 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Shape Reconstruction from a Polarization Image
Jul 17, 2020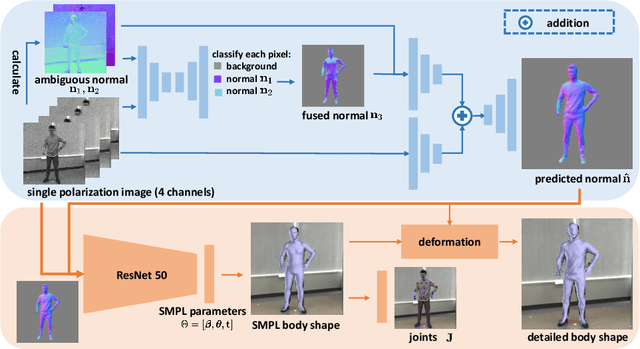
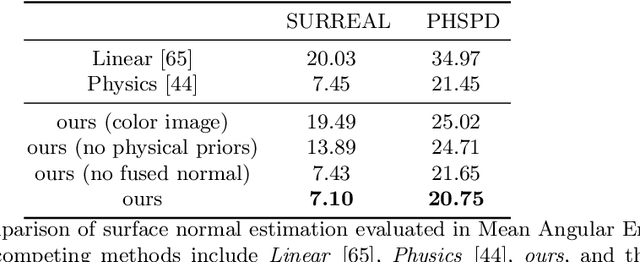


This paper tackles the problem of estimating 3D body shape of clothed humans from single polarized 2D images, i.e. polarization images. Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing surface normal of the objects of interest. Inspired by the recent advances in human shape estimation from single color images, in this paper, we attempt at estimating human body shapes by leveraging the geometric cues from single polarization images. A dedicated two-stage deep learning approach, SfP, is proposed: given a polarization image, stage one aims at inferring the fined-detailed body surface normal; stage two gears to reconstruct the 3D body shape of clothing details. Empirical evaluations on a synthetic dataset (SURREAL) as well as a real-world dataset (PHSPD) demonstrate the qualitative and quantitative performance of our approach in estimating human poses and shapes. This indicates polarization camera is a promising alternative to the more conventional color or depth imaging for human shape estimation. Further, normal maps inferred from polarization imaging play a significant role in accurately recovering the body shapes of clothed people.
SparseFusion: Dynamic Human Avatar Modeling from Sparse RGBD Images
Jun 05, 2020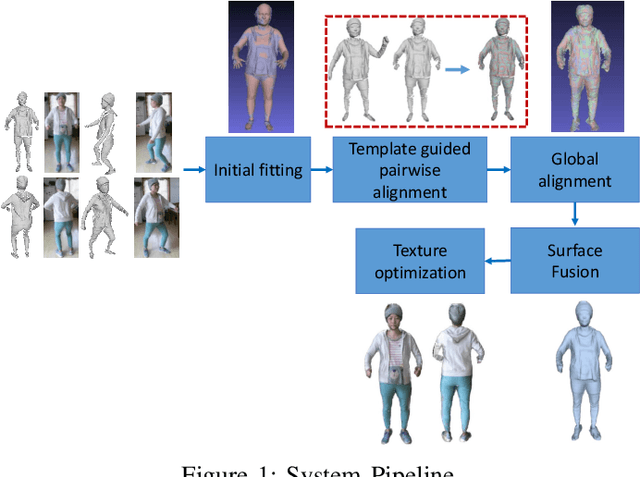

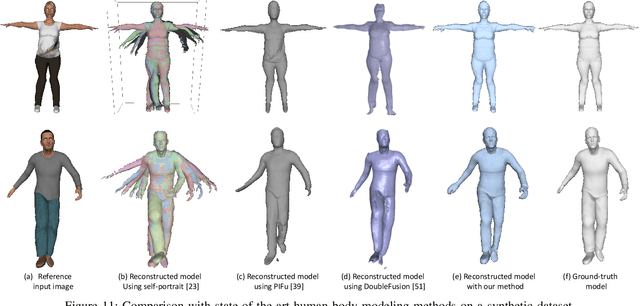
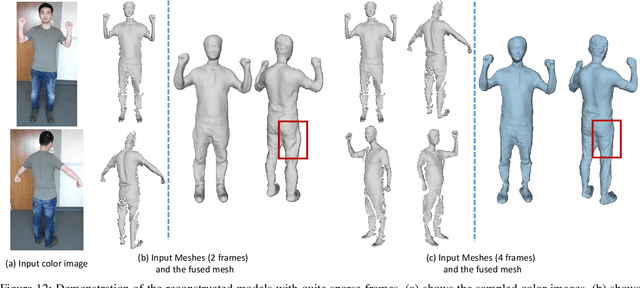
In this paper, we propose a novel approach to reconstruct 3D human body shapes based on a sparse set of RGBD frames using a single RGBD camera. We specifically focus on the realistic settings where human subjects move freely during the capture. The main challenge is how to robustly fuse these sparse frames into a canonical 3D model, under pose changes and surface occlusions. This is addressed by our new framework consisting of the following steps. First, based on a generative human template, for every two frames having sufficient overlap, an initial pairwise alignment is performed; It is followed by a global non-rigid registration procedure, in which partial results from RGBD frames are collected into a unified 3D shape, under the guidance of correspondences from the pairwise alignment; Finally, the texture map of the reconstructed human model is optimized to deliver a clear and spatially consistent texture. Empirical evaluations on synthetic and real datasets demonstrate both quantitatively and qualitatively the superior performance of our framework in reconstructing complete 3D human models with high fidelity. It is worth noting that our framework is flexible, with potential applications going beyond shape reconstruction. As an example, we showcase its use in reshaping and reposing to a new avatar.
Interlayer and Intralayer Scale Aggregation for Scale-invariant Crowd Counting
May 25, 2020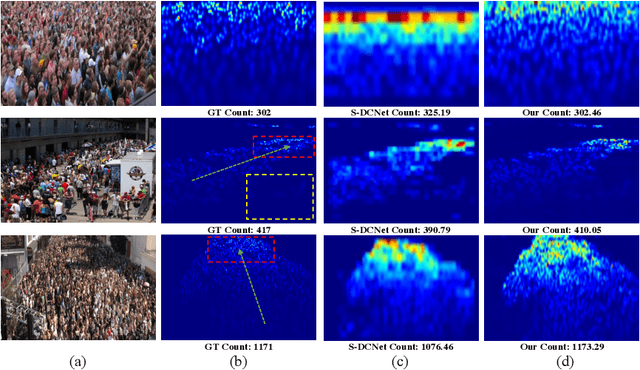
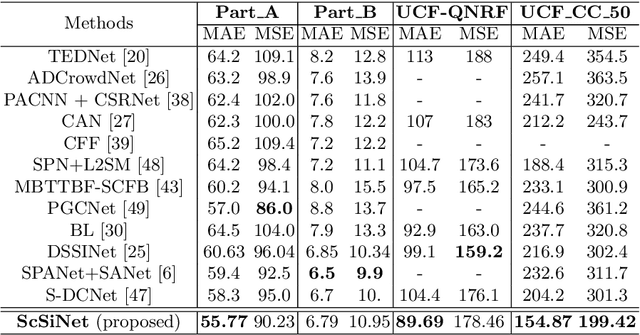
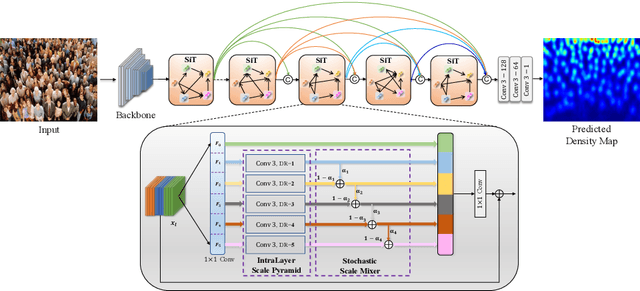

Crowd counting is an important vision task, which faces challenges on continuous scale variation within a given scene and huge density shift both within and across images. These challenges are typically addressed using multi-column structures in existing methods. However, such an approach does not provide consistent improvement and transferability due to limited ability in capturing multi-scale features, sensitiveness to large density shift, and difficulty in training multi-branch models. To overcome these limitations, a Single-column Scale-invariant Network (ScSiNet) is presented in this paper, which extracts sophisticated scale-invariant features via the combination of interlayer multi-scale integration and a novel intralayer scale-invariant transformation (SiT). Furthermore, in order to enlarge the diversity of densities, a randomly integrated loss is presented for training our single-branch method. Extensive experiments on public datasets demonstrate that the proposed method consistently outperforms state-of-the-art approaches in counting accuracy and achieves remarkable transferability and scale-invariant property.
Polarization Human Shape and Pose Dataset
Apr 30, 2020


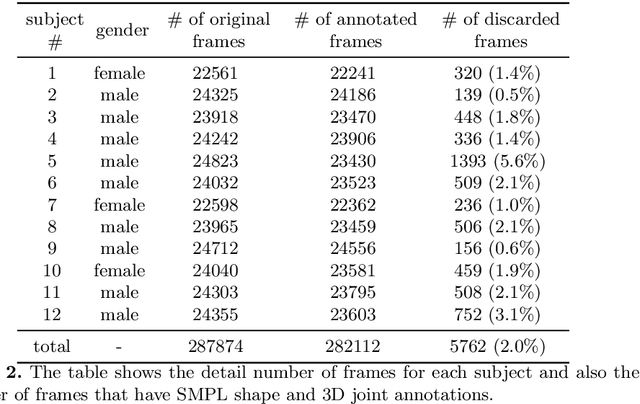
Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing detailed surface normal of the objects of interest. Meanwhile, inspired by the recent breakthroughs in human shape estimation from a single color image, we attempt to investigate the new question of whether the geometric cues from polarization camera could be leveraged in estimating detailed human body shapes. This has led to the curation of Polarization Human Shape and Pose Dataset (PHSPD)5, our home-grown polarization image dataset of various human shapes and poses.
ETNet: Error Transition Network for Arbitrary Style Transfer
Oct 29, 2019

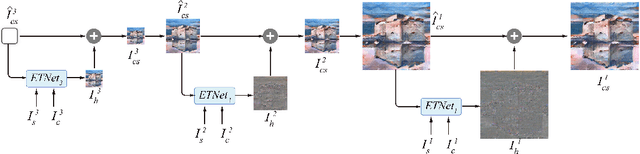

Numerous valuable efforts have been devoted to achieving arbitrary style transfer since the seminal work of Gatys et al. However, existing state-of-the-art approaches often generate insufficiently stylized results under challenging cases. We believe a fundamental reason is that these approaches try to generate the stylized result in a single shot and hence fail to fully satisfy the constraints on semantic structures in the content images and style patterns in the style images. Inspired by the works on error-correction, instead, we propose a self-correcting model to predict what is wrong with the current stylization and refine it accordingly in an iterative manner. For each refinement, we transit the error features across both the spatial and scale domain and invert the processed features into a residual image, with a network we call Error Transition Network (ETNet). The proposed model improves over the state-of-the-art methods with better semantic structures and more adaptive style pattern details. Various qualitative and quantitative experiments show that the key concept of both progressive strategy and error-correction leads to better results. Code and models are available at https://github.com/zhijieW94/ETNet.
Pair-wise Exchangeable Feature Extraction for Arbitrary Style Transfer
Nov 26, 2018
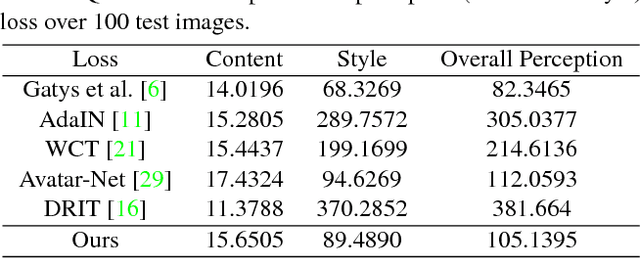
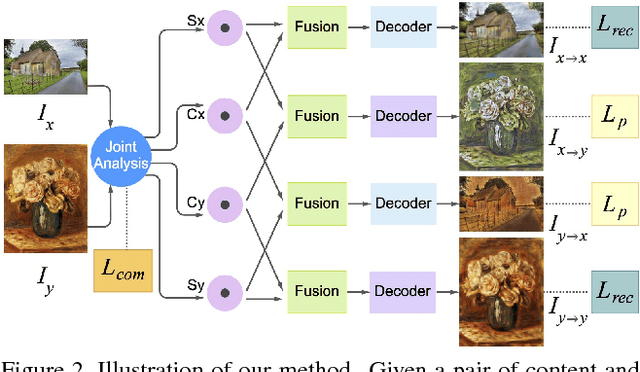
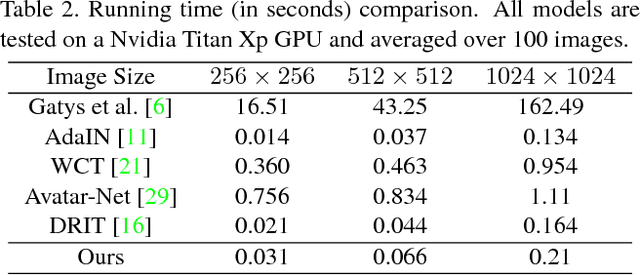
Style transfer has been an important topic in both computer vision and graphics. Gatys et al. first prove that deep features extracted by the pre-trained VGG network represent both content and style features of an image and hence, style transfer can be achieved through optimization in feature space. Huang et al. then show that real-time arbitrary style transfer can be done by simply aligning the mean and variance of each feature channel. In this paper, however, we argue that only aligning the global statistics of deep features cannot always guarantee a good style transfer. Instead, we propose to jointly analyze the input image pair and extract common/exchangeable style features between the two. Besides, a new fusion mode is developed for combining content and style information in feature space. Qualitative and quantitative experiments demonstrate the advantages of our approach.
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
Oct 09, 2018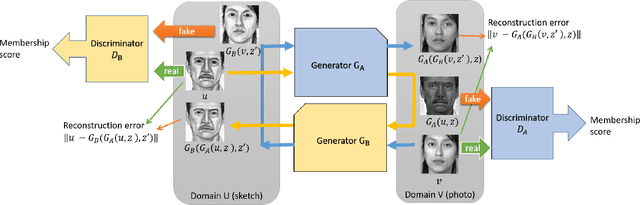
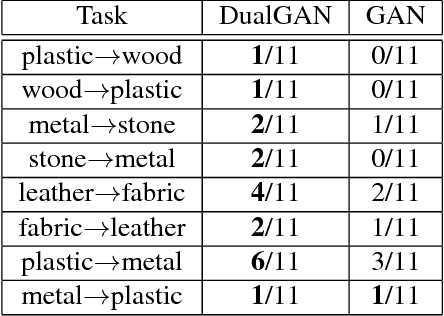

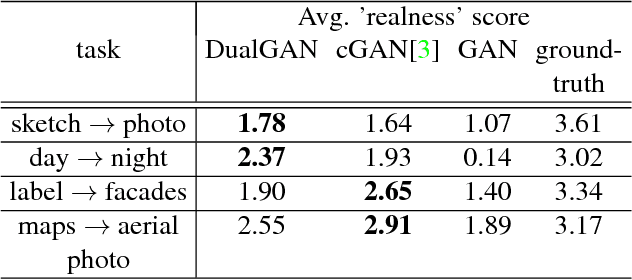
Conditional Generative Adversarial Networks (GANs) for cross-domain image-to-image translation have made much progress recently. Depending on the task complexity, thousands to millions of labeled image pairs are needed to train a conditional GAN. However, human labeling is expensive, even impractical, and large quantities of data may not always be available. Inspired by dual learning from natural language translation, we develop a novel dual-GAN mechanism, which enables image translators to be trained from two sets of unlabeled images from two domains. In our architecture, the primal GAN learns to translate images from domain U to those in domain V, while the dual GAN learns to invert the task. The closed loop made by the primal and dual tasks allows images from either domain to be translated and then reconstructed. Hence a loss function that accounts for the reconstruction error of images can be used to train the translators. Experiments on multiple image translation tasks with unlabeled data show considerable performance gain of DualGAN over a single GAN. For some tasks, DualGAN can even achieve comparable or slightly better results than conditional GAN trained on fully labeled data.
Multi-scale Convolution Aggregation and Stochastic Feature Reuse for DenseNets
Oct 02, 2018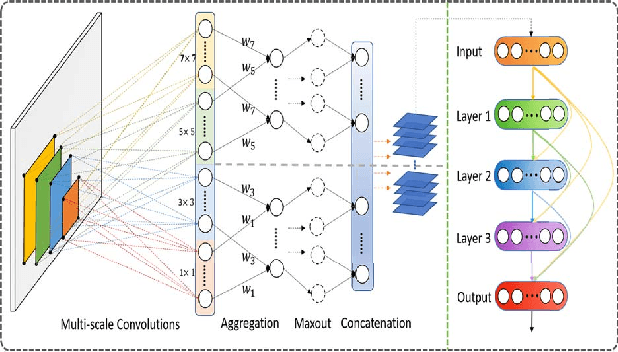
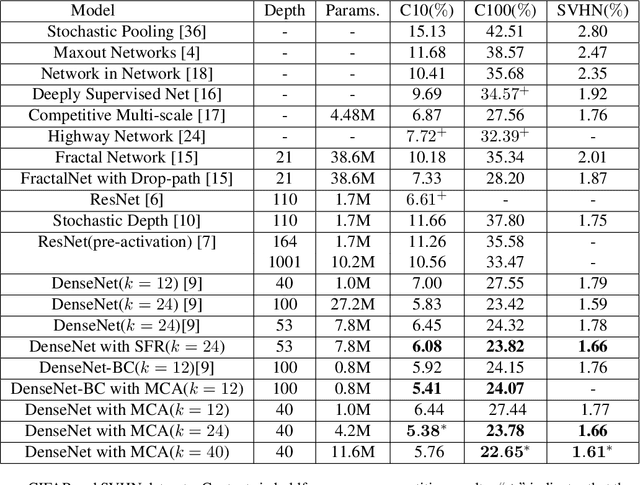

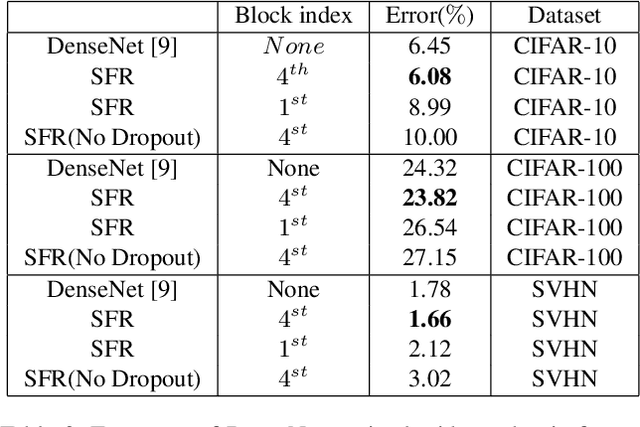
Recently, Convolution Neural Networks (CNNs) obtained huge success in numerous vision tasks. In particular, DenseNets have demonstrated that feature reuse via dense skip connections can effectively alleviate the difficulty of training very deep networks and that reusing features generated by the initial layers in all subsequent layers has strong impact on performance. To feed even richer information into the network, a novel adaptive Multi-scale Convolution Aggregation module is presented in this paper. Composed of layers for multi-scale convolutions, trainable cross-scale aggregation, maxout, and concatenation, this module is highly non-linear and can boost the accuracy of DenseNet while using much fewer parameters. In addition, due to high model complexity, the network with extremely dense feature reuse is prone to overfitting. To address this problem, a regularization method named Stochastic Feature Reuse is also presented. Through randomly dropping a set of feature maps to be reused for each mini-batch during the training phase, this regularization method reduces training costs and prevents co-adaptation. Experimental results on CIFAR-10, CIFAR-100 and SVHN benchmarks demonstrated the effectiveness of the proposed methods.
Semi-dense Stereo Matching using Dual CNNs
Oct 02, 2018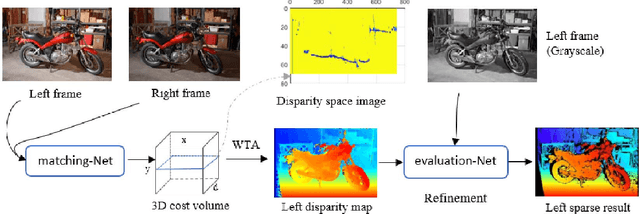
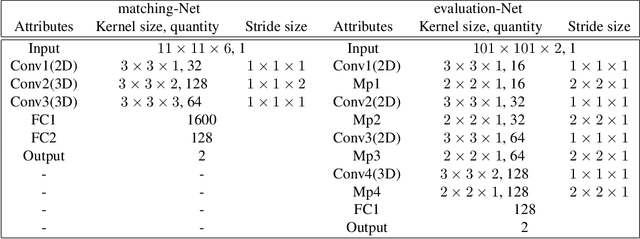
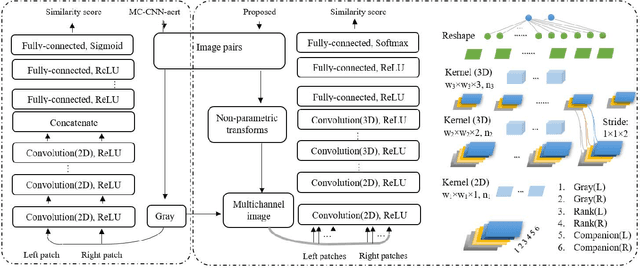
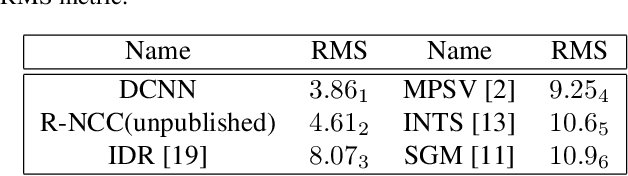
A robust solution for semi-dense stereo matching is presented. It utilizes two CNN models for computing stereo matching cost and performing confidence-based filtering, respectively. Compared to existing CNNs-based matching cost generation approaches, our method feeds additional global information into the network so that the learned model can better handle challenging cases, such as lighting changes and lack of textures. Through utilizing non-parametric transforms, our method is also more self-reliant than most existing semi-dense stereo approaches, which rely highly on the adjustment of parameters. The experimental results based on Middlebury Stereo dataset demonstrate that the proposed approach outperforms the state-of-the-art semi-dense stereo approaches.
Full 3D Reconstruction of Transparent Objects
May 14, 2018
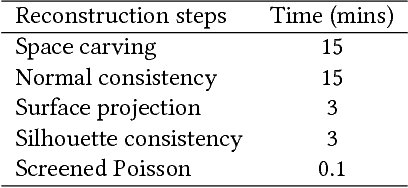
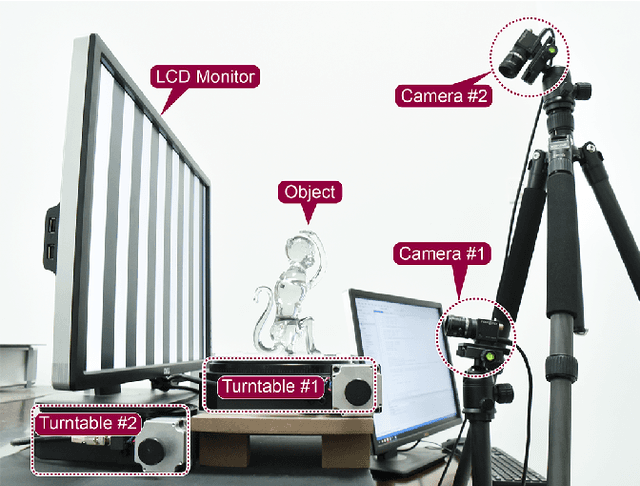
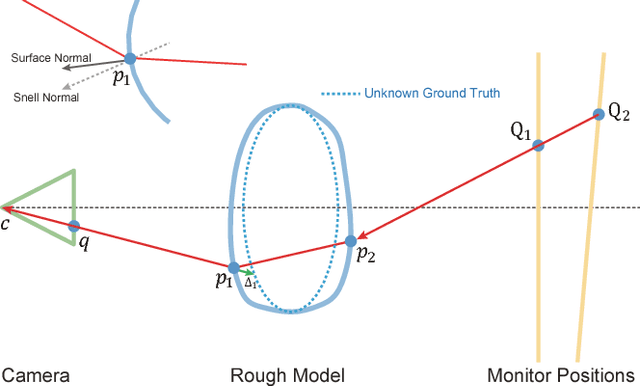
Numerous techniques have been proposed for reconstructing 3D models for opaque objects in past decades. However, none of them can be directly applied to transparent objects. This paper presents a fully automatic approach for reconstructing complete 3D shapes of transparent objects. Through positioning an object on a turntable, its silhouettes and light refraction paths under different viewing directions are captured. Then, starting from an initial rough model generated from space carving, our algorithm progressively optimizes the model under three constraints: surface and refraction normal consistency, surface projection and silhouette consistency, and surface smoothness. Experimental results on both synthetic and real objects demonstrate that our method can successfully recover the complex shapes of transparent objects and faithfully reproduce their light refraction properties.