 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask--Specificity Score: Measuring How Much Instructions Really Matter for Supervision
Feb 03, 2026Instruction tuning is now the default way to train and adapt large language models, but many instruction--input--output pairs are only weakly specified: for a given input, the same output can remain plausible under several alternative instructions. This raises a simple question: \emph{does the instruction uniquely determine the target output?} We propose the \textbf{Task--Specificity Score (TSS)} to quantify how much an instruction matters for predicting its output, by contrasting the true instruction against plausible alternatives for the same input. We further introduce \textbf{TSS++}, which uses hard alternatives and a small quality term to mitigate easy-negative effects. Across three instruction datasets (\textsc{Alpaca}, \textsc{Dolly-15k}, \textsc{NI-20}) and three open LLMs (Gemma, Llama, Qwen), we show that selecting task-specific examples improves downstream performance under tight token budgets and complements quality-based filters such as perplexity and IFD.
Error Taxonomy-Guided Prompt Optimization
Feb 01, 2026Automatic Prompt Optimization (APO) is a powerful approach for extracting performance from large language models without modifying their weights. Many existing methods rely on trial-and-error, testing different prompts or in-context examples until a good configuration emerges, often consuming substantial compute. Recently, natural language feedback derived from execution logs has shown promise as a way to identify how prompts can be improved. However, most prior approaches operate in a bottom-up manner, iteratively adjusting the prompt based on feedback from individual problems, which can cause them to lose the global perspective. In this work, we propose Error Taxonomy-Guided Prompt Optimization (ETGPO), a prompt optimization algorithm that adopts a top-down approach. ETGPO focuses on the global failure landscape by collecting model errors, categorizing them into a taxonomy, and augmenting the prompt with guidance targeting the most frequent failure modes. Across multiple benchmarks spanning mathematics, question answering, and logical reasoning, ETGPO achieves accuracy that is comparable to or better than state-of-the-art methods, while requiring roughly one third of the optimization-phase token usage and evaluation budget.
One Instruction Does Not Fit All: How Well Do Embeddings Align Personas and Instructions in Low-Resource Indian Languages?
Jan 15, 2026Aligning multilingual assistants with culturally grounded user preferences is essential for serving India's linguistically diverse population of over one billion speakers across multiple scripts. However, existing benchmarks either focus on a single language or conflate retrieval with generation, leaving open the question of whether current embedding models can encode persona-instruction compatibility without relying on response synthesis. We present a unified benchmark spanning 12 Indian languages and four evaluation tasks: monolingual and cross-lingual persona-to-instruction retrieval, reverse retrieval from instruction to persona, and binary compatibility classification. Eight multilingual embedding models are evaluated in a frozen-encoder setting with a thin logistic regression head for classification. E5-Large-Instruct achieves the highest Recall@1 of 27.4\% on monolingual retrieval and 20.7\% on cross-lingual transfer, while BGE-M3 leads reverse retrieval at 32.1\% Recall@1. For classification, LaBSE attains 75.3\% AUROC with strong calibration. These findings offer practical guidance for model selection in Indic multilingual retrieval and establish reproducible baselines for future work\footnote{Code, datasets, and models are publicly available at https://github.com/aryashah2k/PI-Indic-Align.
Grammar Search for Multi-Agent Systems
Dec 16, 2025


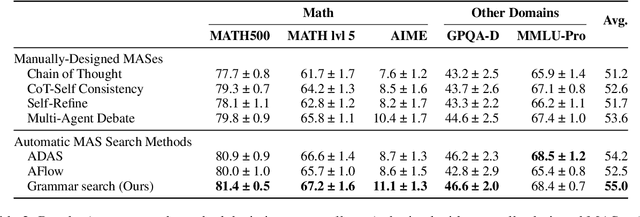
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
Beyond Monolingual Assumptions: A Survey of Code-Switched NLP in the Era of Large Language Models
Oct 08, 2025



Code-switching (CSW), the alternation of languages and scripts within a single utterance, remains a fundamental challenge for multiling ual NLP, even amidst the rapid advances of large language models (LLMs). Most LLMs still struggle with mixed-language inputs, limited CSW datasets, and evaluation biases, hindering deployment in multilingual societies. This survey provides the first comprehensive analysis of CSW-aware LLM research, reviewing \total{unique_references} studies spanning five research areas, 12 NLP tasks, 30+ datasets, and 80+ languages. We classify recent advances by architecture, training strategy, and evaluation methodology, outlining how LLMs have reshaped CSW modeling and what challenges persist. The paper concludes with a roadmap emphasizing the need for inclusive datasets, fair evaluation, and linguistically grounded models to achieve truly multilingual intelligence. A curated collection of all resources is maintained at https://github.com/lingo-iitgn/awesome-code-mixing/.
Eka-Eval : A Comprehensive Evaluation Framework for Large Language Models in Indian Languages
Jul 02, 2025The rapid advancement of Large Language Models (LLMs) has intensified the need for evaluation frameworks that go beyond English centric benchmarks and address the requirements of linguistically diverse regions such as India. We present EKA-EVAL, a unified and production-ready evaluation framework that integrates over 35 benchmarks, including 10 Indic-specific datasets, spanning categories like reasoning, mathematics, tool use, long-context understanding, and reading comprehension. Compared to existing Indian language evaluation tools, EKA-EVAL offers broader benchmark coverage, with built-in support for distributed inference, quantization, and multi-GPU usage. Our systematic comparison positions EKA-EVAL as the first end-to-end, extensible evaluation suite tailored for both global and Indic LLMs, significantly lowering the barrier to multilingual benchmarking. The framework is open-source and publicly available at https://github.com/lingo-iitgn/ eka-eval and a part of ongoing EKA initiative (https://eka.soket.ai), which aims to scale up to over 100 benchmarks and establish a robust, multilingual evaluation ecosystem for LLMs.
UNITYAI-GUARD: Pioneering Toxicity Detection Across Low-Resource Indian Languages
Mar 29, 2025This work introduces UnityAI-Guard, a framework for binary toxicity classification targeting low-resource Indian languages. While existing systems predominantly cater to high-resource languages, UnityAI-Guard addresses this critical gap by developing state-of-the-art models for identifying toxic content across diverse Brahmic/Indic scripts. Our approach achieves an impressive average F1-score of 84.23% across seven languages, leveraging a dataset of 888k training instances and 35k manually verified test instances. By advancing multilingual content moderation for linguistically diverse regions, UnityAI-Guard also provides public API access to foster broader adoption and application.
COMI-LINGUA: Expert Annotated Large-Scale Dataset for Multitask NLP in Hindi-English Code-Mixing
Mar 27, 2025The rapid growth of digital communication has driven the widespread use of code-mixing, particularly Hindi-English, in multilingual communities. Existing datasets often focus on romanized text, have limited scope, or rely on synthetic data, which fails to capture realworld language nuances. Human annotations are crucial for assessing the naturalness and acceptability of code-mixed text. To address these challenges, We introduce COMI-LINGUA, the largest manually annotated dataset for code-mixed text, comprising 100,970 instances evaluated by three expert annotators in both Devanagari and Roman scripts. The dataset supports five fundamental NLP tasks: Language Identification, Matrix Language Identification, Part-of-Speech Tagging, Named Entity Recognition, and Translation. We evaluate LLMs on these tasks using COMILINGUA, revealing limitations in current multilingual modeling strategies and emphasizing the need for improved code-mixed text processing capabilities. COMI-LINGUA is publically availabe at: https://huggingface.co/datasets/LingoIITGN/COMI-LINGUA.
Model Hubs and Beyond: Analyzing Model Popularity, Performance, and Documentation
Mar 19, 2025



With the massive surge in ML models on platforms like Hugging Face, users often lose track and struggle to choose the best model for their downstream tasks, frequently relying on model popularity indicated by download counts, likes, or recency. We investigate whether this popularity aligns with actual model performance and how the comprehensiveness of model documentation correlates with both popularity and performance. In our study, we evaluated a comprehensive set of 500 Sentiment Analysis models on Hugging Face. This evaluation involved massive annotation efforts, with human annotators completing nearly 80,000 annotations, alongside extensive model training and evaluation. Our findings reveal that model popularity does not necessarily correlate with performance. Additionally, we identify critical inconsistencies in model card reporting: approximately 80\% of the models analyzed lack detailed information about the model, training, and evaluation processes. Furthermore, about 88\% of model authors overstate their models' performance in the model cards. Based on our findings, we provide a checklist of guidelines for users to choose good models for downstream tasks.
Leveraging Retrieval Augmented Generative LLMs For Automated Metadata Description Generation to Enhance Data Catalogs
Mar 12, 2025



Data catalogs serve as repositories for organizing and accessing diverse collection of data assets, but their effectiveness hinges on the ease with which business users can look-up relevant content. Unfortunately, many data catalogs within organizations suffer from limited searchability due to inadequate metadata like asset descriptions. Hence, there is a need of content generation solution to enrich and curate metadata in a scalable way. This paper explores the challenges associated with metadata creation and proposes a unique prompt enrichment idea of leveraging existing metadata content using retrieval based few-shot technique tied with generative large language models (LLM). The literature also considers finetuning an LLM on existing content and studies the behavior of few-shot pretrained LLM (Llama, GPT3.5) vis-\`a-vis few-shot finetuned LLM (Llama2-7b) by evaluating their performance based on accuracy, factual grounding, and toxicity. Our preliminary results exhibit more than 80% Rouge-1 F1 for the generated content. This implied 87%- 88% of instances accepted as is or curated with minor edits by data stewards. By automatically generating descriptions for tables and columns in most accurate way, the research attempts to provide an overall framework for enterprises to effectively scale metadata curation and enrich its data catalog thereby vastly improving the data catalog searchability and overall usability.