 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation visualization under missing values: a comparison between imputation and direct parameter estimation methods
May 10, 2023



Correlation matrix visualization is essential for understanding the relationships between variables in a dataset, but missing data can pose a significant challenge in estimating correlation coefficients. In this paper, we compare the effects of various missing data methods on the correlation plot, focusing on two common missing patterns: random and monotone. We aim to provide practical strategies and recommendations for researchers and practitioners in creating and analyzing the correlation plot. Our experimental results suggest that while imputation is commonly used for missing data, using imputed data for plotting the correlation matrix may lead to a significantly misleading inference of the relation between the features. We recommend using DPER, a direct parameter estimation approach, for plotting the correlation matrix based on its performance in the experiments.
Mask-conditioned latent diffusion for generating gastrointestinal polyp images
Apr 11, 2023



In order to take advantage of AI solutions in endoscopy diagnostics, we must overcome the issue of limited annotations. These limitations are caused by the high privacy concerns in the medical field and the requirement of getting aid from experts for the time-consuming and costly medical data annotation process. In computer vision, image synthesis has made a significant contribution in recent years as a result of the progress of generative adversarial networks (GANs) and diffusion probabilistic models (DPM). Novel DPMs have outperformed GANs in text, image, and video generation tasks. Therefore, this study proposes a conditional DPM framework to generate synthetic GI polyp images conditioned on given generated segmentation masks. Our experimental results show that our system can generate an unlimited number of high-fidelity synthetic polyp images with the corresponding ground truth masks of polyps. To test the usefulness of the generated data, we trained binary image segmentation models to study the effect of using synthetic data. Results show that the best micro-imagewise IOU of 0.7751 was achieved from DeepLabv3+ when the training data consists of both real data and synthetic data. However, the results reflect that achieving good segmentation performance with synthetic data heavily depends on model architectures.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Conditional expectation for missing data imputation
Feb 02, 2023



Missing data is common in datasets retrieved in various areas, such as medicine, sports, and finance. In many cases, to enable proper and reliable analyses of such data, the missing values are often imputed, and it is necessary that the method used has a low root mean square error (RMSE) between the imputed and the true values. In addition, for some critical applications, it is also often a requirement that the logic behind the imputation is explainable, which is especially difficult for complex methods that are for example, based on deep learning. This motivates us to introduce a conditional Distribution based Imputation of Missing Values (DIMV) algorithm. This approach works based on finding the conditional distribution of a feature with missing entries based on the fully observed features. As will be illustrated in the paper, DIMV (i) gives a low RMSE for the imputed values compared to state-of-the-art methods under comparison; (ii) is explainable; (iii) can provide an approximated confidence region for the missing values in a given sample; (iv) works for both small and large scale data; (v) in many scenarios, does not require a huge number of parameters as deep learning approaches and therefore can be used for mobile devices or web browsers; and (vi) is robust to the normally distributed assumption that its theoretical grounds rely on. In addition to DIMV, we also introduce the DPER* algorithm improving the speed of DPER for estimating the mean and covariance matrix from the data, and we confirm the speed-up via experiments.
VISEM-Tracking: Human Spermatozoa Tracking Dataset
Dec 23, 2022A manual assessment of sperm motility requires microscopy observation, which is challenging due to the fast-moving spermatozoa in the field of view. To obtain correct results, manual evaluation requires extensive training. Therefore, computer-assisted sperm analysis (CASA) has become increasingly used in clinics. Despite this, more data is needed to train supervised machine learning approaches in order to improve accuracy and reliability in the assessment of sperm motility and kinematics. In this regard, we provide a dataset called VISEM-Tracking with 20 video recordings of 30 seconds of wet sperm preparations with manually annotated bounding-box coordinates and a set of sperm characteristics analyzed by experts in the domain. In addition to the annotated data, we provide unlabeled video clips for easy-to-use access and analysis of the data via methods such as self- or unsupervised learning. As part of this paper, we present baseline sperm detection performances using the YOLOv5 deep learning model trained on the VISEM-Tracking dataset. As a result, we show that the dataset can be used to train complex deep learning models to analyze spermatozoa. The dataset is publicly available at https://zenodo.org/record/7293726.
MLC at HECKTOR 2022: The Effect and Importance of Training Data when Analyzing Cases of Head and Neck Tumors using Machine Learning
Nov 30, 2022



Head and neck cancers are the fifth most common cancer worldwide, and recently, analysis of Positron Emission Tomography (PET) and Computed Tomography (CT) images has been proposed to identify patients with a prognosis. Even though the results look promising, more research is needed to further validate and improve the results. This paper presents the work done by team MLC for the 2022 version of the HECKTOR grand challenge held at MICCAI 2022. For Task 1, the automatic segmentation task, our approach was, in contrast to earlier solutions using 3D segmentation, to keep it as simple as possible using a 2D model, analyzing every slice as a standalone image. In addition, we were interested in understanding how different modalities influence the results. We proposed two approaches; one using only the CT scans to make predictions and another using a combination of the CT and PET scans. For Task 2, the prediction of recurrence-free survival, we first proposed two approaches, one where we only use patient data and one where we combined the patient data with segmentations from the image model. For the prediction of the first two approaches, we used Random Forest. In our third approach, we combined patient data and image data using XGBoost. Low kidney function might worsen cancer prognosis. In this approach, we therefore estimated the kidney function of the patients and included it as a feature. Overall, we conclude that our simple methods were not able to compete with the highest-ranking submissions, but we still obtained reasonably good scores. We also got interesting insights into how the combination of different modalities can influence the segmentation and predictions.
Combining datasets to increase the number of samples and improve model fitting
Oct 11, 2022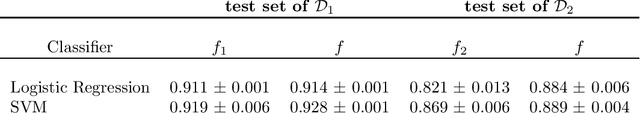

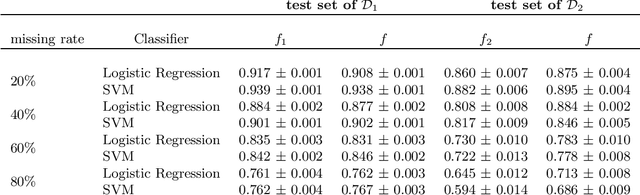
For many use cases, combining information from different datasets can be of interest to improve a machine learning model's performance, especially when the number of samples from at least one of the datasets is small. However, a potential challenge in such cases is that the features from these datasets are not identical, even though there are some commonly shared features among the datasets. To tackle this challenge, we propose a novel framework called Combine datasets based on Imputation (ComImp). In addition, we propose a variant of ComImp that uses Principle Component Analysis (PCA), PCA-ComImp in order to reduce dimension before combining datasets. This is useful when the datasets have a large number of features that are not shared between them. Furthermore, our framework can also be utilized for data preprocessing by imputing missing data, i.e., filling in the missing entries while combining different datasets. To illustrate the power of the proposed methods and their potential usages, we conduct experiments for various tasks: regression, classification, and for different data types: tabular data, time series data, when the datasets to be combined have missing data. We also investigate how the devised methods can be used with transfer learning to provide even further model training improvement. Our results indicate that the proposed methods are somewhat similar to transfer learning in that the merge can significantly improve the accuracy of a prediction model on smaller datasets. In addition, the methods can boost performance by a significant margin when combining small datasets together and can provide extra improvement when being used with transfer learning.
Towards the Neuroevolution of Low-level Artificial General Intelligence
Jul 27, 2022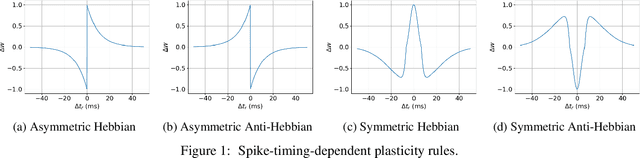
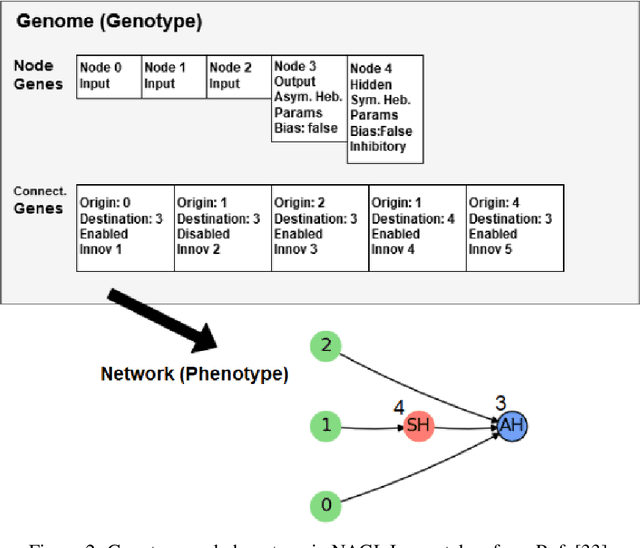
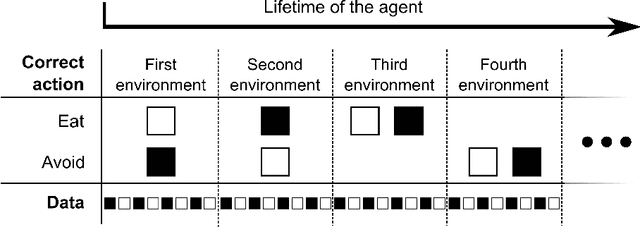
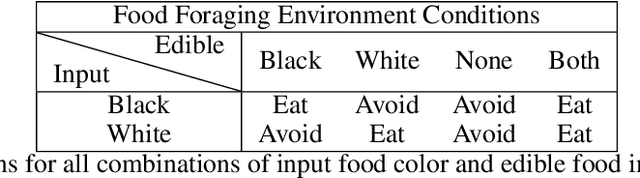
In this work, we argue that the search for Artificial General Intelligence (AGI) should start from a much lower level than human-level intelligence. The circumstances of intelligent behavior in nature resulted from an organism interacting with its surrounding environment, which could change over time and exert pressure on the organism to allow for learning of new behaviors or environment models. Our hypothesis is that learning occurs through interpreting sensory feedback when an agent acts in an environment. For that to happen, a body and a reactive environment are needed. We evaluate a method to evolve a biologically-inspired artificial neural network that learns from environment reactions named Neuroevolution of Artificial General Intelligence (NAGI), a framework for low-level AGI. This method allows the evolutionary complexification of a randomly-initialized spiking neural network with adaptive synapses, which controls agents instantiated in mutable environments. Such a configuration allows us to benchmark the adaptivity and generality of the controllers. The chosen tasks in the mutable environments are food foraging, emulation of logic gates, and cart-pole balancing. The three tasks are successfully solved with rather small network topologies and therefore it opens up the possibility of experimenting with more complex tasks and scenarios where curriculum learning is beneficial.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022



The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Segmentation Consistency Training: Out-of-Distribution Generalization for Medical Image Segmentation
May 30, 2022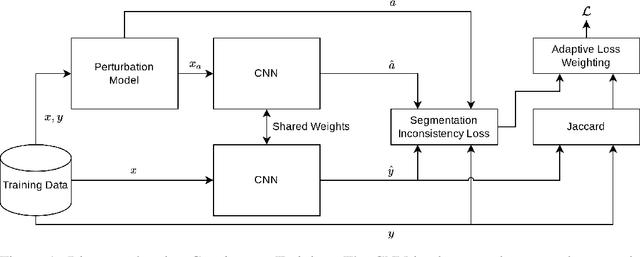
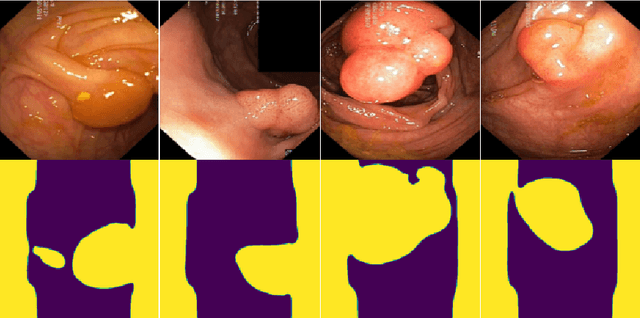

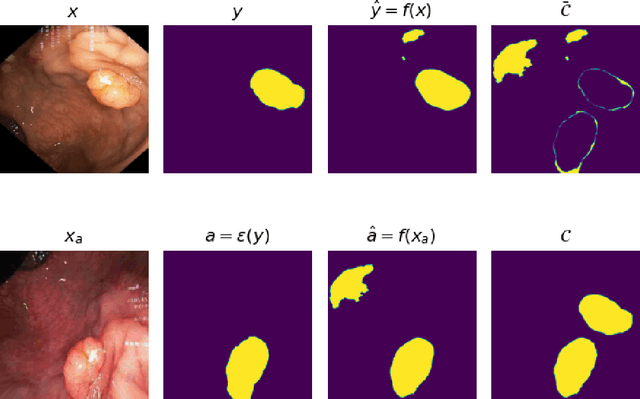
Generalizability is seen as one of the major challenges in deep learning, in particular in the domain of medical imaging, where a change of hospital or in imaging routines can lead to a complete failure of a model. To tackle this, we introduce Consistency Training, a training procedure and alternative to data augmentation based on maximizing models' prediction consistency across augmented and unaugmented data in order to facilitate better out-of-distribution generalization. To this end, we develop a novel region-based segmentation loss function called Segmentation Inconsistency Loss (SIL), which considers the differences between pairs of augmented and unaugmented predictions and labels. We demonstrate that Consistency Training outperforms conventional data augmentation on several out-of-distribution datasets on polyp segmentation, a popular medical task.