 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Center Fetal Brain Tissue Annotation (FeTA) Challenge 2022 Results
Feb 08, 2024



Segmentation is a critical step in analyzing the developing human fetal brain. There have been vast improvements in automatic segmentation methods in the past several years, and the Fetal Brain Tissue Annotation (FeTA) Challenge 2021 helped to establish an excellent standard of fetal brain segmentation. However, FeTA 2021 was a single center study, and the generalizability of algorithms across different imaging centers remains unsolved, limiting real-world clinical applicability. The multi-center FeTA Challenge 2022 focuses on advancing the generalizability of fetal brain segmentation algorithms for magnetic resonance imaging (MRI). In FeTA 2022, the training dataset contained images and corresponding manually annotated multi-class labels from two imaging centers, and the testing data contained images from these two imaging centers as well as two additional unseen centers. The data from different centers varied in many aspects, including scanners used, imaging parameters, and fetal brain super-resolution algorithms applied. 16 teams participated in the challenge, and 17 algorithms were evaluated. Here, a detailed overview and analysis of the challenge results are provided, focusing on the generalizability of the submissions. Both in- and out of domain, the white matter and ventricles were segmented with the highest accuracy, while the most challenging structure remains the cerebral cortex due to anatomical complexity. The FeTA Challenge 2022 was able to successfully evaluate and advance generalizability of multi-class fetal brain tissue segmentation algorithms for MRI and it continues to benchmark new algorithms. The resulting new methods contribute to improving the analysis of brain development in utero.
MMM: Generative Masked Motion Model
Dec 06, 2023



Recent advances in text-to-motion generation using diffusion and autoregressive models have shown promising results. However, these models often suffer from a trade-off between real-time performance, high fidelity, and motion editability. To address this gap, we introduce MMM, a novel yet simple motion generation paradigm based on Masked Motion Model. MMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into a sequence of discrete tokens in latent space, and (2) a conditional masked motion transformer that learns to predict randomly masked motion tokens, conditioned on the pre-computed text tokens. By attending to motion and text tokens in all directions, MMM explicitly captures inherent dependency among motion tokens and semantic mapping between motion and text tokens. During inference, this allows parallel and iterative decoding of multiple motion tokens that are highly consistent with fine-grained text descriptions, therefore simultaneously achieving high-fidelity and high-speed motion generation. In addition, MMM has innate motion editability. By simply placing mask tokens in the place that needs editing, MMM automatically fills the gaps while guaranteeing smooth transitions between editing and non-editing parts. Extensive experiments on the HumanML3D and KIT-ML datasets demonstrate that MMM surpasses current leading methods in generating high-quality motion (evidenced by superior FID scores of 0.08 and 0.429), while offering advanced editing features such as body-part modification, motion in-betweening, and the synthesis of long motion sequences. In addition, MMM is two orders of magnitude faster on a single mid-range GPU than editable motion diffusion models. Our project page is available at \url{https://exitudio.github.io/MMM-page}.
Target-Agnostic Gender-Aware Contrastive Learning for Mitigating Bias in Multilingual Machine Translation
May 23, 2023



Gender bias is a significant issue in machine translation, leading to ongoing research efforts in developing bias mitigation techniques. However, most works focus on debiasing of bilingual models without consideration for multilingual systems. In this paper, we specifically target the unambiguous gender bias issue of multilingual machine translation models and propose a new mitigation method based on a novel perspective on the problem. We hypothesize that the gender bias in unambiguous settings is due to the lack of gender information encoded into the non-explicit gender words and devise a scheme to encode correct gender information into their latent embeddings. Specifically, we employ Gender-Aware Contrastive Learning, GACL, based on gender pseudo-labels to encode gender information on the encoder embeddings. Our method is target-language-agnostic and applicable to already trained multilingual machine translation models through post-fine-tuning. Through multilingual evaluation, we show that our approach improves gender accuracy by a wide margin without hampering translation performance. We also observe that incorporated gender information transfers and benefits other target languages regarding gender accuracy. Finally, we demonstrate that our method is applicable and beneficial to models of various sizes.
Asking Clarification Questions to Handle Ambiguity in Open-Domain QA
May 23, 2023



Ambiguous questions persist in open-domain question answering, because formulating a precise question with a unique answer is often challenging. Previously, Min et al. (2020) have tackled this issue by generating disambiguated questions for all possible interpretations of the ambiguous question. This can be effective, but not ideal for providing an answer to the user. Instead, we propose to ask a clarification question, where the user's response will help identify the interpretation that best aligns with the user's intention. We first present CAMBIGNQ, a dataset consisting of 5,654 ambiguous questions, each with relevant passages, possible answers, and a clarification question. The clarification questions were efficiently created by generating them using InstructGPT and manually revising them as necessary. We then define a pipeline of tasks and design appropriate evaluation metrics. Lastly, we achieve 61.3 F1 on ambiguity detection and 40.5 F1 on clarification-based QA, providing strong baselines for future work.
GaitSADA: Self-Aligned Domain Adaptation for mmWave Gait Recognition
Feb 01, 2023



mmWave radar-based gait recognition is a novel user identification method that captures human gait biometrics from mmWave radar return signals. This technology offers privacy protection and is resilient to weather and lighting conditions. However, its generalization performance is yet unknown and limits its practical deployment. To address this problem, in this paper, a non-synthetic dataset is collected and analyzed to reveal the presence of spatial and temporal domain shifts in mmWave gait biometric data, which significantly impacts identification accuracy. To address this issue, a novel self-aligned domain adaptation method called GaitSADA is proposed. GaitSADA improves system generalization performance by using a two-stage semi-supervised model training approach. The first stage uses semi-supervised contrastive learning and the second stage uses semi-supervised consistency training with centroid alignment. Extensive experiments show that GaitSADA outperforms representative domain adaptation methods by an average of 15.41% in low data regimes.
Error-related Potential Variability: Exploring the Effects on Classification and Transferability
Jan 16, 2023Brain-Computer Interfaces (BCI) have allowed for direct communication from the brain to external applications for the automatic detection of cognitive processes such as error recognition. Error-related potentials (ErrPs) are a particular brain signal elicited when one commits or observes an erroneous event. However, due to the noisy properties of the brain and recording devices, ErrPs vary from instance to instance as they are combined with an assortment of other brain signals, biological noise, and external noise, making the classification of ErrPs a non-trivial problem. Recent works have revealed particular cognitive processes such as awareness, embodiment, and predictability that contribute to ErrP variations. In this paper, we explore the performance of classifier transferability when trained on different ErrP variation datasets generated by varying the levels of awareness and embodiment for a given task. In particular, we look at transference between observational and interactive ErrP categories when elicited by similar and differing tasks. Our empirical results provide an exploratory analysis into the ErrP transferability problem from a data perspective.
GaitMixer: Skeleton-based Gait Representation Learning via Wide-spectrum Multi-axial Mixer
Oct 29, 2022Most existing gait recognition methods are appearance-based, which rely on the silhouettes extracted from the video data of human walking activities. The less-investigated skeleton-based gait recognition methods directly learn the gait dynamics from 2D/3D human skeleton sequences, which are theoretically more robust solutions in the presence of appearance changes caused by clothes, hairstyles, and carrying objects. However, the performance of skeleton-based solutions is still largely behind the appearance-based ones. This paper aims to close such performance gap by proposing a novel network model, GaitMixer, to learn more discriminative gait representation from skeleton sequence data. In particular, GaitMixer follows a heterogeneous multi-axial mixer architecture, which exploits the spatial self-attention mixer followed by the temporal large-kernel convolution mixer to learn rich multi-frequency signals in the gait feature maps. Experiments on the widely used gait database, CASIA-B, demonstrate that GaitMixer outperforms the previous SOTA skeleton-based methods by a large margin while achieving a competitive performance compared with the representative appearance-based solutions. Code will be available at https://github.com/exitudio/gaitmixer
Privacy Enhancement for Cloud-Based Few-Shot Learning
May 10, 2022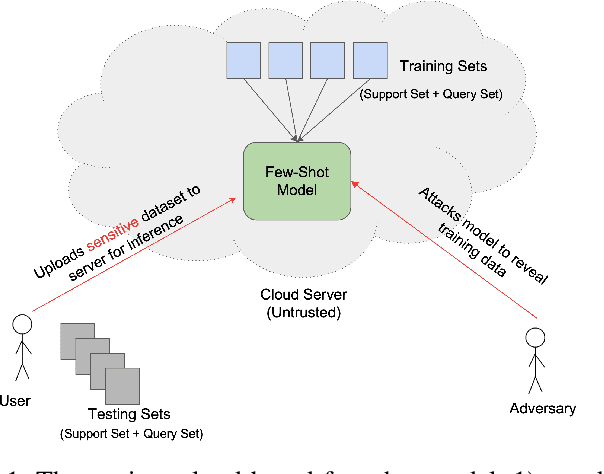
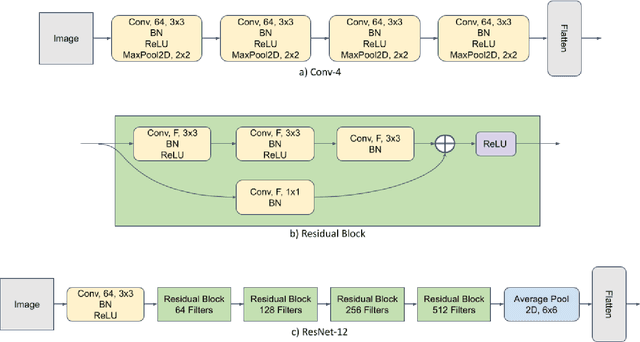
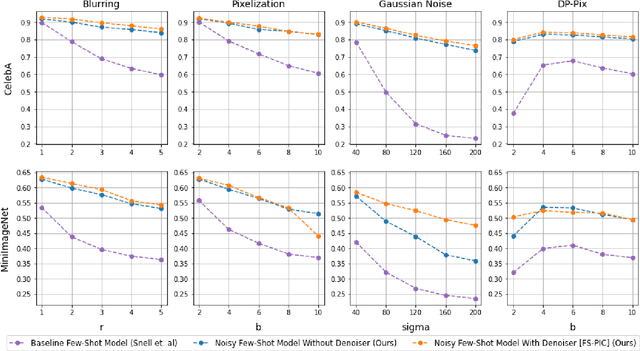
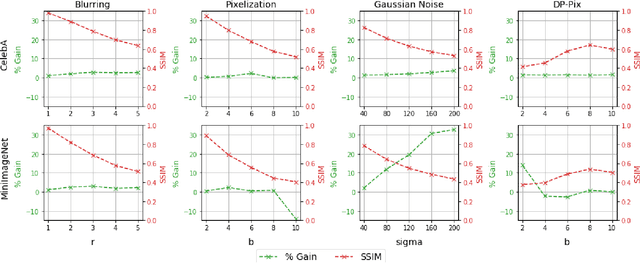
Requiring less data for accurate models, few-shot learning has shown robustness and generality in many application domains. However, deploying few-shot models in untrusted environments may inflict privacy concerns, e.g., attacks or adversaries that may breach the privacy of user-supplied data. This paper studies the privacy enhancement for the few-shot learning in an untrusted environment, e.g., the cloud, by establishing a novel privacy-preserved embedding space that preserves the privacy of data and maintains the accuracy of the model. We examine the impact of various image privacy methods such as blurring, pixelization, Gaussian noise, and differentially private pixelization (DP-Pix) on few-shot image classification and propose a method that learns privacy-preserved representation through the joint loss. The empirical results show how privacy-performance trade-off can be negotiated for privacy-enhanced few-shot learning.
Learning from Few Examples: A Summary of Approaches to Few-Shot Learning
Mar 07, 2022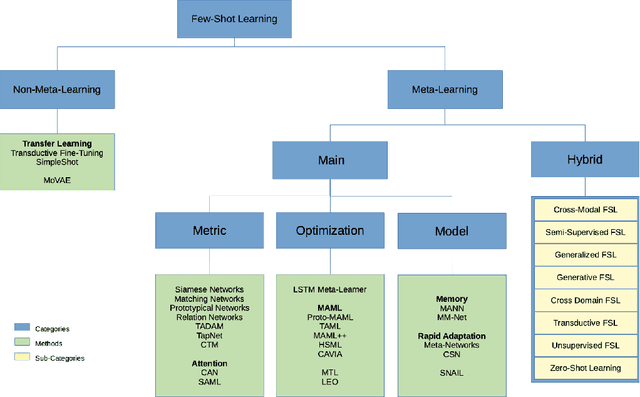

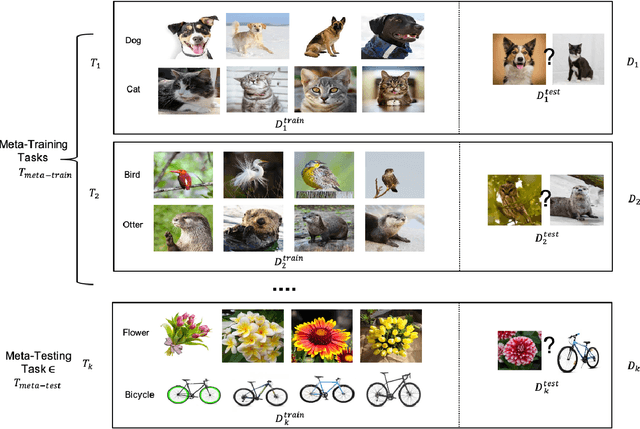

Few-Shot Learning refers to the problem of learning the underlying pattern in the data just from a few training samples. Requiring a large number of data samples, many deep learning solutions suffer from data hunger and extensively high computation time and resources. Furthermore, data is often not available due to not only the nature of the problem or privacy concerns but also the cost of data preparation. Data collection, preprocessing, and labeling are strenuous human tasks. Therefore, few-shot learning that could drastically reduce the turnaround time of building machine learning applications emerges as a low-cost solution. This survey paper comprises a representative list of recently proposed few-shot learning algorithms. Given the learning dynamics and characteristics, the approaches to few-shot learning problems are discussed in the perspectives of meta-learning, transfer learning, and hybrid approaches (i.e., different variations of the few-shot learning problem).
Towards Intrinsic Interactive Reinforcement Learning: A Survey
Dec 02, 2021
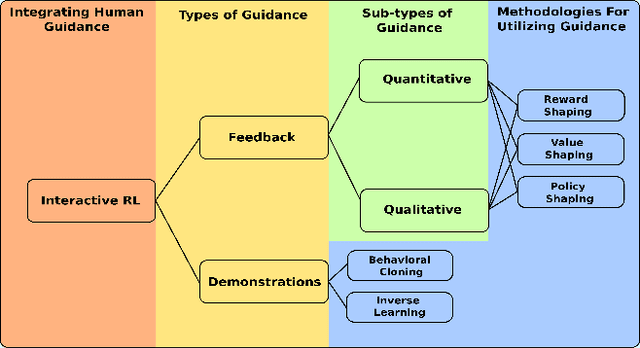
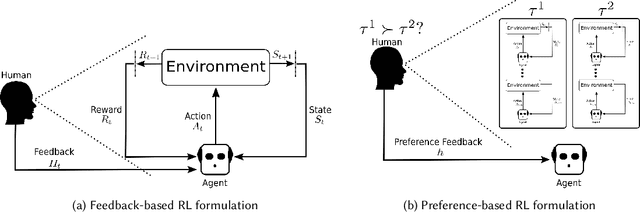
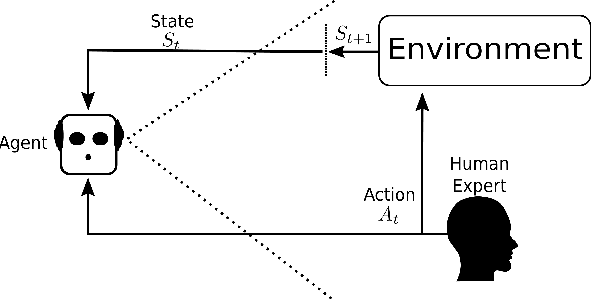
Reinforcement learning (RL) and brain-computer interfaces (BCI) are two fields that have been growing over the past decade. Until recently, these fields have operated independently of one another. With the rising interest in human-in-the-loop (HITL) applications, RL algorithms have been adapted to account for human guidance giving rise to the sub-field of interactive reinforcement learning (IRL). Adjacently, BCI applications have been long interested in extracting intrinsic feedback from neural activity during human-computer interactions. These two ideas have set RL and BCI on a collision course for one another through the integration of BCI into the IRL framework where intrinsic feedback can be utilized to help train an agent. This intersection has been denoted as intrinsic IRL. To further help facilitate deeper ingratiation of BCI and IRL, we provide a review of intrinsic IRL with an emphasis on its parent field of feedback-driven IRL while also providing discussions concerning the validity, challenges, and future research directions.