 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Optimization in the Modular Norm
May 23, 2024



To improve performance in contemporary deep learning, one is interested in scaling up the neural network in terms of both the number and the size of the layers. When ramping up the width of a single layer, graceful scaling of training has been linked to the need to normalize the weights and their updates in the "natural norm" particular to that layer. In this paper, we significantly generalize this idea by defining the modular norm, which is the natural norm on the full weight space of any neural network architecture. The modular norm is defined recursively in tandem with the network architecture itself. We show that the modular norm has several promising applications. On the practical side, the modular norm can be used to normalize the updates of any base optimizer so that the learning rate becomes transferable across width and depth. This means that the user does not need to compute optimizer-specific scale factors in order to scale training. On the theoretical side, we show that for any neural network built from "well-behaved" atomic modules, the gradient of the network is Lipschitz-continuous in the modular norm, with the Lipschitz constant admitting a simple recursive formula. This characterization opens the door to porting standard ideas in optimization theory over to deep learning. We have created a Python package called Modula that automatically normalizes weight updates in the modular norm of the architecture. The package is available via "pip install modula" with source code at https://github.com/jxbz/modula.
The Platonic Representation Hypothesis
May 13, 2024We argue that representations in AI models, particularly deep networks, are converging. First, we survey many examples of convergence in the literature: over time and across multiple domains, the ways by which different neural networks represent data are becoming more aligned. Next, we demonstrate convergence across data modalities: as vision models and language models get larger, they measure distance between datapoints in a more and more alike way. We hypothesize that this convergence is driving toward a shared statistical model of reality, akin to Plato's concept of an ideal reality. We term such a representation the platonic representation and discuss several possible selective pressures toward it. Finally, we discuss the implications of these trends, their limitations, and counterexamples to our analysis.
Training Neural Networks from Scratch with Parallel Low-Rank Adapters
Feb 26, 2024The scalability of deep learning models is fundamentally limited by computing resources, memory, and communication. Although methods like low-rank adaptation (LoRA) have reduced the cost of model finetuning, its application in model pre-training remains largely unexplored. This paper explores extending LoRA to model pre-training, identifying the inherent constraints and limitations of standard LoRA in this context. We introduce LoRA-the-Explorer (LTE), a novel bi-level optimization algorithm designed to enable parallel training of multiple low-rank heads across computing nodes, thereby reducing the need for frequent synchronization. Our approach includes extensive experimentation on vision transformers using various vision datasets, demonstrating that LTE is competitive with standard pre-training.
Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks
May 15, 2023



This work examines the challenges of training neural networks using vector quantization using straight-through estimation. We find that a primary cause of training instability is the discrepancy between the model embedding and the code-vector distribution. We identify the factors that contribute to this issue, including the codebook gradient sparsity and the asymmetric nature of the commitment loss, which leads to misaligned code-vector assignments. We propose to address this issue via affine re-parameterization of the code vectors. Additionally, we introduce an alternating optimization to reduce the gradient error introduced by the straight-through estimation. Moreover, we propose an improvement to the commitment loss to ensure better alignment between the codebook representation and the model embedding. These optimization methods improve the mathematical approximation of the straight-through estimation and, ultimately, the model performance. We demonstrate the effectiveness of our methods on several common model architectures, such as AlexNet, ResNet, and ViT, across various tasks, including image classification and generative modeling.
Totems: Physical Objects for Verifying Visual Integrity
Sep 26, 2022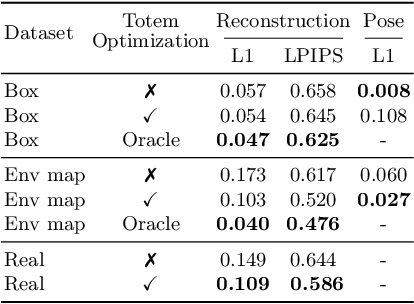
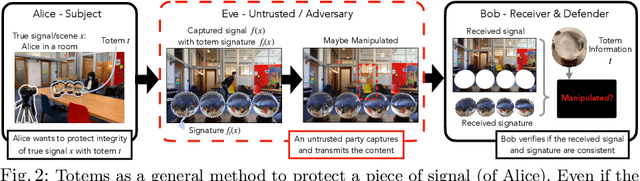

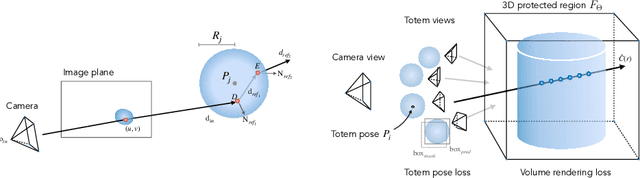
We introduce a new approach to image forensics: placing physical refractive objects, which we call totems, into a scene so as to protect any photograph taken of that scene. Totems bend and redirect light rays, thus providing multiple, albeit distorted, views of the scene within a single image. A defender can use these distorted totem pixels to detect if an image has been manipulated. Our approach unscrambles the light rays passing through the totems by estimating their positions in the scene and using their known geometric and material properties. To verify a totem-protected image, we detect inconsistencies between the scene reconstructed from totem viewpoints and the scene's appearance from the camera viewpoint. Such an approach makes the adversarial manipulation task more difficult, as the adversary must modify both the totem and image pixels in a geometrically consistent manner without knowing the physical properties of the totem. Unlike prior learning-based approaches, our method does not require training on datasets of specific manipulations, and instead uses physical properties of the scene and camera to solve the forensics problem.
Learning to Ground Multi-Agent Communication with Autoencoders
Oct 28, 2021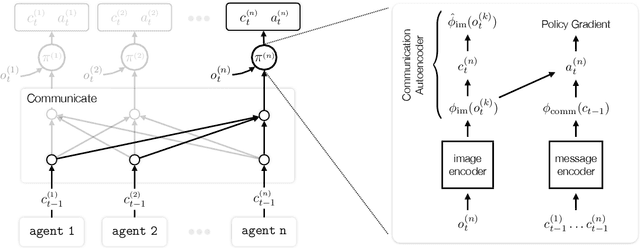
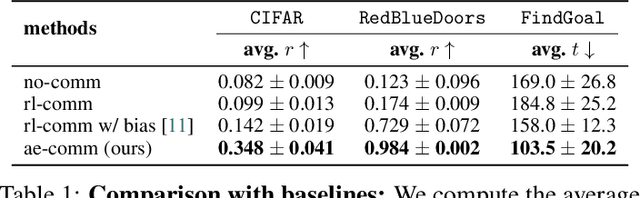
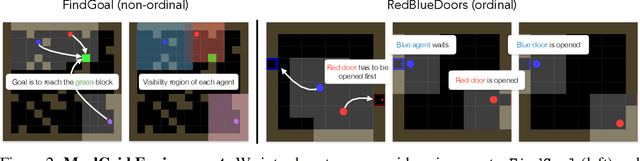

Communication requires having a common language, a lingua franca, between agents. This language could emerge via a consensus process, but it may require many generations of trial and error. Alternatively, the lingua franca can be given by the environment, where agents ground their language in representations of the observed world. We demonstrate a simple way to ground language in learned representations, which facilitates decentralized multi-agent communication and coordination. We find that a standard representation learning algorithm -- autoencoding -- is sufficient for arriving at a grounded common language. When agents broadcast these representations, they learn to understand and respond to each other's utterances and achieve surprisingly strong task performance across a variety of multi-agent communication environments.
The Low-Rank Simplicity Bias in Deep Networks
Mar 18, 2021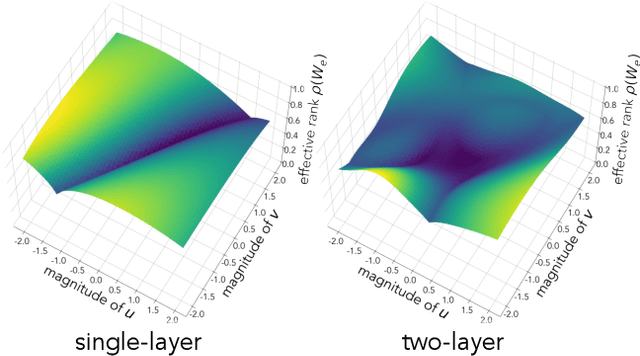
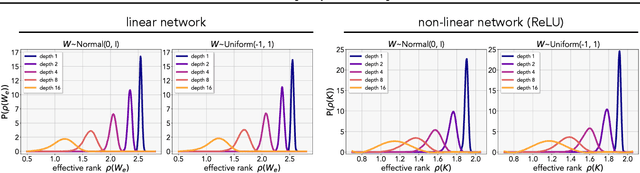
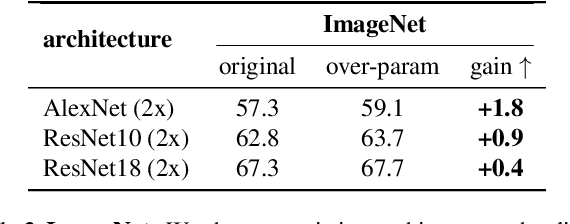
Modern deep neural networks are highly over-parameterized compared to the data on which they are trained, yet they often generalize remarkably well. A flurry of recent work has asked: why do deep networks not overfit to their training data? We investigate the hypothesis that deeper nets are implicitly biased to find lower rank solutions and that these are the solutions that generalize well. We prove for the asymptotic case that the percent volume of low effective-rank solutions increases monotonically as linear neural networks are made deeper. We then show empirically that our claim holds true on finite width models. We further empirically find that a similar result holds for non-linear networks: deeper non-linear networks learn a feature space whose kernel has a lower rank. We further demonstrate how linear over-parameterization of deep non-linear models can be used to induce low-rank bias, improving generalization performance without changing the effective model capacity. We evaluate on various model architectures and demonstrate that linearly over-parameterized models outperform existing baselines on image classification tasks, including ImageNet.
Transforming and Projecting Images into Class-conditional Generative Networks
May 04, 2020
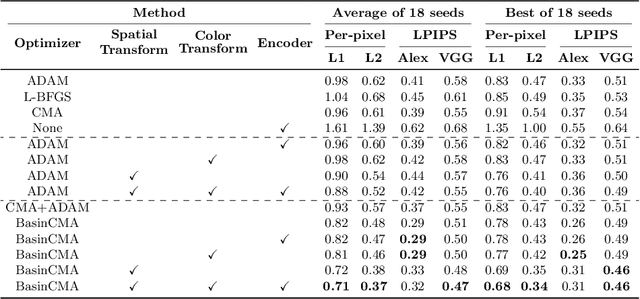
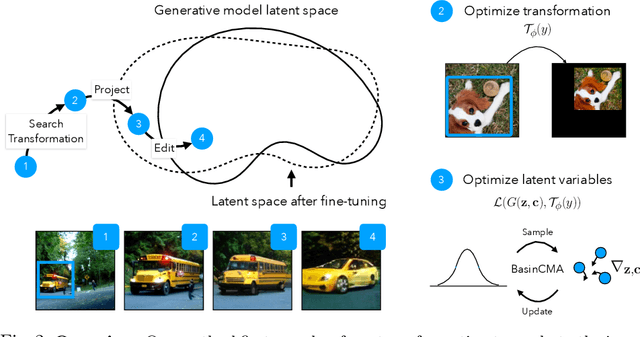
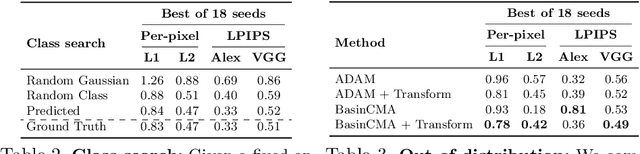
We present a method for projecting an input image into the space of a class-conditional generative neural network. We propose a method that optimizes for transformation to counteract the model biases in a generative neural networks. Specifically, we demonstrate that one can solve for image translation, scale, and global color transformation, during the projection optimization to address the object-center bias of a Generative Adversarial Network. This projection process poses a difficult optimization problem, and purely gradient-based optimizations fail to find good solutions. We describe a hybrid optimization strategy that finds good projections by estimating transformations and class parameters. We show the effectiveness of our method on real images and further demonstrate how the corresponding projections lead to better edit-ability of these images.
Fighting Fake News: Image Splice Detection via Learned Self-Consistency
Sep 05, 2018
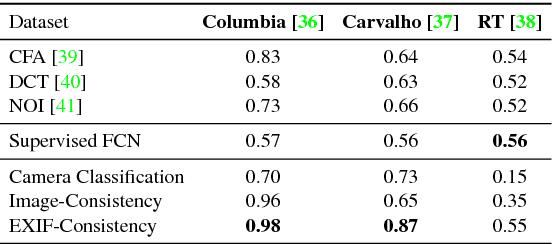

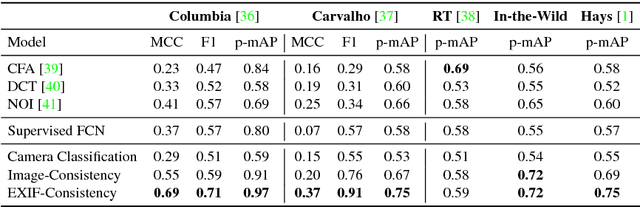
Advances in photo editing and manipulation tools have made it significantly easier to create fake imagery. Learning to detect such manipulations, however, remains a challenging problem due to the lack of sufficient amounts of manipulated training data. In this paper, we propose a learning algorithm for detecting visual image manipulations that is trained only using a large dataset of real photographs. The algorithm uses the automatically recorded photo EXIF metadata as supervisory signal for training a model to determine whether an image is self-consistent -- that is, whether its content could have been produced by a single imaging pipeline. We apply this self-consistency model to the task of detecting and localizing image splices. The proposed method obtains state-of-the-art performance on several image forensics benchmarks, despite never seeing any manipulated images at training. That said, it is merely a step in the long quest for a truly general purpose visual forensics tool.
What makes ImageNet good for transfer learning?
Dec 10, 2016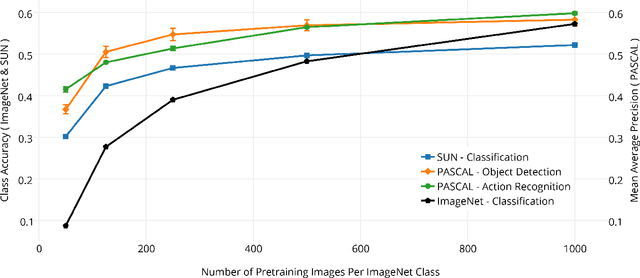
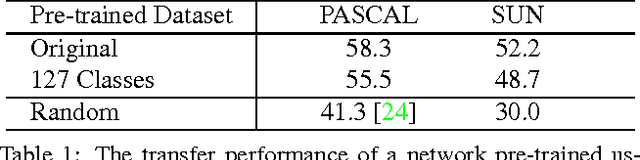
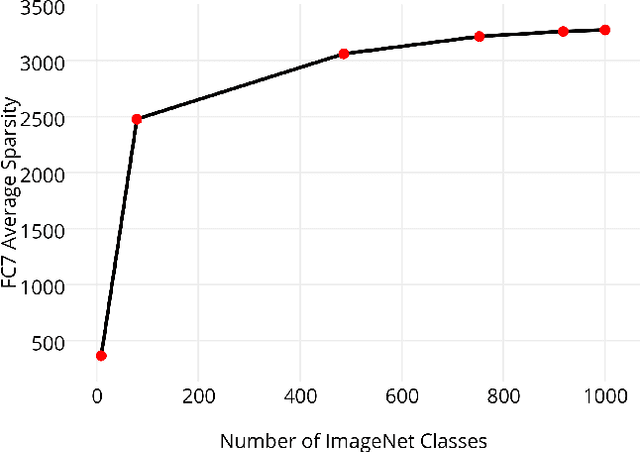
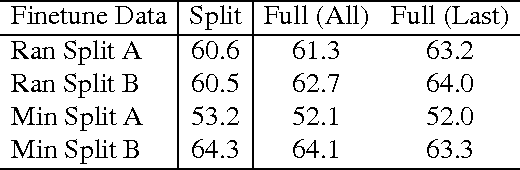
The tremendous success of ImageNet-trained deep features on a wide range of transfer tasks begs the question: what are the properties of the ImageNet dataset that are critical for learning good, general-purpose features? This work provides an empirical investigation of various facets of this question: Is more pre-training data always better? How does feature quality depend on the number of training examples per class? Does adding more object classes improve performance? For the same data budget, how should the data be split into classes? Is fine-grained recognition necessary for learning good features? Given the same number of training classes, is it better to have coarse classes or fine-grained classes? Which is better: more classes or more examples per class? To answer these and related questions, we pre-trained CNN features on various subsets of the ImageNet dataset and evaluated transfer performance on PASCAL detection, PASCAL action classification, and SUN scene classification tasks. Our overall findings suggest that most changes in the choice of pre-training data long thought to be critical do not significantly affect transfer performance.? Given the same number of training classes, is it better to have coarse classes or fine-grained classes? Which is better: more classes or more examples per class?