 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of N-gram Language Models
Oct 08, 2019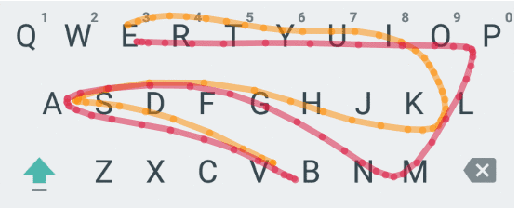

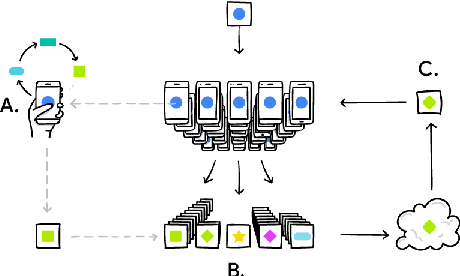
We propose algorithms to train production-quality n-gram language models using federated learning. Federated learning is a distributed computation platform that can be used to train global models for portable devices such as smart phones. Federated learning is especially relevant for applications handling privacy-sensitive data, such as virtual keyboards, because training is performed without the users' data ever leaving their devices. While the principles of federated learning are fairly generic, its methodology assumes that the underlying models are neural networks. However, virtual keyboards are typically powered by n-gram language models for latency reasons. We propose to train a recurrent neural network language model using the decentralized FederatedAveraging algorithm and to approximate this federated model server-side with an n-gram model that can be deployed to devices for fast inference. Our technical contributions include ways of handling large vocabularies, algorithms to correct capitalization errors in user data, and efficient finite state transducer algorithms to convert word language models to word-piece language models and vice versa. The n-gram language models trained with federated learning are compared to n-grams trained with traditional server-based algorithms using A/B tests on tens of millions of users of virtual keyboard. Results are presented for two languages, American English and Brazilian Portuguese. This work demonstrates that high-quality n-gram language models can be trained directly on client mobile devices without sensitive training data ever leaving the devices.
Federated Learning Of Out-Of-Vocabulary Words
Mar 26, 2019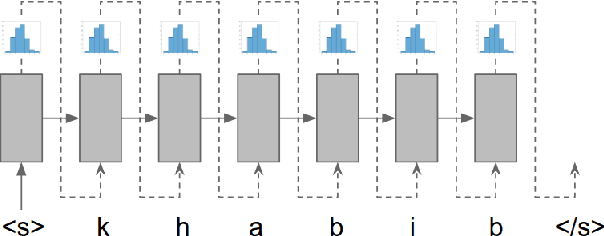
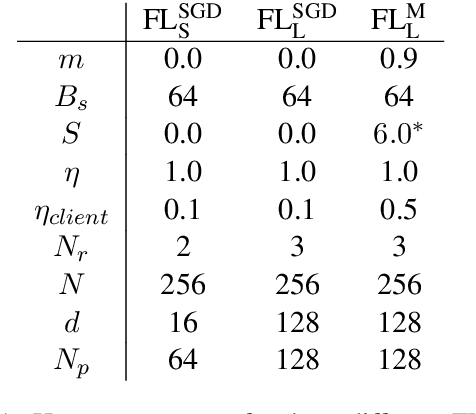
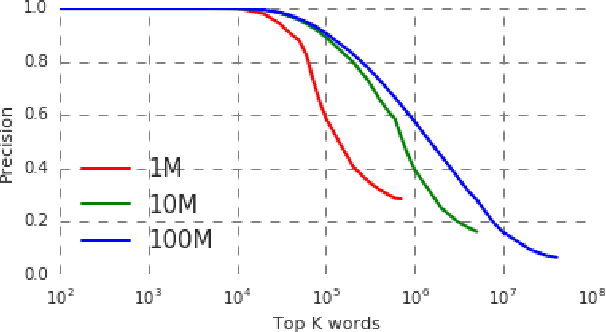

We demonstrate that a character-level recurrent neural network is able to learn out-of-vocabulary (OOV) words under federated learning settings, for the purpose of expanding the vocabulary of a virtual keyboard for smartphones without exporting sensitive text to servers. High-frequency words can be sampled from the trained generative model by drawing from the joint posterior directly. We study the feasibility of the approach in two settings: (1) using simulated federated learning on a publicly available non-IID per-user dataset from a popular social networking website, (2) using federated learning on data hosted on user mobile devices. The model achieves good recall and precision compared to ground-truth OOV words in setting (1). With (2) we demonstrate the practicality of this approach by showing that we can learn meaningful OOV words with good character-level prediction accuracy and cross entropy loss.
Automatic Liver Segmentation Using an Adversarial Image-to-Image Network
Jul 25, 2017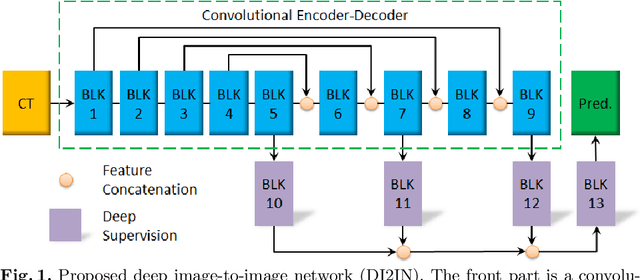
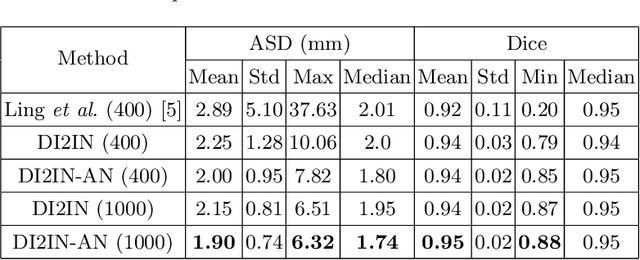
Automatic liver segmentation in 3D medical images is essential in many clinical applications, such as pathological diagnosis of hepatic diseases, surgical planning, and postoperative assessment. However, it is still a very challenging task due to the complex background, fuzzy boundary, and various appearance of liver. In this paper, we propose an automatic and efficient algorithm to segment liver from 3D CT volumes. A deep image-to-image network (DI2IN) is first deployed to generate the liver segmentation, employing a convolutional encoder-decoder architecture combined with multi-level feature concatenation and deep supervision. Then an adversarial network is utilized during training process to discriminate the output of DI2IN from ground truth, which further boosts the performance of DI2IN. The proposed method is trained on an annotated dataset of 1000 CT volumes with various different scanning protocols (e.g., contrast and non-contrast, various resolution and position) and large variations in populations (e.g., ages and pathology). Our approach outperforms the state-of-the-art solutions in terms of segmentation accuracy and computing efficiency.
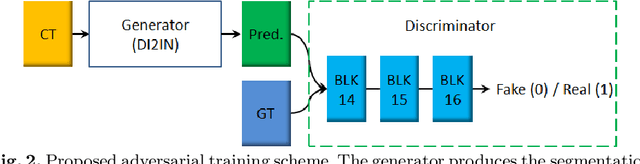
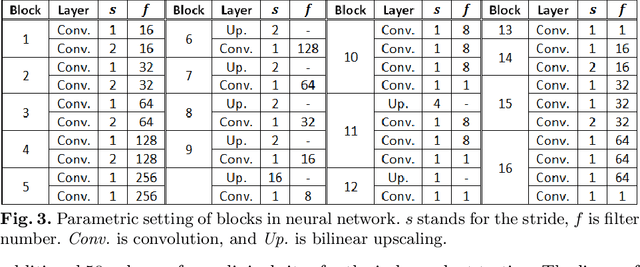
Automatic Vertebra Labeling in Large-Scale 3D CT using Deep Image-to-Image Network with Message Passing and Sparsity Regularization
May 17, 2017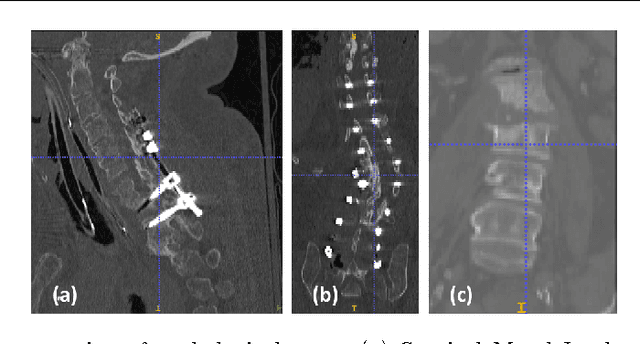
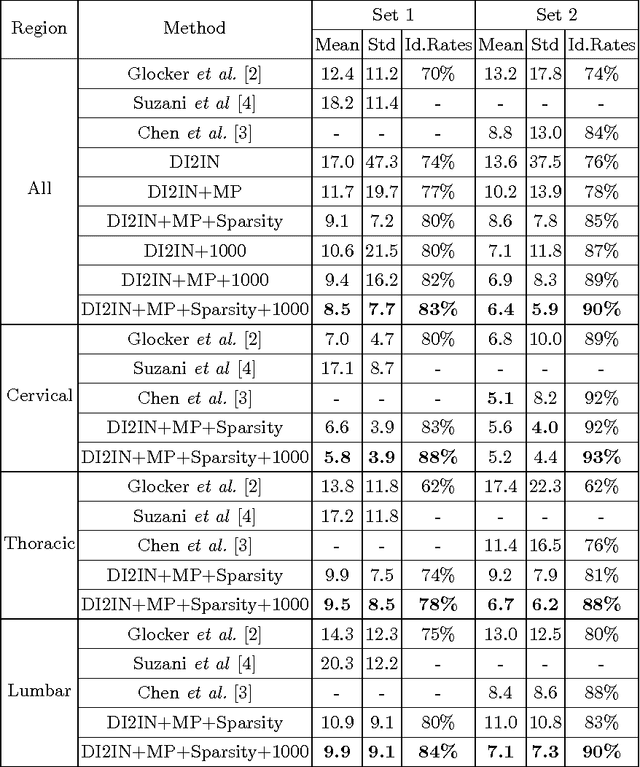

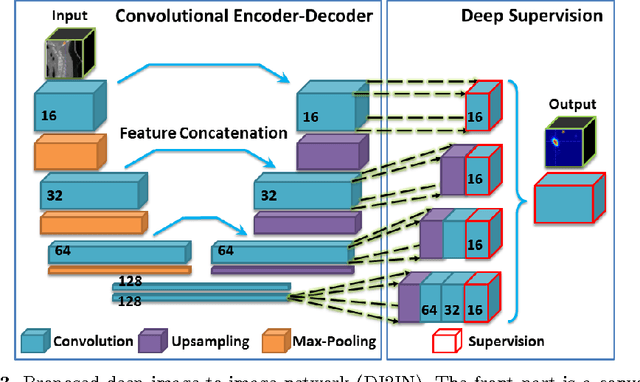
Automatic localization and labeling of vertebra in 3D medical images plays an important role in many clinical tasks, including pathological diagnosis, surgical planning and postoperative assessment. However, the unusual conditions of pathological cases, such as the abnormal spine curvature, bright visual imaging artifacts caused by metal implants, and the limited field of view, increase the difficulties of accurate localization. In this paper, we propose an automatic and fast algorithm to localize and label the vertebra centroids in 3D CT volumes. First, we deploy a deep image-to-image network (DI2IN) to initialize vertebra locations, employing the convolutional encoder-decoder architecture together with multi-level feature concatenation and deep supervision. Next, the centroid probability maps from DI2IN are iteratively evolved with the message passing schemes based on the mutual relation of vertebra centroids. Finally, the localization results are refined with sparsity regularization. The proposed method is evaluated on a public dataset of 302 spine CT volumes with various pathologies. Our method outperforms other state-of-the-art methods in terms of localization accuracy. The run time is around 3 seconds on average per case. To further boost the performance, we retrain the DI2IN on additional 1000+ 3D CT volumes from different patients. To the best of our knowledge, this is the first time more than 1000 3D CT volumes with expert annotation are adopted in experiments for the anatomic landmark detection tasks. Our experimental results show that training with such a large dataset significantly improves the performance and the overall identification rate, for the first time by our knowledge, reaches 90 %.