 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Vision Transformer Methods for Deep Reinforcement Learning from Pixels
Apr 11, 2022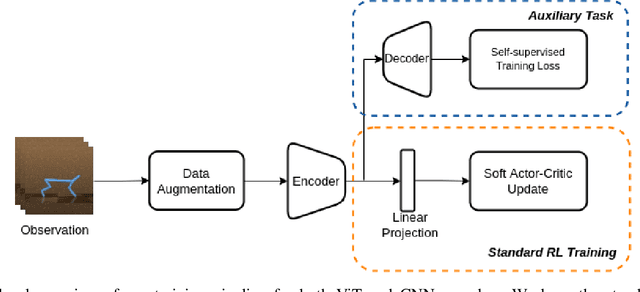
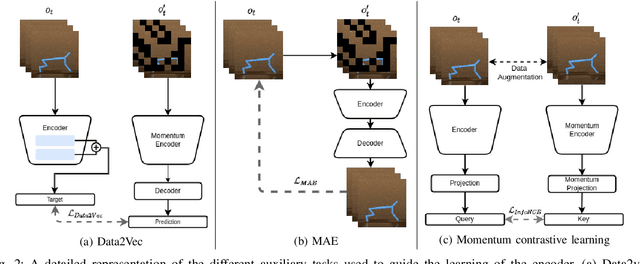
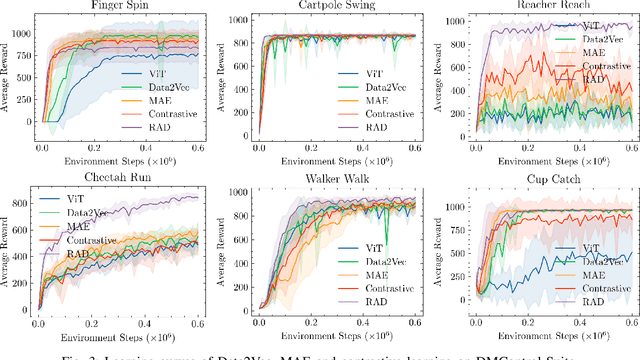
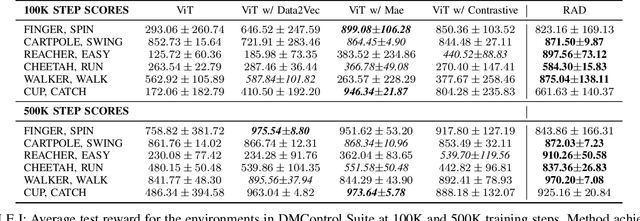
Vision Transformers (ViT) have recently demonstrated the significant potential of transformer architectures for computer vision. To what extent can image-based deep reinforcement learning also benefit from ViT architectures, as compared to standard convolutional neural network (CNN) architectures? To answer this question, we evaluate ViT training methods for image-based reinforcement learning (RL) control tasks and compare these results to a leading convolutional-network architecture method, RAD. For training the ViT encoder, we consider several recently-proposed self-supervised losses that are treated as auxiliary tasks, as well as a baseline with no additional loss terms. We find that the CNN architectures trained using RAD still generally provide superior performance. For the ViT methods, all three types of auxiliary tasks that we consider provide a benefit over plain ViT training. Furthermore, ViT masking-based tasks are found to significantly outperform ViT contrastive-learning.
Style-ERD: Responsive and Coherent Online Motion Style Transfer
Mar 29, 2022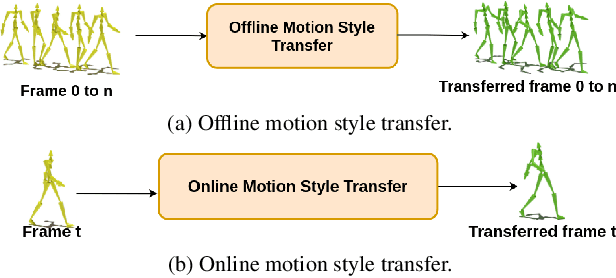

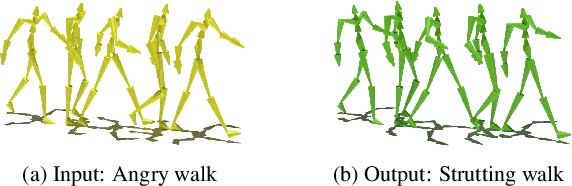
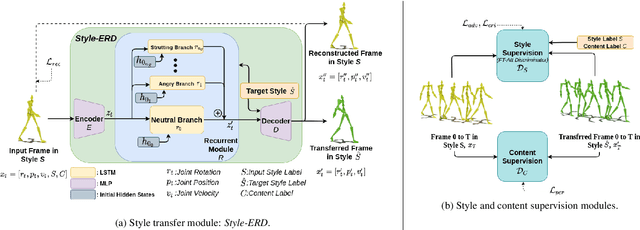
Motion style transfer is a common method for enriching character animation. Motion style transfer algorithms are often designed for offline settings where motions are processed in segments. However, for online animation applications, such as realtime avatar animation from motion capture, motions need to be processed as a stream with minimal latency. In this work, we realize a flexible, high-quality motion style transfer method for this setting. We propose a novel style transfer model, Style-ERD, to stylize motions in an online manner with an Encoder-Recurrent-Decoder structure, along with a novel discriminator that combines feature attention and temporal attention. Our method stylizes motions into multiple target styles with a unified model. Although our method targets online settings, it outperforms previous offline methods in motion realism and style expressiveness and provides significant gains in runtime efficiency
A Survey on Reinforcement Learning Methods in Character Animation
Mar 07, 2022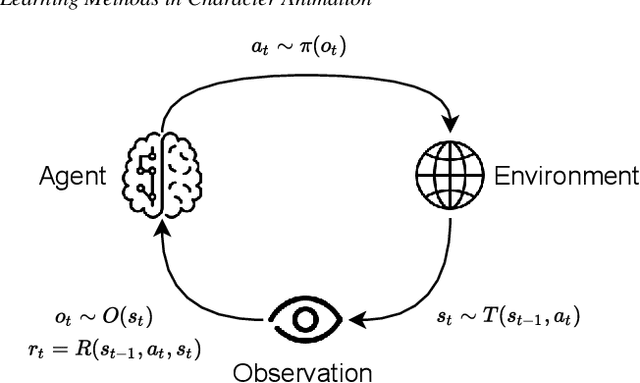
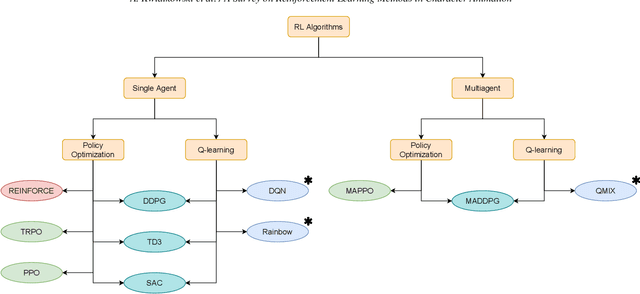
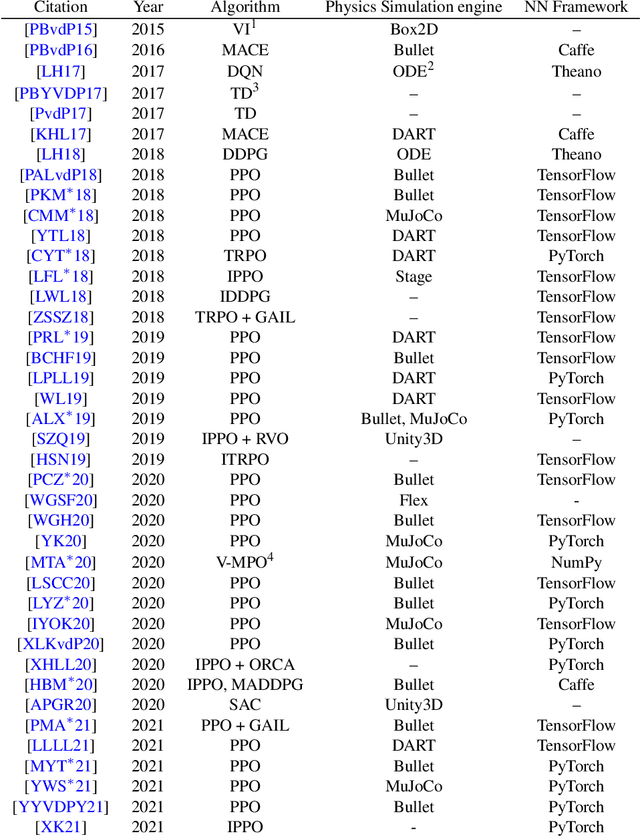
Reinforcement Learning is an area of Machine Learning focused on how agents can be trained to make sequential decisions, and achieve a particular goal within an arbitrary environment. While learning, they repeatedly take actions based on their observation of the environment, and receive appropriate rewards which define the objective. This experience is then used to progressively improve the policy controlling the agent's behavior, typically represented by a neural network. This trained module can then be reused for similar problems, which makes this approach promising for the animation of autonomous, yet reactive characters in simulators, video games or virtual reality environments. This paper surveys the modern Deep Reinforcement Learning methods and discusses their possible applications in Character Animation, from skeletal control of a single, physically-based character to navigation controllers for individual agents and virtual crowds. It also describes the practical side of training DRL systems, comparing the different frameworks available to build such agents.
Exploration with Multi-Sample Target Values for Distributional Reinforcement Learning
Feb 06, 2022
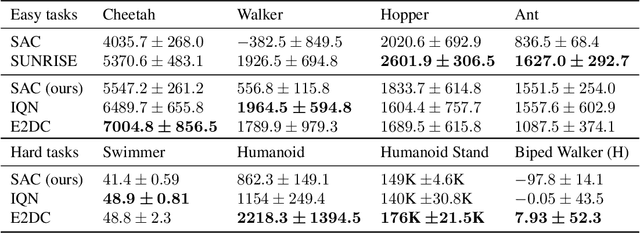
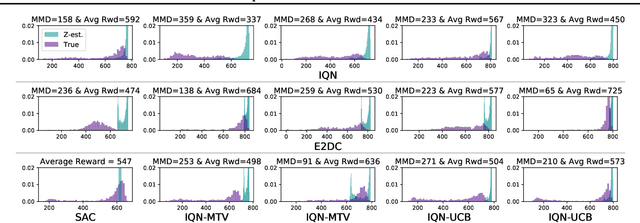
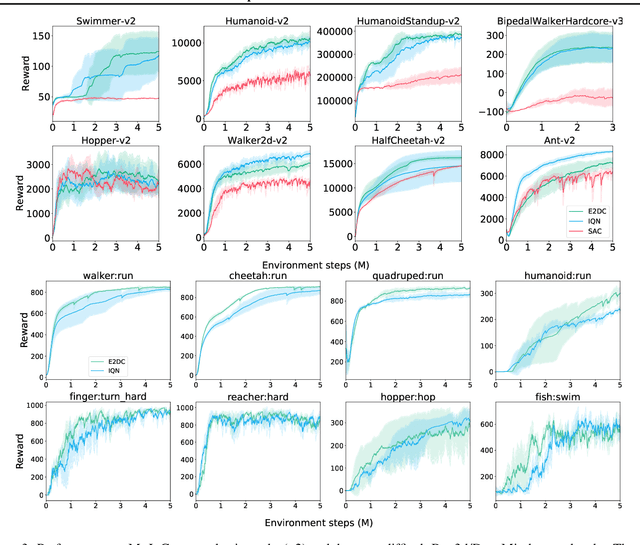
Distributional reinforcement learning (RL) aims to learn a value-network that predicts the full distribution of the returns for a given state, often modeled via a quantile-based critic. This approach has been successfully integrated into common RL methods for continuous control, giving rise to algorithms such as Distributional Soft Actor-Critic (DSAC). In this paper, we introduce multi-sample target values (MTV) for distributional RL, as a principled replacement for single-sample target value estimation, as commonly employed in current practice. The improved distributional estimates further lend themselves to UCB-based exploration. These two ideas are combined to yield our distributional RL algorithm, E2DC (Extra Exploration with Distributional Critics). We evaluate our approach on a range of continuous control tasks and demonstrate state-of-the-art model-free performance on difficult tasks such as Humanoid control. We provide further insight into the method via visualization and analysis of the learned distributions and their evolution during training.
Discovering Diverse Athletic Jumping Strategies
May 02, 2021
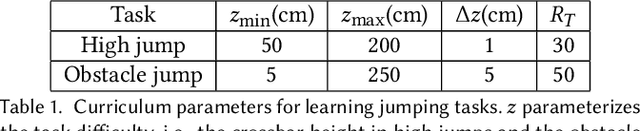
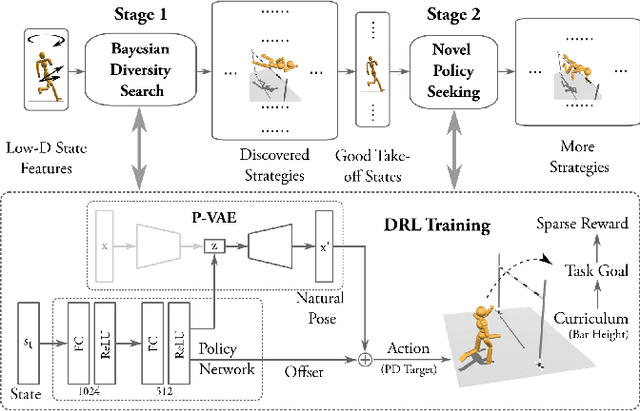
We present a framework that enables the discovery of diverse and natural-looking motion strategies for athletic skills such as the high jump. The strategies are realized as control policies for physics-based characters. Given a task objective and an initial character configuration, the combination of physics simulation and deep reinforcement learning (DRL) provides a suitable starting point for automatic control policy training. To facilitate the learning of realistic human motions, we propose a Pose Variational Autoencoder (P-VAE) to constrain the actions to a subspace of natural poses. In contrast to motion imitation methods, a rich variety of novel strategies can naturally emerge by exploring initial character states through a sample-efficient Bayesian diversity search (BDS) algorithm. A second stage of optimization that encourages novel policies can further enrich the unique strategies discovered. Our method allows for the discovery of diverse and novel strategies for athletic jumping motions such as high jumps and obstacle jumps with no motion examples and less reward engineering than prior work.
* 17 pages; SIGGRAPH 2021
GLiDE: Generalizable Quadrupedal Locomotion in Diverse Environments with a Centroidal Model
Apr 22, 2021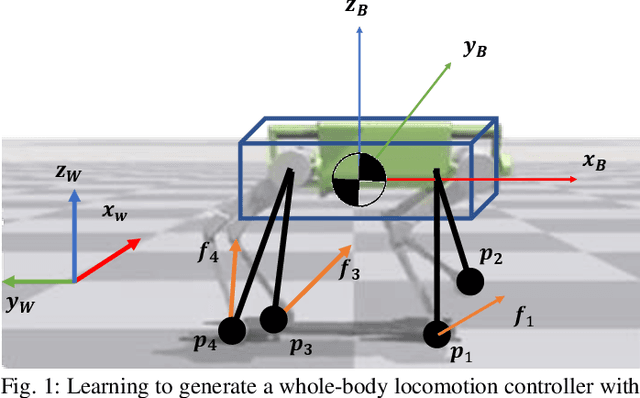
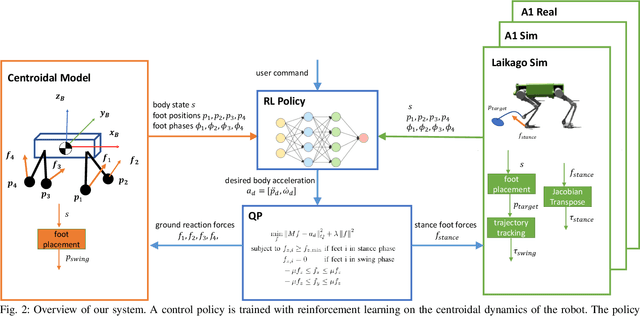


Model-free reinforcement learning (RL) for legged locomotion commonly relies on a physics simulator that can accurately predict the behaviors of every degree of freedom of the robot. In contrast, approximate reduced-order models are often sufficient for many model-based control strategies. In this work we explore how RL can be effectively used with a centroidal model to generate robust control policies for quadrupedal locomotion. Advantages over RL with a full-order model include a simple reward structure, reduced computational costs, and robust sim-to-real transfer. We further show the potential of the method by demonstrating stepping-stone locomotion, two-legged in-place balance, balance beam locomotion, and sim-to-real transfer without further adaptations. Additional Results: https://www.pair.toronto.edu/glide-quadruped/.
Character Controllers Using Motion VAEs
Mar 26, 2021
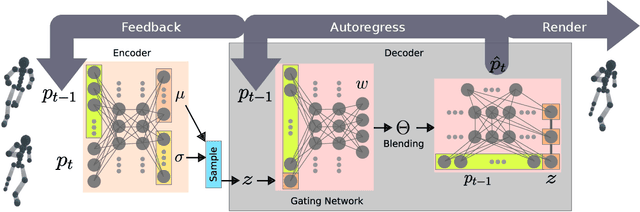
A fundamental problem in computer animation is that of realizing purposeful and realistic human movement given a sufficiently-rich set of motion capture clips. We learn data-driven generative models of human movement using autoregressive conditional variational autoencoders, or Motion VAEs. The latent variables of the learned autoencoder define the action space for the movement and thereby govern its evolution over time. Planning or control algorithms can then use this action space to generate desired motions. In particular, we use deep reinforcement learning to learn controllers that achieve goal-directed movements. We demonstrate the effectiveness of the approach on multiple tasks. We further evaluate system-design choices and describe the current limitations of Motion VAEs.
Dynamics Randomization Revisited:A Case Study for Quadrupedal Locomotion
Nov 04, 2020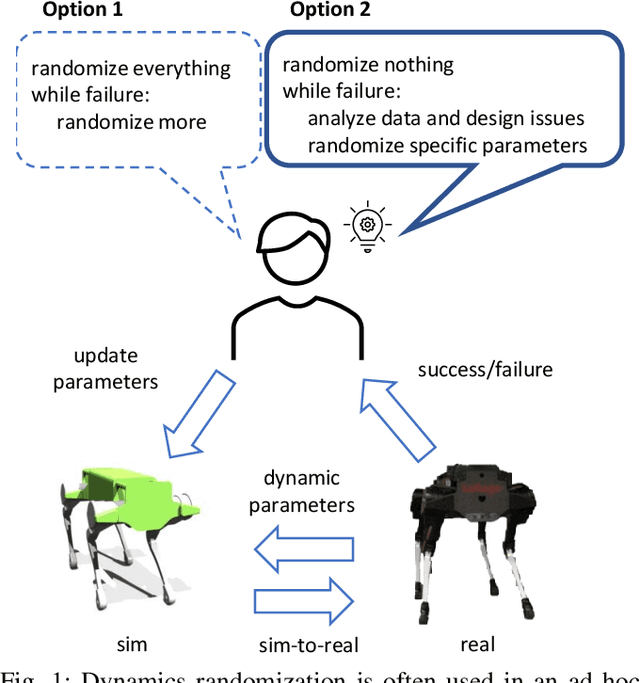
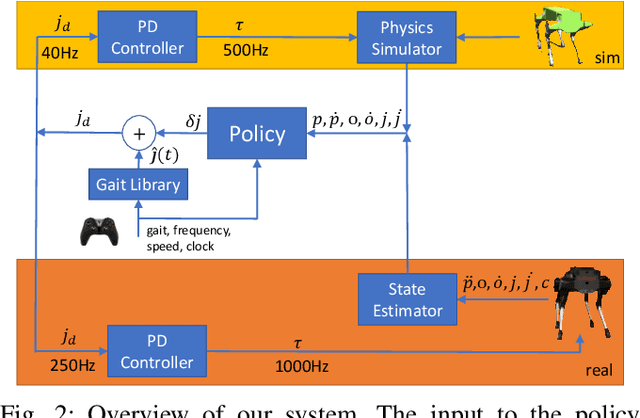

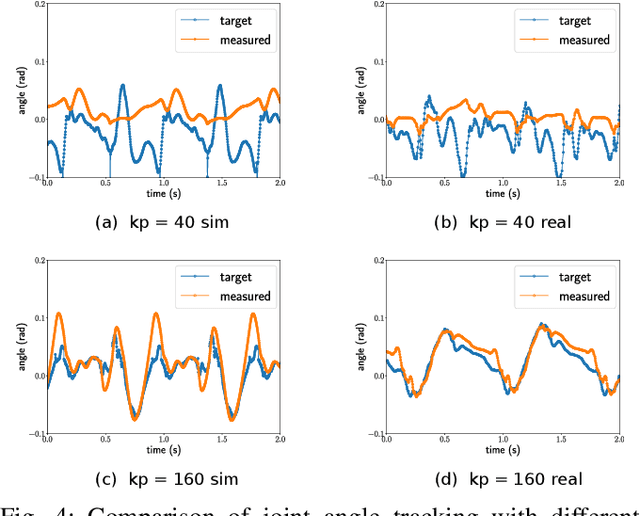
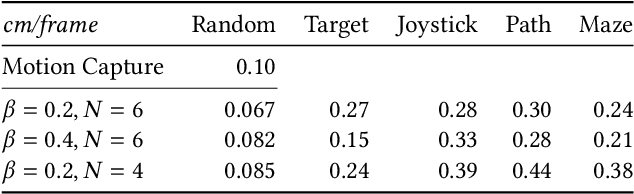
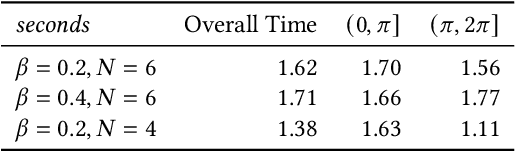
Understanding the gap between simulation andreality is critical for reinforcement learning with legged robots,which are largely trained in simulation. However, recent workhas resulted in sometimes conflicting conclusions with regardto which factors are important for success, including therole of dynamics randomization. In this paper, we aim toprovide clarity and understanding on the role of dynamicsrandomization in learning robust locomotion policies for theLaikago quadruped robot. Surprisingly, in contrast to priorwork with the same robot model, we find that direct sim-to-real transfer is possible without dynamics randomizationor on-robot adaptation schemes. We conduct extensive abla-tion studies in a sim-to-sim setting to understand the keyissues underlying successful policy transfer, including otherdesign decisions that can impact policy robustness. We furtherground our conclusions via sim-to-real experiments with variousgaits, speeds, and stepping frequencies. Additional Details: https://www.pair.toronto.edu/understanding-dr/.
Learning to Locomote: Understanding How Environment Design Matters for Deep Reinforcement Learning
Oct 09, 2020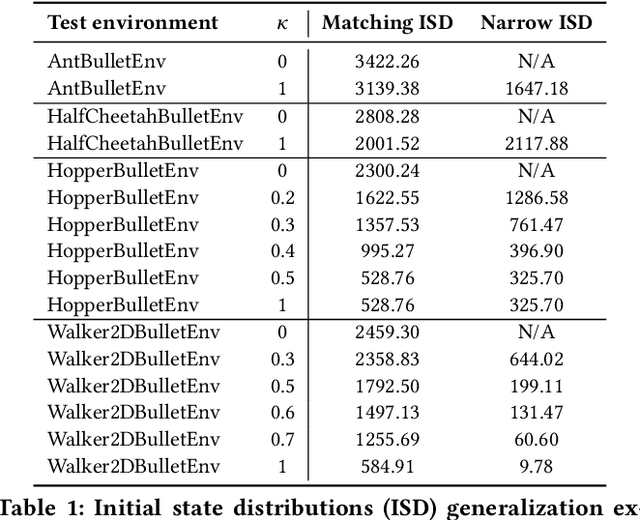
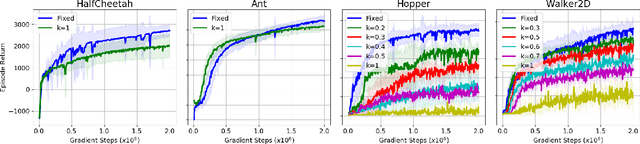
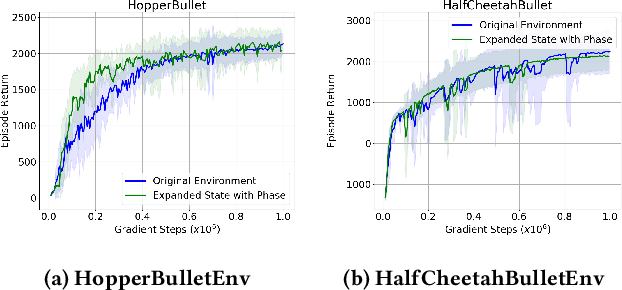

Learning to locomote is one of the most common tasks in physics-based animation and deep reinforcement learning (RL). A learned policy is the product of the problem to be solved, as embodied by the RL environment, and the RL algorithm. While enormous attention has been devoted to RL algorithms, much less is known about the impact of design choices for the RL environment. In this paper, we show that environment design matters in significant ways and document how it can contribute to the brittle nature of many RL results. Specifically, we examine choices related to state representations, initial state distributions, reward structure, control frequency, episode termination procedures, curriculum usage, the action space, and the torque limits. We aim to stimulate discussion around such choices, which in practice strongly impact the success of RL when applied to continuous-action control problems of interest to animation, such as learning to locomote.
Learning Task-Agnostic Action Spaces for Movement Optimization
Sep 22, 2020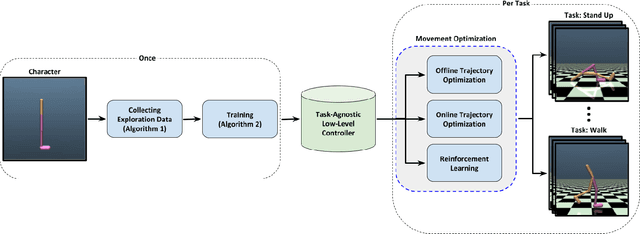
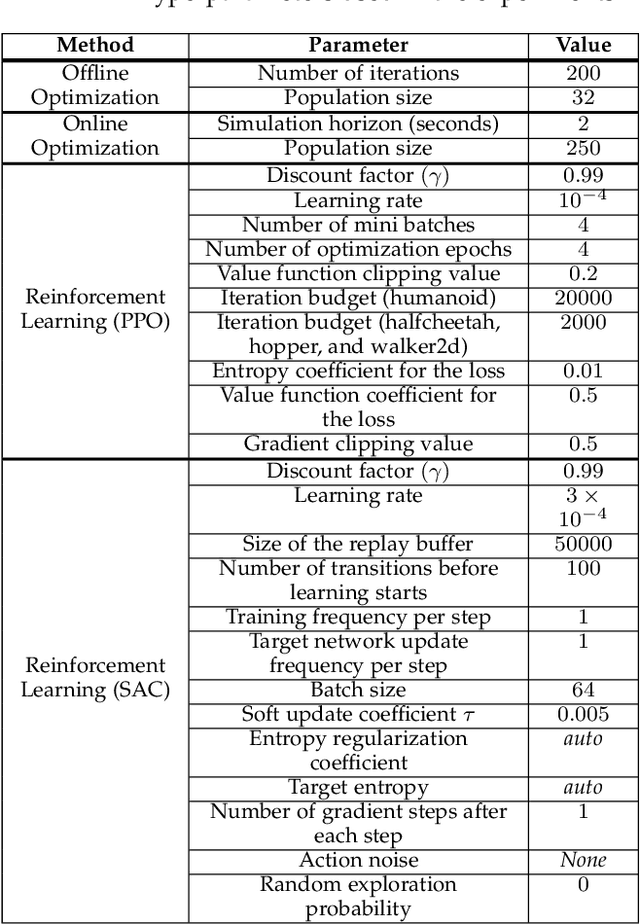
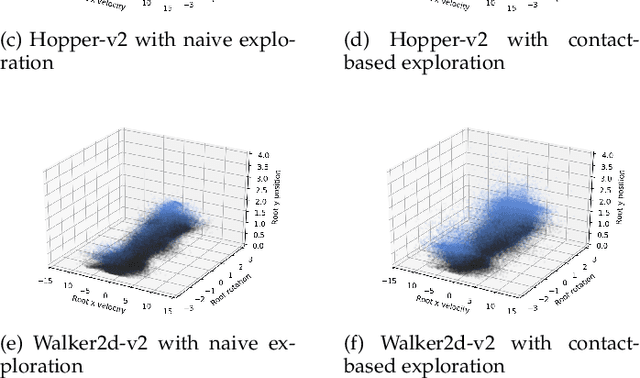

We propose a novel method for exploring the dynamics of physically based animated characters, and learning a task-agnostic action space that makes movement optimization easier. Like several previous papers, we parameterize actions as target states, and learn a short-horizon goal-conditioned low-level control policy that drives the agent's state towards the targets. Our novel contribution is that with our exploration data, we are able to learn the low-level policy in a generic manner and without any reference movement data. Trained once for each agent or simulation environment, the policy improves the efficiency of optimizing both trajectories and high-level policies across multiple tasks and optimization algorithms. We also contribute novel visualizations that show how using target states as actions makes optimized trajectories more robust to disturbances; this manifests as wider optima that are easy to find. Due to its simplicity and generality, our proposed approach should provide a building block that can improve a large variety of movement optimization methods and applications.