 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonalized SGD and Nested Architectures for Anytime Neural Networks
Paper and Code
Aug 15, 2020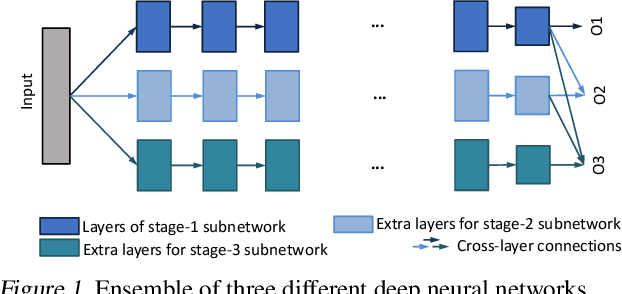
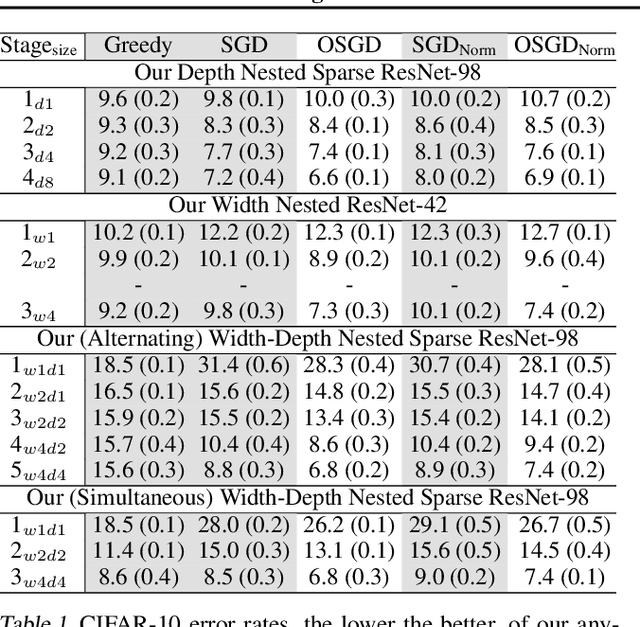
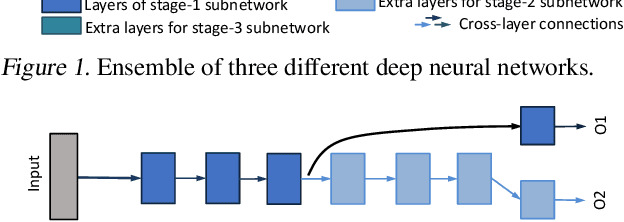
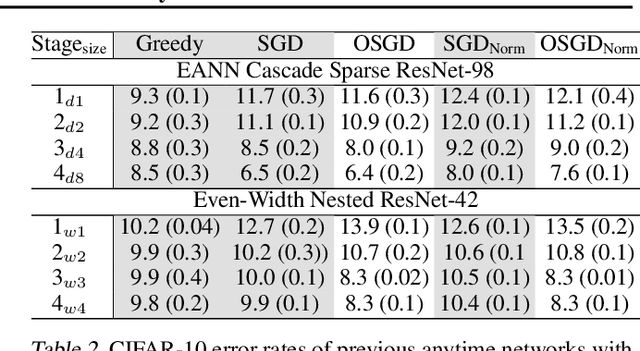
We propose a novel variant of SGD customized for training network architectures that support anytime behavior: such networks produce a series of increasingly accurate outputs over time. Efficient architectural designs for these networks focus on re-using internal state; subnetworks must produce representations relevant for both immediate prediction as well as refinement by subsequent network stages. We consider traditional branched networks as well as a new class of recursively nested networks. Our new optimizer, Orthogonalized SGD, dynamically re-balances task-specific gradients when training a multitask network. In the context of anytime architectures, this optimizer projects gradients from later outputs onto a parameter subspace that does not interfere with those from earlier outputs. Experiments demonstrate that training with Orthogonalized SGD significantly improves generalization accuracy of anytime networks.