 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Divergent Reference Texts when Evaluating Table-to-Text Generation
Jun 03, 2019


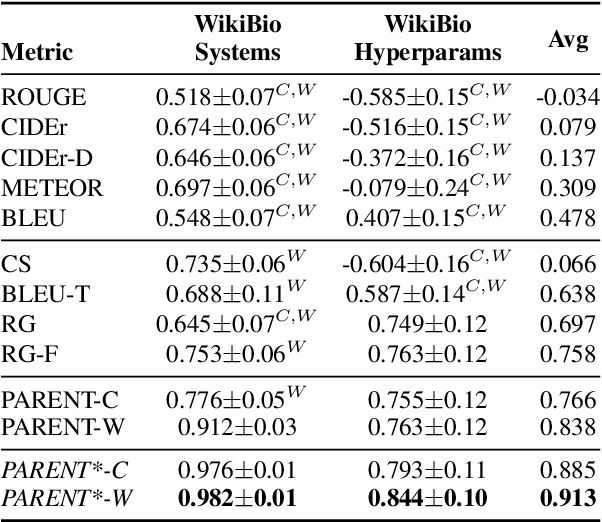
Automatically constructed datasets for generating text from semi-structured data (tables), such as WikiBio, often contain reference texts that diverge from the information in the corresponding semi-structured data. We show that metrics which rely solely on the reference texts, such as BLEU and ROUGE, show poor correlation with human judgments when those references diverge. We propose a new metric, PARENT, which aligns n-grams from the reference and generated texts to the semi-structured data before computing their precision and recall. Through a large scale human evaluation study of table-to-text models for WikiBio, we show that PARENT correlates with human judgments better than existing text generation metrics. We also adapt and evaluate the information extraction based evaluation proposed by Wiseman et al (2017), and show that PARENT has comparable correlation to it, while being easier to use. We show that PARENT is also applicable when the reference texts are elicited from humans using the data from the WebNLG challenge.
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
May 24, 2019

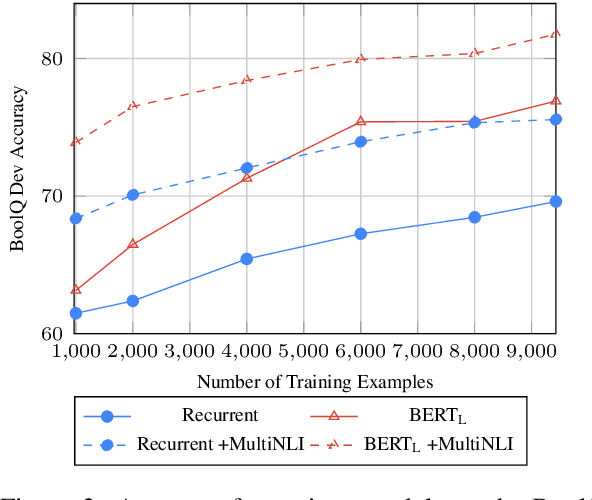
In this paper we study yes/no questions that are naturally occurring --- meaning that they are generated in unprompted and unconstrained settings. We build a reading comprehension dataset, BoolQ, of such questions, and show that they are unexpectedly challenging. They often query for complex, non-factoid information, and require difficult entailment-like inference to solve. We also explore the effectiveness of a range of transfer learning baselines. We find that transferring from entailment data is more effective than transferring from paraphrase or extractive QA data, and that it, surprisingly, continues to be very beneficial even when starting from massive pre-trained language models such as BERT. Our best method trains BERT on MultiNLI and then re-trains it on our train set. It achieves 80.4% accuracy compared to 90% accuracy of human annotators (and 62% majority-baseline), leaving a significant gap for future work.
Language Model Pre-training for Hierarchical Document Representations
Jan 26, 2019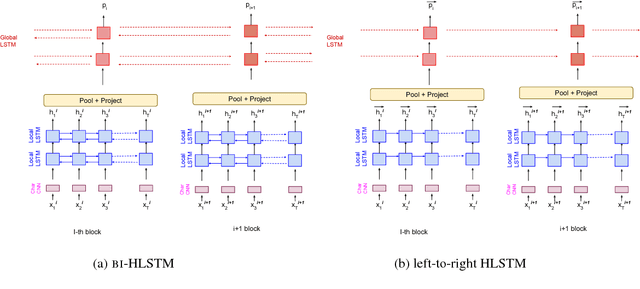

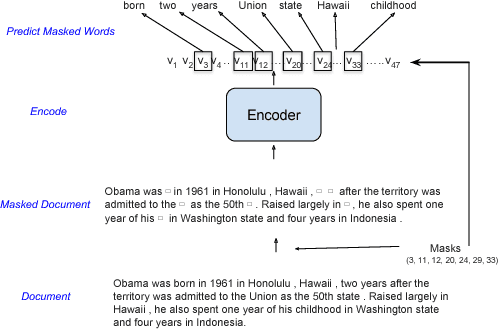

Hierarchical neural architectures are often used to capture long-distance dependencies and have been applied to many document-level tasks such as summarization, document segmentation, and sentiment analysis. However, effective usage of such a large context can be difficult to learn, especially in the case where there is limited labeled data available. Building on the recent success of language model pretraining methods for learning flat representations of text, we propose algorithms for pre-training hierarchical document representations from unlabeled data. Unlike prior work, which has focused on pre-training contextual token representations or context-independent {sentence/paragraph} representations, our hierarchical document representations include fixed-length sentence/paragraph representations which integrate contextual information from the entire documents. Experiments on document segmentation, document-level question answering, and extractive document summarization demonstrate the effectiveness of the proposed pre-training algorithms.
Improving Span-based Question Answering Systems with Coarsely Labeled Data
Nov 05, 2018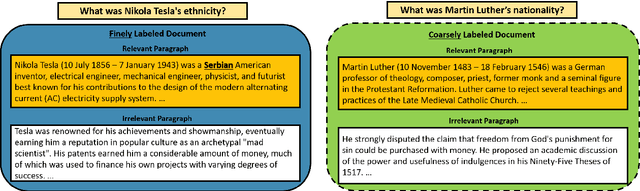
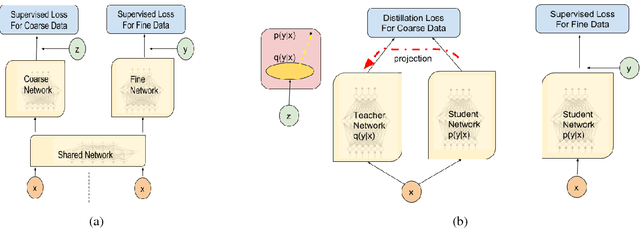
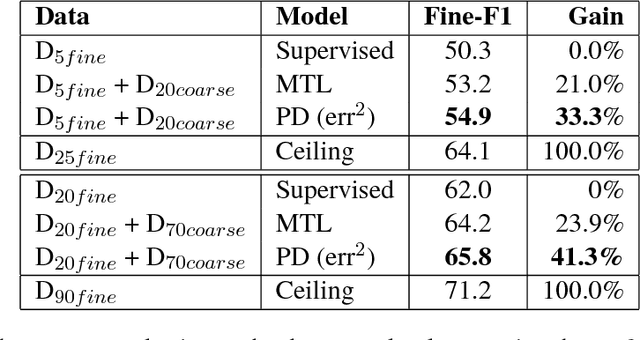
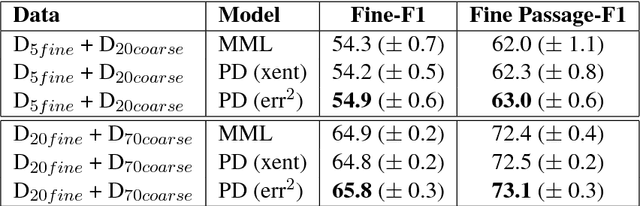
We study approaches to improve fine-grained short answer Question Answering models by integrating coarse-grained data annotated for paragraph-level relevance and show that coarsely annotated data can bring significant performance gains. Experiments demonstrate that the standard multi-task learning approach of sharing representations is not the most effective way to leverage coarse-grained annotations. Instead, we can explicitly model the latent fine-grained short answer variables and optimize the marginal log-likelihood directly or use a newly proposed \emph{posterior distillation} learning objective. Since these latent-variable methods have explicit access to the relationship between the fine and coarse tasks, they result in significantly larger improvements from coarse supervision.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Oct 11, 2018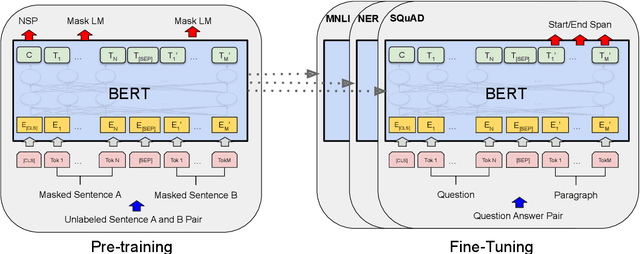
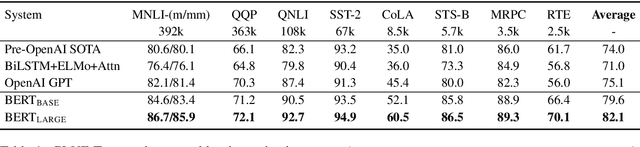
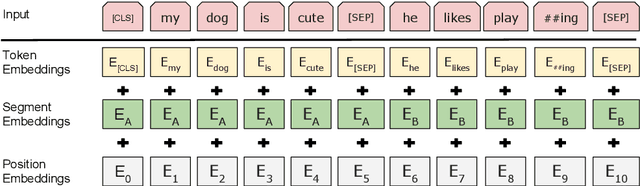
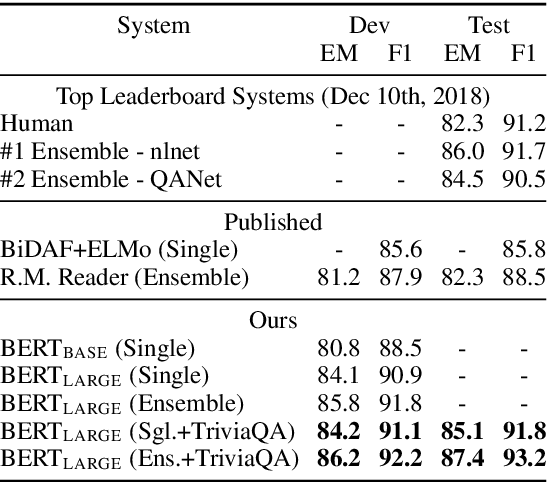
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%.
Policy Shaping and Generalized Update Equations for Semantic Parsing from Denotations
Sep 05, 2018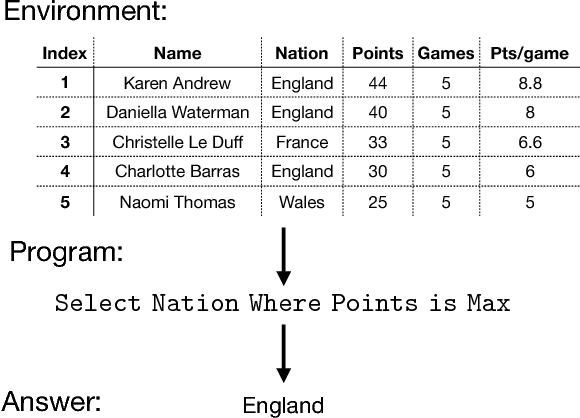


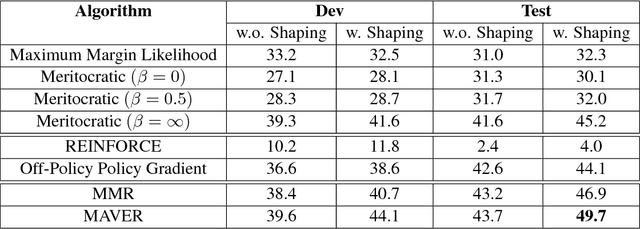
Semantic parsing from denotations faces two key challenges in model training: (1) given only the denotations (e.g., answers), search for good candidate semantic parses, and (2) choose the best model update algorithm. We propose effective and general solutions to each of them. Using policy shaping, we bias the search procedure towards semantic parses that are more compatible to the text, which provide better supervision signals for training. In addition, we propose an update equation that generalizes three different families of learning algorithms, which enables fast model exploration. When experimented on a recently proposed sequential question answering dataset, our framework leads to a new state-of-the-art model that outperforms previous work by 5.0% absolute on exact match accuracy.
Link Prediction using Embedded Knowledge Graphs
Apr 22, 2018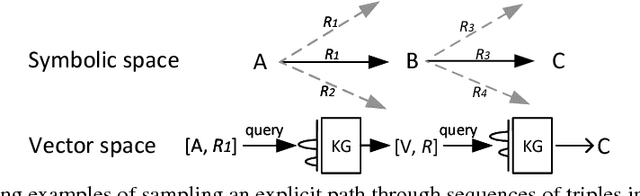
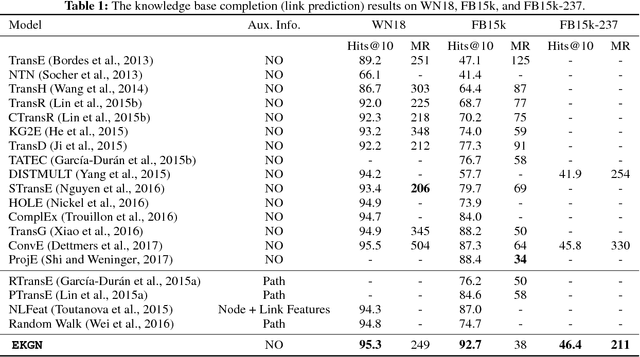
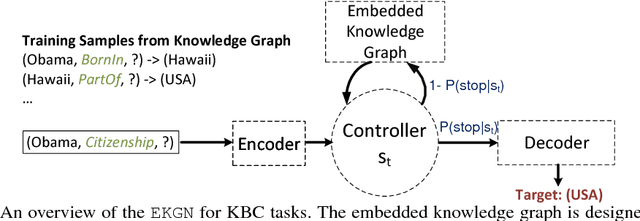

Since large knowledge bases are typically incomplete, missing facts need to be inferred from observed facts in a task called knowledge base completion. The most successful approaches to this task have typically explored explicit paths through sequences of triples. These approaches have usually resorted to human-designed sampling procedures, since large knowledge graphs produce prohibitively large numbers of possible paths, most of which are uninformative. As an alternative approach, we propose performing a single, short sequence of interactive lookup operations on an embedded knowledge graph which has been trained through end-to-end backpropagation to be an optimized and compressed version of the initial knowledge base. Our proposed model, called Embedded Knowledge Graph Network (EKGN), achieves new state-of-the-art results on popular knowledge base completion benchmarks.
A Knowledge-Grounded Neural Conversation Model
Feb 07, 2017
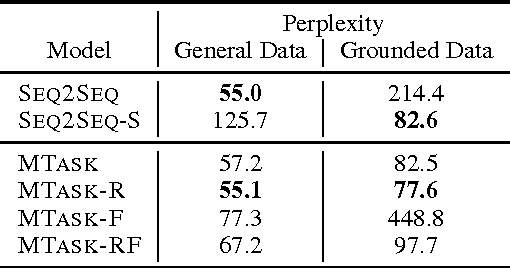
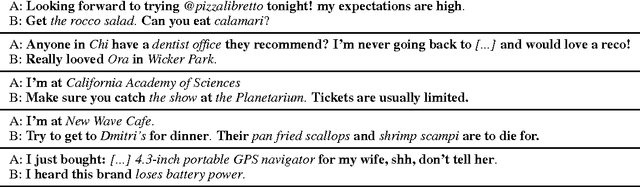
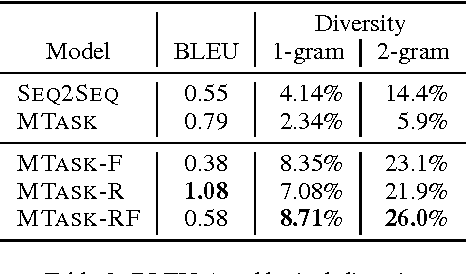
Neural network models are capable of generating extremely natural sounding conversational interactions. Nevertheless, these models have yet to demonstrate that they can incorporate content in the form of factual information or entity-grounded opinion that would enable them to serve in more task-oriented conversational applications. This paper presents a novel, fully data-driven, and knowledge-grounded neural conversation model aimed at producing more contentful responses without slot filling. We generalize the widely-used Seq2Seq approach by conditioning responses on both conversation history and external "facts", allowing the model to be versatile and applicable in an open-domain setting. Our approach yields significant improvements over a competitive Seq2Seq baseline. Human judges found that our outputs are significantly more informative.
Annotating Derivations: A New Evaluation Strategy and Dataset for Algebra Word Problems
Jan 10, 2017
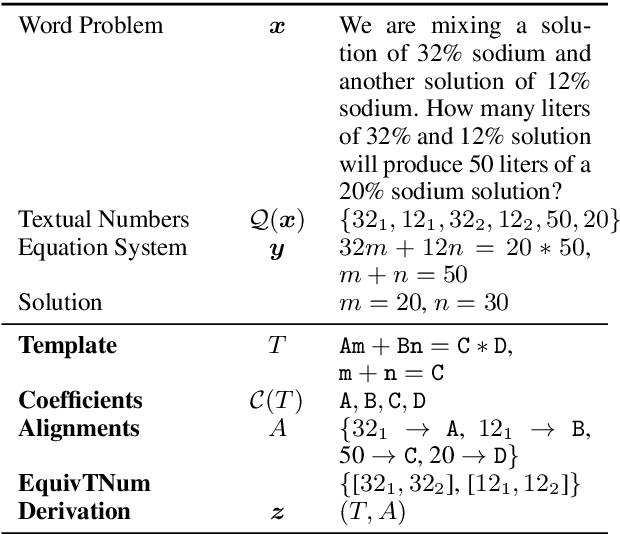
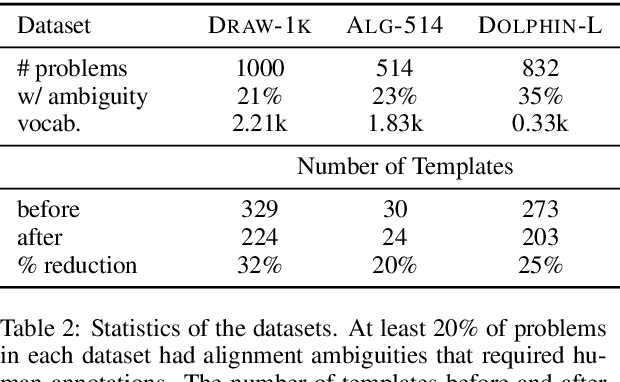
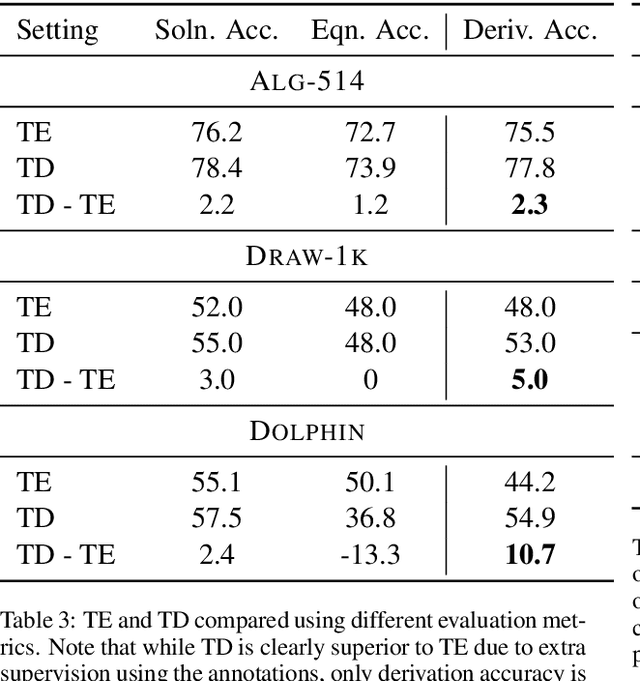
We propose a new evaluation for automatic solvers for algebra word problems, which can identify mistakes that existing evaluations overlook. Our proposal is to evaluate such solvers using derivations, which reflect how an equation system was constructed from the word problem. To accomplish this, we develop an algorithm for checking the equivalence between two derivations, and show how derivation an- notations can be semi-automatically added to existing datasets. To make our experiments more comprehensive, we include the derivation annotation for DRAW-1K, a new dataset containing 1000 general algebra word problems. In our experiments, we found that the annotated derivations enable a more accurate evaluation of automatic solvers than previously used metrics. We release derivation annotations for over 2300 algebra word problems for future evaluations.
Answering Complicated Question Intents Expressed in Decomposed Question Sequences
Nov 04, 2016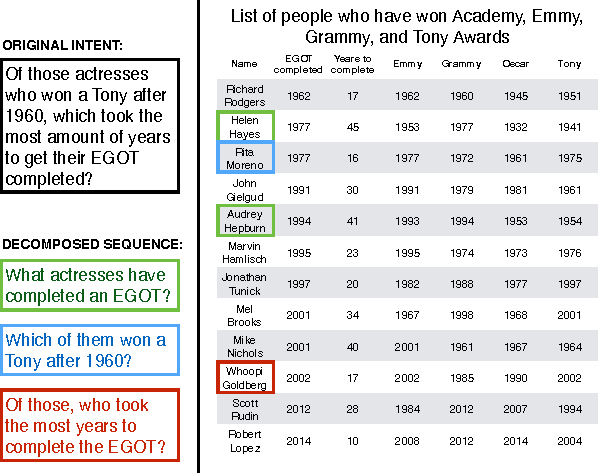
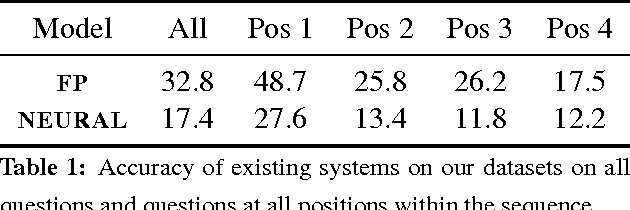
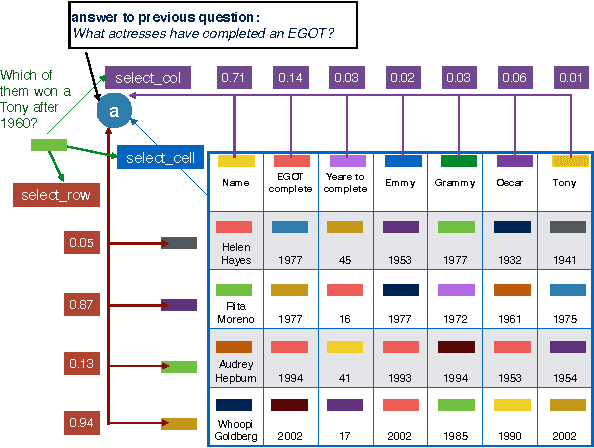

Recent work in semantic parsing for question answering has focused on long and complicated questions, many of which would seem unnatural if asked in a normal conversation between two humans. In an effort to explore a conversational QA setting, we present a more realistic task: answering sequences of simple but inter-related questions. We collect a dataset of 6,066 question sequences that inquire about semi-structured tables from Wikipedia, with 17,553 question-answer pairs in total. Existing QA systems face two major problems when evaluated on our dataset: (1) handling questions that contain coreferences to previous questions or answers, and (2) matching words or phrases in a question to corresponding entries in the associated table. We conclude by proposing strategies to handle both of these issues.