 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALLSTEPS: Curriculum-driven Learning of Stepping Stone Skills
May 09, 2020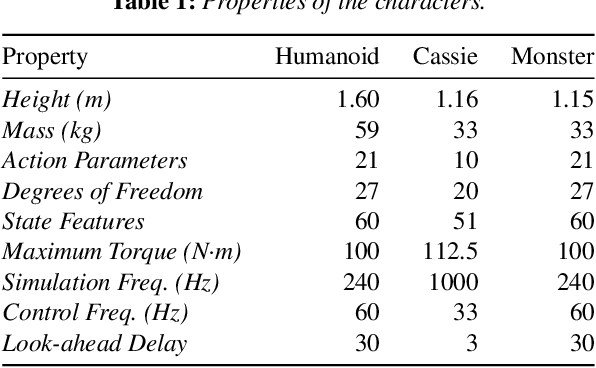
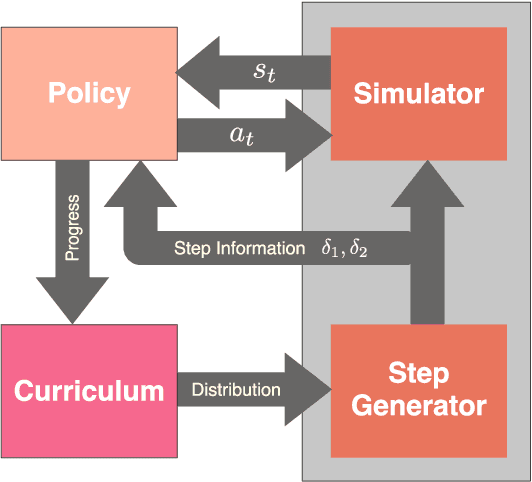

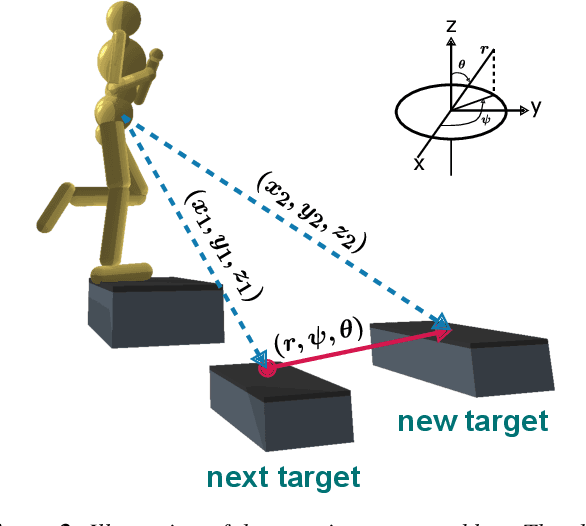
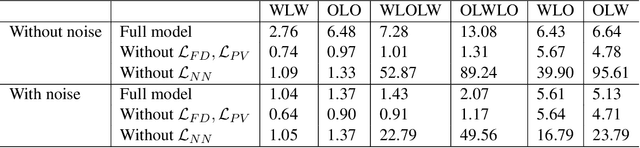
Humans are highly adept at walking in environments with foot placement constraints, including stepping-stone scenarios where the footstep locations are fully constrained. Finding good solutions to stepping-stone locomotion is a longstanding and fundamental challenge for animation and robotics. We present fully learned solutions to this difficult problem using reinforcement learning. We demonstrate the importance of a curriculum for efficient learning and evaluate four possible curriculum choices compared to a non-curriculum baseline. Results are presented for a simulated human character, a realistic bipedal robot simulation and a monster character, in each case producing robust, plausible motions for challenging stepping stone sequences and terrains.
Learning to Correspond Dynamical Systems
Dec 23, 2019
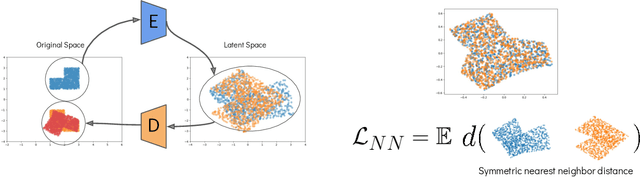
Many dynamical systems exhibit similar structure, as often captured by hand-designed simplified models that can be used for analysis and control. We develop a method for learning to correspond pairs of dynamical systems via a learned latent dynamical system. Given trajectory data from two dynamical systems, we learn a shared latent state space and a shared latent dynamics model, along with an encoder-decoder pair for each of the original systems. With the learned correspondences in place, we can use a simulation of one system to produce an imagined motion of its counterpart. We can also simulate in the learned latent dynamics and synthesize the motions of both corresponding systems, as a form of bisimulation. We demonstrate the approach using pairs of controlled bipedal walkers, as well as by pairing a walker with a controlled pendulum.
Iterative Reinforcement Learning Based Design of Dynamic Locomotion Skills for Cassie
Mar 22, 2019
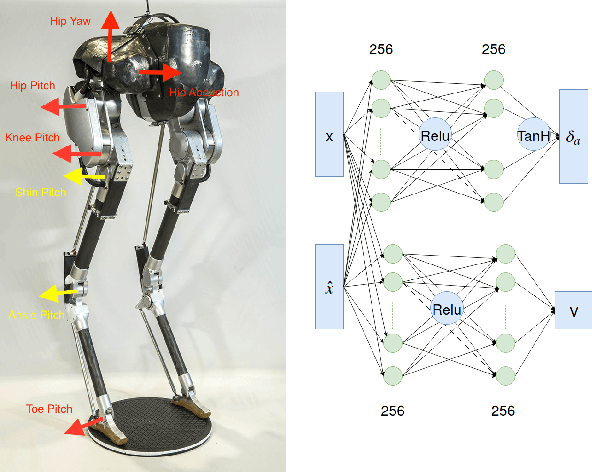
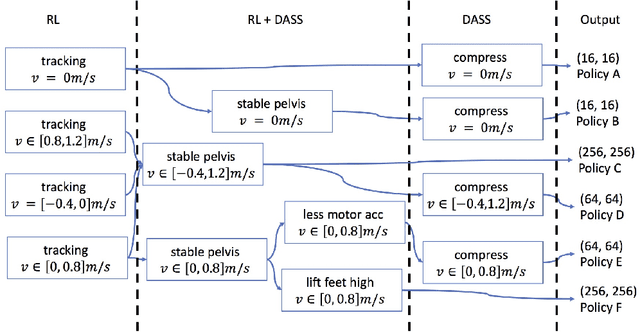
Deep reinforcement learning (DRL) is a promising approach for developing legged locomotion skills. However, the iterative design process that is inevitable in practice is poorly supported by the default methodology. It is difficult to predict the outcomes of changes made to the reward functions, policy architectures, and the set of tasks being trained on. In this paper, we propose a practical method that allows the reward function to be fully redefined on each successive design iteration while limiting the deviation from the previous iteration. We characterize policies via sets of Deterministic Action Stochastic State (DASS) tuples, which represent the deterministic policy state-action pairs as sampled from the states visited by the trained stochastic policy. New policies are trained using a policy gradient algorithm which then mixes RL-based policy gradients with gradient updates defined by the DASS tuples. The tuples also allow for robust policy distillation to new network architectures. We demonstrate the effectiveness of this iterative-design approach on the bipedal robot Cassie, achieving stable walking with different gait styles at various speeds. We demonstrate the successful transfer of policies learned in simulation to the physical robot without any dynamics randomization, and that variable-speed walking policies for the physical robot can be represented by a small dataset of 5-10k tuples.
Feedback Control For Cassie With Deep Reinforcement Learning
Jul 27, 2018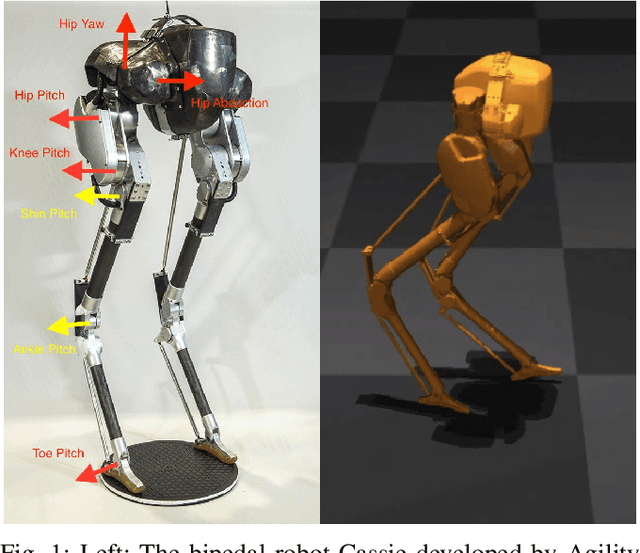
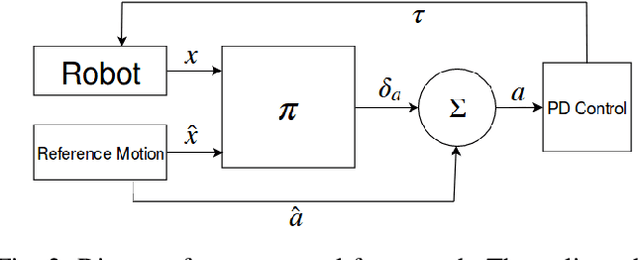
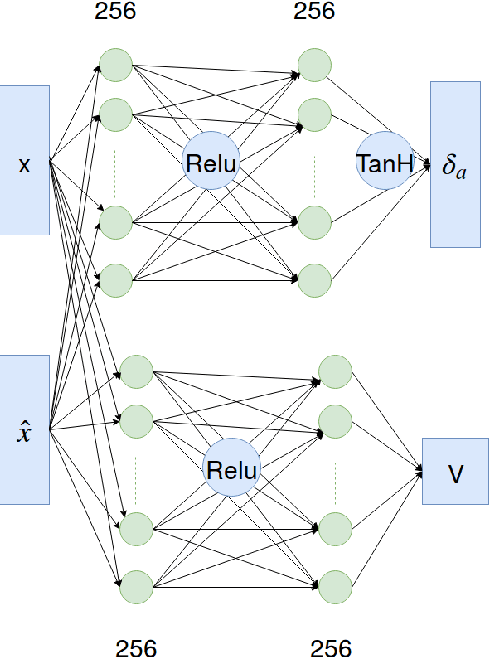
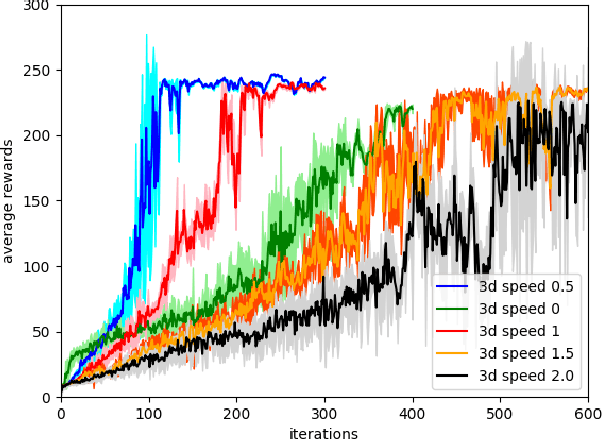
Bipedal locomotion skills are challenging to develop. Control strategies often use local linearization of the dynamics in conjunction with reduced-order abstractions to yield tractable solutions. In these model-based control strategies, the controller is often not fully aware of many details, including torque limits, joint limits, and other non-linearities that are necessarily excluded from the control computations for simplicity. Deep reinforcement learning (DRL) offers a promising model-free approach for controlling bipedal locomotion which can more fully exploit the dynamics. However, current results in the machine learning literature are often based on ad-hoc simulation models that are not based on corresponding hardware. Thus it remains unclear how well DRL will succeed on realizable bipedal robots. In this paper, we demonstrate the effectiveness of DRL using a realistic model of Cassie, a bipedal robot. By formulating a feedback control problem as finding the optimal policy for a Markov Decision Process, we are able to learn robust walking controllers that imitate a reference motion with DRL. Controllers for different walking speeds are learned by imitating simple time-scaled versions of the original reference motion. Controller robustness is demonstrated through several challenging tests, including sensory delay, walking blindly on irregular terrain and unexpected pushes at the pelvis. We also show we can interpolate between individual policies and that robustness can be improved with an interpolated policy.
DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
Jul 27, 2018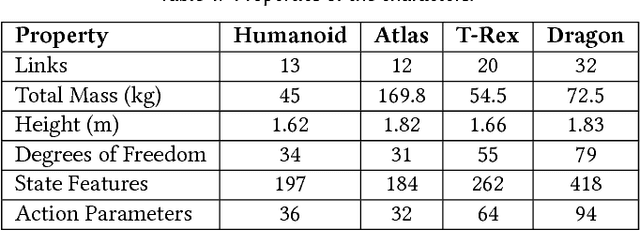
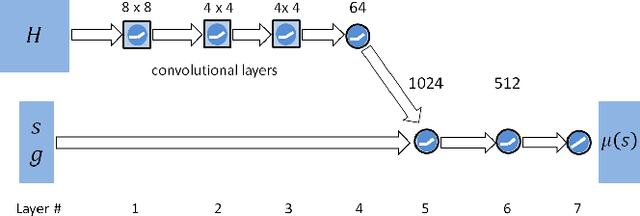
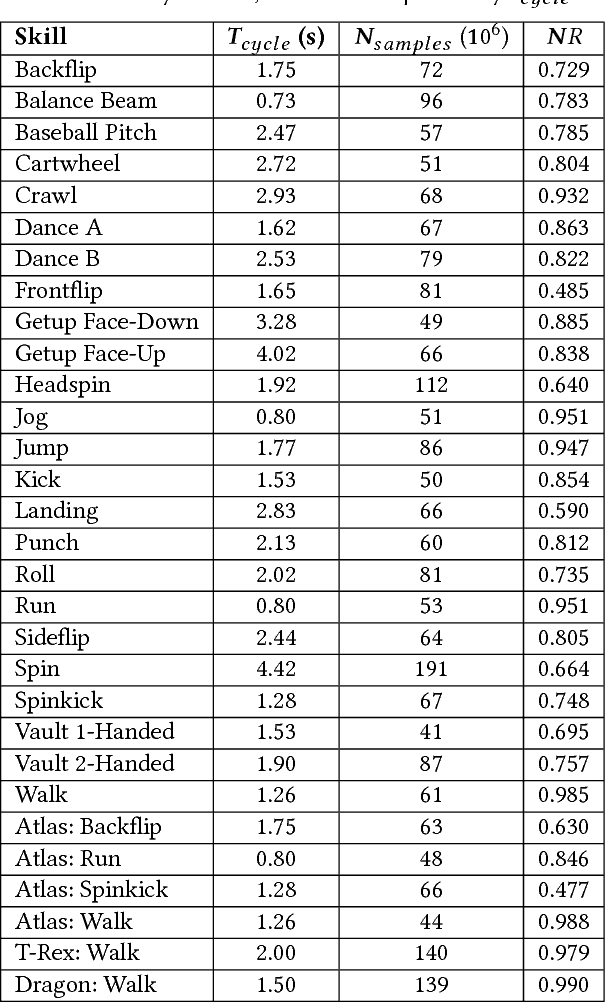
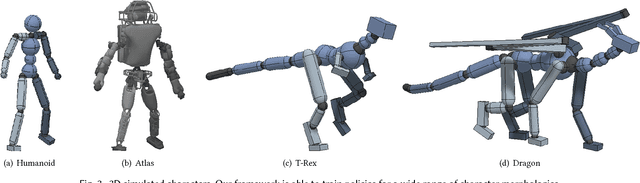
A longstanding goal in character animation is to combine data-driven specification of behavior with a system that can execute a similar behavior in a physical simulation, thus enabling realistic responses to perturbations and environmental variation. We show that well-known reinforcement learning (RL) methods can be adapted to learn robust control policies capable of imitating a broad range of example motion clips, while also learning complex recoveries, adapting to changes in morphology, and accomplishing user-specified goals. Our method handles keyframed motions, highly-dynamic actions such as motion-captured flips and spins, and retargeted motions. By combining a motion-imitation objective with a task objective, we can train characters that react intelligently in interactive settings, e.g., by walking in a desired direction or throwing a ball at a user-specified target. This approach thus combines the convenience and motion quality of using motion clips to define the desired style and appearance, with the flexibility and generality afforded by RL methods and physics-based animation. We further explore a number of methods for integrating multiple clips into the learning process to develop multi-skilled agents capable of performing a rich repertoire of diverse skills. We demonstrate results using multiple characters (human, Atlas robot, bipedal dinosaur, dragon) and a large variety of skills, including locomotion, acrobatics, and martial arts.
Terrain RL Simulator
Apr 17, 2018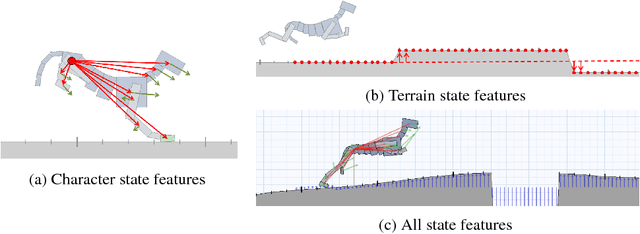
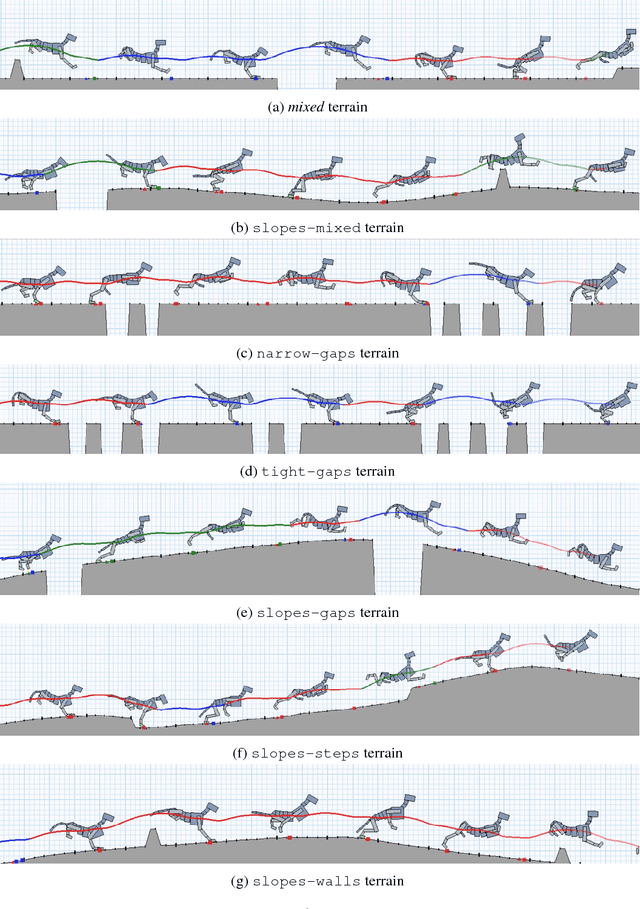
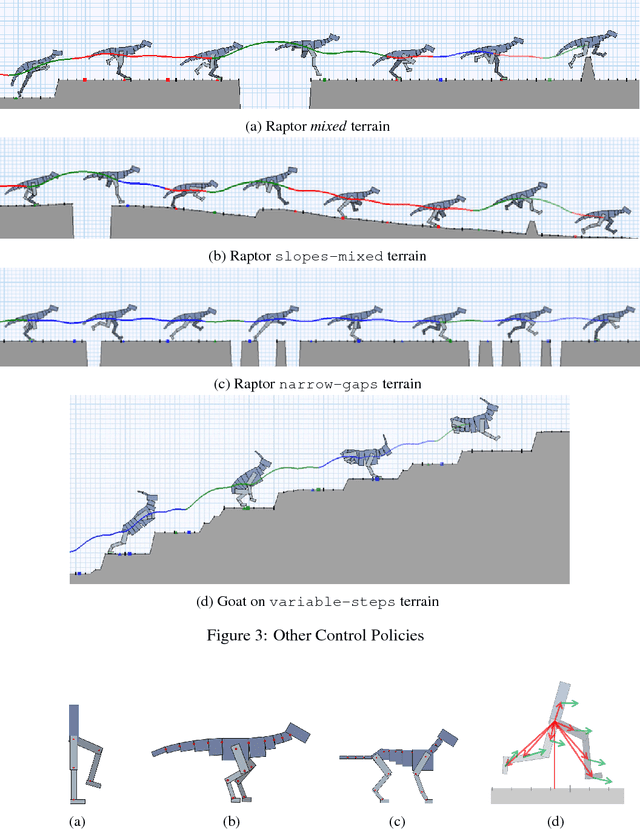
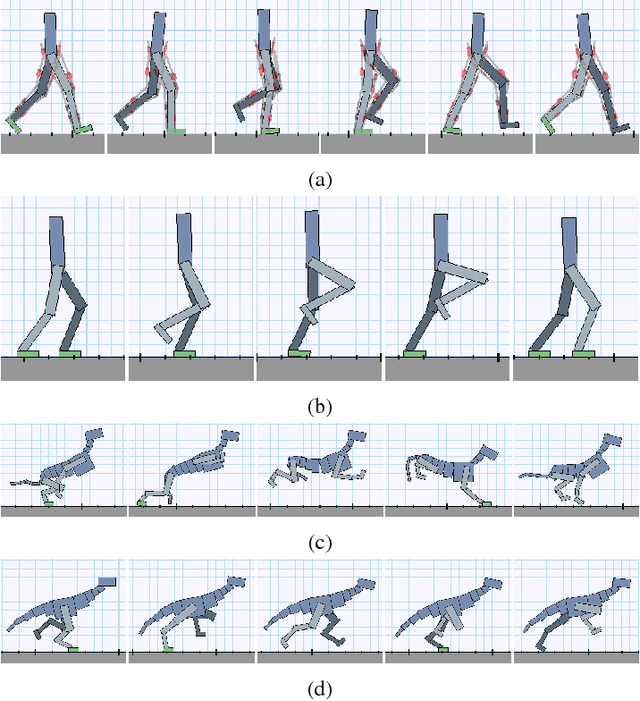
We provide $89$ challenging simulation environments that range in difficulty. The difficulty of solving a task is linked not only to the number of dimensions in the action space but also to the size and shape of the distribution of configurations the agent experiences. Therefore, we are releasing a number of simulation environments that include randomly generated terrain. The library also provides simple mechanisms to create new environments with different agent morphologies and the option to modify the distribution of generated terrain. We believe using these and other more complex simulations will help push the field closer to creating human-level intelligence.
Model-Based Action Exploration for Learning Dynamic Motion Skills
Apr 12, 2018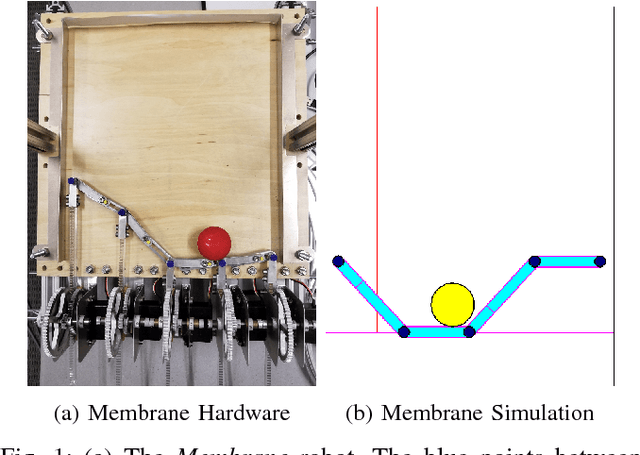
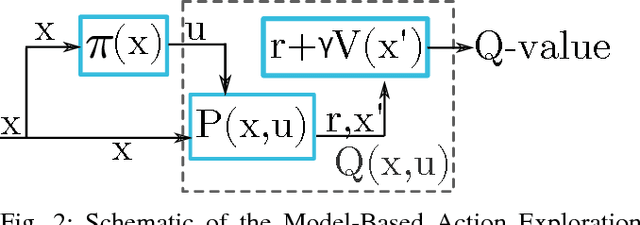
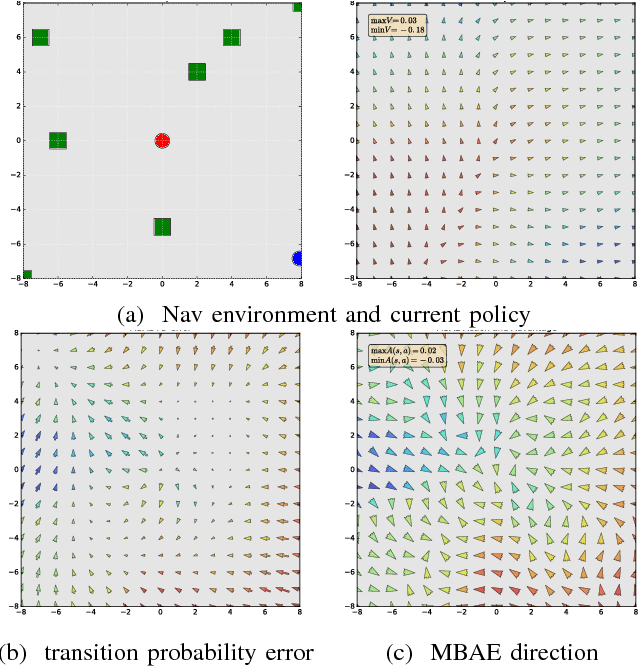
Deep reinforcement learning has achieved great strides in solving challenging motion control tasks. Recently, there has been significant work on methods for exploiting the data gathered during training, but there has been less work on how to best generate the data to learn from. For continuous action domains, the most common method for generating exploratory actions involves sampling from a Gaussian distribution centred around the mean action output by a policy. Although these methods can be quite capable, they do not scale well with the dimensionality of the action space, and can be dangerous to apply on hardware. We consider learning a forward dynamics model to predict the result, ($x_{t+1}$), of taking a particular action, ($u$), given a specific observation of the state, ($x_{t}$). With this model we perform internal look-ahead predictions of outcomes and seek actions we believe have a reasonable chance of success. This method alters the exploratory action space, thereby increasing learning speed and enables higher quality solutions to difficult problems, such as robotic locomotion and juggling.
Learning Locomotion Skills Using DeepRL: Does the Choice of Action Space Matter?
Nov 03, 2016
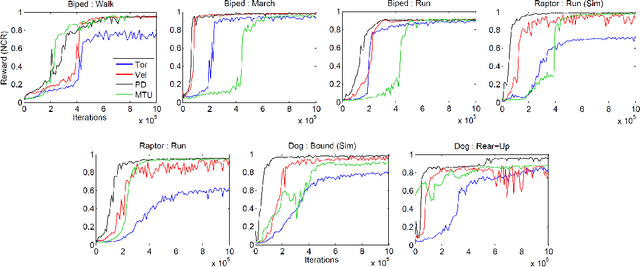

The use of deep reinforcement learning allows for high-dimensional state descriptors, but little is known about how the choice of action representation impacts the learning difficulty and the resulting performance. We compare the impact of four different action parameterizations (torques, muscle-activations, target joint angles, and target joint-angle velocities) in terms of learning time, policy robustness, motion quality, and policy query rates. Our results are evaluated on a gait-cycle imitation task for multiple planar articulated figures and multiple gaits. We demonstrate that the local feedback provided by higher-level action parameterizations can significantly impact the learning, robustness, and quality of the resulting policies.