 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCacheGen: Fast Context Loading for Language Model Applications
Oct 11, 2023



As large language models (LLMs) take on more complex tasks, their inputs incorporate longer contexts to respond to questions that require domain knowledge or user-specific conversational histories. Yet, using long contexts poses a challenge for responsive LLM systems, as nothing can be generated until all the contexts are fetched to and processed by the LLM. Existing systems optimize only the computation delay in context processing (e.g., by caching intermediate key-value features of the text context) but often cause longer network delays in context fetching (e.g., key-value features consume orders of magnitude larger bandwidth than the text context). This paper presents CacheGen to minimize the delays in fetching and processing contexts for LLMs. CacheGen reduces the bandwidth needed for transmitting long contexts' key-value (KV) features through a novel encoder that compresses KV features into more compact bitstream representations. The encoder combines adaptive quantization with a tailored arithmetic coder, taking advantage of the KV features' distributional properties, such as locality across tokens. Furthermore, CacheGen minimizes the total delay in fetching and processing a context by using a controller that determines when to load the context as compressed KV features or raw text and picks the appropriate compression level if loaded as KV features. We test CacheGen on three models of various sizes and three datasets of different context lengths. Compared to recent methods that handle long contexts, CacheGen reduces bandwidth usage by 3.7-4.3x and the total delay in fetching and processing contexts by 2.7-3x while maintaining similar LLM performance on various tasks as loading the text contexts.
Automatic and Efficient Customization of Neural Networks for ML Applications
Oct 07, 2023ML APIs have greatly relieved application developers of the burden to design and train their own neural network models -- classifying objects in an image can now be as simple as one line of Python code to call an API. However, these APIs offer the same pre-trained models regardless of how their output is used by different applications. This can be suboptimal as not all ML inference errors can cause application failures, and the distinction between inference errors that can or cannot cause failures varies greatly across applications. To tackle this problem, we first study 77 real-world applications, which collectively use six ML APIs from two providers, to reveal common patterns of how ML API output affects applications' decision processes. Inspired by the findings, we propose ChameleonAPI, an optimization framework for ML APIs, which takes effect without changing the application source code. ChameleonAPI provides application developers with a parser that automatically analyzes the application to produce an abstract of its decision process, which is then used to devise an application-specific loss function that only penalizes API output errors critical to the application. ChameleonAPI uses the loss function to efficiently train a neural network model customized for each application and deploys it to serve API invocations from the respective application via existing interface. Compared to a baseline that selects the best-of-all commercial ML API, we show that ChameleonAPI reduces incorrect application decisions by 43%.
Structural Adversarial Objectives for Self-Supervised Representation Learning
Oct 04, 2023Within the framework of generative adversarial networks (GANs), we propose objectives that task the discriminator for self-supervised representation learning via additional structural modeling responsibilities. In combination with an efficient smoothness regularizer imposed on the network, these objectives guide the discriminator to learn to extract informative representations, while maintaining a generator capable of sampling from the domain. Specifically, our objectives encourage the discriminator to structure features at two levels of granularity: aligning distribution characteristics, such as mean and variance, at coarse scales, and grouping features into local clusters at finer scales. Operating as a feature learner within the GAN framework frees our self-supervised system from the reliance on hand-crafted data augmentation schemes that are prevalent across contrastive representation learning methods. Across CIFAR-10/100 and an ImageNet subset, experiments demonstrate that equipping GANs with our self-supervised objectives suffices to produce discriminators which, evaluated in terms of representation learning, compete with networks trained by contrastive learning approaches.
Factorized Diffusion Architectures for Unsupervised Image Generation and Segmentation
Sep 27, 2023We develop a neural network architecture which, trained in an unsupervised manner as a denoising diffusion model, simultaneously learns to both generate and segment images. Learning is driven entirely by the denoising diffusion objective, without any annotation or prior knowledge about regions during training. A computational bottleneck, built into the neural architecture, encourages the denoising network to partition an input into regions, denoise them in parallel, and combine the results. Our trained model generates both synthetic images and, by simple examination of its internal predicted partitions, a semantic segmentation of those images. Without any finetuning, we directly apply our unsupervised model to the downstream task of segmenting real images via noising and subsequently denoising them. Experiments demonstrate that our model achieves accurate unsupervised image segmentation and high-quality synthetic image generation across multiple datasets.
Accelerated Training via Incrementally Growing Neural Networks using Variance Transfer and Learning Rate Adaptation
Jun 22, 2023



We develop an approach to efficiently grow neural networks, within which parameterization and optimization strategies are designed by considering their effects on the training dynamics. Unlike existing growing methods, which follow simple replication heuristics or utilize auxiliary gradient-based local optimization, we craft a parameterization scheme which dynamically stabilizes weight, activation, and gradient scaling as the architecture evolves, and maintains the inference functionality of the network. To address the optimization difficulty resulting from imbalanced training effort distributed to subnetworks fading in at different growth phases, we propose a learning rate adaption mechanism that rebalances the gradient contribution of these separate subcomponents. Experimental results show that our method achieves comparable or better accuracy than training large fixed-size models, while saving a substantial portion of the original computation budget for training. We demonstrate that these gains translate into real wall-clock training speedups.
Evaluating Machine Learning Models with NERO: Non-Equivariance Revealed on Orbits
May 31, 2023



Proper evaluations are crucial for better understanding, troubleshooting, interpreting model behaviors and further improving model performance. While using scalar-based error metrics provides a fast way to overview model performance, they are often too abstract to display certain weak spots and lack information regarding important model properties, such as robustness. This not only hinders machine learning models from being more interpretable and gaining trust, but also can be misleading to both model developers and users. Additionally, conventional evaluation procedures often leave researchers unclear about where and how model fails, which complicates model comparisons and further developments. To address these issues, we propose a novel evaluation workflow, named Non-Equivariance Revealed on Orbits (NERO) Evaluation. The goal of NERO evaluation is to turn focus from traditional scalar-based metrics onto evaluating and visualizing models equivariance, closely capturing model robustness, as well as to allow researchers quickly investigating interesting or unexpected model behaviors. NERO evaluation is consist of a task-agnostic interactive interface and a set of visualizations, called NERO plots, which reveals the equivariance property of the model. Case studies on how NERO evaluation can be applied to multiple research areas, including 2D digit recognition, object detection, particle image velocimetry (PIV), and 3D point cloud classification, demonstrate that NERO evaluation can quickly illustrate different model equivariance, and effectively explain model behaviors through interactive visualizations of the model outputs. In addition, we propose consensus, an alternative to ground truths, to be used in NERO evaluation so that model equivariance can still be evaluated with new, unlabeled datasets.
Multimodal Contrastive Training for Visual Representation Learning
Apr 26, 2021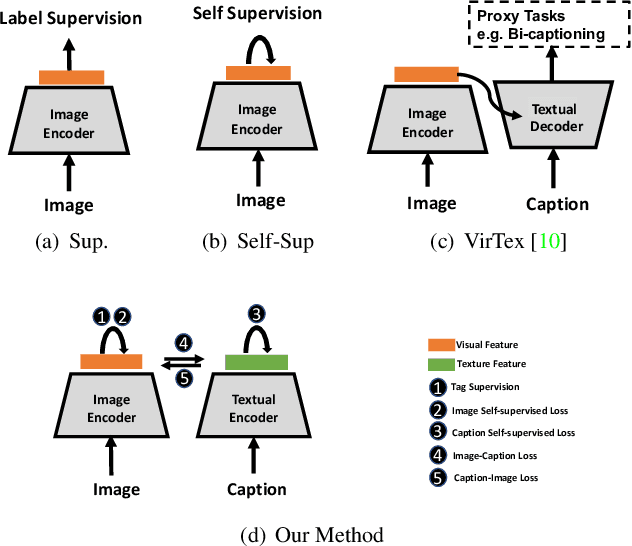
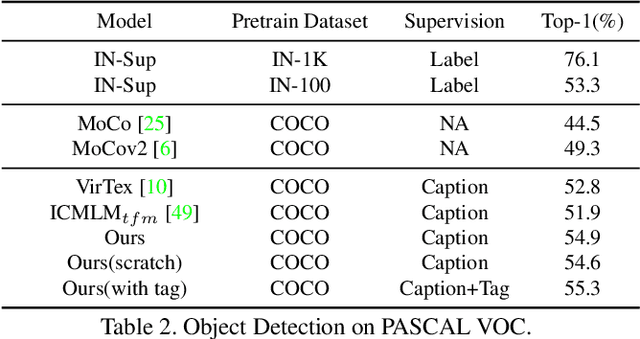
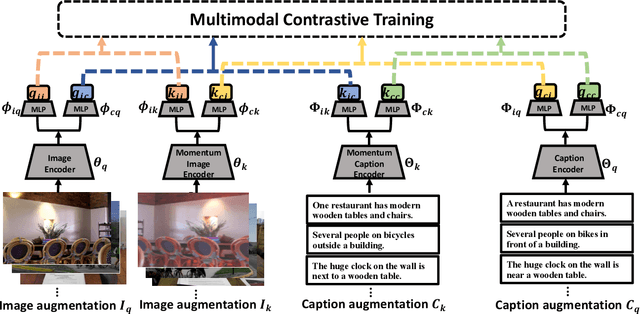
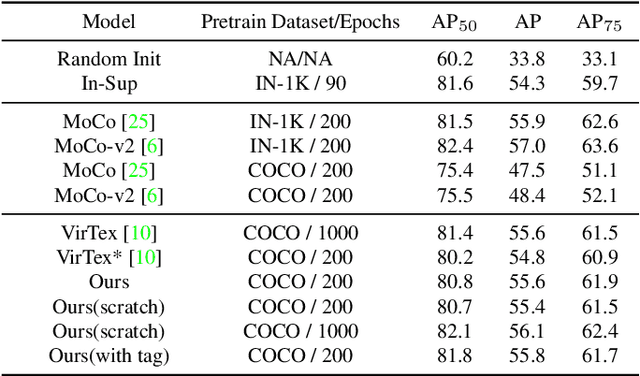
We develop an approach to learning visual representations that embraces multimodal data, driven by a combination of intra- and inter-modal similarity preservation objectives. Unlike existing visual pre-training methods, which solve a proxy prediction task in a single domain, our method exploits intrinsic data properties within each modality and semantic information from cross-modal correlation simultaneously, hence improving the quality of learned visual representations. By including multimodal training in a unified framework with different types of contrastive losses, our method can learn more powerful and generic visual features. We first train our model on COCO and evaluate the learned visual representations on various downstream tasks including image classification, object detection, and instance segmentation. For example, the visual representations pre-trained on COCO by our method achieve state-of-the-art top-1 validation accuracy of $55.3\%$ on ImageNet classification, under the common transfer protocol. We also evaluate our method on the large-scale Stock images dataset and show its effectiveness on multi-label image tagging, and cross-modal retrieval tasks.
Information-Theoretic Segmentation by Inpainting Error Maximization
Dec 14, 2020
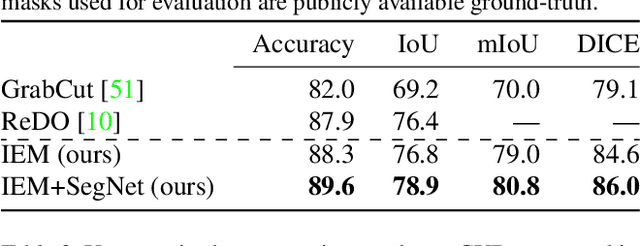
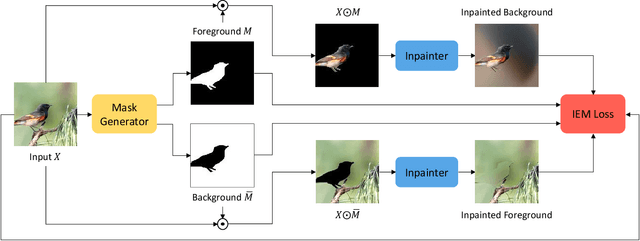
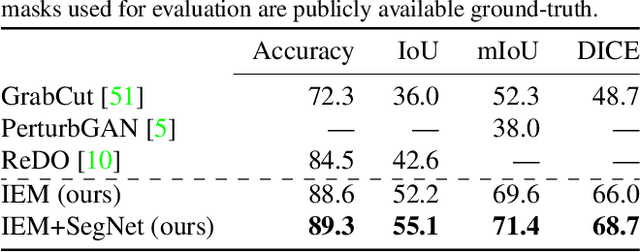
We study image segmentation from an information-theoretic perspective, proposing a novel adversarial method that performs unsupervised segmentation by partitioning images into maximally independent sets. More specifically, we group image pixels into foreground and background, with the goal of minimizing predictability of one set from the other. An easily computed loss drives a greedy search process to maximize inpainting error over these partitions. Our method does not involve training deep networks, is computationally cheap, class-agnostic, and even applicable in isolation to a single unlabeled image. Experiments demonstrate that it achieves a new state-of-the-art in unsupervised segmentation quality, while being substantially faster and more general than competing approaches.
Self-Supervised Visual Representation Learning from Hierarchical Grouping
Dec 05, 2020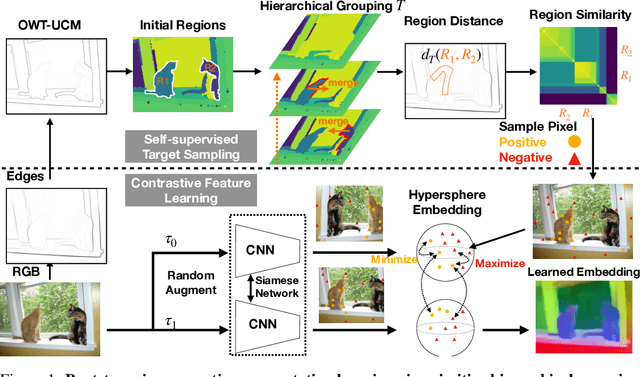
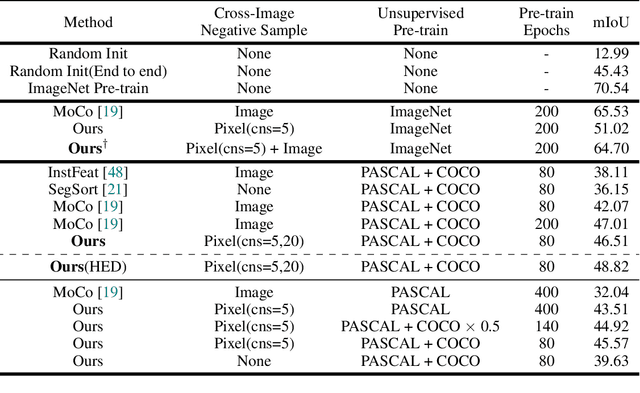


We create a framework for bootstrapping visual representation learning from a primitive visual grouping capability. We operationalize grouping via a contour detector that partitions an image into regions, followed by merging of those regions into a tree hierarchy. A small supervised dataset suffices for training this grouping primitive. Across a large unlabeled dataset, we apply this learned primitive to automatically predict hierarchical region structure. These predictions serve as guidance for self-supervised contrastive feature learning: we task a deep network with producing per-pixel embeddings whose pairwise distances respect the region hierarchy. Experiments demonstrate that our approach can serve as state-of-the-art generic pre-training, benefiting downstream tasks. We additionally explore applications to semantic region search and video-based object instance tracking.
Boosting Contrastive Self-Supervised Learning with False Negative Cancellation
Nov 23, 2020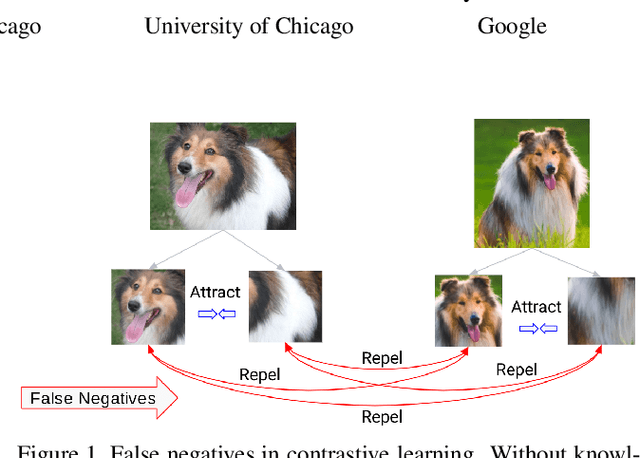

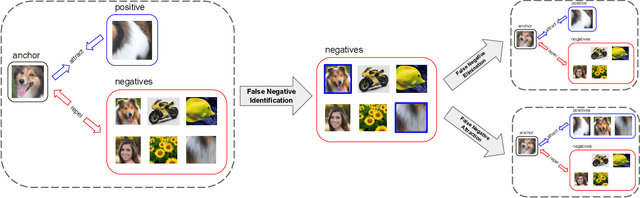

Self-supervised representation learning has witnessed significant leaps fueled by recent progress in Contrastive learning, which seeks to learn transformations that embed positive input pairs nearby, while pushing negative pairs far apart. While positive pairs can be generated reliably (e.g., as different views of the same image), it is difficult to accurately establish negative pairs, defined as samples from different images regardless of their semantic content or visual features. A fundamental problem in contrastive learning is mitigating the effects of false negatives. Contrasting false negatives induces two critical issues in representation learning: discarding semantic information and slow convergence. In this paper, we study this problem in detail and propose novel approaches to mitigate the effects of false negatives. The proposed methods exhibit consistent and significant improvements over existing contrastive learning-based models. They achieve new state-of-the-art performance on ImageNet evaluations, achieving 5.8% absolute improvement in top-1 accuracy over the previous state-of-the-art when finetuning with 1% labels, as well as transferring to downstream tasks.