 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Explainable Selection to Control Abstractive Generation
Apr 24, 2020
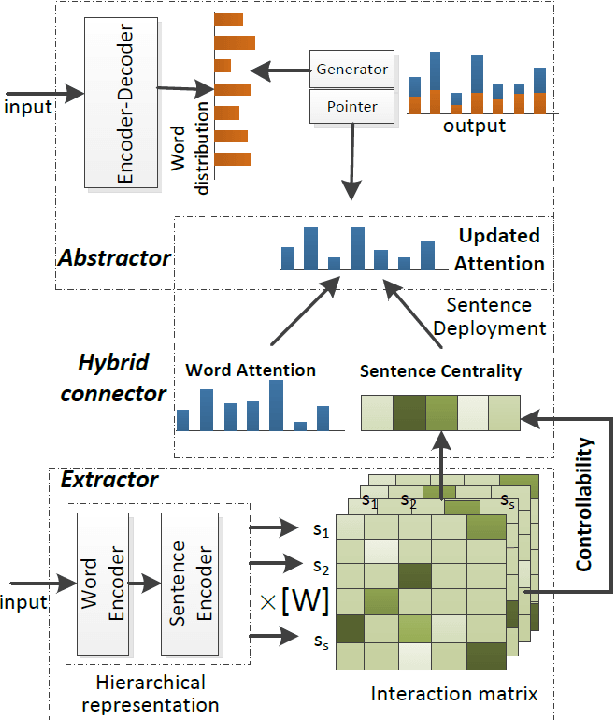
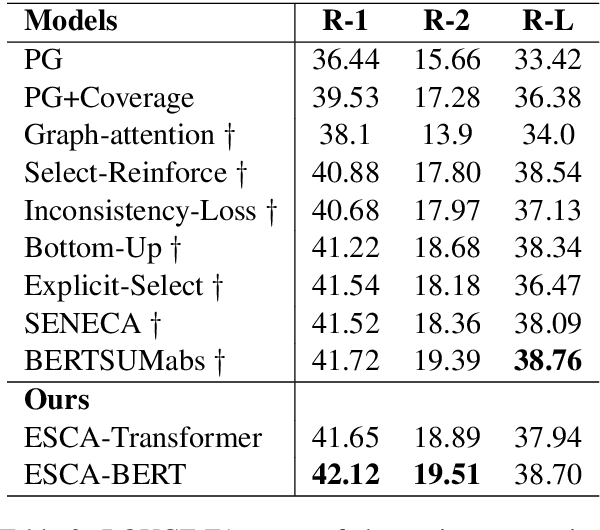
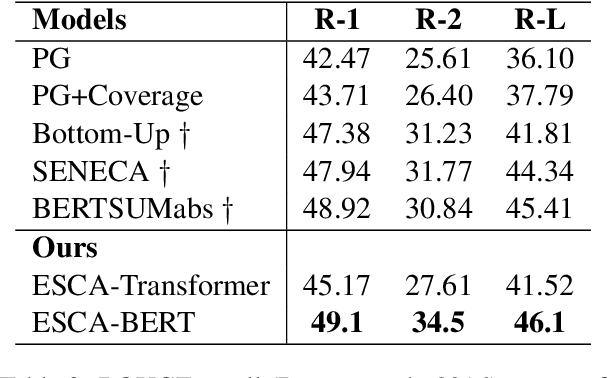
It is a big challenge to model long-range input for document summarization. In this paper, we target using a select and generate paradigm to enhance the capability of selecting explainable contents (i.e., interpret the selection given its semantics, novelty, relevance) and then guiding to control the abstract generation. Specifically, a newly designed pair-wise extractor is proposed to capture the sentence pair interactions and their centrality. Furthermore, the generator is hybrid with the selected content and is jointly integrated with a pointer distribution that is derived from a sentence deployment's attention. The abstract generation can be controlled by an explainable mask matrix that determines to what extent the content can be included in the summary. Encoders are adaptable with both Transformer-based and BERT-based configurations. Overall, both results based on ROUGE metrics and human evaluation gain outperformance over several state-of-the-art models on two benchmark CNN/DailyMail and NYT datasets.
Experience Grounds Language
Apr 21, 2020Successful linguistic communication relies on a shared experience of the world, and it is this shared experience that makes utterances meaningful. Despite the incredible effectiveness of language processing models trained on text alone, today's best systems still make mistakes that arise from a failure to relate language to the physical world it describes and to the social interactions it facilitates. Natural Language Processing is a diverse field, and progress throughout its development has come from new representational theories, modeling techniques, data collection paradigms, and tasks. We posit that the present success of representation learning approaches trained on large text corpora can be deeply enriched from the parallel tradition of research on the contextual and social nature of language. In this article, we consider work on the contextual foundations of language: grounding, embodiment, and social interaction. We describe a brief history and possible progression of how contextual information can factor into our representations, with an eye towards how this integration can move the field forward and where it is currently being pioneered. We believe this framing will serve as a roadmap for truly contextual language understanding.
Unsupervised Opinion Summarization with Noising and Denoising
Apr 21, 2020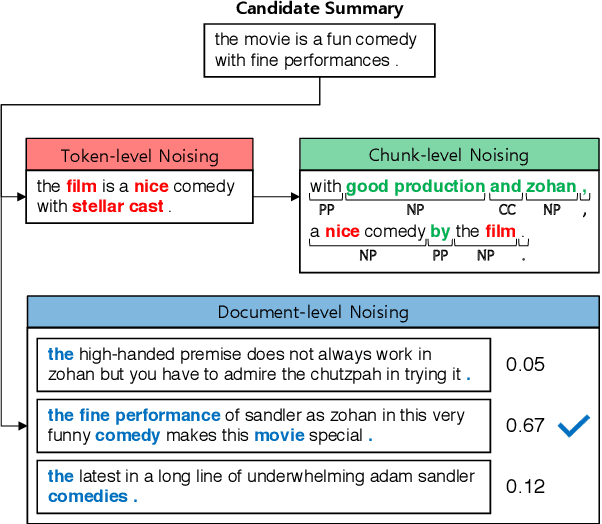
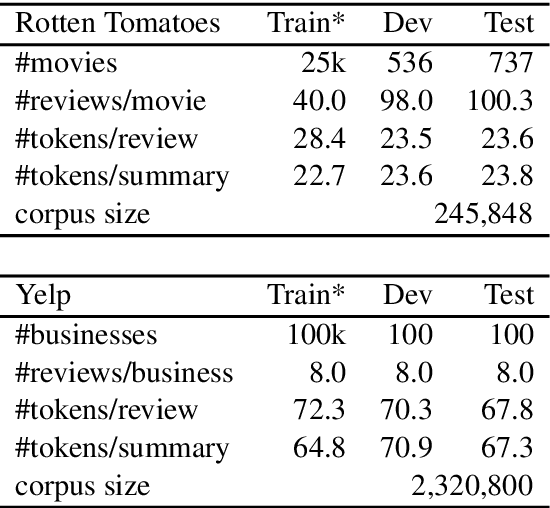
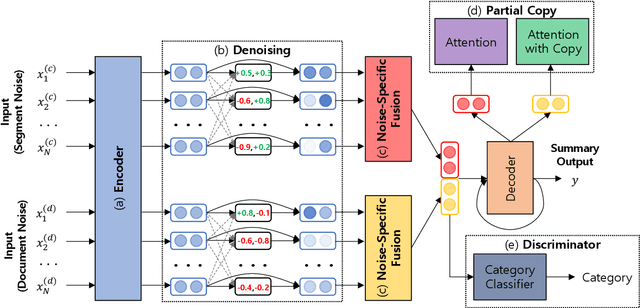
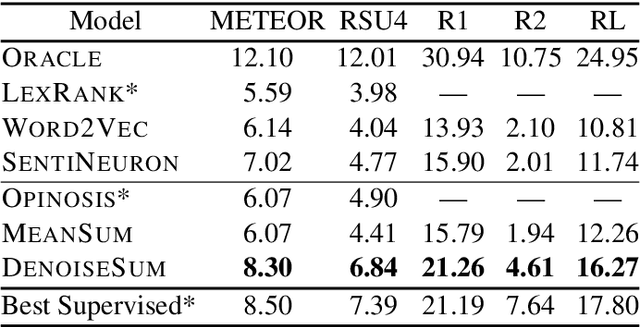
The supervised training of high-capacity models on large datasets containing hundreds of thousands of document-summary pairs is critical to the recent success of deep learning techniques for abstractive summarization. Unfortunately, in most domains (other than news) such training data is not available and cannot be easily sourced. In this paper we enable the use of supervised learning for the setting where there are only documents available (e.g.,~product or business reviews) without ground truth summaries. We create a synthetic dataset from a corpus of user reviews by sampling a review, pretending it is a summary, and generating noisy versions thereof which we treat as pseudo-review input. We introduce several linguistically motivated noise generation functions and a summarization model which learns to denoise the input and generate the original review. At test time, the model accepts genuine reviews and generates a summary containing salient opinions, treating those that do not reach consensus as noise. Extensive automatic and human evaluation shows that our model brings substantial improvements over both abstractive and extractive baselines.
Bootstrapping a Crosslingual Semantic Parser
Apr 16, 2020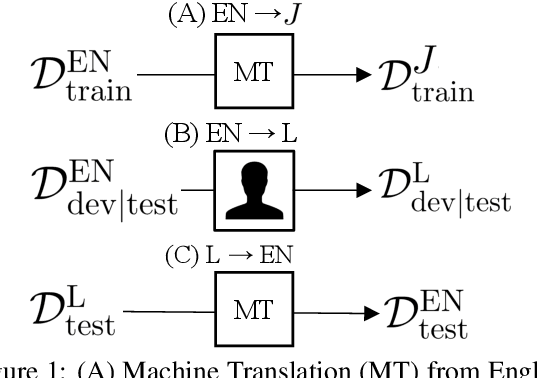
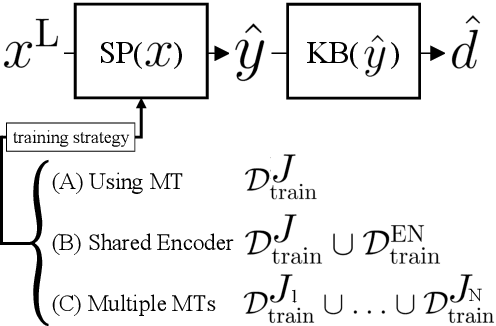
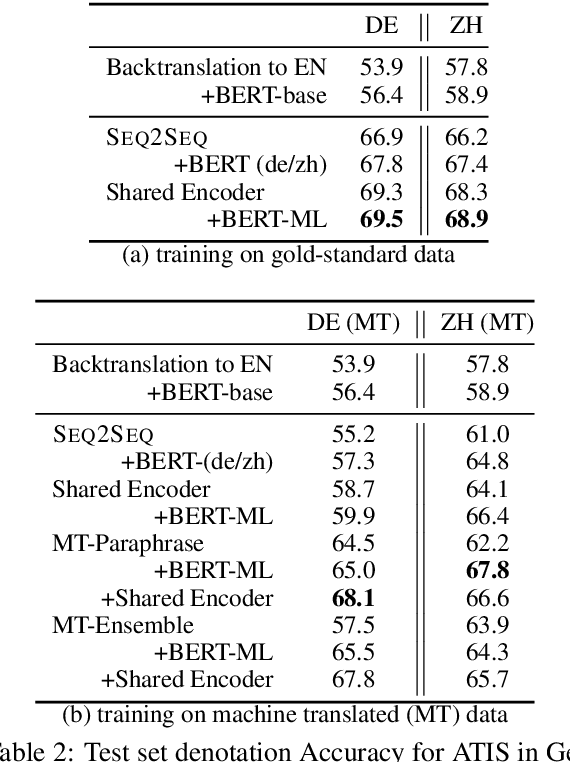
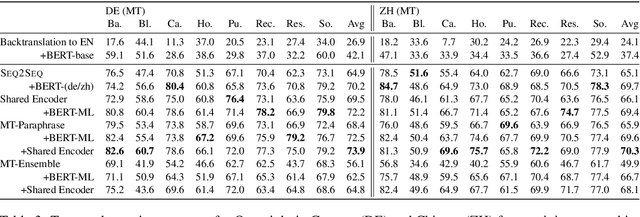
Datasets for semantic parsing scarcely consider languages other than English and professional translation can be prohibitively expensive. In this work, we propose to adapt a semantic parser trained on a single language, such as English, to new languages and multiple domains with minimal annotation. We evaluate if machine translation is an adequate substitute for training data, and extend this to investigate bootstrapping using joint training with English, paraphrasing, and resources such as multilingual BERT. Experimental results on a new version of ATIS and Overnight in German and Chinese indicate that MT can approximate training data in a new language for accurate parsing when augmented with paraphrasing through multiple MT engines.
Query Focused Multi-Document Summarization with Distant Supervision
Apr 06, 2020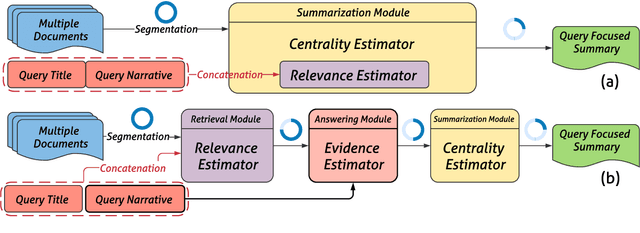
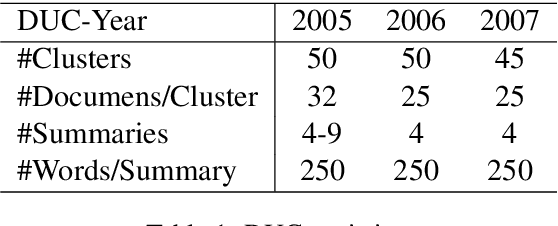
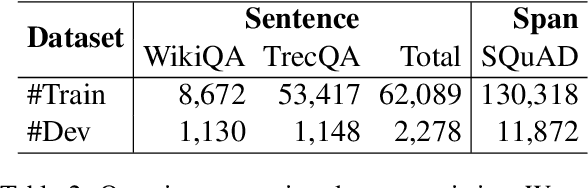
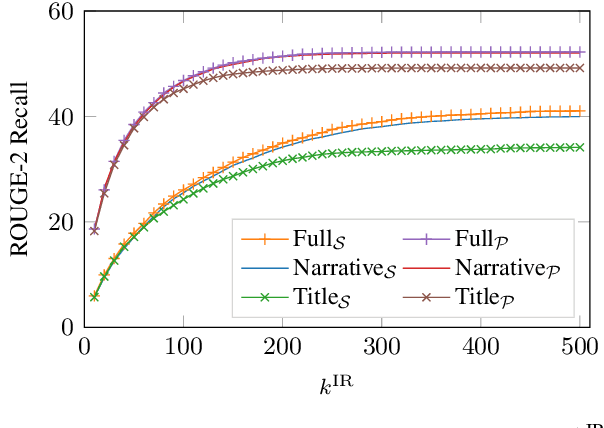
We consider the problem of better modeling query-cluster interactions to facilitate query focused multi-document summarization (QFS). Due to the lack of training data, existing work relies heavily on retrieval-style methods for estimating the relevance between queries and text segments. In this work, we leverage distant supervision from question answering where various resources are available to more explicitly capture the relationship between queries and documents. We propose a coarse-to-fine modeling framework which introduces separate modules for estimating whether segments are relevant to the query, likely to contain an answer, and central. Under this framework, a trained evidence estimator further discerns which retrieved segments might answer the query for final selection in the summary. We demonstrate that our framework outperforms strong comparison systems on standard QFS benchmarks.
Unsupervised Multi-Document Opinion Summarization as Copycat-Review Generation
Nov 06, 2019
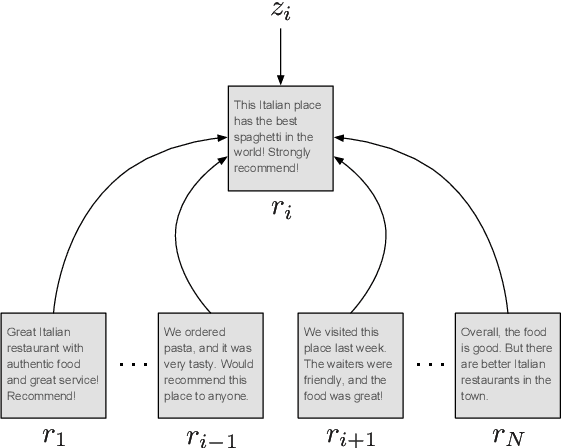
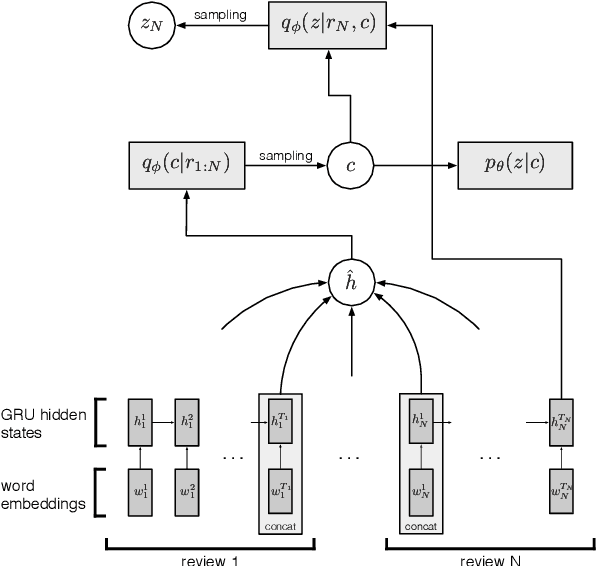
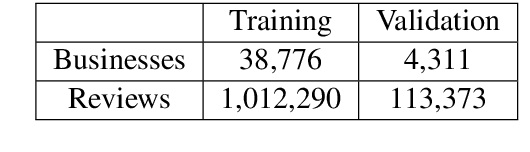
Summarization of opinions is the process of automatically creating text summaries that reflect subjective information expressed in input documents, such as product reviews. While most previous research in opinion summarization has focused on the extractive setting, i.e. selecting fragments of the input documents to produce a summary, we let the model generate novel sentences and hence produce fluent text. Supervised abstractive summarization methods typically rely on large quantities of document-summary pairs which are expensive to acquire. In contrast, we consider the unsupervised setting, in other words, we do not use any summaries in training. We define a generative model for a multi-product review collection. Intuitively, we want to design such a model that, when generating a new review given a set of other reviews of the product, we can control the `amount of novelty' going into the new review or, equivalently, vary the degree of deviation from the input reviews. At test time, when generating summaries, we force the novelty to be minimal, and produce a text reflecting consensus opinions. We capture this intuition by defining a hierarchical variational autoencoder model. Both individual reviews and products they correspond to are associated with stochastic latent codes, and the review generator ('decoder') has direct access to the text of input reviews through the pointer-generator mechanism. In experiments on Amazon and Yelp data, we show that in this model by setting at test time the review's latent code to its mean, we produce fluent and coherent summaries.
Semantic Graph Parsing with Recurrent Neural Network DAG Grammars
Oct 20, 2019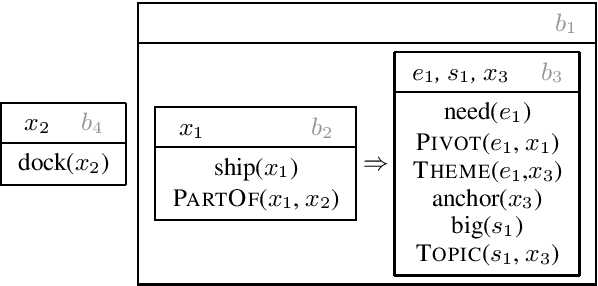
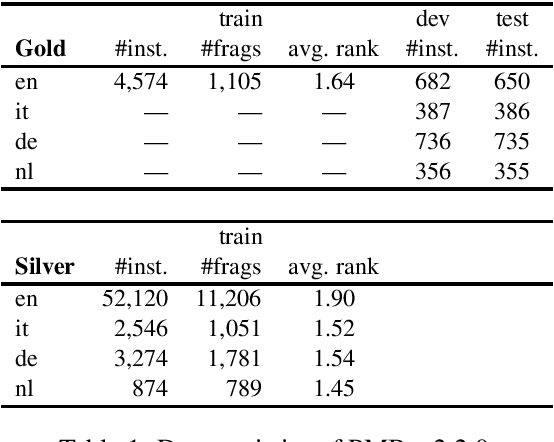
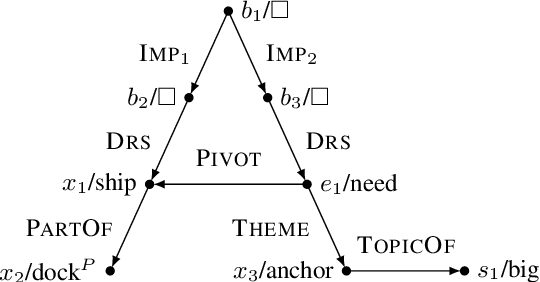

Semantic parses are directed acyclic graphs (DAGs), so semantic parsing should be modeled as graph prediction. But predicting graphs presents difficult technical challenges, so it is simpler and more common to predict the linearized graphs found in semantic parsing datasets using well-understood sequence models. The cost of this simplicity is that the predicted strings may not be well-formed graphs. We present recurrent neural network DAG grammars, a graph-aware sequence model that ensures only well-formed graphs while sidestepping many difficulties in graph prediction. We test our model on the Parallel Meaning Bank---a multilingual semantic graphbank. Our approach yields competitive results in English and establishes the first results for German, Italian and Dutch.
Controllable Sentence Simplification: Employing Syntactic and Lexical Constraints
Oct 10, 2019



Sentence simplification aims to make sentences easier to read and understand. Recent approaches have shown promising results with sequence-to-sequence models which have been developed assuming homogeneous target audiences. In this paper we argue that different users have different simplification needs (e.g. dyslexics vs. non-native speakers), and propose CROSS, ContROllable Sentence Simplification model, which allows to control both the level of simplicity and the type of the simplification. We achieve this by enriching a Transformer-based architecture with syntactic and lexical constraints (which can be set or learned from data). Empirical results on two benchmark datasets show that constraints are key to successful simplification, offering flexible generation output.
Learning Semantic Parsers from Denotations with Latent Structured Alignments and Abstract Programs
Sep 09, 2019
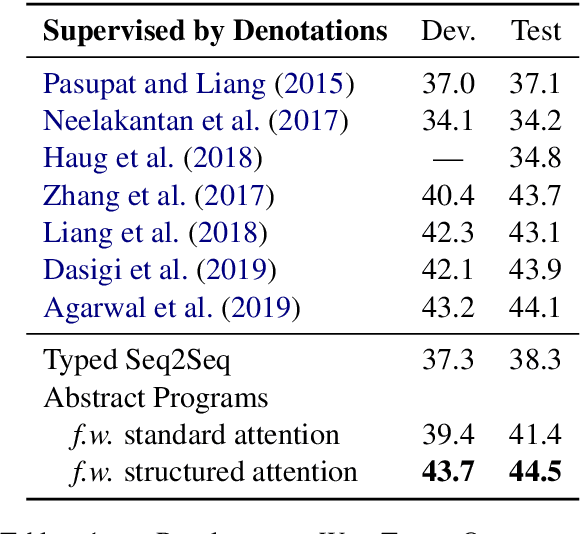
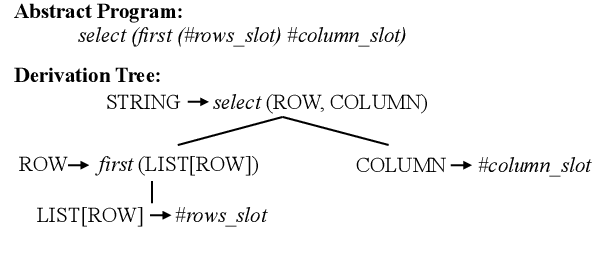
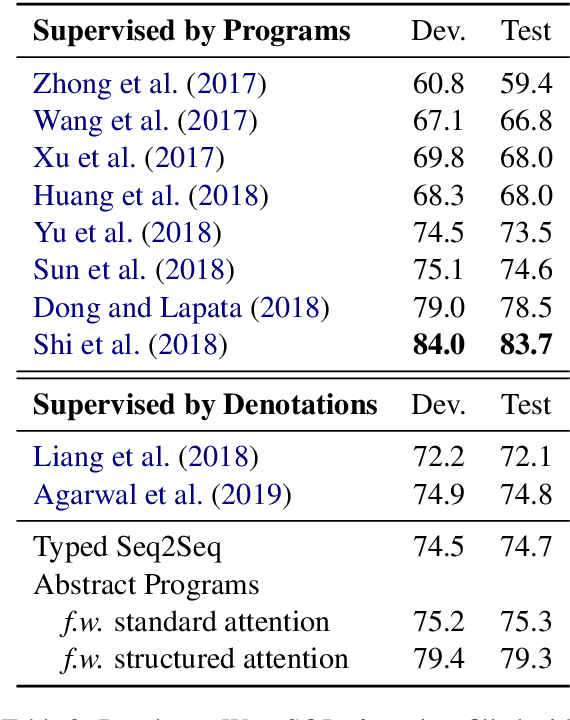
Semantic parsing aims to map natural language utterances onto machine interpretable meaning representations, aka programs whose execution against a real-world environment produces a denotation. Weakly-supervised semantic parsers are trained on utterance-denotation pairs treating programs as latent. The task is challenging due to the large search space and spuriousness of programs which may execute to the correct answer but do not generalize to unseen examples. Our goal is to instill an inductive bias in the parser to help it distinguish between spurious and correct programs. We capitalize on the intuition that correct programs would likely respect certain structural constraints were they to be aligned to the question (e.g., program fragments are unlikely to align to overlapping text spans) and propose to model alignments as structured latent variables. In order to make the latent-alignment framework tractable, we decompose the parsing task into (1) predicting a partial "abstract program" and (2) refining it while modeling structured alignments with differential dynamic programming. We obtain state-of-the-art performance on the WIKITABLEQUESTIONS and WIKISQL datasets. When compared to a standard attention baseline, we observe that the proposed structured-alignment mechanism is highly beneficial.
Text Summarization with Pretrained Encoders
Sep 05, 2019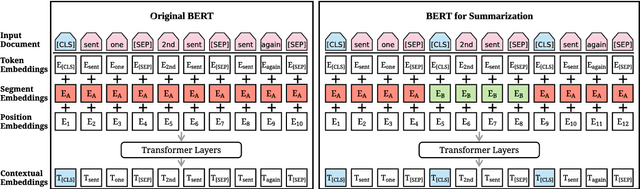

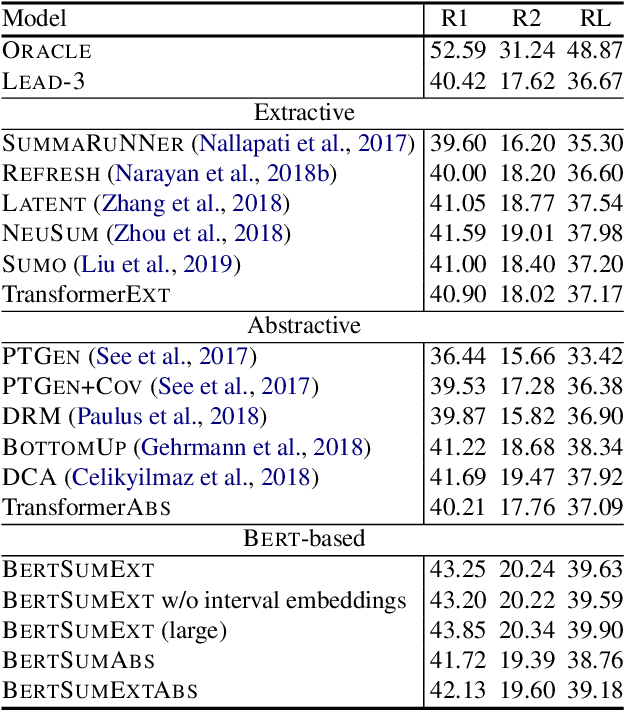
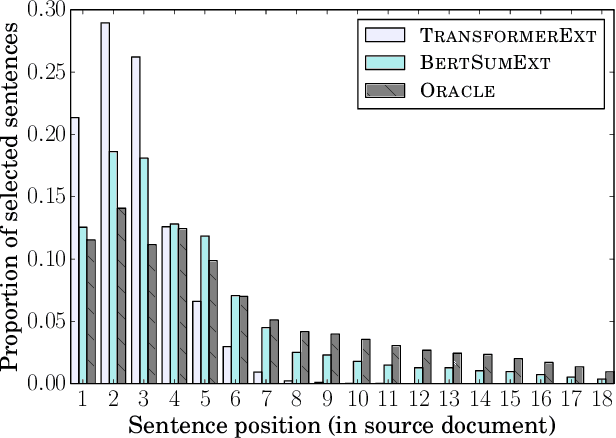
Bidirectional Encoder Representations from Transformers (BERT) represents the latest incarnation of pretrained language models which have recently advanced a wide range of natural language processing tasks. In this paper, we showcase how BERT can be usefully applied in text summarization and propose a general framework for both extractive and abstractive models. We introduce a novel document-level encoder based on BERT which is able to express the semantics of a document and obtain representations for its sentences. Our extractive model is built on top of this encoder by stacking several inter-sentence Transformer layers. For abstractive summarization, we propose a new fine-tuning schedule which adopts different optimizers for the encoder and the decoder as a means of alleviating the mismatch between the two (the former is pretrained while the latter is not). We also demonstrate that a two-staged fine-tuning approach can further boost the quality of the generated summaries. Experiments on three datasets show that our model achieves state-of-the-art results across the board in both extractive and abstractive settings. Our code is available at https://github.com/nlpyang/PreSumm