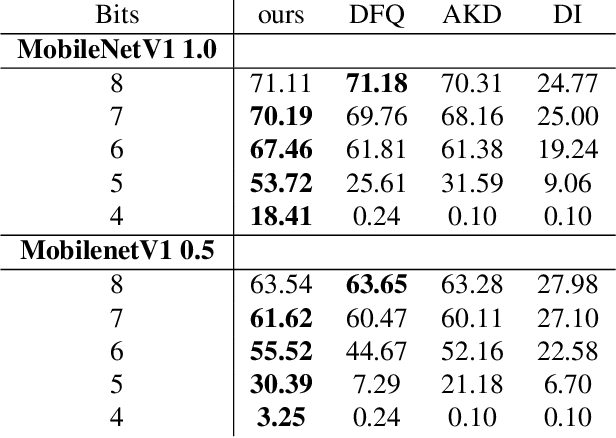
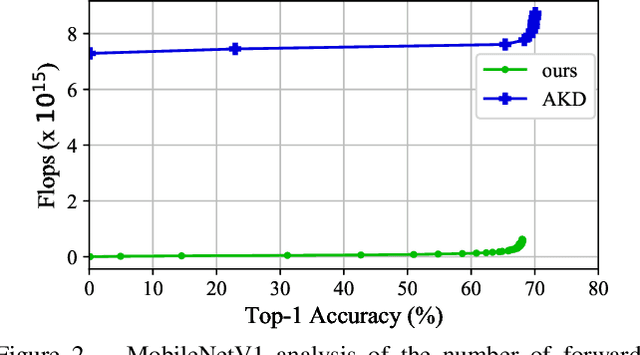
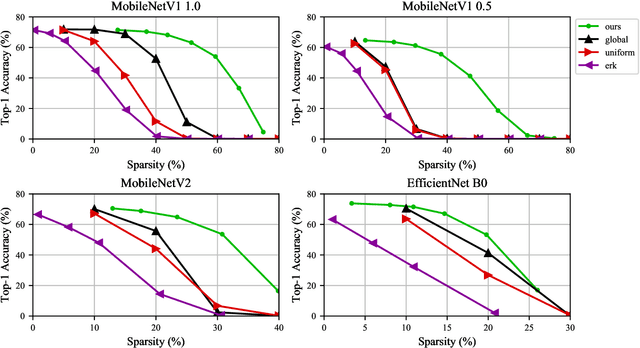
We present an efficient method for compressing a trained neural network without using any data. Our data-free method requires 14x-450x fewer FLOPs than comparable state-of-the-art methods. We break the problem of data-free network compression into a number of independent layer-wise compressions. We show how to efficiently generate layer-wise training data, and how to precondition the network to maintain accuracy during layer-wise compression. We show state-of-the-art performance on MobileNetV1 for data-free low-bit-width quantization. We also show state-of-the-art performance on data-free pruning of EfficientNet B0 when combining our method with end-to-end generative methods.
Supermasks in Superposition
Jun 30, 2020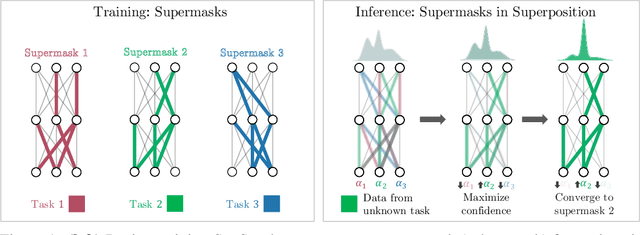

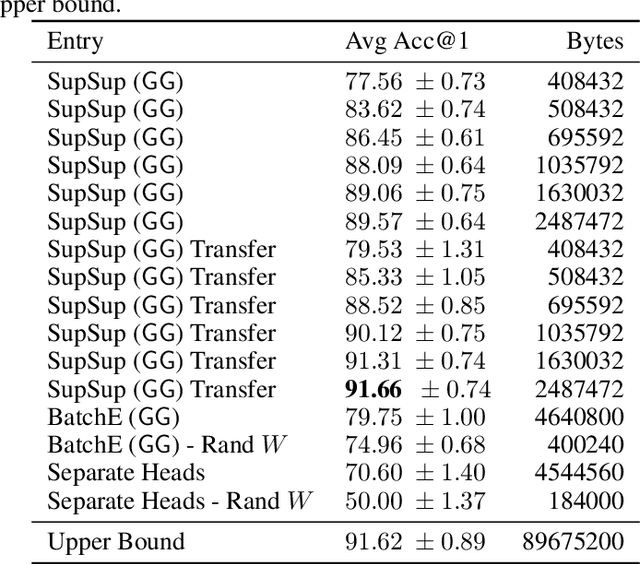
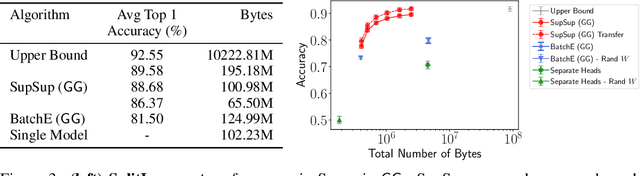
We present the Supermasks in Superposition (SupSup) model, capable of sequentially learning thousands of tasks without catastrophic forgetting. Our approach uses a randomly initialized, fixed base network and for each task finds a subnetwork (supermask) that achieves good performance. If task identity is given at test time, the correct subnetwork can be retrieved with minimal memory usage. If not provided, SupSup can infer the task using gradient-based optimization to find a linear superposition of learned supermasks which minimizes the output entropy. In practice we find that a single gradient step is often sufficient to identify the correct mask, even among 2500 tasks. We also showcase two promising extensions. First, SupSup models can be trained entirely without task identity information, as they may detect when they are uncertain about new data and allocate an additional supermask for the new training distribution. Finally the entire, growing set of supermasks can be stored in a constant-sized reservoir by implicitly storing them as attractors in a fixed-sized Hopfield network.
What's Hidden in a Randomly Weighted Neural Network?
Nov 29, 2019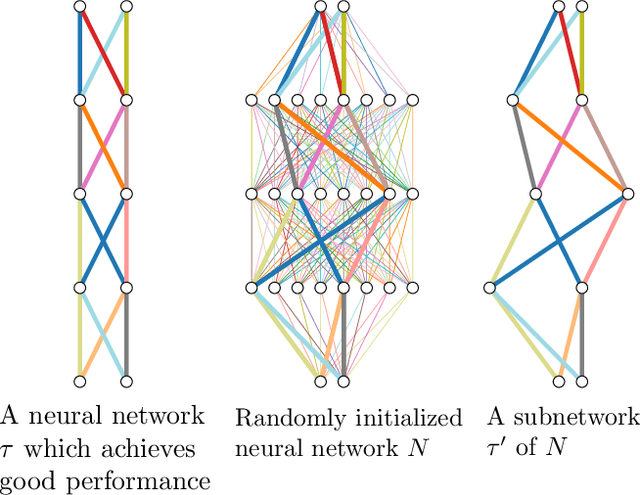
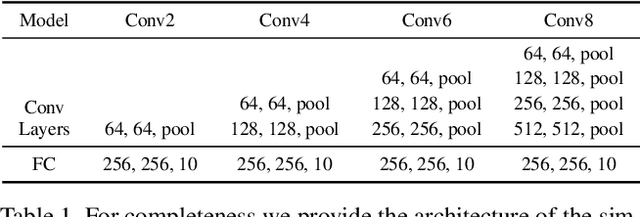
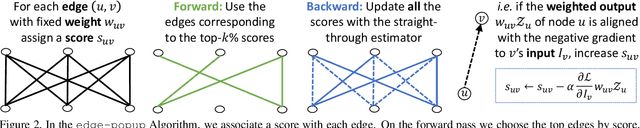
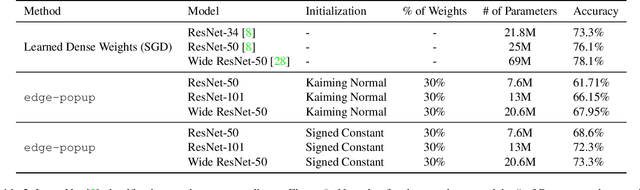
Training a neural network is synonymous with learning the values of the weights. In contrast, we demonstrate that randomly weighted neural networks contain subnetworks which achieve impressive performance without ever training the weight values. Hidden in a randomly weighted Wide ResNet-50 we show that there is a subnetwork (with random weights) that is smaller than, but matches the performance of a ResNet-34 trained on ImageNet. Not only do these "untrained subnetworks" exist, but we provide an algorithm to effectively find them. We empirically show that as randomly weighted neural networks with fixed weights grow wider and deeper, an "untrained subnetwork" approaches a network with learned weights in accuracy.
DeFINE: DEep Factorized INput Word Embeddings for Neural Sequence Modeling
Nov 27, 2019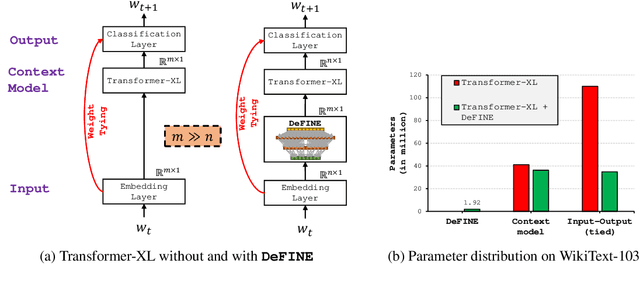
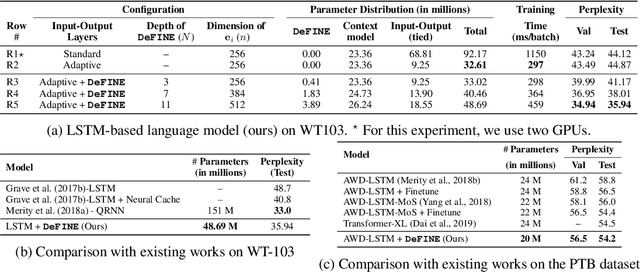
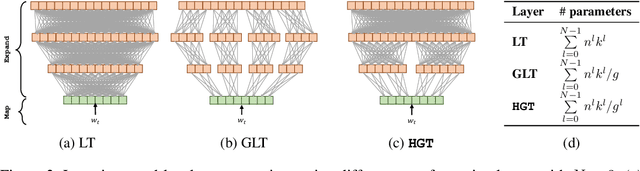
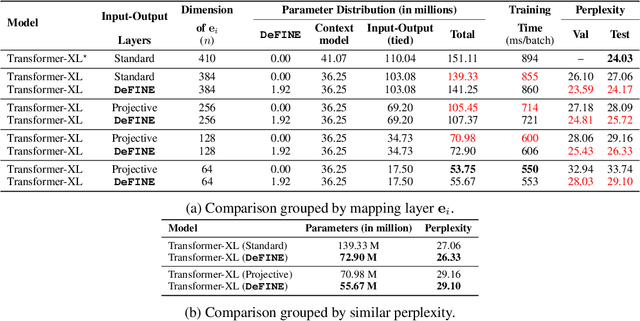
For sequence models with large word-level vocabularies, a majority of network parameters lie in the input and output layers. In this work, we describe a new method, DeFINE, for learning deep word-level representations efficiently. Our architecture uses a hierarchical structure with novel skip-connections which allows for the use of low dimensional input and output layers, reducing total parameters and training time while delivering similar or better performance versus existing methods. DeFINE can be incorporated easily in new or existing sequence models. Compared to state-of-the-art methods including adaptive input representations, this technique results in a 6% to 20% drop in perplexity. On WikiText-103, DeFINE reduces the total parameters of Transformer-XL by half with minimal impact on performance. On the Penn Treebank, DeFINE improves AWD-LSTM by 4 points with a 17% reduction in parameters, achieving comparable performance to state-of-the-art methods with fewer parameters. For machine translation, DeFINE improves the efficiency of the Transformer model by about 1.4 times while delivering similar performance.
Assisted Excitation of Activations: A Learning Technique to Improve Object Detectors
Jun 12, 2019
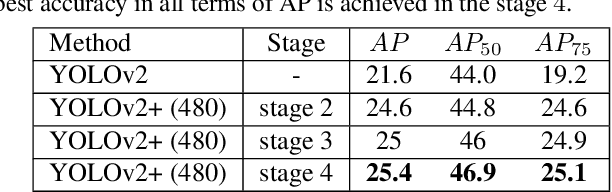


We present a simple and effective learning technique that significantly improves mAP of YOLO object detectors without compromising their speed. During network training, we carefully feed in localization information. We excite certain activations in order to help the network learn to better localize. In the later stages of training, we gradually reduce our assisted excitation to zero. We reached a new state-of-the-art in the speed-accuracy trade-off. Our technique improves the mAP of YOLOv2 by 3.8% and mAP of YOLOv3 by 2.2% on MSCOCO dataset.This technique is inspired from curriculum learning. It is simple and effective and it is applicable to most single-stage object detectors.
DiCENet: Dimension-wise Convolutions for Efficient Networks
Jun 08, 2019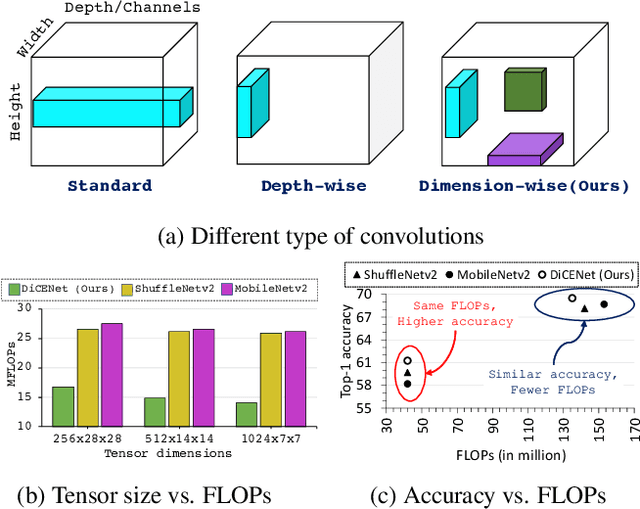
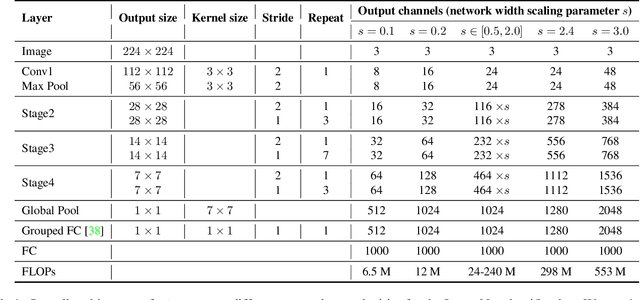
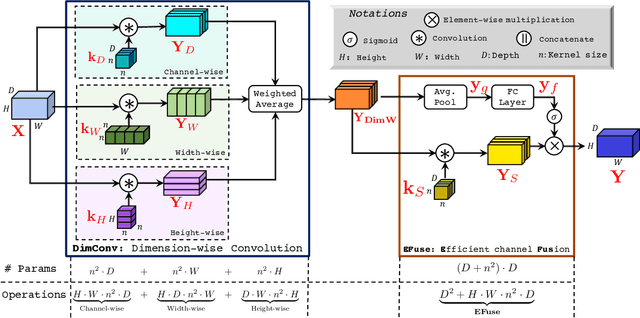
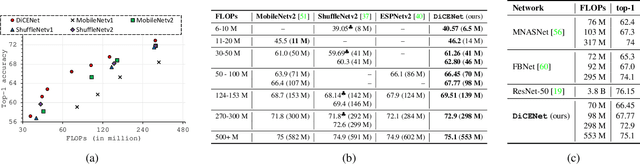
In this paper, we propose a new CNN model DiCENet, that is built using: (1) dimension-wise convolutions and (2) efficient channel fusion. The introduced blocks maximize the use of information in the input tensor by learning representations across all dimensions while simultaneously reducing the complexity of the network and achieving high accuracy. Our model shows significant improvements over state-of-the-art models across various visual recognition tasks, including image classification, object detection, and semantic segmentation. Our model delivers either the same or better performance than existing models with fewer FLOPs, including task-specific models. Notably, DiCENet delivers competitive performance to neural architecture search-based methods at fewer FLOPs (70-100 MFLOPs). On the MS-COCO object detection, DiCENet is 4.5% more accurate and has 5.6 times fewer FLOPs than YOLOv2. On the PASCAL VOC 2012 semantic segmentation dataset, DiCENet is 4.3% more accurate and has 3.2 times fewer FLOPs than a recent efficient semantic segmentation network, ESPNet. Our source code is available at \url{https://github.com/sacmehta/EdgeNets}
Butterfly Transform: An Efficient FFT Based Neural Architecture Design
Jun 05, 2019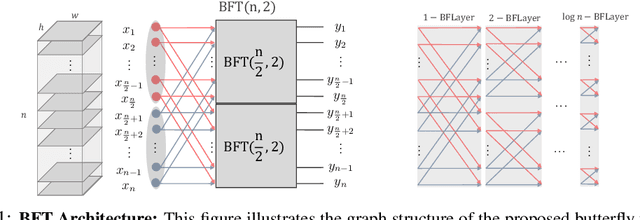
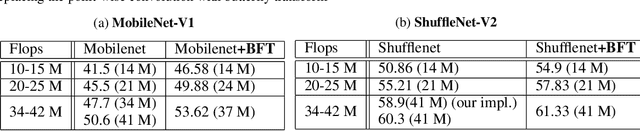
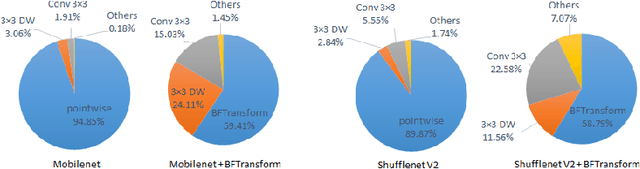
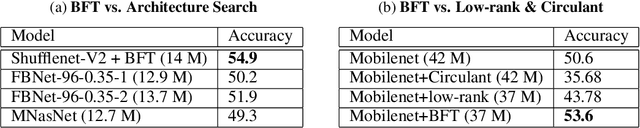
In this paper, we introduce the Butterfly Transform (BFT), a light weight channel fusion method that reduces the computational complexity of point-wise convolutions from O(n^2) of conventional solutions to O(n log n) with respect to the number of channels while improving the accuracy of the networks under the same range of FLOPs. The proposed BFT generalizes the Discrete Fourier Transform in a way that its parameters are learned at training time. Our experimental evaluations show that replacing channel fusion modules with \sys results in significant accuracy gains at similar FLOPs across a wide range of network architectures. For example, replacing channel fusion convolutions with BFT offers 3% absolute top-1 improvement for MobileNetV1-0.25 and 2.5% for ShuffleNet V2-0.5 while maintaining the same number of FLOPS. Notably, the ShuffleNet-V2+BFT outperforms state-of-the-art architecture search methods MNasNet \cite{tan2018mnasnet} and FBNet \cite{wu2018fbnet}. We also show that the structure imposed by BFT has interesting properties that ensures the efficacy of the resulting network.
Discovering Neural Wirings
Jun 03, 2019

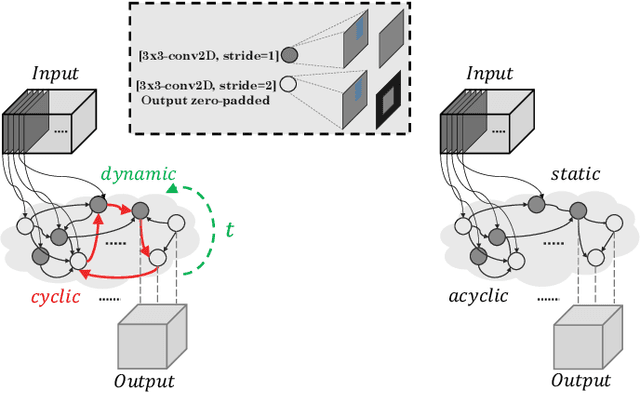
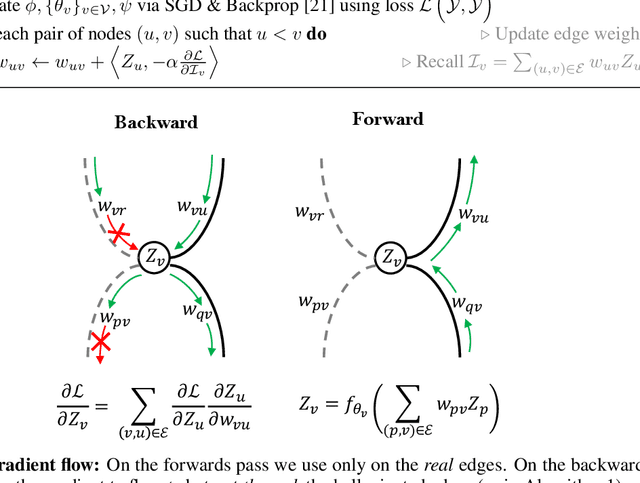
The success of neural networks has driven a shift in focus from feature engineering to architecture engineering. However, successful networks today are constructed using a small and manually defined set of building blocks. Even in methods of neural architecture search (NAS) the network connectivity patterns are largely constrained. In this work we propose a method for discovering neural wirings. We relax the typical notion of layers and instead enable channels to form connections independent of each other. This allows for a much larger space of possible networks. The wiring of our network is not fixed during training -- as we learn the network parameters we also learn the structure itself. Our experiments demonstrate that our learned connectivity outperforms hand engineered and randomly wired networks. By learning the connectivity of MobileNetV1 [9] we boost the ImageNet accuracy by 10% at ~41M FLOPs. Moreover, we show that our method generalizes to recurrent and continuous time networks.
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
May 31, 2019


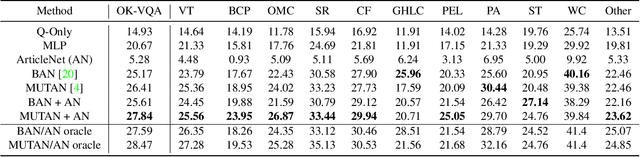
Visual Question Answering (VQA) in its ideal form lets us study reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most VQA benchmarks to date are focused on questions such as simple counting, visual attributes, and object detection that do not require reasoning or knowledge beyond what is in the image. In this paper, we address the task of knowledge-based visual question answering and provide a benchmark, called OK-VQA, where the image content is not sufficient to answer the questions, encouraging methods that rely on external knowledge resources. Our new dataset includes more than 14,000 questions that require external knowledge to answer. We show that the performance of the state-of-the-art VQA models degrades drastically in this new setting. Our analysis shows that our knowledge-based VQA task is diverse, difficult, and large compared to previous knowledge-based VQA datasets. We hope that this dataset enables researchers to open up new avenues for research in this domain. See http://okvqa.allenai.org to download and browse the dataset.