 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Forget the Critic: Value-Based Data Rehearsal for Multi-Cyclic Continual Reinforcement Learning
May 21, 2026Data rehearsal has emerged as a leading approach for mitigating catastrophic forgetting in Continual Reinforcement Learning (CRL). However, existing work remains confined to policy gradient frameworks, regularizing only actors due to the performance degradation incurred by critic regularization. This actor-centric approach overlooks the potential of data rehearsal for value function approximation. Moreover, existing evaluations in CRL rarely consider multi-cyclic environments where task sequences repeat, a critical real-world scenario that exacerbates forgetting and plasticity. We investigate data rehearsal for Deep Q-Networks using Q-value regularization in multi-cyclic settings and propose Qreg+NWLU which introduces two simple modifications: (1) continuous data rehearsal that dynamically collects and updates stored Q-values throughout training, and (2) "No-Wait" regularization that applies immediately rather than after the first task. Together, these modifications yield improvements in learning efficiency, forgetting mitigation, and knowledge transfer over Qreg and conventional CRL methods within value function approximation settings.
Error-related Potential Variability: Exploring the Effects on Classification and Transferability
Jan 16, 2023Brain-Computer Interfaces (BCI) have allowed for direct communication from the brain to external applications for the automatic detection of cognitive processes such as error recognition. Error-related potentials (ErrPs) are a particular brain signal elicited when one commits or observes an erroneous event. However, due to the noisy properties of the brain and recording devices, ErrPs vary from instance to instance as they are combined with an assortment of other brain signals, biological noise, and external noise, making the classification of ErrPs a non-trivial problem. Recent works have revealed particular cognitive processes such as awareness, embodiment, and predictability that contribute to ErrP variations. In this paper, we explore the performance of classifier transferability when trained on different ErrP variation datasets generated by varying the levels of awareness and embodiment for a given task. In particular, we look at transference between observational and interactive ErrP categories when elicited by similar and differing tasks. Our empirical results provide an exploratory analysis into the ErrP transferability problem from a data perspective.
Towards Intrinsic Interactive Reinforcement Learning: A Survey
Dec 02, 2021
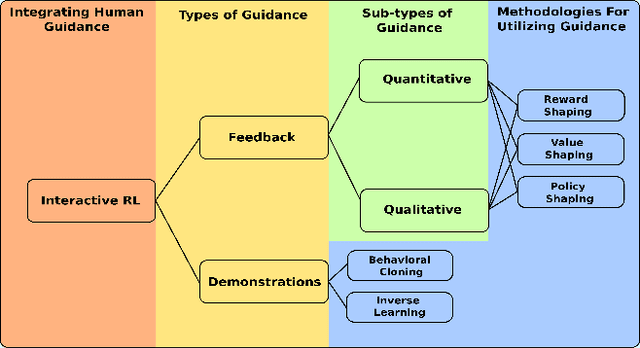
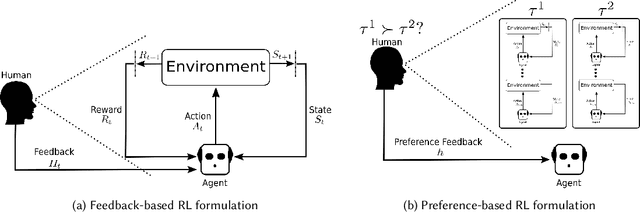
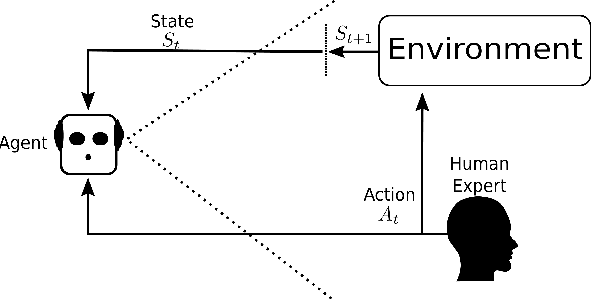
Reinforcement learning (RL) and brain-computer interfaces (BCI) are two fields that have been growing over the past decade. Until recently, these fields have operated independently of one another. With the rising interest in human-in-the-loop (HITL) applications, RL algorithms have been adapted to account for human guidance giving rise to the sub-field of interactive reinforcement learning (IRL). Adjacently, BCI applications have been long interested in extracting intrinsic feedback from neural activity during human-computer interactions. These two ideas have set RL and BCI on a collision course for one another through the integration of BCI into the IRL framework where intrinsic feedback can be utilized to help train an agent. This intersection has been denoted as intrinsic IRL. To further help facilitate deeper ingratiation of BCI and IRL, we provide a review of intrinsic IRL with an emphasis on its parent field of feedback-driven IRL while also providing discussions concerning the validity, challenges, and future research directions.