 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Semi-supervised Federated Learning
Aug 26, 2020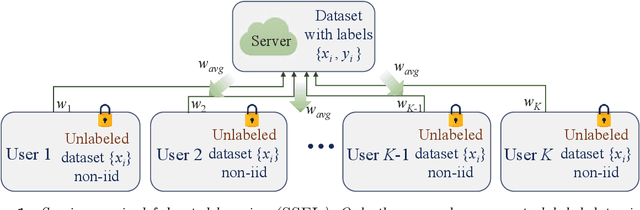

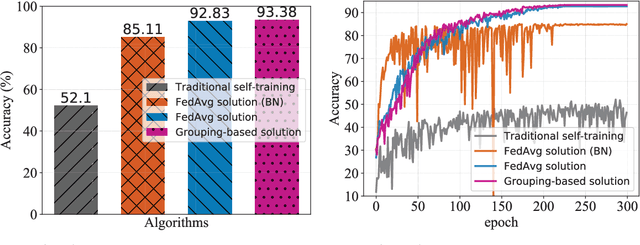
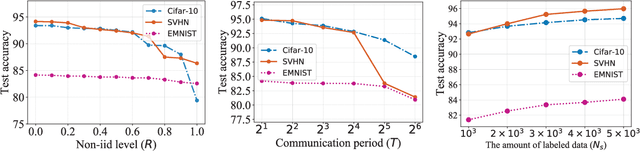
Federated learning promises to use the computational power of edge devices while maintaining user data privacy. Current frameworks, however, typically make the unrealistic assumption that the data stored on user devices come with ground truth labels, while the server has no data. In this work, we consider the more realistic scenario where the users have only unlabeled data and the server has a limited amount of labeled data. In this semi-supervised federated learning (ssfl) setting, the data distribution can be non-iid, in the sense of different distributions of classes at different users. We define a metric, $R$, to measure this non-iidness in class distributions. In this setting, we provide a thorough study on different factors that can affect the final test accuracy, including algorithm design (such as training objective), the non-iidness $R$, the communication period $T$, the number of users $K$, the amount of labeled data in the server $N_s$, and the number of users $C_k\leq K$ that communicate with the server in each communication round. We evaluate our ssfl framework on Cifar-10, SVHN, and EMNIST. Overall, we find that a simple consistency loss-based method, along with group normalization, achieves better generalization performance, even compared to previous supervised federated learning settings. Furthermore, we propose a novel grouping-based model average method to improve convergence efficiency, and we show that this can boost performance by up to 10.79% on EMNIST, compared to the non-grouping based method.
Continuous-in-Depth Neural Networks
Aug 05, 2020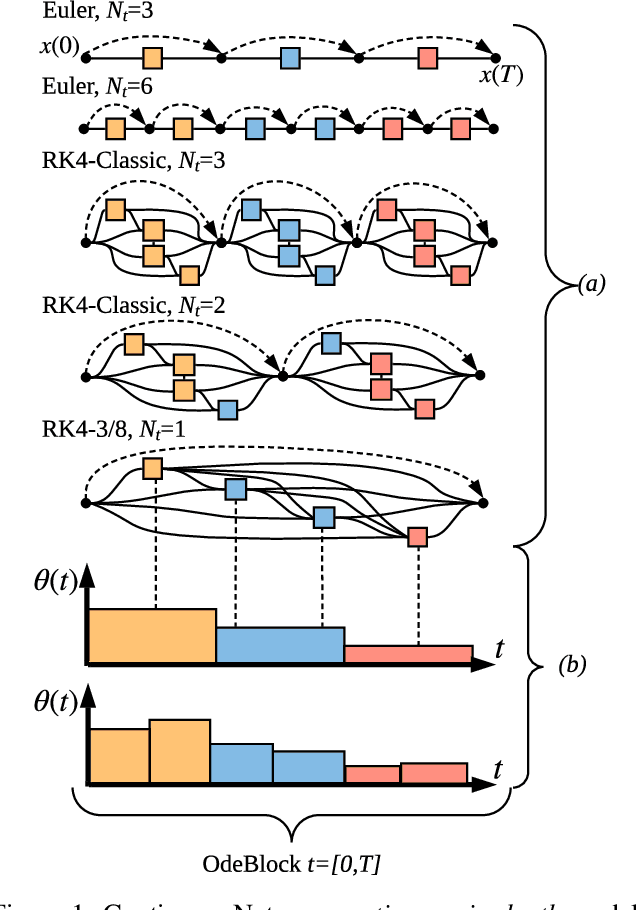
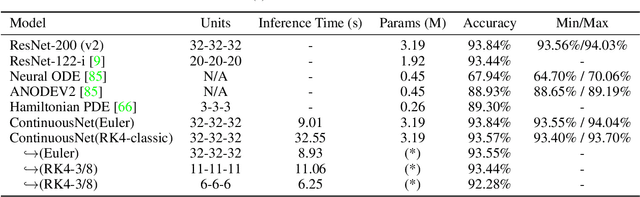

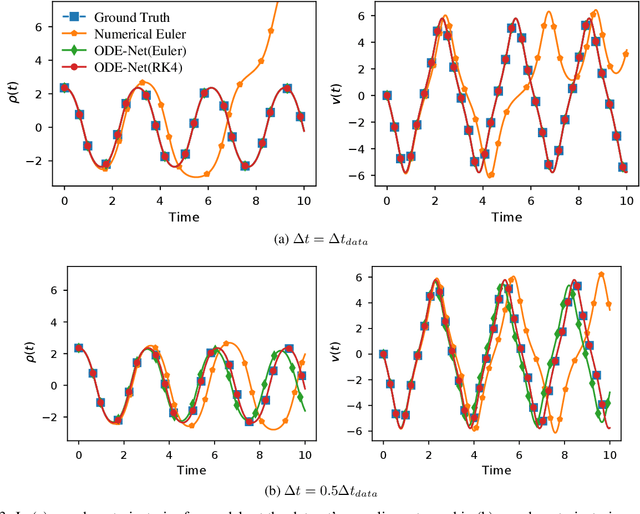
Recent work has attempted to interpret residual networks (ResNets) as one step of a forward Euler discretization of an ordinary differential equation, focusing mainly on syntactic algebraic similarities between the two systems. Discrete dynamical integrators of continuous dynamical systems, however, have a much richer structure. We first show that ResNets fail to be meaningful dynamical integrators in this richer sense. We then demonstrate that neural network models can learn to represent continuous dynamical systems, with this richer structure and properties, by embedding them into higher-order numerical integration schemes, such as the Runge Kutta schemes. Based on these insights, we introduce ContinuousNet as a continuous-in-depth generalization of ResNet architectures. ContinuousNets exhibit an invariance to the particular computational graph manifestation. That is, the continuous-in-depth model can be evaluated with different discrete time step sizes, which changes the number of layers, and different numerical integration schemes, which changes the graph connectivity. We show that this can be used to develop an incremental-in-depth training scheme that improves model quality, while significantly decreasing training time. We also show that, once trained, the number of units in the computational graph can even be decreased, for faster inference with little-to-no accuracy drop.
Noise-response Analysis for Rapid Detection of Backdoors in Deep Neural Networks
Jul 31, 2020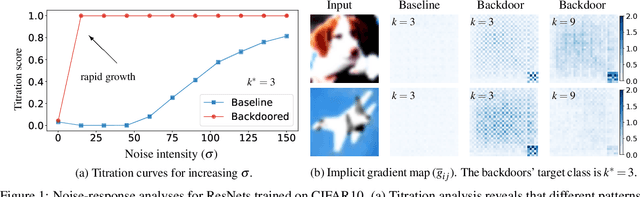
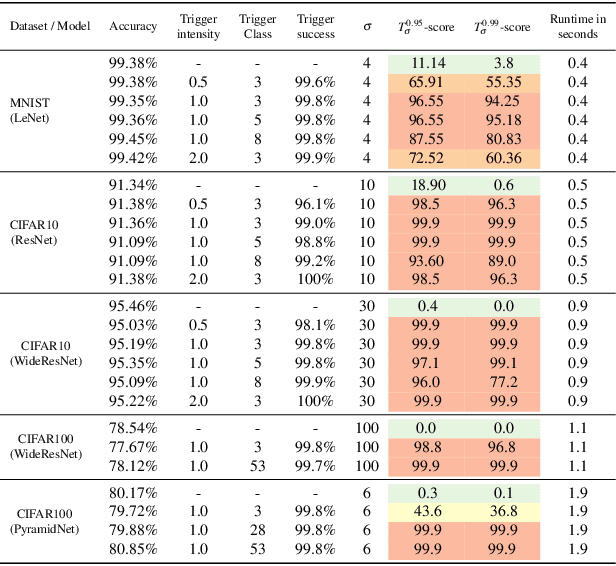

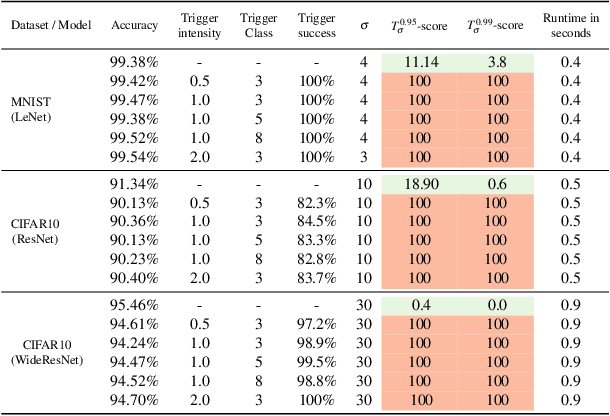
The pervasiveness of deep neural networks (DNNs) in technology, matched with the ubiquity of cloud-based training and transfer learning, is giving rise to a new frontier for cybersecurity whereby `structural malware' is manifest as compromised weights and activation pathways for unsecure DNNs. In particular, DNNs can be designed to have backdoors in which an adversary can easily and reliably fool a classifier by adding to any image a pattern of pixels called a trigger. Since DNNs are black-box algorithms, it is generally difficult to detect a backdoor or any other type of structural malware. To efficiently provide a reliable signal for the absence/presence of backdoors, we propose a rapid feature-generation step in which we study how DNNs respond to noise-infused images with varying noise intensity. This results in titration curves, which are a type of `fingerprinting' for DNNs. We find that DNNs with backdoors are more sensitive to input noise and respond in a characteristic way that reveals the backdoor and where it leads (i.e,. its target). Our empirical results demonstrate that we can accurately detect a backdoor with high confidence orders-of-magnitude faster than existing approaches (i.e., seconds versus hours). Our method also yields a titration-score that can automate the detection of compromised DNNs, whereas existing backdoor-detection strategies are not automated.
Adversarially-Trained Deep Nets Transfer Better
Jul 11, 2020

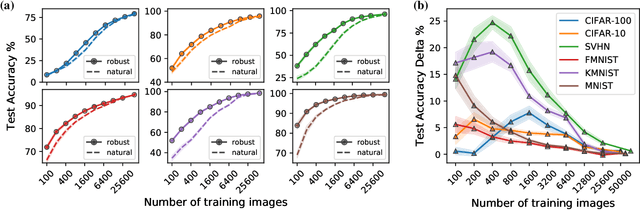
Transfer learning has emerged as a powerful methodology for adapting pre-trained deep neural networks to new domains. This process consists of taking a neural network pre-trained on a large feature-rich source dataset, freezing the early layers that encode essential generic image properties, and then fine-tuning the last few layers in order to capture specific information related to the target situation. This approach is particularly useful when only limited or weakly labelled data are available for the new task. In this work, we demonstrate that adversarially-trained models transfer better across new domains than naturally-trained models, even though it's known that these models do not generalize as well as naturally-trained models on the source domain. We show that this behavior results from a bias, introduced by the adversarial training, that pushes the learned inner layers to more natural image representations, which in turn enables better transfer.
Boundary thickness and robustness in learning models
Jul 09, 2020
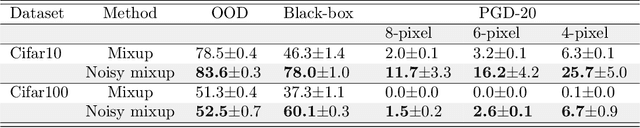
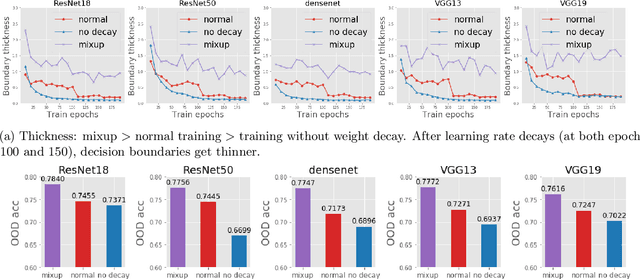
Robustness of machine learning models to various adversarial and non-adversarial corruptions continues to be of interest. In this paper, we introduce the notion of the boundary thickness of a classifier, and we describe its connection with and usefulness for model robustness. Thick decision boundaries lead to improved performance, while thin decision boundaries lead to overfitting (e.g., measured by the robust generalization gap between training and testing) and lower robustness. We show that a thicker boundary helps improve robustness against adversarial examples (e.g., improving the robust test accuracy of adversarial training) as well as so-called out-of-distribution (OOD) transforms, and we show that many commonly-used regularization and data augmentation procedures can increase boundary thickness. On the theoretical side, we establish that maximizing boundary thickness during training is akin to the so-called mixup training. Using these observations, we show that noise-augmentation on mixup training further increases boundary thickness, thereby combating vulnerability to various forms of adversarial attacks and OOD transforms. We can also show that the performance improvement in several lines of recent work happens in conjunction with a thicker boundary.
Debiasing Distributed Second Order Optimization with Surrogate Sketching and Scaled Regularization
Jul 02, 2020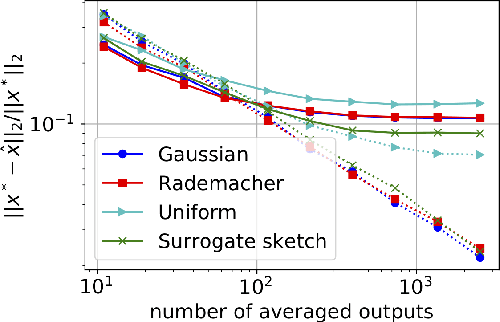

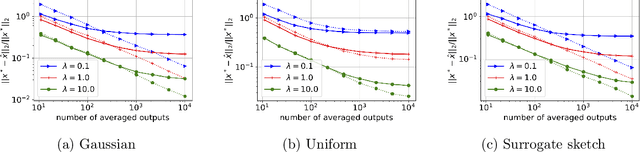
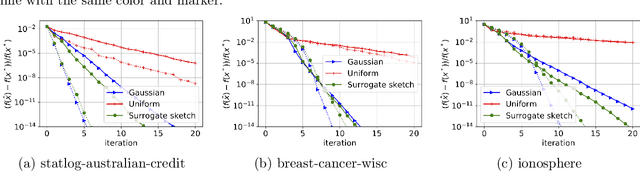
In distributed second order optimization, a standard strategy is to average many local estimates, each of which is based on a small sketch or batch of the data. However, the local estimates on each machine are typically biased, relative to the full solution on all of the data, and this can limit the effectiveness of averaging. Here, we introduce a new technique for debiasing the local estimates, which leads to both theoretical and empirical improvements in the convergence rate of distributed second order methods. Our technique has two novel components: (1) modifying standard sketching techniques to obtain what we call a surrogate sketch; and (2) carefully scaling the global regularization parameter for local computations. Our surrogate sketches are based on determinantal point processes, a family of distributions for which the bias of an estimate of the inverse Hessian can be computed exactly. Based on this computation, we show that when the objective being minimized is $l_2$-regularized with parameter $\lambda$ and individual machines are each given a sketch of size $m$, then to eliminate the bias, local estimates should be computed using a shrunk regularization parameter given by $\lambda^{\prime}=\lambda\cdot(1-\frac{d_{\lambda}}{m})$, where $d_{\lambda}$ is the $\lambda$-effective dimension of the Hessian (or, for quadratic problems, the data matrix).
Good linear classifiers are abundant in the interpolating regime
Jun 22, 2020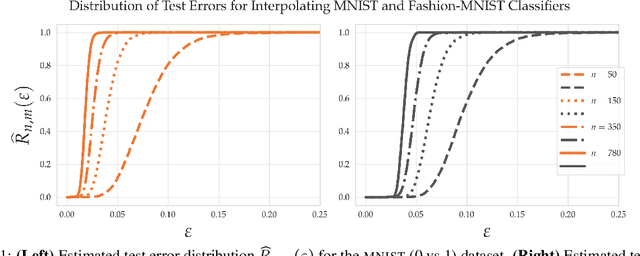
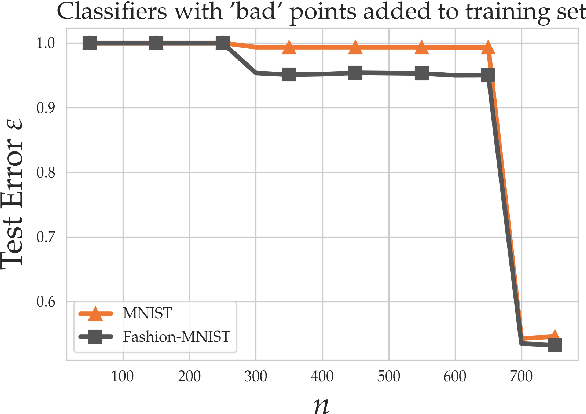
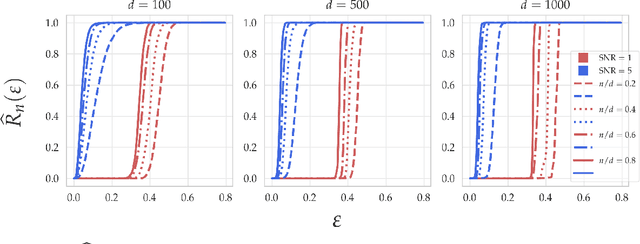
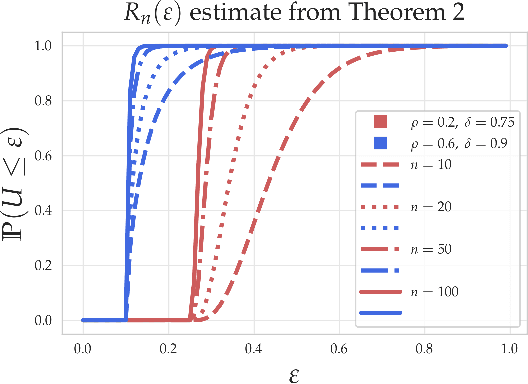
Within the machine learning community, the widely-used uniform convergence framework seeks to answer the question of how complex models such as modern neural networks can generalize well to new data. This approach bounds the test error of the \emph{worst-case} model one could have fit to the data, which presents fundamental limitations. In this paper, we revisit the statistical mechanics approach to learning, which instead attempts to understand the behavior of the \emph{typical} model. To quantify this typicality in the setting of over-parameterized linear classification, we develop a methodology to compute the full distribution of test errors among interpolating classifiers. We apply our method to compute this distribution for several real and synthetic datasets. We find that in many regimes of interest, an overwhelming proportion of interpolating classifiers have good test performance, even though---as we demonstrate---classifiers with very high test error do exist. This shows that the behavior of the worst-case model can deviate substantially from that of the usual model. Furthermore, we observe that for a given training set and testing distribution, there is a critical value $\varepsilon^* > 0$ which is \emph{typical}, in the sense that nearly all test errors eventually concentrate around it. Based on these empirical results, we study this phenomenon theoretically under simplifying assumptions on the data, and we derive simple asymptotic expressions for both the distribution of test errors as well as the critical value $\varepsilon^*$. Both of these results qualitatively reproduce our empirical findings. Our results show that the usual style of analysis in statistical learning theory may not be fine-grained enough to capture the good generalization performance observed in practice, and that approaches based on the statistical mechanics of learning offer a promising alternative.
Lipschitz Recurrent Neural Networks
Jun 22, 2020
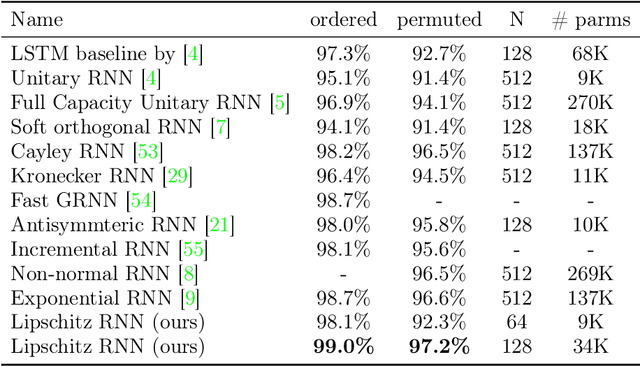
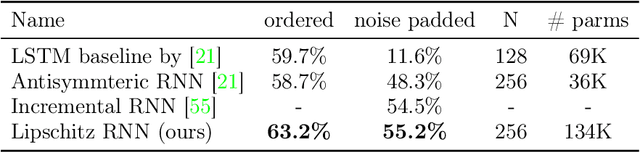
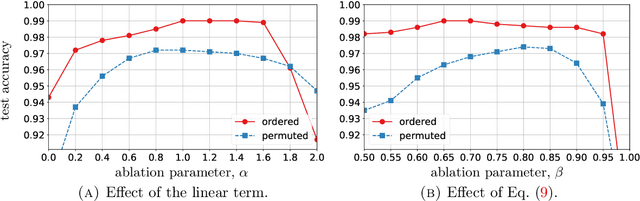
Differential equations are a natural choice for modeling recurrent neural networks because they can be viewed as dynamical systems with a driving input. In this work, we propose a recurrent unit that describes the hidden state's evolution with two parts: a well-understood linear component plus a Lipschitz nonlinearity. This particular functional form simplifies stability analysis, which enables us to provide an asymptotic stability guarantee. Further, we demonstrate that Lipschitz recurrent units are more robust with respect to perturbations. We evaluate our approach on a range of benchmark tasks, and we show it outperforms existing recurrent units.
Precise expressions for random projections: Low-rank approximation and randomized Newton
Jun 18, 2020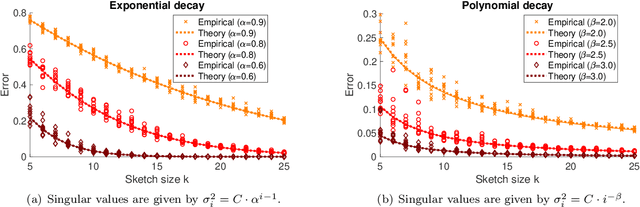
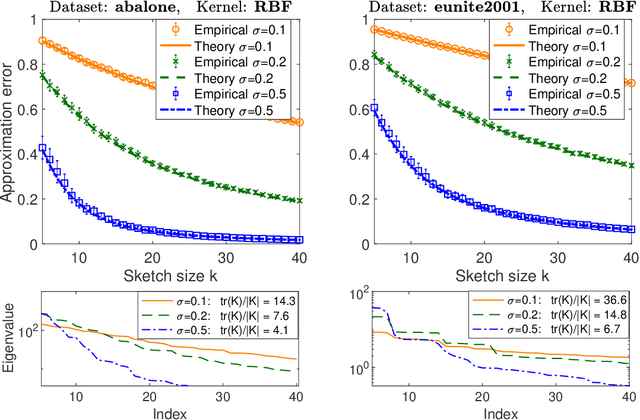
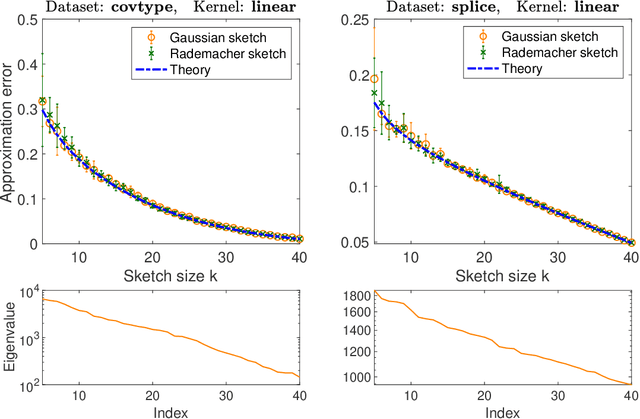
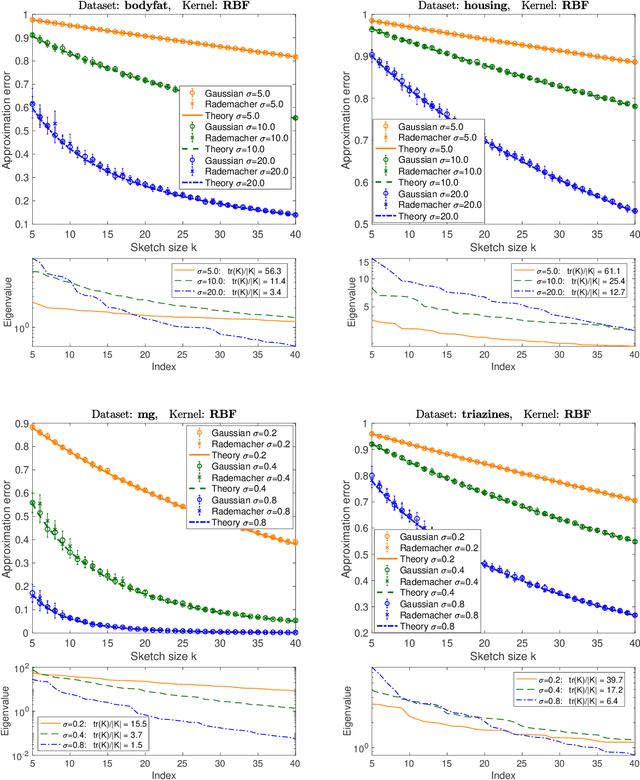
It is often desirable to reduce the dimensionality of a large dataset by projecting it onto a low-dimensional subspace. Matrix sketching has emerged as a powerful technique for performing such dimensionality reduction very efficiently. Even though there is an extensive literature on the worst-case performance of sketching, existing guarantees are typically very different from what is observed in practice. We exploit recent developments in the spectral analysis of random matrices to develop novel techniques that provide provably accurate expressions for the expected value of random projection matrices obtained via sketching. These expressions can be used to characterize the performance of dimensionality reduction in a variety of common machine learning tasks, ranging from low-rank approximation to iterative stochastic optimization. Our results apply to several popular sketching methods, including Gaussian and Rademacher sketches, and they enable precise analysis of these methods in terms of spectral properties of the data. Empirical results show that the expressions we derive reflect the practical performance of these sketching methods, down to lower-order effects and even constant factors.
Multiplicative noise and heavy tails in stochastic optimization
Jun 11, 2020
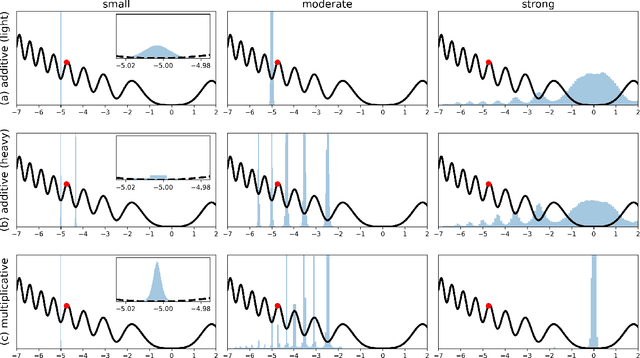

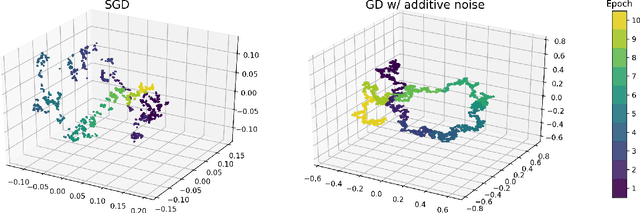
Although stochastic optimization is central to modern machine learning, the precise mechanisms underlying its success, and in particular, the precise role of the stochasticity, still remain unclear. Modelling stochastic optimization algorithms as discrete random recurrence relations, we show that multiplicative noise, as it commonly arises due to variance in local rates of convergence, results in heavy-tailed stationary behaviour in the parameters. A detailed analysis is conducted for SGD applied to a simple linear regression problem, followed by theoretical results for a much larger class of models (including non-linear and non-convex) and optimizers (including momentum, Adam, and stochastic Newton), demonstrating that our qualitative results hold much more generally. In each case, we describe dependence on key factors, including step size, batch size, and data variability, all of which exhibit similar qualitative behavior to recent empirical results on state-of-the-art neural network models from computer vision and natural language processing. Furthermore, we empirically demonstrate how multiplicative noise and heavy-tailed structure improve capacity for basin hopping and exploration of non-convex loss surfaces, over commonly-considered stochastic dynamics with only additive noise and light-tailed structure.