 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of Generation Order in Language Modeling
Aug 23, 2018
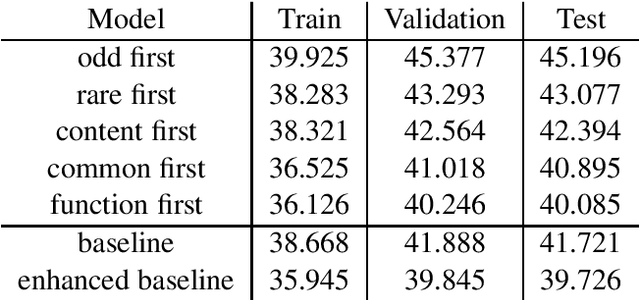
Neural language models are a critical component of state-of-the-art systems for machine translation, summarization, audio transcription, and other tasks. These language models are almost universally autoregressive in nature, generating sentences one token at a time from left to right. This paper studies the influence of token generation order on model quality via a novel two-pass language model that produces partially-filled sentence "templates" and then fills in missing tokens. We compare various strategies for structuring these two passes and observe a surprisingly large variation in model quality. We find the most effective strategy generates function words in the first pass followed by content words in the second. We believe these experimental results justify a more extensive investigation of generation order for neural language models.
Smoothed Action Value Functions for Learning Gaussian Policies
Jul 25, 2018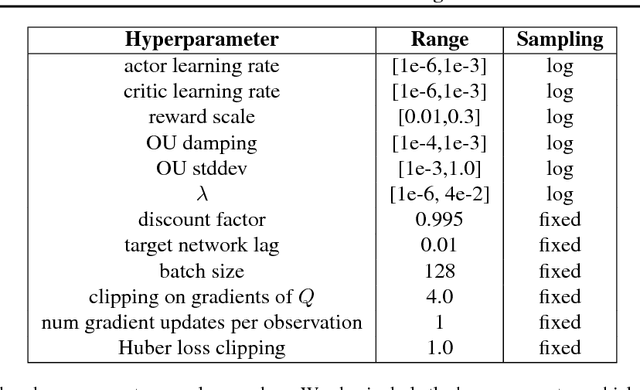
State-action value functions (i.e., Q-values) are ubiquitous in reinforcement learning (RL), giving rise to popular algorithms such as SARSA and Q-learning. We propose a new notion of action value defined by a Gaussian smoothed version of the expected Q-value. We show that such smoothed Q-values still satisfy a Bellman equation, making them learnable from experience sampled from an environment. Moreover, the gradients of expected reward with respect to the mean and covariance of a parameterized Gaussian policy can be recovered from the gradient and Hessian of the smoothed Q-value function. Based on these relationships, we develop new algorithms for training a Gaussian policy directly from a learned smoothed Q-value approximator. The approach is additionally amenable to proximal optimization by augmenting the objective with a penalty on KL-divergence from a previous policy. We find that the ability to learn both a mean and covariance during training leads to significantly improved results on standard continuous control benchmarks.
Discovery of Latent 3D Keypoints via End-to-end Geometric Reasoning
Jul 05, 2018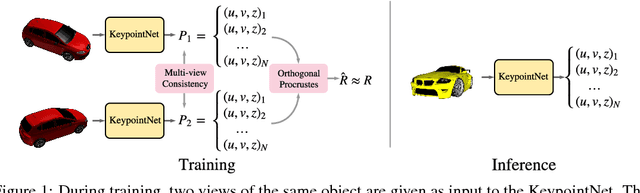
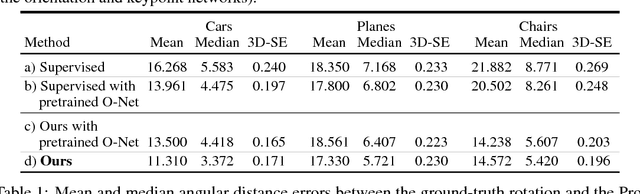

This paper presents KeypointNet, an end-to-end geometric reasoning framework to learn an optimal set of category-specific 3D keypoints, along with their detectors. Given a single image, KeypointNet extracts 3D keypoints that are optimized for a downstream task. We demonstrate this framework on 3D pose estimation by proposing a differentiable objective that seeks the optimal set of keypoints for recovering the relative pose between two views of an object. Our model discovers geometrically and semantically consistent keypoints across viewing angles and instances of an object category. Importantly, we find that our end-to-end framework using no ground-truth keypoint annotations outperforms a fully supervised baseline using the same neural network architecture on the task of pose estimation. The discovered 3D keypoints on the car, chair, and plane categories of ShapeNet are visualized at http://keypointnet.github.io/.
Embedding Text in Hyperbolic Spaces
Jun 12, 2018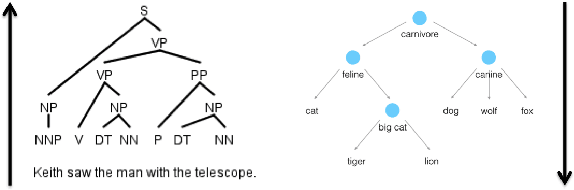
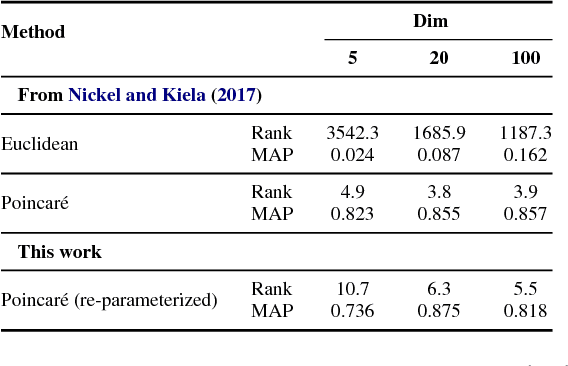
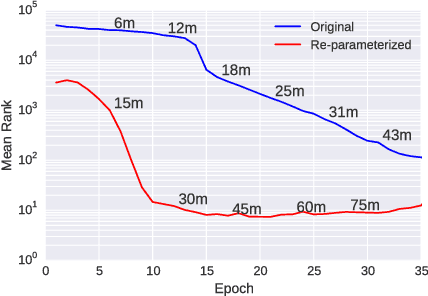

Natural language text exhibits hierarchical structure in a variety of respects. Ideally, we could incorporate our prior knowledge of this hierarchical structure into unsupervised learning algorithms that work on text data. Recent work by Nickel & Kiela (2017) proposed using hyperbolic instead of Euclidean embedding spaces to represent hierarchical data and demonstrated encouraging results when embedding graphs. In this work, we extend their method with a re-parameterization technique that allows us to learn hyperbolic embeddings of arbitrarily parameterized objects. We apply this framework to learn word and sentence embeddings in hyperbolic space in an unsupervised manner from text corpora. The resulting embeddings seem to encode certain intuitive notions of hierarchy, such as word-context frequency and phrase constituency. However, the implicit continuous hierarchy in the learned hyperbolic space makes interrogating the model's learned hierarchies more difficult than for models that learn explicit edges between items. The learned hyperbolic embeddings show improvements over Euclidean embeddings in some -- but not all -- downstream tasks, suggesting that hierarchical organization is more useful for some tasks than others.
Parallel Architecture and Hyperparameter Search via Successive Halving and Classification
May 25, 2018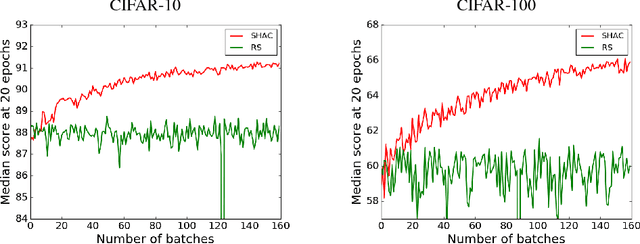
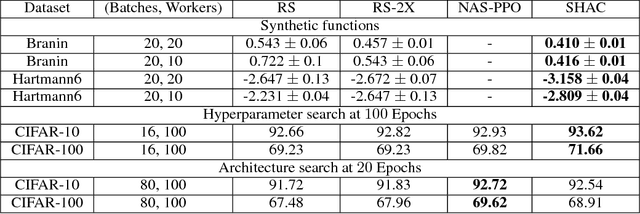
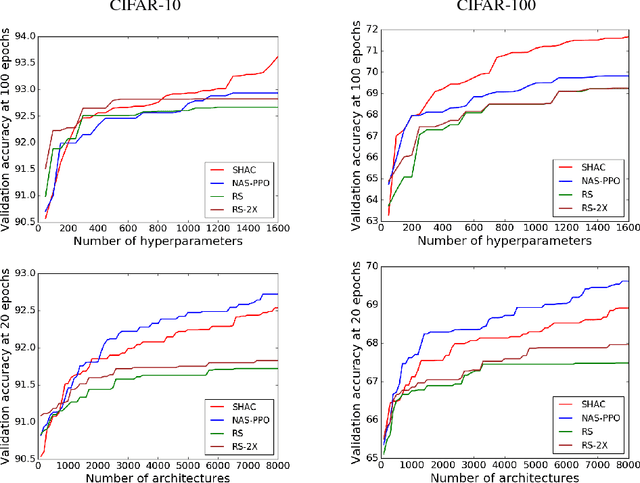

We present a simple and powerful algorithm for parallel black box optimization called Successive Halving and Classification (SHAC). The algorithm operates in $K$ stages of parallel function evaluations and trains a cascade of binary classifiers to iteratively cull the undesirable regions of the search space. SHAC is easy to implement, requires no tuning of its own configuration parameters, is invariant to the scale of the objective function and can be built using any choice of binary classifier. We adopt tree-based classifiers within SHAC and achieve competitive performance against several strong baselines for optimizing synthetic functions, hyperparameters and architectures.
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
Apr 23, 2018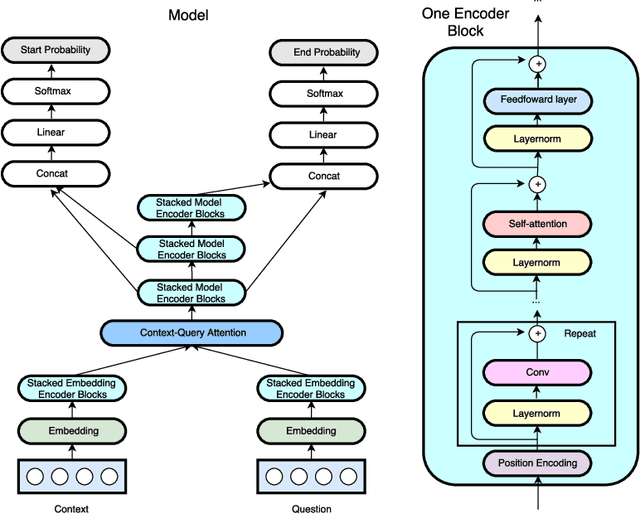

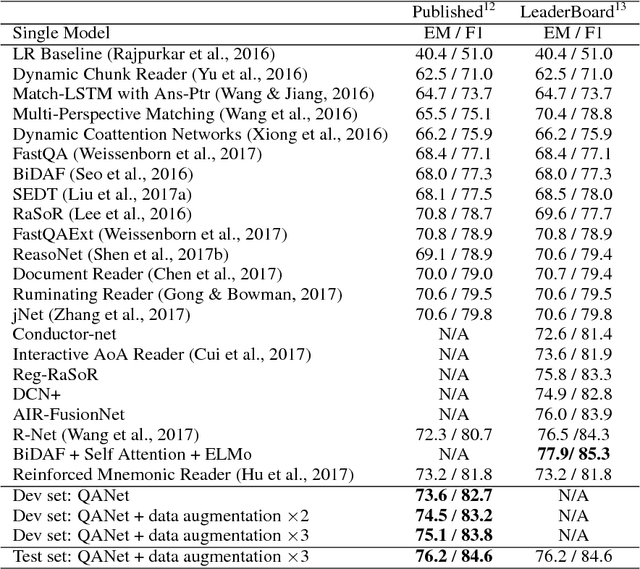
Current end-to-end machine reading and question answering (Q\&A) models are primarily based on recurrent neural networks (RNNs) with attention. Despite their success, these models are often slow for both training and inference due to the sequential nature of RNNs. We propose a new Q\&A architecture called QANet, which does not require recurrent networks: Its encoder consists exclusively of convolution and self-attention, where convolution models local interactions and self-attention models global interactions. On the SQuAD dataset, our model is 3x to 13x faster in training and 4x to 9x faster in inference, while achieving equivalent accuracy to recurrent models. The speed-up gain allows us to train the model with much more data. We hence combine our model with data generated by backtranslation from a neural machine translation model. On the SQuAD dataset, our single model, trained with augmented data, achieves 84.6 F1 score on the test set, which is significantly better than the best published F1 score of 81.8.
Neural Program Synthesis with Priority Queue Training
Mar 23, 2018


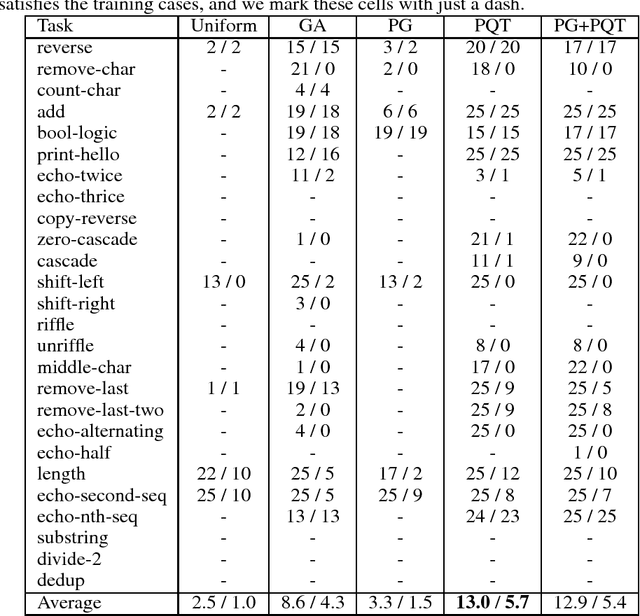
We consider the task of program synthesis in the presence of a reward function over the output of programs, where the goal is to find programs with maximal rewards. We employ an iterative optimization scheme, where we train an RNN on a dataset of K best programs from a priority queue of the generated programs so far. Then, we synthesize new programs and add them to the priority queue by sampling from the RNN. We benchmark our algorithm, called priority queue training (or PQT), against genetic algorithm and reinforcement learning baselines on a simple but expressive Turing complete programming language called BF. Our experimental results show that our simple PQT algorithm significantly outperforms the baselines. By adding a program length penalty to the reward function, we are able to synthesize short, human readable programs.
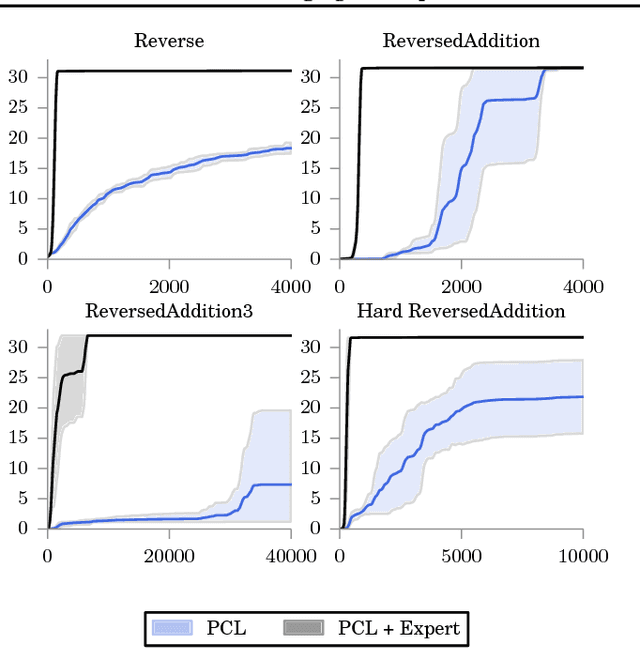
Trust-PCL: An Off-Policy Trust Region Method for Continuous Control
Feb 22, 2018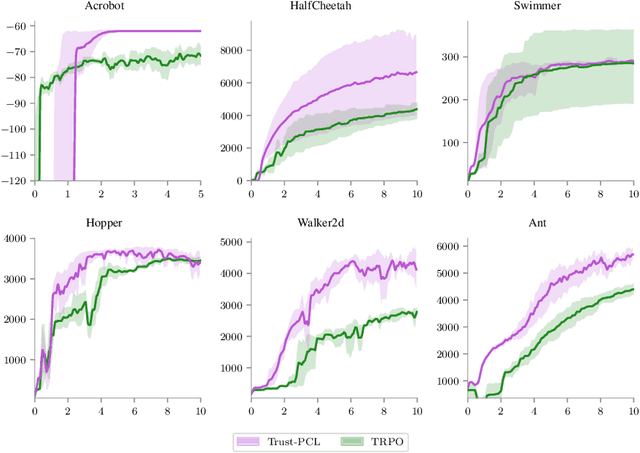

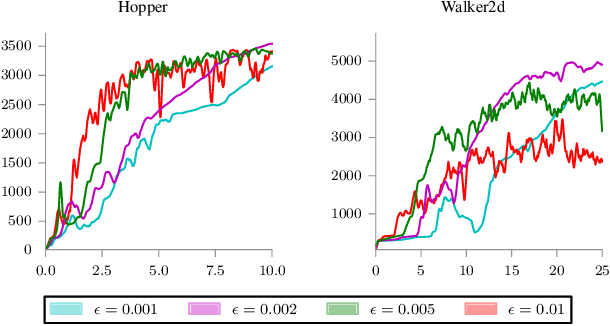
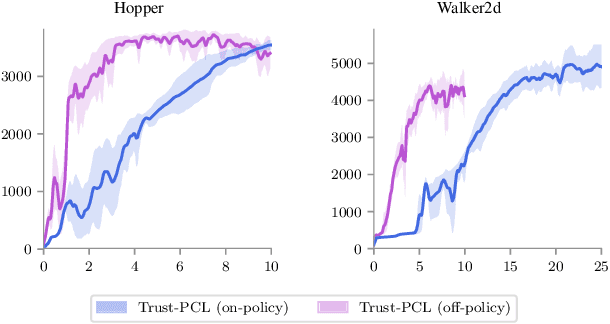
Trust region methods, such as TRPO, are often used to stabilize policy optimization algorithms in reinforcement learning (RL). While current trust region strategies are effective for continuous control, they typically require a prohibitively large amount of on-policy interaction with the environment. To address this problem, we propose an off-policy trust region method, Trust-PCL. The algorithm is the result of observing that the optimal policy and state values of a maximum reward objective with a relative-entropy regularizer satisfy a set of multi-step pathwise consistencies along any path. Thus, Trust-PCL is able to maintain optimization stability while exploiting off-policy data to improve sample efficiency. When evaluated on a number of continuous control tasks, Trust-PCL improves the solution quality and sample efficiency of TRPO.
Bridging the Gap Between Value and Policy Based Reinforcement Learning
Nov 22, 2017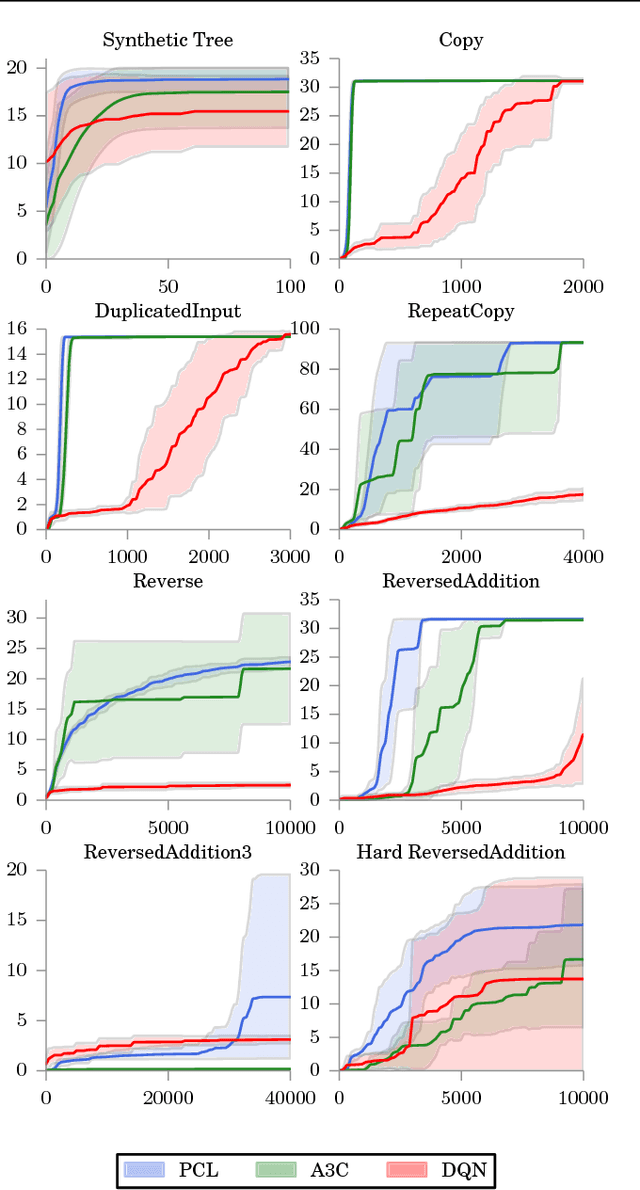
We establish a new connection between value and policy based reinforcement learning (RL) based on a relationship between softmax temporal value consistency and policy optimality under entropy regularization. Specifically, we show that softmax consistent action values correspond to optimal entropy regularized policy probabilities along any action sequence, regardless of provenance. From this observation, we develop a new RL algorithm, Path Consistency Learning (PCL), that minimizes a notion of soft consistency error along multi-step action sequences extracted from both on- and off-policy traces. We examine the behavior of PCL in different scenarios and show that PCL can be interpreted as generalizing both actor-critic and Q-learning algorithms. We subsequently deepen the relationship by showing how a single model can be used to represent both a policy and the corresponding softmax state values, eliminating the need for a separate critic. The experimental evaluation demonstrates that PCL significantly outperforms strong actor-critic and Q-learning baselines across several benchmarks.
Filtering Variational Objectives
Nov 12, 2017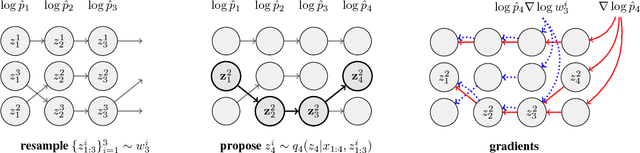
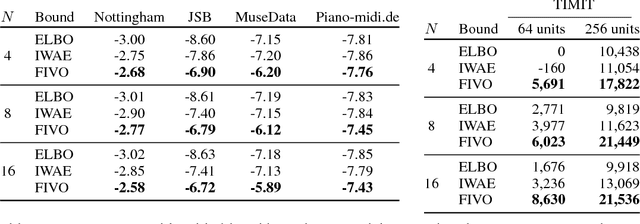
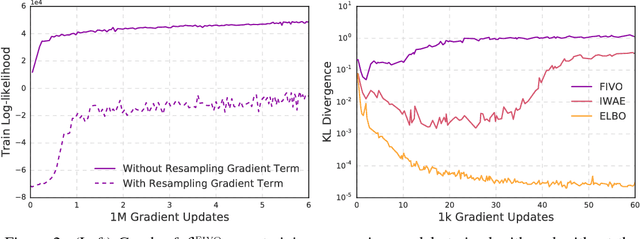
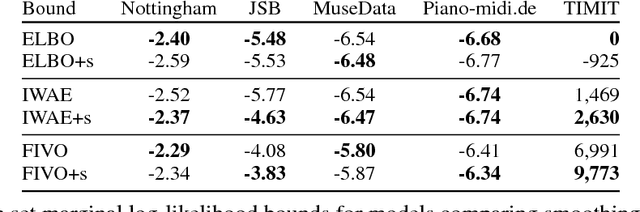
When used as a surrogate objective for maximum likelihood estimation in latent variable models, the evidence lower bound (ELBO) produces state-of-the-art results. Inspired by this, we consider the extension of the ELBO to a family of lower bounds defined by a particle filter's estimator of the marginal likelihood, the filtering variational objectives (FIVOs). FIVOs take the same arguments as the ELBO, but can exploit a model's sequential structure to form tighter bounds. We present results that relate the tightness of FIVO's bound to the variance of the particle filter's estimator by considering the generic case of bounds defined as log-transformed likelihood estimators. Experimentally, we show that training with FIVO results in substantial improvements over training the same model architecture with the ELBO on sequential data.