 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Third Workshop on Neural Generation and Translation
Oct 30, 2019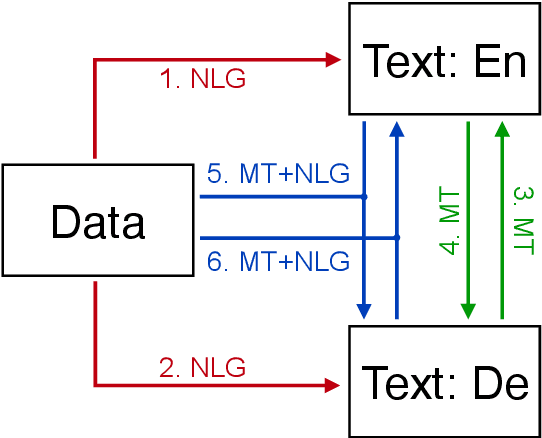
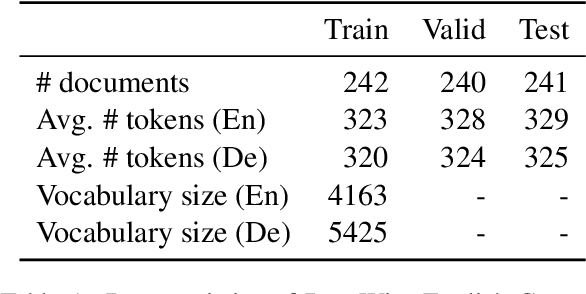
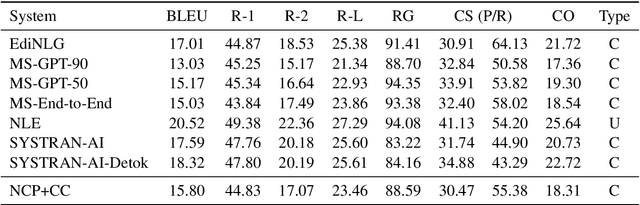
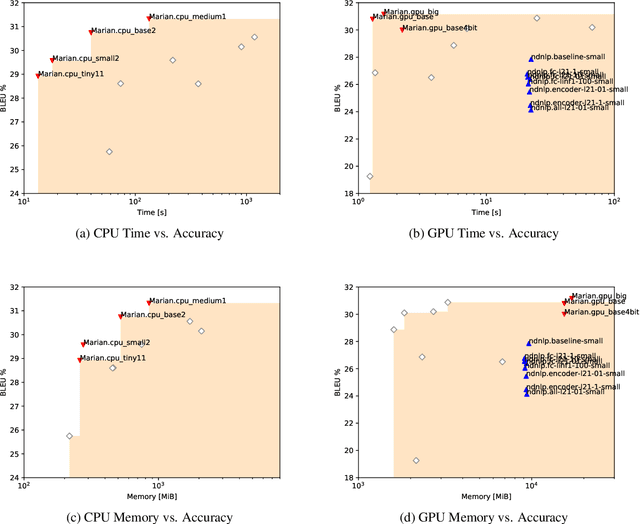
This document describes the findings of the Third Workshop on Neural Generation and Translation, held in concert with the annual conference of the Empirical Methods in Natural Language Processing (EMNLP 2019). First, we summarize the research trends of papers presented in the proceedings. Second, we describe the results of the two shared tasks 1) efficient neural machine translation (NMT) where participants were tasked with creating NMT systems that are both accurate and efficient, and 2) document-level generation and translation (DGT) where participants were tasked with developing systems that generate summaries from structured data, potentially with assistance from text in another language.
Selfie: Self-supervised Pretraining for Image Embedding
Jul 23, 2019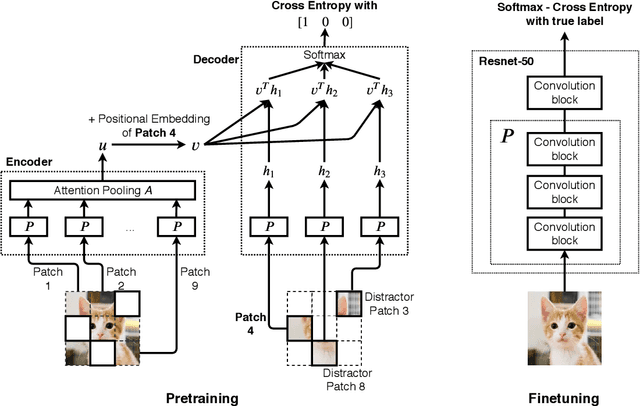
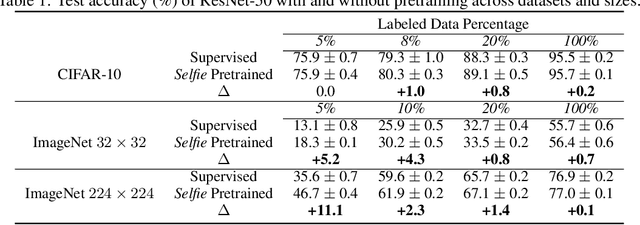

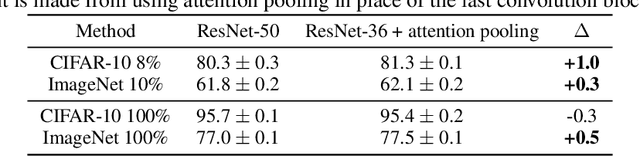
We introduce a pretraining technique called Selfie, which stands for SELFie supervised Image Embedding. Selfie generalizes the concept of masked language modeling of BERT (Devlin et al., 2019) to continuous data, such as images, by making use of the Contrastive Predictive Coding loss (Oord et al., 2018). Given masked-out patches in an input image, our method learns to select the correct patch, among other "distractor" patches sampled from the same image, to fill in the masked location. This classification objective sidesteps the need for predicting exact pixel values of the target patches. The pretraining architecture of Selfie includes a network of convolutional blocks to process patches followed by an attention pooling network to summarize the content of unmasked patches before predicting masked ones. During finetuning, we reuse the convolutional weights found by pretraining. We evaluate Selfie on three benchmarks (CIFAR-10, ImageNet 32 x 32, and ImageNet 224 x 224) with varying amounts of labeled data, from 5% to 100% of the training sets. Our pretraining method provides consistent improvements to ResNet-50 across all settings compared to the standard supervised training of the same network. Notably, on ImageNet 224 x 224 with 60 examples per class (5%), our method improves the mean accuracy of ResNet-50 from 35.6% to 46.7%, an improvement of 11.1 points in absolute accuracy. Our pretraining method also improves ResNet-50 training stability, especially on low data regime, by significantly lowering the standard deviation of test accuracies across different runs.
BAM! Born-Again Multi-Task Networks for Natural Language Understanding
Jul 10, 2019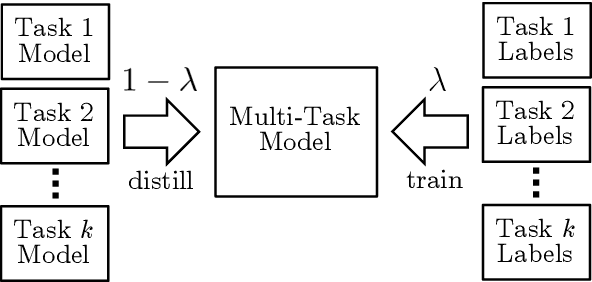
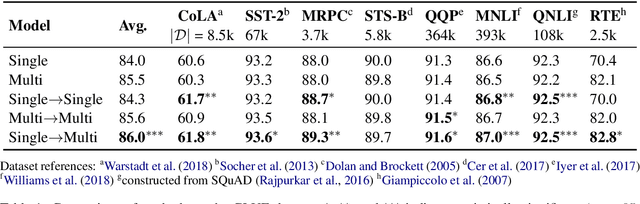
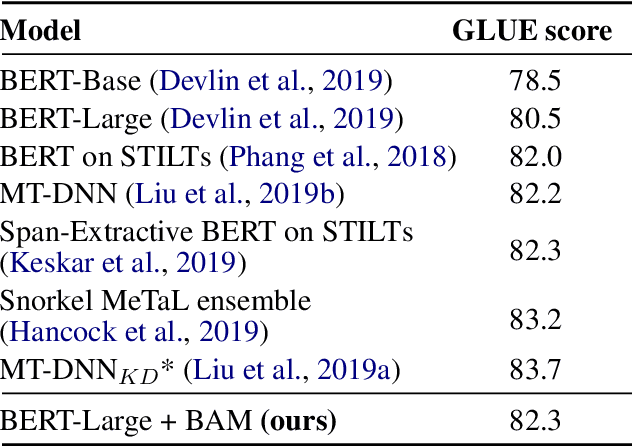
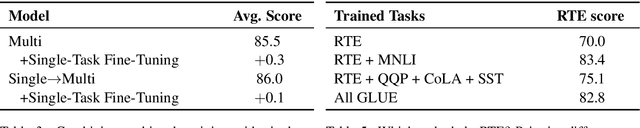
It can be challenging to train multi-task neural networks that outperform or even match their single-task counterparts. To help address this, we propose using knowledge distillation where single-task models teach a multi-task model. We enhance this training with teacher annealing, a novel method that gradually transitions the model from distillation to supervised learning, helping the multi-task model surpass its single-task teachers. We evaluate our approach by multi-task fine-tuning BERT on the GLUE benchmark. Our method consistently improves over standard single-task and multi-task training.
Unsupervised Data Augmentation
Apr 29, 2019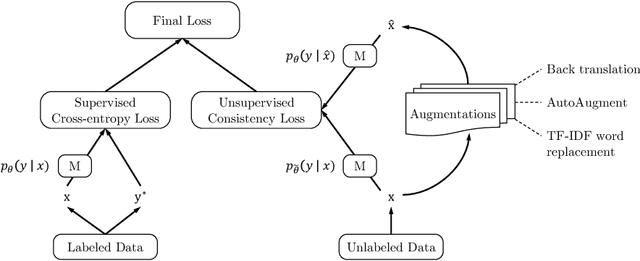
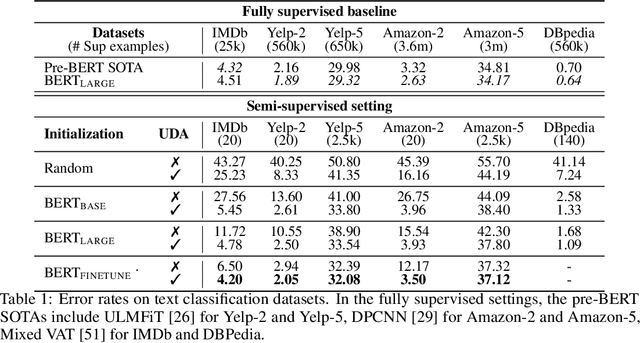
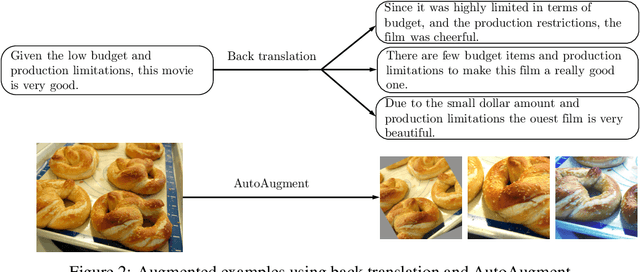

Despite its success, deep learning still needs large labeled datasets to succeed. Data augmentation has shown much promise in alleviating the need for more labeled data, but it so far has mostly been applied in supervised settings and achieved limited gains. In this work, we propose to apply data augmentation to unlabeled data in a semi-supervised learning setting. Our method, named Unsupervised Data Augmentation or UDA, encourages the model predictions to be consistent between an unlabeled example and an augmented unlabeled example. Unlike previous methods that use random noise such as Gaussian noise or dropout noise, UDA has a small twist in that it makes use of harder and more realistic noise generated by state-of-the-art data augmentation methods. This small twist leads to substantial improvements on six language tasks and three vision tasks even when the labeled set is extremely small. For example, on the IMDb text classification dataset, with only 20 labeled examples, UDA outperforms the state-of-the-art model trained on 25,000 labeled examples. On standard semi-supervised learning benchmarks, CIFAR-10 with 4,000 examples and SVHN with 1,000 examples, UDA outperforms all previous approaches and reduces more than $30\%$ of the error rates of state-of-the-art methods: going from 7.66% to 5.27% and from 3.53% to 2.46% respectively. UDA also works well on datasets that have a lot of labeled data. For example, on ImageNet, with 1.3M extra unlabeled data, UDA improves the top-1/top-5 accuracy from 78.28/94.36% to 79.04/94.45% when compared to AutoAugment.
Semi-Supervised Sequence Modeling with Cross-View Training
Sep 22, 2018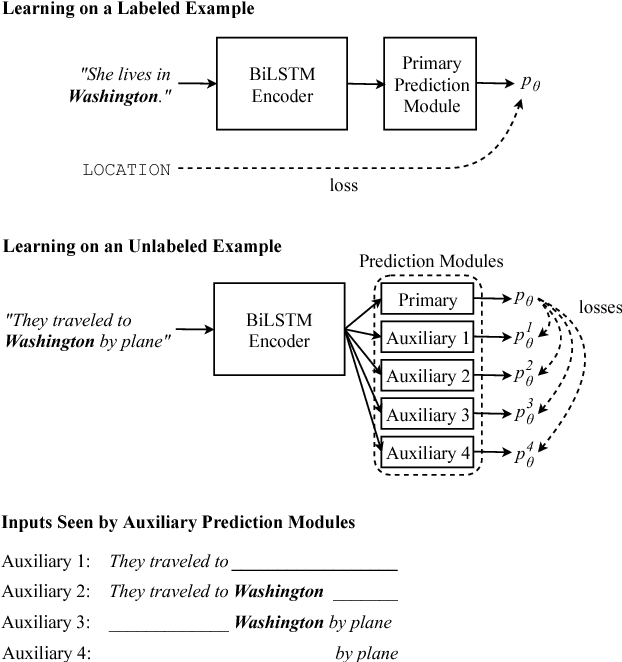
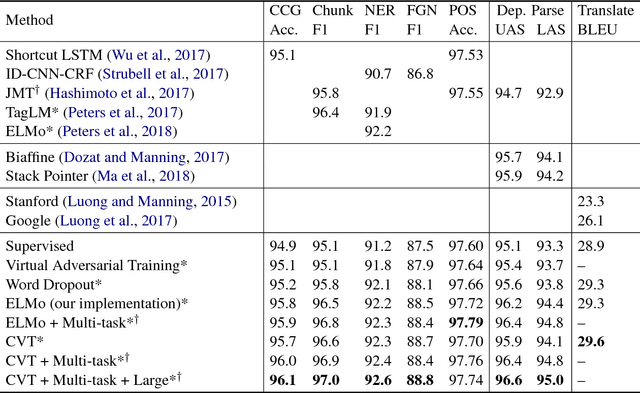
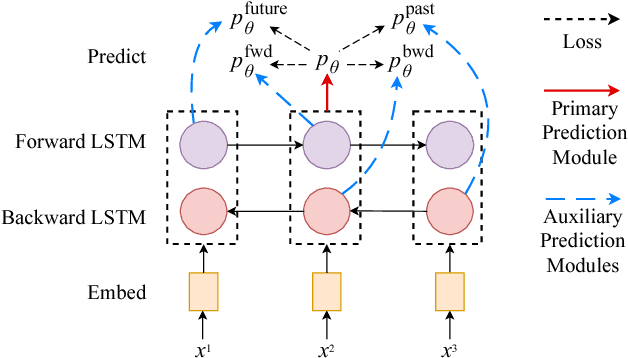
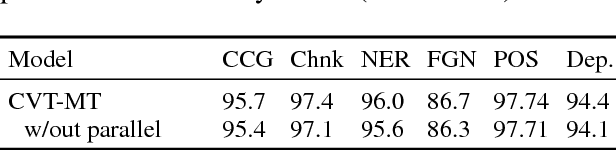
Unsupervised representation learning algorithms such as word2vec and ELMo improve the accuracy of many supervised NLP models, mainly because they can take advantage of large amounts of unlabeled text. However, the supervised models only learn from task-specific labeled data during the main training phase. We therefore propose Cross-View Training (CVT), a semi-supervised learning algorithm that improves the representations of a Bi-LSTM sentence encoder using a mix of labeled and unlabeled data. On labeled examples, standard supervised learning is used. On unlabeled examples, CVT teaches auxiliary prediction modules that see restricted views of the input (e.g., only part of a sentence) to match the predictions of the full model seeing the whole input. Since the auxiliary modules and the full model share intermediate representations, this in turn improves the full model. Moreover, we show that CVT is particularly effective when combined with multi-task learning. We evaluate CVT on five sequence tagging tasks, machine translation, and dependency parsing, achieving state-of-the-art results.
Latent Topic Conversational Models
Sep 19, 2018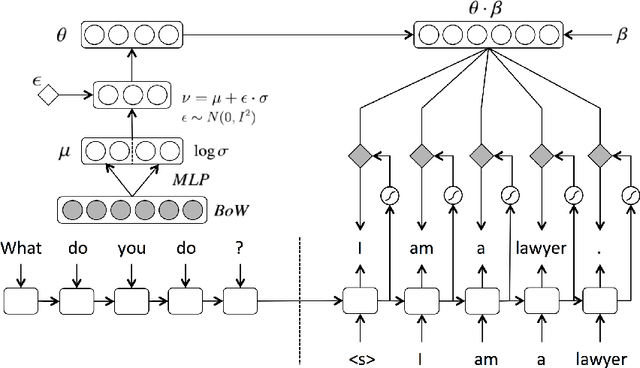
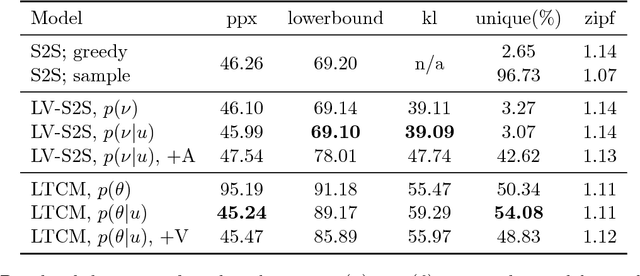

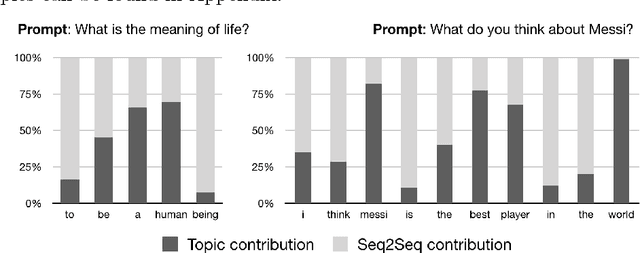
Latent variable models have been a preferred choice in conversational modeling compared to sequence-to-sequence (seq2seq) models which tend to generate generic and repetitive responses. Despite so, training latent variable models remains to be difficult. In this paper, we propose Latent Topic Conversational Model (LTCM) which augments seq2seq with a neural latent topic component to better guide response generation and make training easier. The neural topic component encodes information from the source sentence to build a global "topic" distribution over words, which is then consulted by the seq2seq model at each generation step. We study in details how the latent representation is learnt in both the vanilla model and LTCM. Our extensive experiments contribute to better understanding and training of conditional latent models for languages. Our results show that by sampling from the learnt latent representations, LTCM can generate diverse and interesting responses. In a subjective human evaluation, the judges also confirm that LTCM is the overall preferred option.
Findings of the Second Workshop on Neural Machine Translation and Generation
Jun 18, 2018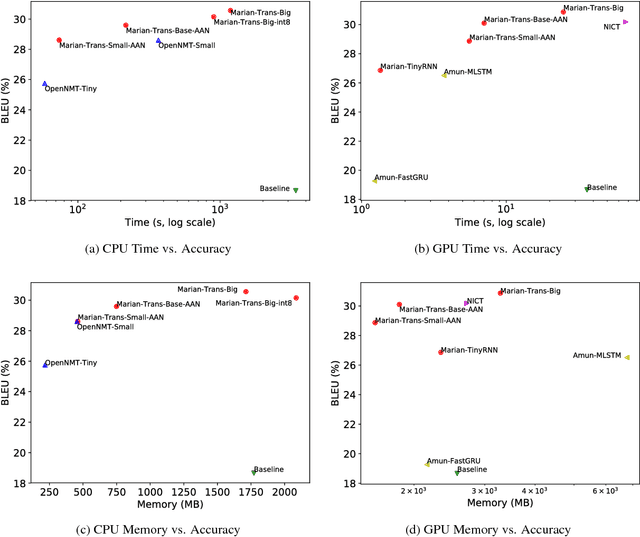
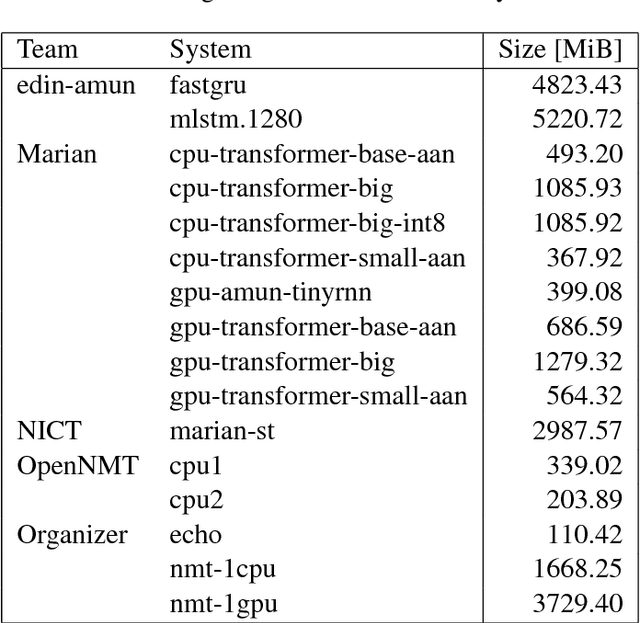
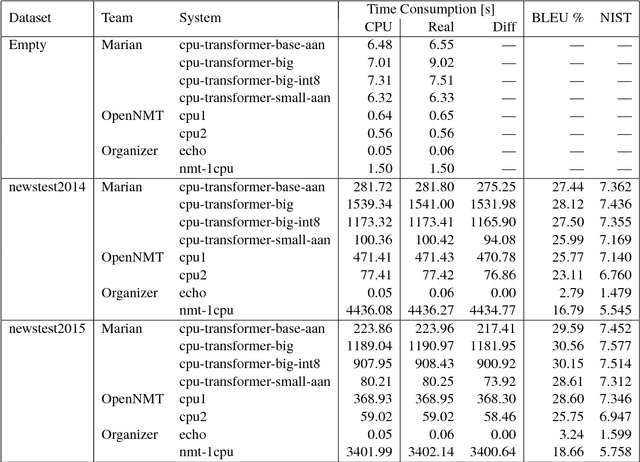
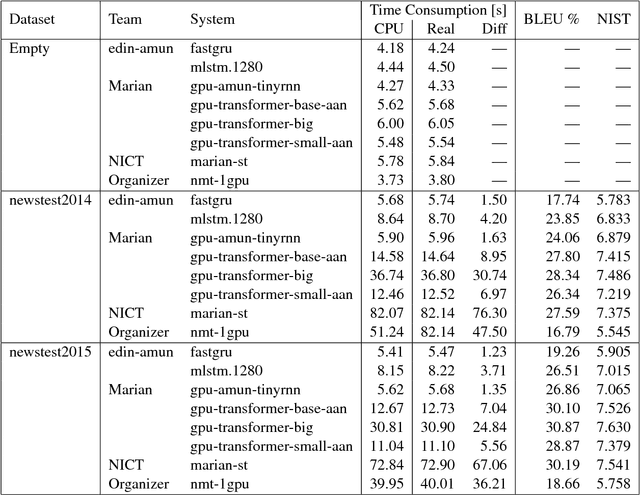
This document describes the findings of the Second Workshop on Neural Machine Translation and Generation, held in concert with the annual conference of the Association for Computational Linguistics (ACL 2018). First, we summarize the research trends of papers presented in the proceedings, and note that there is particular interest in linguistic structure, domain adaptation, data augmentation, handling inadequate resources, and analysis of models. Second, we describe the results of the workshop's shared task on efficient neural machine translation, where participants were tasked with creating MT systems that are both accurate and efficient.
Learning Longer-term Dependencies in RNNs with Auxiliary Losses
Jun 13, 2018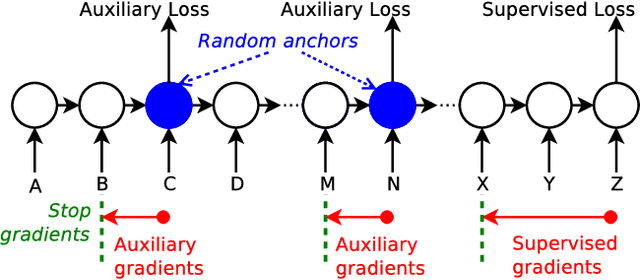
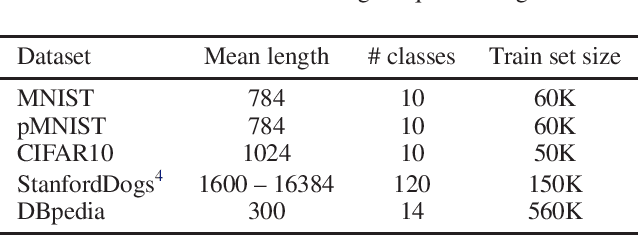
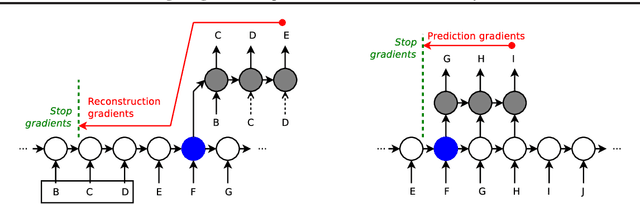
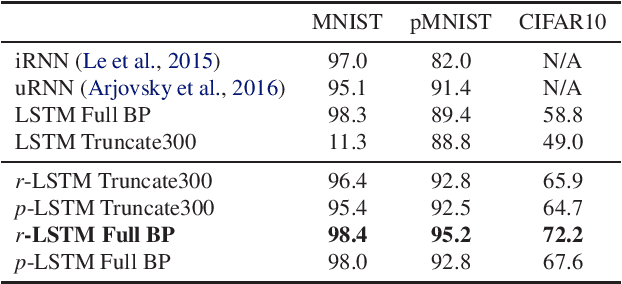
Despite recent advances in training recurrent neural networks (RNNs), capturing long-term dependencies in sequences remains a fundamental challenge. Most approaches use backpropagation through time (BPTT), which is difficult to scale to very long sequences. This paper proposes a simple method that improves the ability to capture long term dependencies in RNNs by adding an unsupervised auxiliary loss to the original objective. This auxiliary loss forces RNNs to either reconstruct previous events or predict next events in a sequence, making truncated backpropagation feasible for long sequences and also improving full BPTT. We evaluate our method on a variety of settings, including pixel-by-pixel image classification with sequence lengths up to 16\,000, and a real document classification benchmark. Our results highlight good performance and resource efficiency of this approach over competitive baselines, including other recurrent models and a comparable sized Transformer. Further analyses reveal beneficial effects of the auxiliary loss on optimization and regularization, as well as extreme cases where there is little to no backpropagation.
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
Apr 23, 2018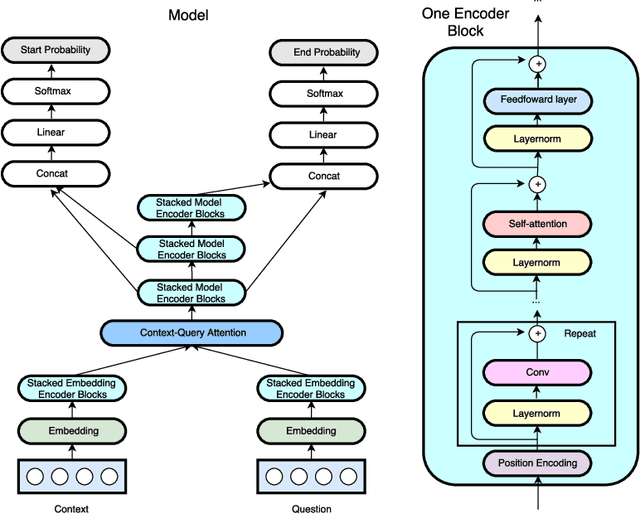

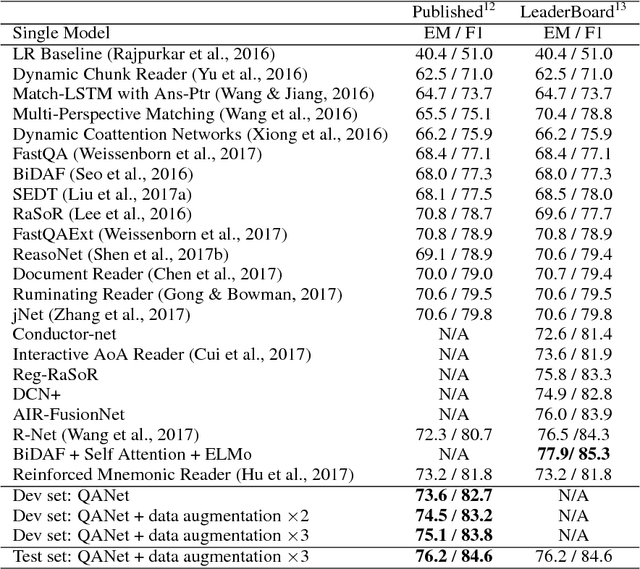
Current end-to-end machine reading and question answering (Q\&A) models are primarily based on recurrent neural networks (RNNs) with attention. Despite their success, these models are often slow for both training and inference due to the sequential nature of RNNs. We propose a new Q\&A architecture called QANet, which does not require recurrent networks: Its encoder consists exclusively of convolution and self-attention, where convolution models local interactions and self-attention models global interactions. On the SQuAD dataset, our model is 3x to 13x faster in training and 4x to 9x faster in inference, while achieving equivalent accuracy to recurrent models. The speed-up gain allows us to train the model with much more data. We hence combine our model with data generated by backtranslation from a neural machine translation model. On the SQuAD dataset, our single model, trained with augmented data, achieves 84.6 F1 score on the test set, which is significantly better than the best published F1 score of 81.8.
On the Effective Use of Pretraining for Natural Language Inference
Oct 05, 2017

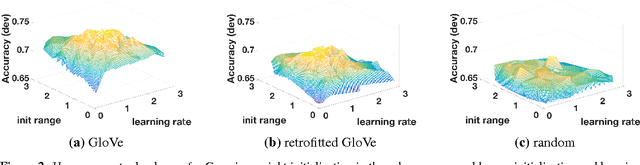

Neural networks have excelled at many NLP tasks, but there remain open questions about the performance of pretrained distributed word representations and their interaction with weight initialization and other hyperparameters. We address these questions empirically using attention-based sequence-to-sequence models for natural language inference (NLI). Specifically, we compare three types of embeddings: random, pretrained (GloVe, word2vec), and retrofitted (pretrained plus WordNet information). We show that pretrained embeddings outperform both random and retrofitted ones in a large NLI corpus. Further experiments on more controlled data sets shed light on the contexts for which retrofitted embeddings can be useful. We also explore two principled approaches to initializing the rest of the model parameters, Gaussian and orthogonal, showing that the latter yields gains of up to 2.9% in the NLI task.