 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVFormer: Diversifying Feature Normalization and Token Mixing for Efficient Vision Transformers
Nov 28, 2024



Active research is currently underway to enhance the efficiency of vision transformers (ViTs). Most studies have focused solely on effective token mixers, overlooking the potential relationship with normalization. To boost diverse feature learning, we propose two components: a normalization module called multi-view normalization (MVN) and a token mixer called multi-view token mixer (MVTM). The MVN integrates three differently normalized features via batch, layer, and instance normalization using a learnable weighted sum. Each normalization method outputs a different distribution, generating distinct features. Thus, the MVN is expected to offer diverse pattern information to the token mixer, resulting in beneficial synergy. The MVTM is a convolution-based multiscale token mixer with local, intermediate, and global filters, and it incorporates stage specificity by configuring various receptive fields for the token mixer at each stage, efficiently capturing ranges of visual patterns. We propose a novel ViT model, multi-vision transformer (MVFormer), adopting the MVN and MVTM in the MetaFormer block, the generalized ViT scheme. Our MVFormer outperforms state-of-the-art convolution-based ViTs on image classification, object detection, and instance and semantic segmentation with the same or lower parameters and MACs. Particularly, MVFormer variants, MVFormer-T, S, and B achieve 83.4%, 84.3%, and 84.6% top-1 accuracy, respectively, on ImageNet-1K benchmark.
3D Equivariant Pose Regression via Direct Wigner-D Harmonics Prediction
Nov 04, 2024Determining the 3D orientations of an object in an image, known as single-image pose estimation, is a crucial task in 3D vision applications. Existing methods typically learn 3D rotations parametrized in the spatial domain using Euler angles or quaternions, but these representations often introduce discontinuities and singularities. SO(3)-equivariant networks enable the structured capture of pose patterns with data-efficient learning, but the parametrizations in spatial domain are incompatible with their architecture, particularly spherical CNNs, which operate in the frequency domain to enhance computational efficiency. To overcome these issues, we propose a frequency-domain approach that directly predicts Wigner-D coefficients for 3D rotation regression, aligning with the operations of spherical CNNs. Our SO(3)-equivariant pose harmonics predictor overcomes the limitations of spatial parameterizations, ensuring consistent pose estimation under arbitrary rotations. Trained with a frequency-domain regression loss, our method achieves state-of-the-art results on benchmarks such as ModelNet10-SO(3) and PASCAL3D+, with significant improvements in accuracy, robustness, and data efficiency.
In Defense of Lazy Visual Grounding for Open-Vocabulary Semantic Segmentation
Aug 09, 2024We present lazy visual grounding, a two-stage approach of unsupervised object mask discovery followed by object grounding, for open-vocabulary semantic segmentation. Plenty of the previous art casts this task as pixel-to-text classification without object-level comprehension, leveraging the image-to-text classification capability of pretrained vision-and-language models. We argue that visual objects are distinguishable without the prior text information as segmentation is essentially a vision task. Lazy visual grounding first discovers object masks covering an image with iterative Normalized cuts and then later assigns text on the discovered objects in a late interaction manner. Our model requires no additional training yet shows great performance on five public datasets: Pascal VOC, Pascal Context, COCO-object, COCO-stuff, and ADE 20K. Especially, the visually appealing segmentation results demonstrate the model capability to localize objects precisely. Paper homepage: https://cvlab.postech.ac.kr/research/lazygrounding
Online Temporal Action Localization with Memory-Augmented Transformer
Aug 06, 2024



Online temporal action localization (On-TAL) is the task of identifying multiple action instances given a streaming video. Since existing methods take as input only a video segment of fixed size per iteration, they are limited in considering long-term context and require tuning the segment size carefully. To overcome these limitations, we propose memory-augmented transformer (MATR). MATR utilizes the memory queue that selectively preserves the past segment features, allowing to leverage long-term context for inference. We also propose a novel action localization method that observes the current input segment to predict the end time of the ongoing action and accesses the memory queue to estimate the start time of the action. Our method outperformed existing methods on two datasets, THUMOS14 and MUSES, surpassing not only TAL methods in the online setting but also some offline TAL methods.
Classification Matters: Improving Video Action Detection with Class-Specific Attention
Jul 29, 2024



Video action detection (VAD) aims to detect actors and classify their actions in a video. We figure that VAD suffers more from classification rather than localization of actors. Hence, we analyze how prevailing methods form features for classification and find that they prioritize actor regions, yet often overlooking the essential contextual information necessary for accurate classification. Accordingly, we propose to reduce the bias toward actor and encourage paying attention to the context that is relevant to each action class. By assigning a class-dedicated query to each action class, our model can dynamically determine where to focus for effective classification. The proposed model demonstrates superior performance on three challenging benchmarks with significantly fewer parameters and less computation.
3D Geometric Shape Assembly via Efficient Point Cloud Matching
Jul 15, 2024



Learning to assemble geometric shapes into a larger target structure is a pivotal task in various practical applications. In this work, we tackle this problem by establishing local correspondences between point clouds of part shapes in both coarse- and fine-levels. To this end, we introduce Proxy Match Transform (PMT), an approximate high-order feature transform layer that enables reliable matching between mating surfaces of parts while incurring low costs in memory and computation. Building upon PMT, we introduce a new framework, dubbed Proxy Match TransformeR (PMTR), for the geometric assembly task. We evaluate the proposed PMTR on the large-scale 3D geometric shape assembly benchmark dataset of Breaking Bad and demonstrate its superior performance and efficiency compared to state-of-the-art methods. Project page: https://nahyuklee.github.io/pmtr.
Burst Image Super-Resolution with Base Frame Selection
Jun 25, 2024Burst image super-resolution has been a topic of active research in recent years due to its ability to obtain a high-resolution image by using complementary information between multiple frames in the burst. In this work, we explore using burst shots with non-uniform exposures to confront real-world practical scenarios by introducing a new benchmark dataset, dubbed Non-uniformly Exposed Burst Image (NEBI), that includes the burst frames at varying exposure times to obtain a broader range of irradiance and motion characteristics within a scene. As burst shots with non-uniform exposures exhibit varying levels of degradation, fusing information of the burst shots into the first frame as a base frame may not result in optimal image quality. To address this limitation, we propose a Frame Selection Network (FSN) for non-uniform scenarios. This network seamlessly integrates into existing super-resolution methods in a plug-and-play manner with low computational costs. The comparative analysis reveals the effectiveness of the nonuniform setting for the practical scenario and our FSN on synthetic-/real- NEBI datasets.
Multi-view Image Prompted Multi-view Diffusion for Improved 3D Generation
Apr 26, 2024Using image as prompts for 3D generation demonstrate particularly strong performances compared to using text prompts alone, for images provide a more intuitive guidance for the 3D generation process. In this work, we delve into the potential of using multiple image prompts, instead of a single image prompt, for 3D generation. Specifically, we build on ImageDream, a novel image-prompt multi-view diffusion model, to support multi-view images as the input prompt. Our method, dubbed MultiImageDream, reveals that transitioning from a single-image prompt to multiple-image prompts enhances the performance of multi-view and 3D object generation according to various quantitative evaluation metrics and qualitative assessments. This advancement is achieved without the necessity of fine-tuning the pre-trained ImageDream multi-view diffusion model.
Learning SO(3)-Invariant Semantic Correspondence via Local Shape Transform
Apr 17, 2024



Establishing accurate 3D correspondences between shapes stands as a pivotal challenge with profound implications for computer vision and robotics. However, existing self-supervised methods for this problem assume perfect input shape alignment, restricting their real-world applicability. In this work, we introduce a novel self-supervised Rotation-Invariant 3D correspondence learner with Local Shape Transform, dubbed RIST, that learns to establish dense correspondences between shapes even under challenging intra-class variations and arbitrary orientations. Specifically, RIST learns to dynamically formulate an SO(3)-invariant local shape transform for each point, which maps the SO(3)-equivariant global shape descriptor of the input shape to a local shape descriptor. These local shape descriptors are provided as inputs to our decoder to facilitate point cloud self- and cross-reconstruction. Our proposed self-supervised training pipeline encourages semantically corresponding points from different shapes to be mapped to similar local shape descriptors, enabling RIST to establish dense point-wise correspondences. RIST demonstrates state-of-the-art performances on 3D part label transfer and semantic keypoint transfer given arbitrarily rotated point cloud pairs, outperforming existing methods by significant margins.
Enhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences
Apr 16, 2024

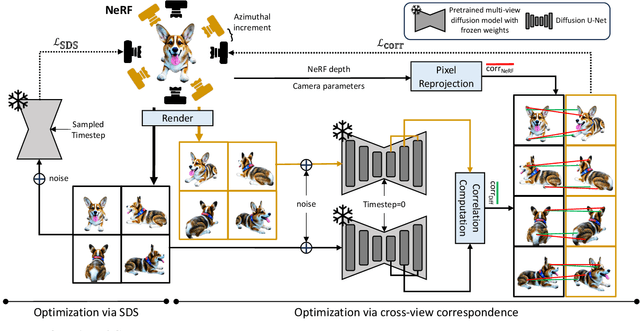

Leveraging multi-view diffusion models as priors for 3D optimization have alleviated the problem of 3D consistency, e.g., the Janus face problem or the content drift problem, in zero-shot text-to-3D models. However, the 3D geometric fidelity of the output remains an unresolved issue; albeit the rendered 2D views are realistic, the underlying geometry may contain errors such as unreasonable concavities. In this work, we propose CorrespondentDream, an effective method to leverage annotation-free, cross-view correspondences yielded from the diffusion U-Net to provide additional 3D prior to the NeRF optimization process. We find that these correspondences are strongly consistent with human perception, and by adopting it in our loss design, we are able to produce NeRF models with geometries that are more coherent with common sense, e.g., more smoothed object surface, yielding higher 3D fidelity. We demonstrate the efficacy of our approach through various comparative qualitative results and a solid user study.